 夜雨聆风
夜雨聆风





PDF OCR转换工具,把那些“图片式”的PDF转换成真正能用的文档


把那些“图片式”的PDF,变成了真正能用的文档


上周同事发来一份扫描版的合同,让帮忙核对条款。打开PDF,找到需要修改的那一段,按了Ctrl+C——然后粘贴到Word里,出来一堆乱七八糟的符号。
又试了一次,还是一样。这时候才反应过来:这份PDF根本不是文字,就是一页一页的图片。文字是印在图片上的,不是真正的文本。
明明眼睛看着清清楚楚的文字,电脑就是识别不出来。想引用一段话,得一个字一个字重新敲。想搜索某个关键词,搜不到。想标注重点,没法复制粘贴。
那天下午,为了改那份合同,硬生生对着PDF敲了两千多字。敲完之后,盯着电脑屏幕发呆:都这年代了,为什么还得干这种活?
后来一个做档案管理的朋友听说这事,发了工具过来,说:”下次再遇到这种扫描件,先扔到这个软件里跑一下。”
试了试,然后沉默了。
绿色版,不用安装,解压之后双击就能打开。界面也干净,没有乱七八糟的广告和弹窗。
拿之前那份让我敲了两千字的合同试了一下。把扫描版PDF拖进去,点了”开始转换”。大概等了一两分钟——具体时间取决于文件页数——转换完成了。
打开转换后的PDF,随手选中一段文字,Ctrl+C,粘贴到Word里。完美。文字、标点、段落,全部都在。连那些有点模糊的扫描痕迹,都没有影响识别准确率。
看着那几页能复制、能搜索的PDF,心里只有一个念头:之前那两个小时到底在干什么?
而且这个工具是批量处理的。有一次需要处理十几份扫描文档,一次性全拖进去,让它自己在后台跑,去倒了杯水回来,十几份文件全转好了。不用一个一个操作,不用守着电脑等。
它做的事就是把”图片式PDF”变成”真正的PDF”。技术上叫”双层PDF”——上层保留原文档的扫描图像,下层是OCR识别出来的文字。你眼睛看到的还是原来的样子,但电脑能识别出里面的文字了。
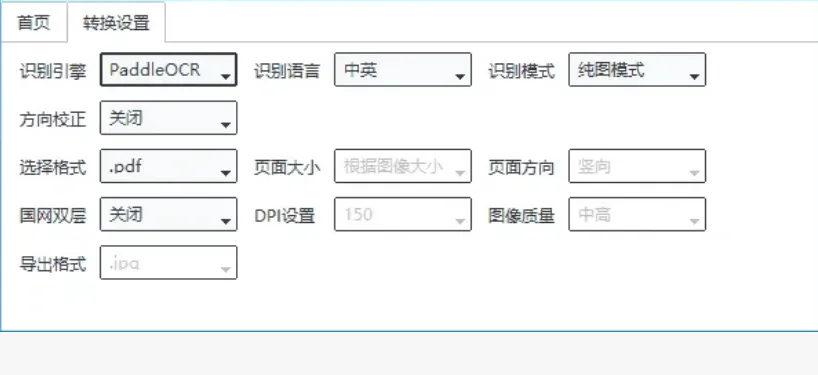
支持的输入格式挺全的:PDF文件、JPEG、PNG这些图片格式都能转。OCR识别的语言支持也不少,试过中文、英文混排的文档,识别得挺准。官方说支持中、英、日、韩、法、德这些语言,基本上常见的语种都覆盖了。
输出的时候,还可以自己调页面尺寸、图片质量、要不要嵌入字体这些参数。虽然我用默认设置就够用了,但如果有特殊需求,它也能满足。
省时间是最直接的。一份20页的扫描合同,手动重打至少一两个小时。用这个工具,两分钟搞定。时间就是命,这个账太划算了。
准确率高。手打难免有错别字,尤其是数字、专业术语这些。OCR虽然不能保证100%准确,但在我试过的文档里,准确率绝对比手打要高。而且它不会疲劳,不会分心,不会手滑。
支持搜索。转完之后,在PDF里按Ctrl+F,可以直接搜到任何关键词。这个功能对于查资料、找合同条款来说,特别实用。
永久可用。很多在线转换网站,转完给你加水印,或者限制页数,或者免费版只能转三页。这个工具是本地的,一次下载,永久使用,没有页数限制,没有水印,没有”每天只能转两次”这种限制。
这个工具不是什么炫酷的黑科技。OCR技术已经存在很多年了,但问题是——我们需要它的时候,它总是不在顺手的地方。
急用的时候,去网上搜在线转换,要么要钱,要么要等,要么转出来效果稀烂。手头有个本地的工具,想用随时用,不用上传文件,不用担心隐私泄露,这种感觉特别踏实。
如果你也经常收到那种”图片式PDF”,或者需要把一堆扫描文档转成可搜索的版本,那这个工具值得你存一份在电脑里。
1.压缩包内的资源/内容源于互联网公开分享的内容,本公众号仅做整理和分享,不收取任何费用。
2.本公众号对所提供下载的软件和程序代码不拥有任何权利,其版权归该软件和程序代码的合法拥有者所有。
3.软件仅供个人学习使用,请用户下载后于24小时内删除,并禁止用于商业和倒卖。如真正需要,请支持正版,侵权请联系删除。
4.软件内任何收费,广告宣传,推广信息均为诈骗请勿相信。与本号无关。可反映及时删除

