 夜雨聆风
夜雨聆风





Soul App 又又又开源了!这次是实时交互数字人,支持小时级长视频甚至无限时长!
最近 AI 数字人领域又热闹起来了。
前两天刷 GitHub,又发现 Soul App 新开源了一个名为 SoulX-LiveAct 的实时数字人项目。

这已经不知道是 Soul 开源的第几个数字人相关项目了。更别说在此之前还开源了 SoulX-Singer、SoulX-Podcast 等热门项目。
Soul App(Soul AI Lab)已经让我们见识到了什么叫”中国速度”。
而这一次的 SoulX-LiveAct 更让人惊叹的是它的技术实力:在双卡 H100/H200 上跑出 20 FPS 实时流式推理,延迟仅 0.94 秒,而且支持小时级甚至无限时长的实时交互数字人视频生成。
项目简介
SoulX-LiveAct 是 Soul App AI 团队开源的实时数字人生成框架,核心解决的是 AR(自回归)扩散模型在流式生成场景下的稳定性问题。
简单来说,传统的扩散模型生成视频是一帧一帧”画”出来的,但当你需要实时生成(比如直播场景)时,就会出现严重的画面抖动、人物变形、身份漂移等问题。
SoulX-LiveAct 通过多项核心技术——Neighbor Forcing、长时一致性导向的自回归训练构造、ConvKV Memory——彻底解决了这些痛点。
核心亮点
1、🎯 真正的实时吞吐
在 720×416 或 512×512 分辨率下,SoulX-LiveAct 仅需两张 H100/H200 GPU 就能实现 20 FPS 的实时流式推理,端到端延迟仅 0.94 秒。
这背后是一整套极致的性能优化:
-
• 自适应 FP8 精度:在保证画质的前提下大幅降低计算量 -
• 序列并行(Sequence Parallelism):充分利用多卡算力 -
• 算子融合(Operator Fusion):减少内存访问开销
2、💾 恒定显存,小时级甚至无限时长生成
这是 SoulX-LiveAct 最革命性的突破之一。
传统的视频生成模型,生成时间越长,显存占用就越高,最终必然爆显存。
而 SoulX-LiveAct 通过 ConvKV Memory 机制,实现了恒定显存占用,理论上可以生成无限时长的视频。
ConvKV Memory 的核心思想是”短期精确 + 长期压缩”:
-
• 短期:保留最近几帧的高精度 KV Cache,确保画面连贯 -
• 长期:对历史帧进行轻量级压缩,用极低的显存代价保存长期信息
实测表明,这种压缩机制的 overhead 几乎可以忽略不计,但显存占用却能控制在恒定水平。
3、🧠 长时一致
AR 扩散模型在流式生成时的核心痛点是分布不一致:每一帧的生成条件(如扩散步数)不同,导致画面风格、亮度、细节出现跳变。
SoulX-LiveAct 提出的 Neighbor Forcing 技术,通过将相邻帧的扩散步对齐,强制保持生成过程的一致性。
这相当于给模型加了一个”稳定器”,让每一帧都在相同的”频道”上生成。
