 夜雨聆风
夜雨聆风





Chandra OCR 2: 文档智能领域的开源新标杆
Chandra OCR 2: 文档智能领域的开源新标杆

引言: 当AI真正读懂你的文档
在这个信息爆炸的时代,我们每天都在与海量文档打交道:PDF报告、扫描件、手写笔记、复杂表格、数学公式…传统的OCR工具只能机械地提取文字,却丢失了文档的灵魂——版式、结构和语义。而今天,Chandra OCR 2 的出现,正在重新定义文档智能的边界。
Datalab团队于2026年3月发布的 Chandra OCR 2,是一款开源的文档理解模型,它不仅能将图片和PDF转换为结构化文本,更能精准还原文档的版式信息。这意味着什么?你的数学公式会被正确渲染,表格结构会被完整保留,多栏布局会被智能识别,甚至连手写草书都能准确识别。
核心能力: 不止于OCR
Chandra OCR 2 的强大之处在于它的多模态理解能力。让我们看看它究竟能做什么:
90+ 语言支持: 从阿拉伯语到印地语,从日语到俄语,Chandra 2 在多语言基准测试中平均达到77.8%的准确率,远超Gemini 2.5 Flash的67.6%。
数学公式识别: 对于科研工作者和学生来说,这简直是福音。CS229教材中的复杂数学公式?轻松搞定。
表格结构还原: 财务报表、统计表格,Chandra 2 能准确识别单元格边界和内容对应关系。
手写文字识别: 无论是工整的笔记还是潦草的草书,它都能准确识别。
表单与复选框: 自动识别表单字段和勾选状态,数字化纸质表单从未如此简单。
