 夜雨聆风
夜雨聆风





从AI助手到AI科学家:让大模型自己发明算法
论文信息
论文标题:From AI Assistant to AI Scientist: Autonomous Discovery of LLM-RL Algorithms with LLM Agents
第一作者:Sirui Xia
作者单位:复旦大学数据科学上海市重点实验室、复旦大学计算机科学技术学院;复旦大学数据科学学院
论文主页:arXiv: 2603.23951
开源代码:论文正文中暂未给出官方代码链接。
一、从研究助手到算法发现者
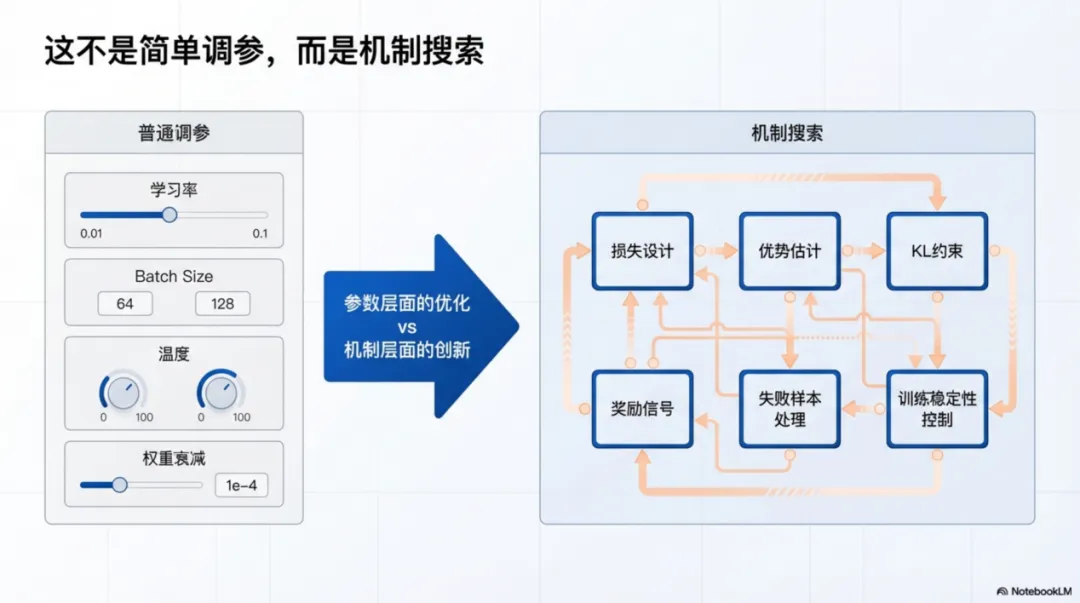
这篇论文讨论的是一个很有意思、也很有野心的问题:大模型能不能不只是辅助研究者写代码、查资料、跑实验,而是进一步参与“发明算法”这件事。作者把关注点放在大语言模型强化学习后训练里的策略优化算法上。这个领域的改进往往不是简单调几个参数,而是要不断修改损失设计、优势估计、正则约束等核心机制,再通过昂贵的训练和评测去验证效果。这个过程很慢、很贵,而且高度依赖研究者经验。