确保在小时级的长视频中,人物身份和关键细节始终保持稳定。
快速上手
环境准备
# 创建 conda 环境
conda create -n liveact python=3.10
conda activate liveact
# 安装基础依赖
pip install -r requirements.txt
conda install conda-forge::sox -y安装 SageAttention(FP8 注意力支持)
git clone https://github.com/thu-ml/SageAttention.git
cd SageAttention
git checkout v2.2.0
python setup.py install可选:安装 QKV 算子融合版本以获得更高性能:
git clone https://github.com/ZhiqiJiang/SageAttentionFusion.git
cd SageAttentionFusion
python setup.py install安装 vLLM(FP8 GEMM 支持)
pip install vllm==0.11.0安装 LightVAE
git clone https://github.com/ModelTC/LightX2V
cd LightX2V
python setup_vae.py install下载模型权重
从 Hugging Face 或 ModelScope 下载 SoulX-LiveAct 模型:
-
• Hugging Face:https://huggingface.co/Soul-AI-Lab/SoulX-LiveAct -
• ModelScope(魔搭):https://modelscope.cn/models/Soul-AI-Lab/SoulX-LiveAct
同时需要下载 chinese-wav2vec2-base 音频编码器。
运行推理
双卡 H100/H200 实时流式推理(推荐配置):
USE_CHANNELS_LAST_3D=1 CUDA_VISIBLE_DEVICES=0,1 \
torchrun --nproc_per_node=2 --master_port=$(shuf -n 1 -i 10000-65535) \
generate.py \
--size 416*720 \
--ckpt_dir MODEL_PATH \
--wav2vec_dir chinese-wav2vec2-base \
--fps 20 \
--dura_print \
--input_json examples/example.json \
--steam_audio支持动作/表情编辑的实时推理:
USE_CHANNELS_LAST_3D=1 CUDA_VISIBLE_DEVICES=0,1 \
torchrun --nproc_per_node=2 --master_port=$(shuf -n 1 -i 10000-65535) \