技术架构: 双模式推理的灵活设计
Chandra OCR 2 的架构设计充分考虑了不同场景的需求:
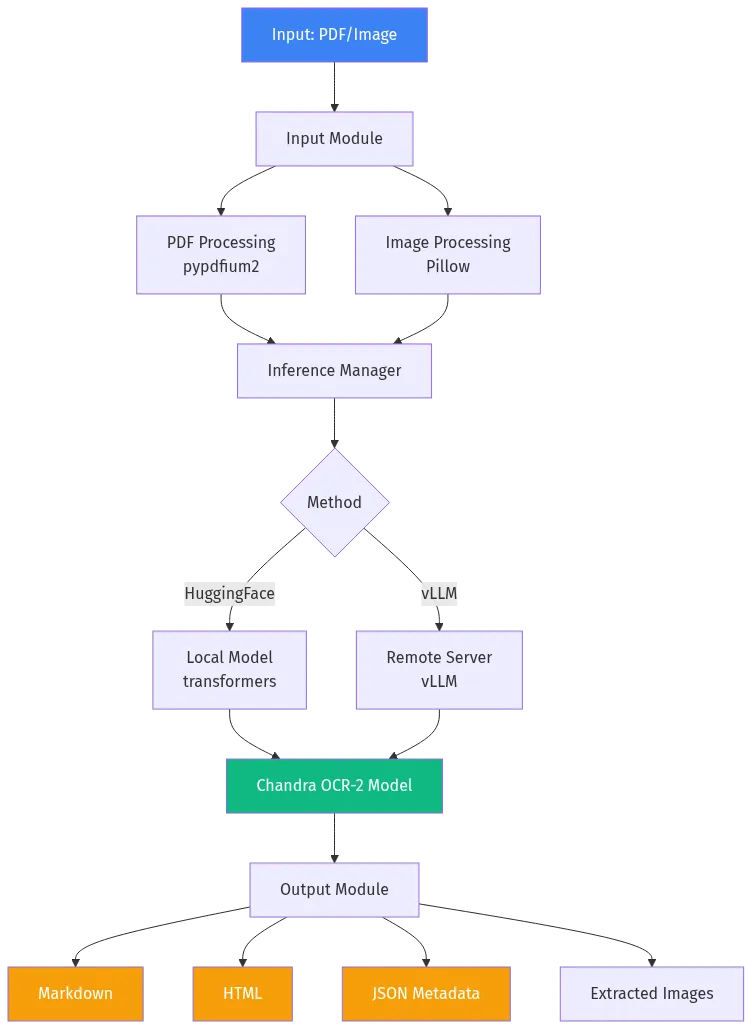
HuggingFace 本地模式: 适合数据隐私要求高的场景,完全离线运行,无需联网。
vLLM 服务端模式: 适合企业级部署,支持高并发请求,单张H100显卡可达1.44页/秒的吞吐量。
这种双模式设计让用户可以根据实际需求灵活选择,既保证了隐私安全,又满足了性能要求。
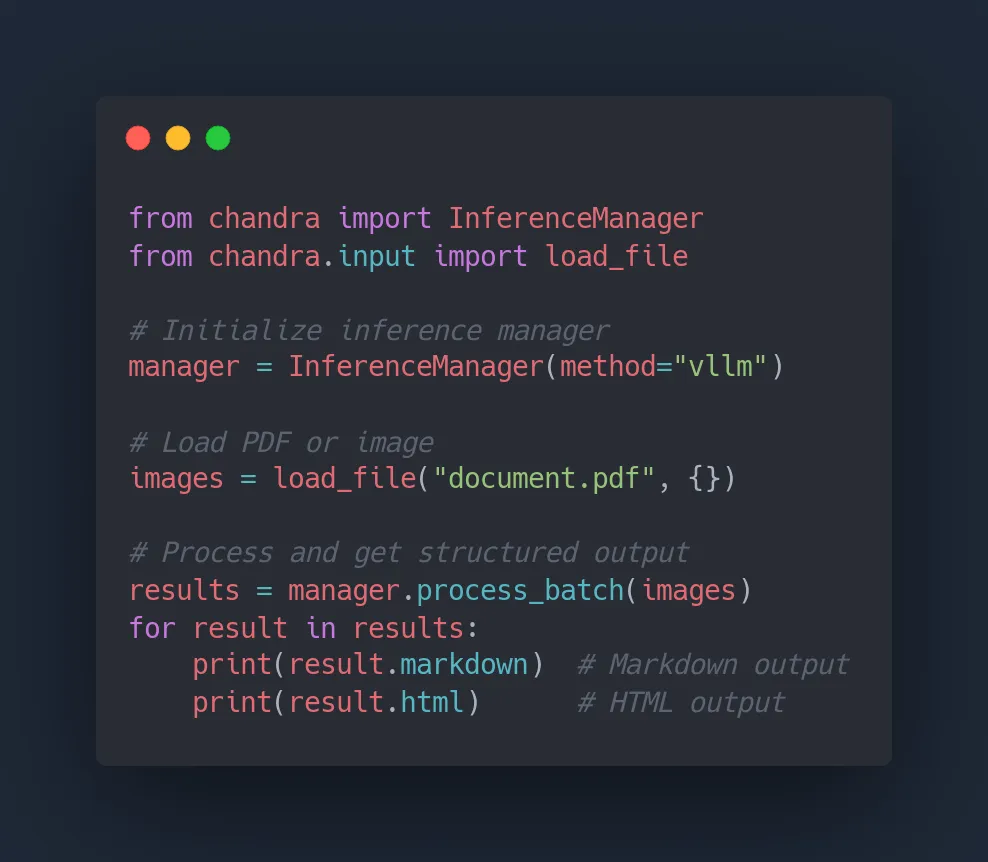
代码示例: 极简的API设计
Chandra OCR 2 的API设计非常简洁,几行代码就能完成文档转换:
安装同样简单:
CODE_BLOCK_0
对于想要交互式体验的用户,还可以启动Streamlit应用:
CODE_BLOCK_1
性能表现: 数据说话
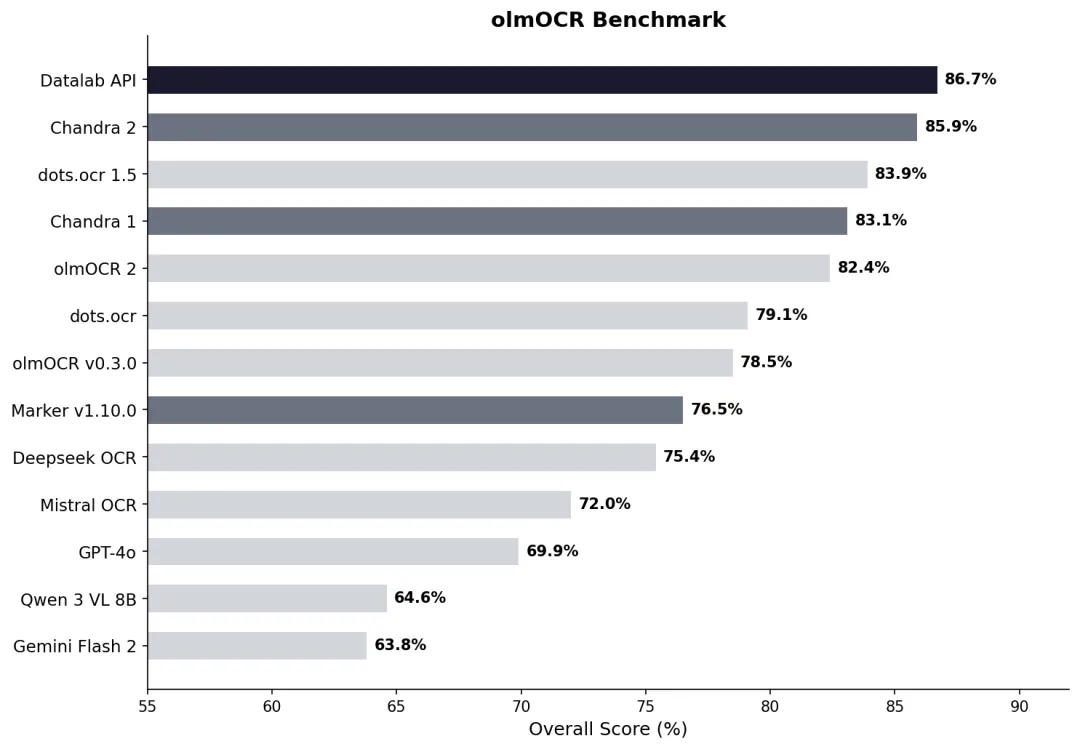
在权威的olmOCR基准测试中,Chandra 2 以85.9分的综合成绩位列开源模型第一,仅次于Datalab的商业API版本(86.7分)。具体表现如下:
- •ArXiv论文: 90.2分
- •旧扫描件数学: 89.3分
- •表格识别: 89.9分
- •多栏布局: 83.5分
相比Chandra 1,新版本在数学识别、表格处理和旧扫描件识别方面都有显著提升。