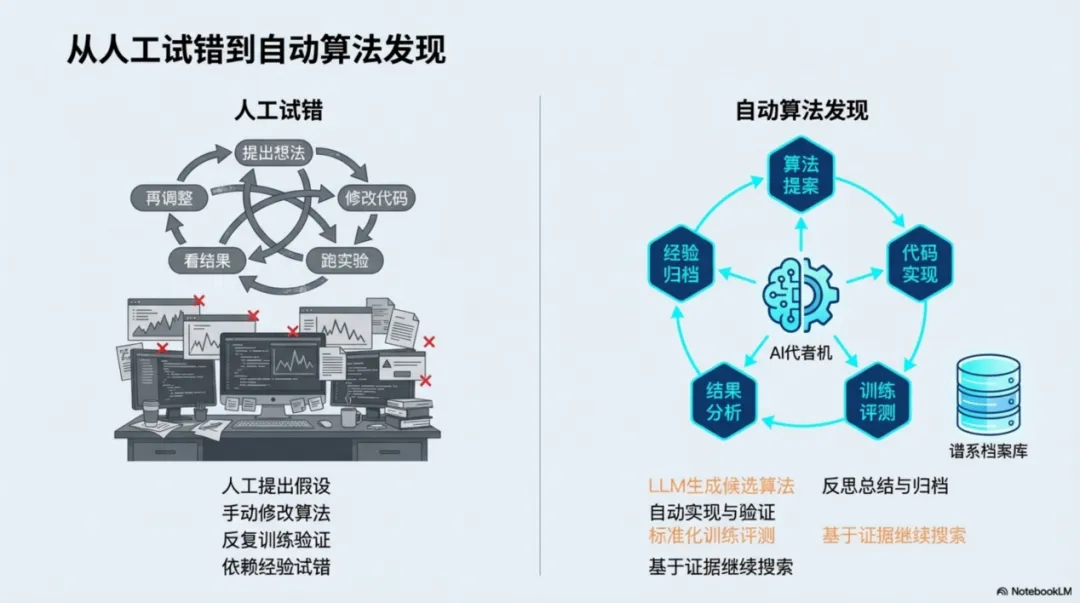
作者认为,真正困难的地方并不只是“提出一个新想法”,而是要回答一连串更深的问题:这个机制为什么可能有效?它在哪些实验里失效了?前面失败过的尝试,能不能变成下一轮设计的依据?也正因为如此,策略优化算法的自动发现,不适合被看成普通的组合搜索或自动调参问题。它更像是一种围绕训练动力学展开的机制搜索,需要把每一次实验留下来的经验真正积累起来。
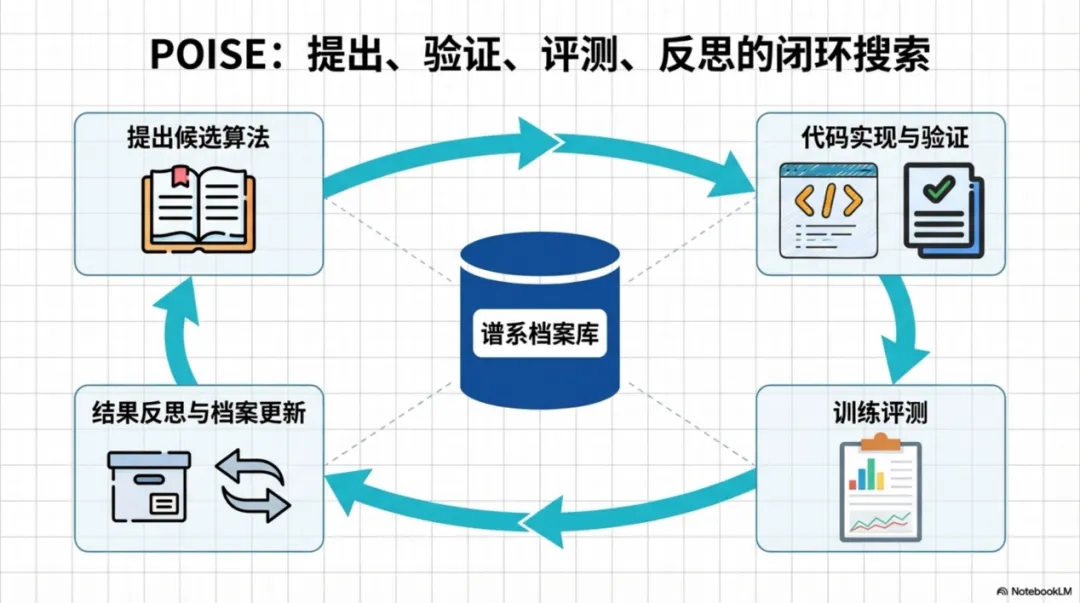
在这个背景下,论文提出了 POISE,全称是 Policy Optimization through Iterative Search and Evidence。从名字就能看出来,它强调的不只是“搜索”,还强调“证据”。作者想做的不是让模型不断瞎试,而是把算法设计组织成一个闭环:提出方案、实现代码、训练评估、分析结果、记录反思,再进入下一轮搜索。换句话说,论文真正要推动的是一种角色变化——让大模型从“研究助手”慢慢向“算法发现者”迈一步。