generate.py \
--size 512*512 \
--ckpt_dir MODEL_PATH \
--wav2vec_dir chinese-wav2vec2-base \
--fps 24 \
--input_json examples/example_edit.jsonRTX 4090/5090 消费级显卡运行:
USE_CHANNELS_LAST_3D=1 CUDA_VISIBLE_DEVICES=0 \
python generate.py \
--size 416*720 \
--ckpt_dir MODEL_PATH \
--wav2vec_dir chinese-wav2vec2-base \
--fps 24 \
--input_json examples/example.json \
--fp8_kv_cache \
--block_offload \
--t5_cpu注意:FP8 KV Cache 可能会对生成质量有轻微影响。
综合表现
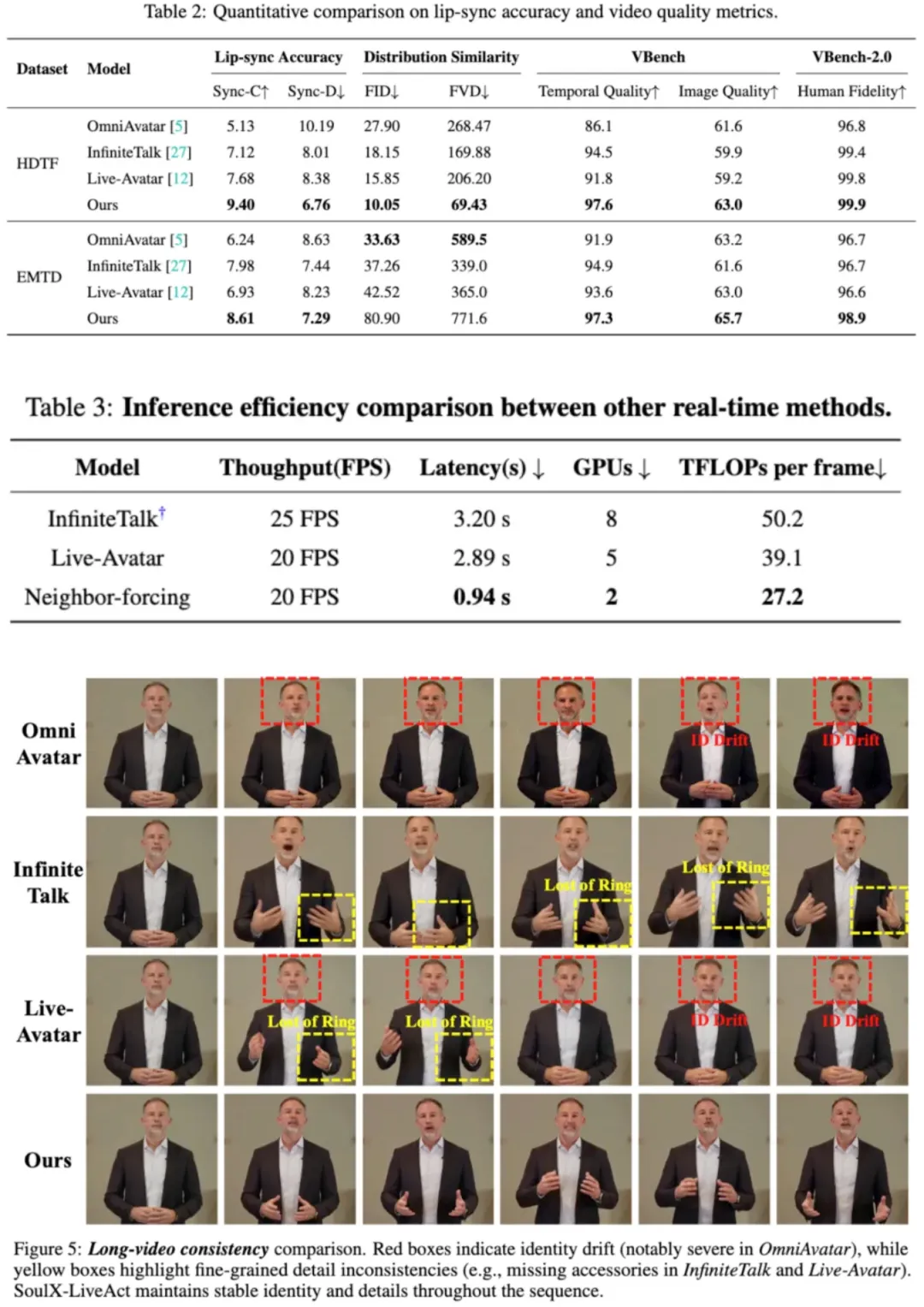
在技术报告的对比实验中,SoulX-LiveAct 展现出了显著的优势:
|
|
|
|
|---|---|---|
| 长时稳定性 |
|
|
| 显存占用 |
|
|
| 实时性能 |
|
|
| 口型同步 |
|
|
| 配饰/纹理 |
|
|
实测结论:在报告的长时对比中,基线方法普遍出现不同程度的身份漂移与细节不稳定;而 SoulX-LiveAct 能在更长时间窗口内保持身份一致性与关键细节持续稳定。
应用场景
-
• 🎙️ 播客/对话场景:双人对谈、访谈节目,实时生成自然的面部表情和口型同步。 -
• 🎤 音乐/脱口秀:支持唱歌、演讲等需要强表情管理的场景,情感表达丰富自然。 -
• 📱 FaceTime/视频通话:模拟真实的视频通话体验,可用于虚拟客服、在线教育等 B 端场景。
可以看出,Soul AI Lab 正在系统性地攻克实时数字人的各个技术难点:从低延迟到高帧率,从短片段到长视频,从服务器到消费级显卡。
写在最后
SoulX-LiveAct 的出现,标志着开源数字人技术进入了一个新阶段。
它不再是那种”看起来很酷但没法用”的 demo,而是一个真正可以落地到生产环境的工具。
无论是做直播、做客服、做内容创作,还是做虚拟社交,它都能提供稳定、实时、高质量的输出。
更重要的是,它是开源的。这意味着每一个开发者、每一个创业团队,都可以基于它构建自己的应用,而不必被闭源 API 的高昂成本和功能限制所束缚。
Soul AI Lab 这种持续开源的精神,也同样值得点赞。
GitHub:
https://github.com/Soul-AILab/SoulX-LiveAct
Hugging Face:
https://huggingface.co/Soul-AI-Lab/SoulX-LiveAct

如果本文对您有帮助,也请帮忙点个 赞👍 + 在看 哈!❤️