应用场景: 无限可能
Chandra OCR 2 的应用场景几乎涵盖了所有需要文档数字化的领域:
学术研究: 将扫描版论文转换为可编辑的Markdown,保留公式和引用格式。
企业文档管理: 批量处理合同、发票、报告,构建企业知识库。
教育领域: 将手写教案、学生作业数字化,便于存档和分析。
金融审计: 自动提取财务报表中的关键数据,生成结构化JSON。
多语言翻译: 支持90+语言的准确识别,为翻译工作流提供高质量的源文本。
开源协议与商业许可
Chandra OCR 2 采用Apache 2.0开源协议,模型权重使用修改版OpenRAIL-M许可。这意味着:
- •研究和个人使用完全免费
- •初创企业(融资/收入低于200万美元)可以免费使用
- •不能用于与Datalab API竞争的商业服务
对于需要更广泛商业授权的企业,Datalab提供了付费的商业许可选项。
结语: 文档智能的新纪元
Chandra OCR 2 的发布,标志着开源文档智能模型已经具备了与商业API一较高下的实力。它不仅在准确率上接近顶尖水平,更在隐私保护、成本控制和使用灵活性上提供了独特的价值主张。
对于开发者来说,这是一个值得深入研究和集成的工具;对于企业来说,这是构建文档智能系统的理想选择;对于研究者来说,这是探索多模态AI的绝佳平台。
项目地址: https://github.com/datalab-to/chandra
在线体验: https://www.datalab.to/playground