二、POISE如何一步步找到更优解
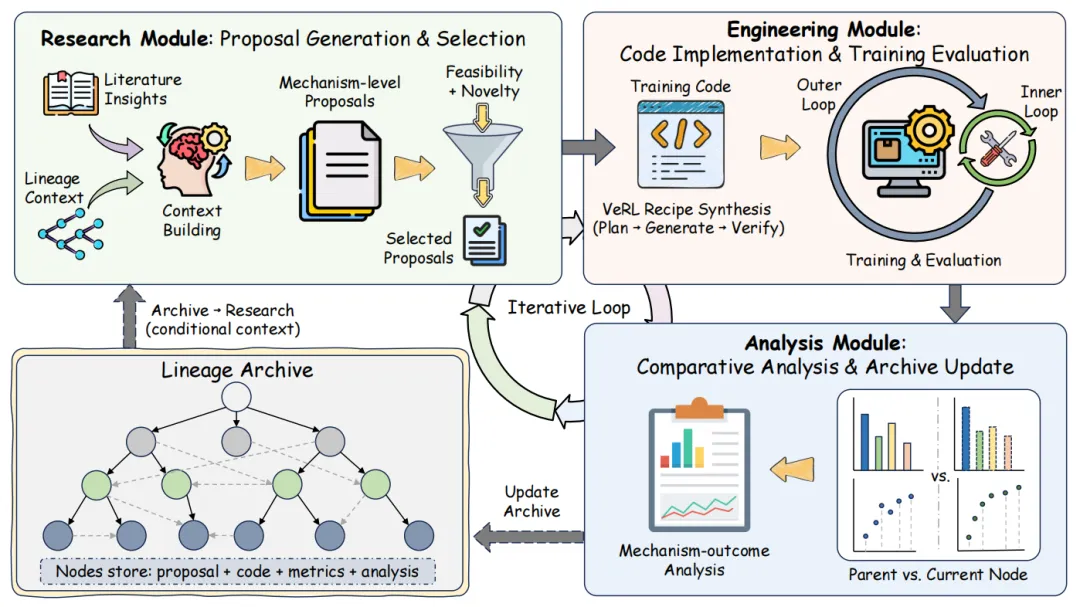
POISE 的核心思路可以概括成一句话:让算法搜索变成一个会积累经验的迭代过程。在这个系统里,每一个候选算法都不是孤立存在的。它会和自己的提案动机、实现代码、标准化评测结果以及自然语言反思一起,被存进一个带有谱系关系的档案库中。后面的新方案,不再从零开始乱试,而是会参考前面哪些设计有效、哪些设计失败、哪些思路值得继续扩展。这样的档案库,实际上把“实验经验”从零散记录变成了可以继承的研究资产。
更具体一点看,POISE 的运行大致分成几步。先是结合文献线索和已有谱系,生成一批机制层面的候选算法;然后对这些提案做筛选,看它们是否具有一定新意、是否逻辑自洽、能否真正落成代码;接着进入实现、验证和训练评测阶段;最后再把新节点和它的父节点放在一起比较,分析这次改动可能为什么有效,或者为什么没有达到预期。整个过程不是单纯追求“多试几个”,而是尽量让每一轮试验都给下一轮留下更清楚的判断依据。
