 夜雨聆风
夜雨聆风





【Java】千万行 Excel 导入数据库?Sheet 上限、EasyExcel、批量与对账
千万行 Excel 导入踩过 3 个坑,OOM、慢、丢数全都中过
业务扔过来一句「这个 Excel 要导进库,一千万行」。大多数人直接开始撸代码,结果第一步就错了:单 Sheet 根本装不下。这篇把 OOM、慢、丢数三个根本原因和对应方案说清楚,不绕弯子。

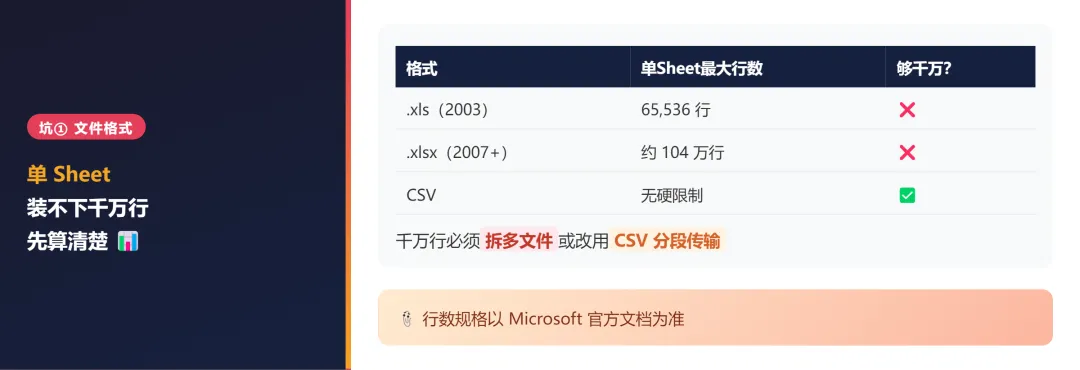
① Sheet 行数天花板——写代码前先算清楚
千万级数据写代码前,先确认文件结构能不能装下。单 Sheet 有硬性上限:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
千万行必须拆多 Sheet或拆多文件,或改用 CSV 分段传输。行数规格以 Microsoft 官方文档 为准。
② 解决 OOM:流式读取,不整表加载
用 POI 一次性把文件读成 List 是 OOM 的直接原因。换 EasyExcel(github.com/alibaba/easyexcel)做流式回调,每攒够一批就落库,堆内存始终可控:
// 每读满 5000 行触发 flush,不把整文件加载进内存EasyExcel.read(filePath, Row.class, new AnalysisEventListener<Row>() { private final List<Row> buf = new ArrayList<>(); @Override public void invoke(Row row, AnalysisContext ctx) { buf.add(row); if (buf.size() >= 5000) { flush(buf); buf.clear(); } } @Override public void doAfterAllAnalysed(AnalysisContext ctx) { if (!buf.isEmpty()) flush(buf); } void flush(List<Row> b) { batchSave(b); } }).sheet().doRead();
百万行内放单 Sheet 问题不大;超千万需拆文件或 CSV,EasyExcel 3.1.1+ 已支持 CSV 读取(以 Release Notes 为准)。

③ 解决慢:批量分片 + 多线程
循环里一条条 INSERT 是性能杀手,每次都触发一次远程 IO。改批量插入,单批用 Guava Lists.partition 切成 1000 条一组再提交(批次大小需压测,过大易超时):
// 先做完业务逻辑,再统一分片写库List<Entity> processed = doBusinessLogic(batch); Lists.partition(processed, 1000) .forEach(sub -> mapper.batchInsert(sub));
业务逻辑复杂、单批处理耗时长时,可用 CompletableFuture 并发处理,但务必显式传入自定义线程池(不传默认 ForkJoinPool,高并发下行为不可控),且线程数不宜过多——上下文切换会反噬 CPU:
// executor 为业务自定义线程池,线程数建议压测后配置化List<Entity> result = new CopyOnWriteArrayList<>(); CompletableFuture.allOf( batch.stream() .map(d -> CompletableFuture .supplyAsync(() -> process(d), executor) .whenComplete((r, ex) -> { if (r != null) result.add(r); })) .toArray(CompletableFuture[]::new) ).join(); mapper.batchInsert(result);
④ 解决丢数:对账 + 唯一索引 + 失败重试
数据量越大,异常越难发现。以下三条缺一不可:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
INSERT IGNORE |
|
⚠️ 高频踩坑:单批超过 5000 条写库容易触发 DB 超时或锁等待;线程数配置太高会导致 CPU 使用率飙升。两个数字都应通过压测确定,而不是凭经验拍。
💡 原生 JDBC addBatch 性能更高: ORM(MyBatis/Hibernate)底层有反射开销。若批量写入成为瓶颈,可评估在关键路径换用 JDBC PreparedStatement.addBatch() / executeBatch(),代价是多写样板代码——要用压测数据说话,而非提前优化。
总结
-
千万级数据先算 Sheet 上限,必须拆文件或改 CSV,再谈读写方案 -
流式读(EasyExcel)+ 分片批量写(Guava partition 1000)+ 自定义线程池并发处理,三板斧缺一不可 -
导入结束必须做条数对账;唯一索引 + INSERT IGNORE 防重复;失败批次打日志记首尾主键