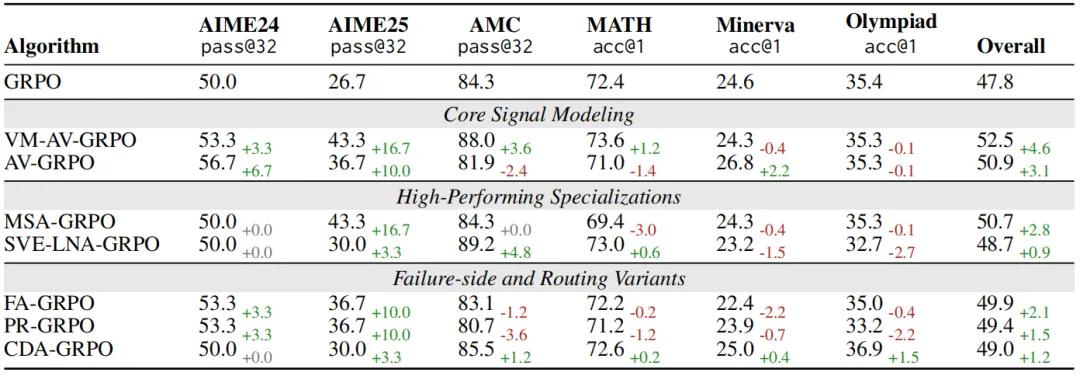
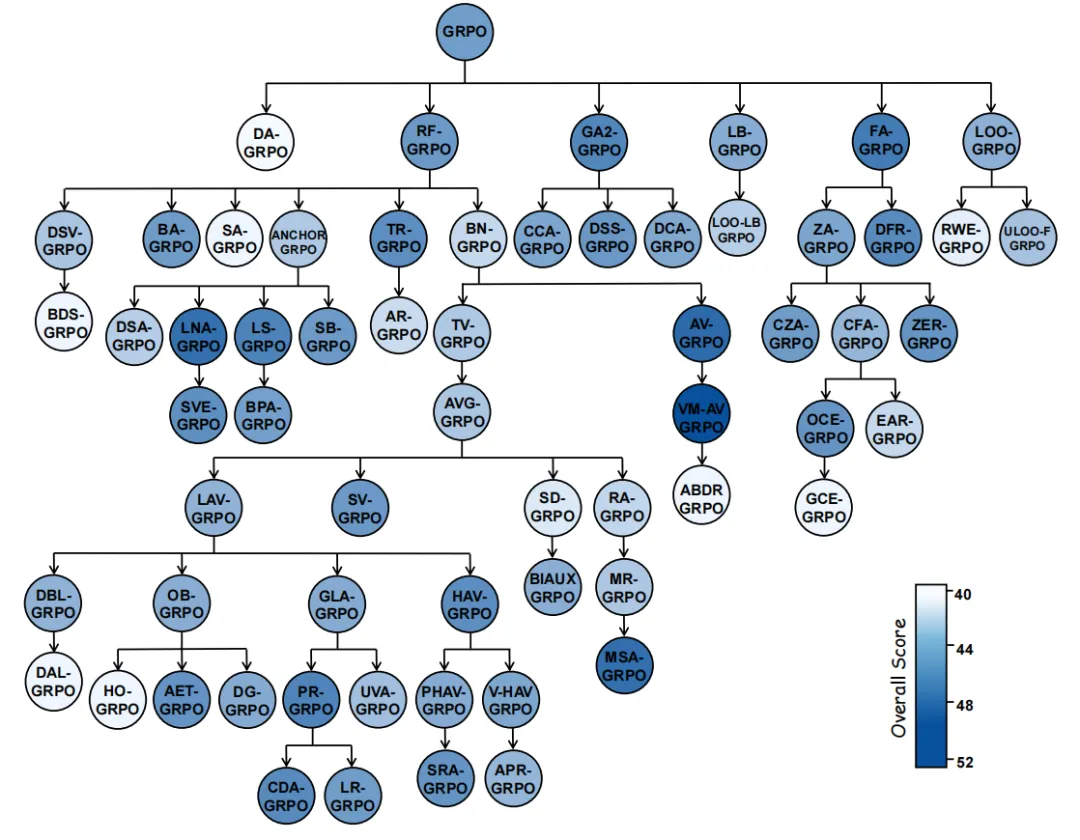
实验部分,作者选择了数学推理任务作为主要验证场景,并从 GRPO 这个基线算法出发,让 POISE 自主搜索更优的变体。论文中一共评估了 64 个候选算法。最终找到的一批变体中,最强的一个版本是 VM-AV-GRPO。它把加权 Overall 从基线的 47.8 提升到 52.5,同时把 AIME25 pass@32 从 26.7% 提升到 43.3%。这说明 POISE 找到的并不只是一些表面上的小修小补,而是真正在机制层面带来了可观提升。
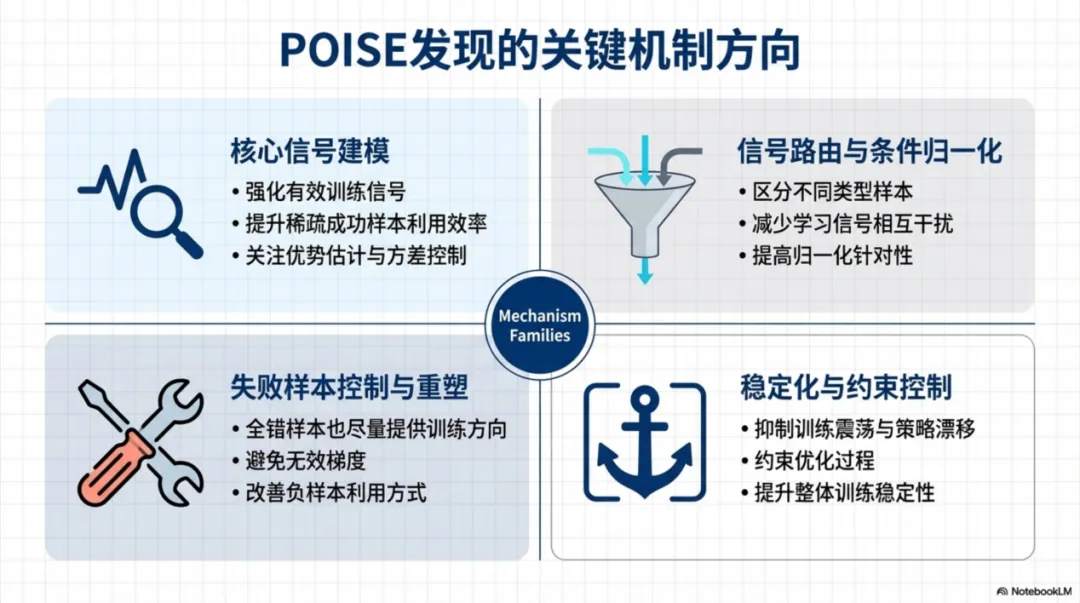
从论文总结来看,POISE 发现的改进并不是单一技巧,而是一类类逐步形成的机制方向。比如,有些改进聚焦于更好地建模有效信号,尽量放大稀疏成功样本在训练中的作用;有些改进关注信号路由和条件归一化,试图把不同类型样本的学习信号分开处理,减少相互干扰;还有一些改进更偏向失败样本控制和训练稳定性,希望在模型“全错”的情况下也能提供有方向的梯度,而不是让训练陷入无效漂移。论文最后提炼出的几个 recurring principles,包括 signal decoupling、conditional normalization 和 correctness-first efficiency shaping,都来自这种跨代演化中的反复验证。
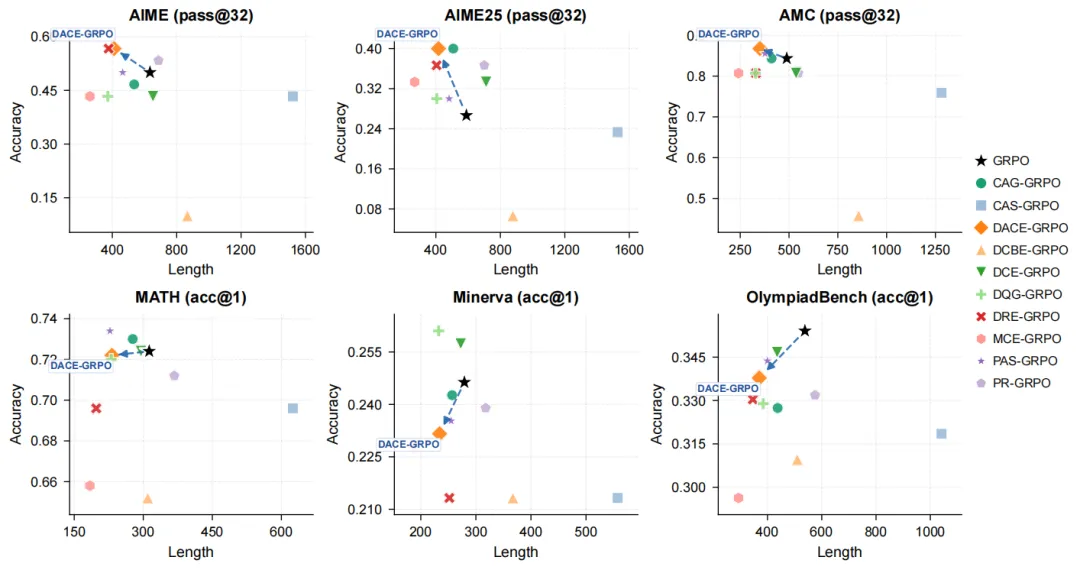
这篇论文里还有一个很值得注意的实验:作者没有只让系统盯着分数做优化,而是额外加入了“压缩回答长度”的目标。结果表明,POISE 不仅能往更高准确率方向搜索,也能在“准确率—长度”之间寻找更合适的平衡。论文结论明确写到,在这种长度压缩设定下,系统进一步展示了自然语言指令可以把搜索过程引导到特定的性能权衡区域中。这个细节很重要,因为它意味着 POISE 不只是一个刷榜工具,它还有可能变成一种更可控的算法设计框架。
三、这项工作的意义与边界
如果只看实验结果,这篇论文当然是在说:我们让大模型自动找到了比 GRPO 更强的一些策略优化变体。但我觉得,它更重要的地方其实不在“多拿了几个点”,而在于它展示了一种新的研究组织方式。过去,算法设计往往依赖研究者个人经验,很多判断留在脑子里,很多失败尝试也不会被系统沉淀下来。POISE 则试图把这些内容组织成一个结构化过程:每个节点都有提案、有实现、有结果、有分析,还有和前代方案之间的谱系关系。这样一来,算法发现就不再只是一次次互相割裂的试错,而更像是一棵可以不断生长的知识树。
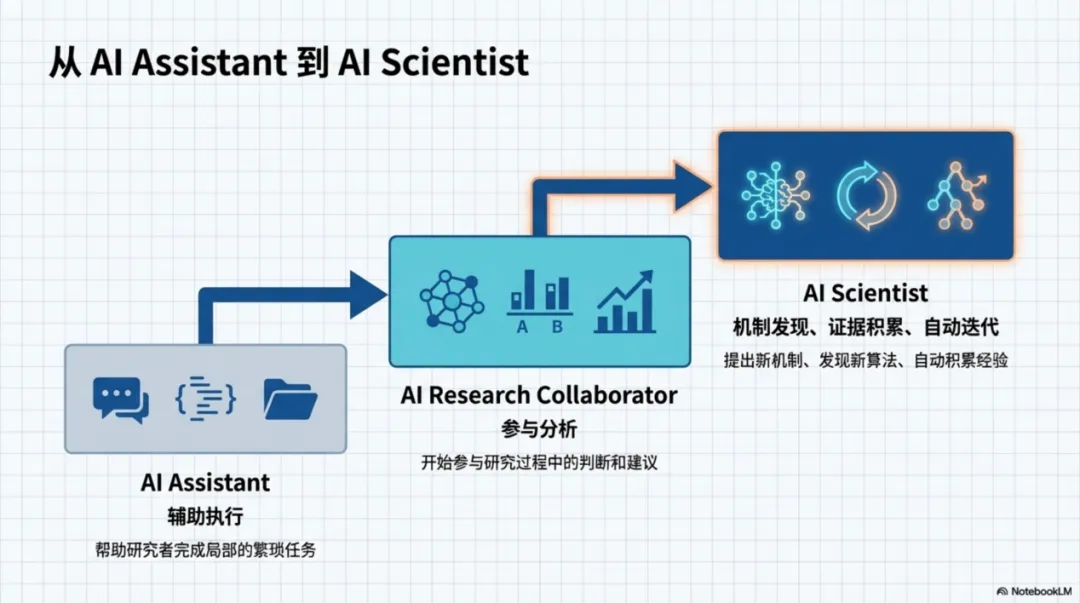
从更大的背景看,这篇论文也很契合近两年“AI Scientist”这条线索。作者在相关工作部分提到,近年来已经出现了不少试图让大模型参与科研流程的系统,它们覆盖了文献分析、程序优化、架构搜索、研究自动化等方向。而 POISE 往前再走了一步:它不是只让大模型帮助研究者完成任务,而是让它直接进入“机制发现”这个更核心的环节。也正因此,这篇论文的意义不只是提出了一个新框架,更是在尝试回答一个更大的问题——在多大程度上,算法创新这件事本身,也可以被部分自动化。
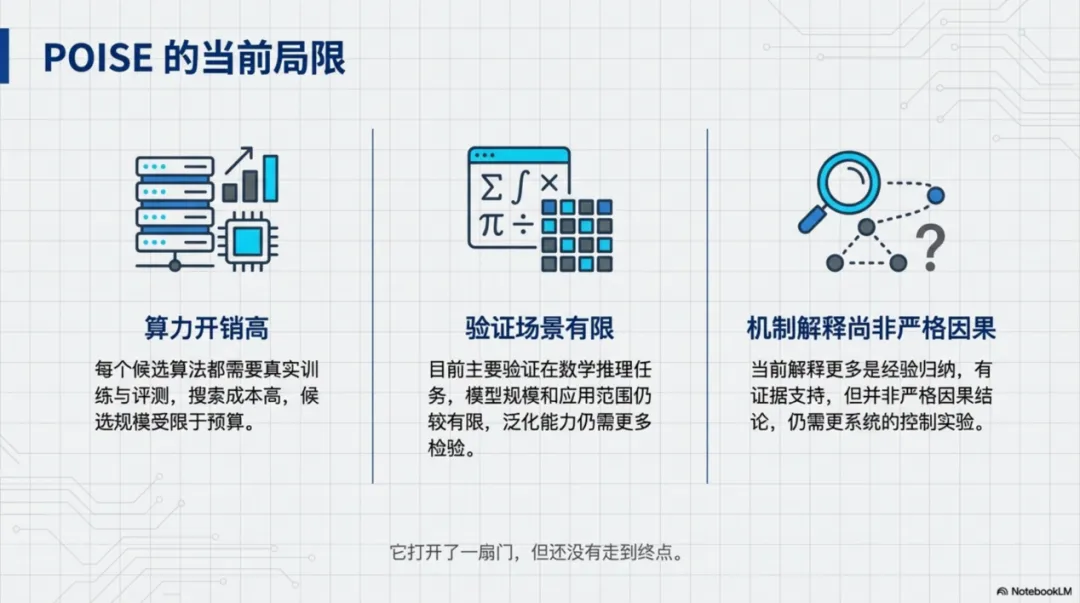
当然,论文也很坦诚地写出了边界。第一,它仍然非常耗算力。因为每个候选算法都要经过完整训练和标准化评测,所以在固定预算下,能探索的候选数量和后续控制实验的规模都会受限制。第二,目前证据主要集中在数学推理任务和较有限的模型设置上,能不能迁移到开放对话、代码生成、工具使用等更广泛场景,还远远没有定论。第三,虽然论文通过谱系分析、训练动态和反思诊断提出了不少机制层面的解释,但这些解释更接近“有证据支持的假说”,还不能算严格的因果确认。作者也明确表示,不应把这些发现视为在所有场景下都普遍安全或最优的方案。
总的来说,我觉得这篇论文最值得关注的地方,是它把“算法研究”这件事从一个高度依赖个人经验的过程,推进成了一个可记录、可比较、可继承、可反思的系统流程。它离真正意义上的“AI科学家”当然还有距离,但至少已经证明:在一个有约束、有反馈、能积累证据的闭环里,大模型确实可以开始承担一部分原本属于研究者的探索工作。对大模型后训练、对强化学习、对自动化科研来说,这都是一个值得继续跟踪的方向。