 夜雨聆风
夜雨聆风





Claude Code源码泄露,透过顶级AI产品,窥见了五个AI的核心秘密
全网都在喊:Claude Code源码泄露了!51万行!快去下!
然后呢?
下完了。截图了。发朋友圈了。然后呢?
99%的人看了个寂寞。
因为他们看到的是代码。我看到的是——全球最贵的AI编程产品,到底凭什么好用。
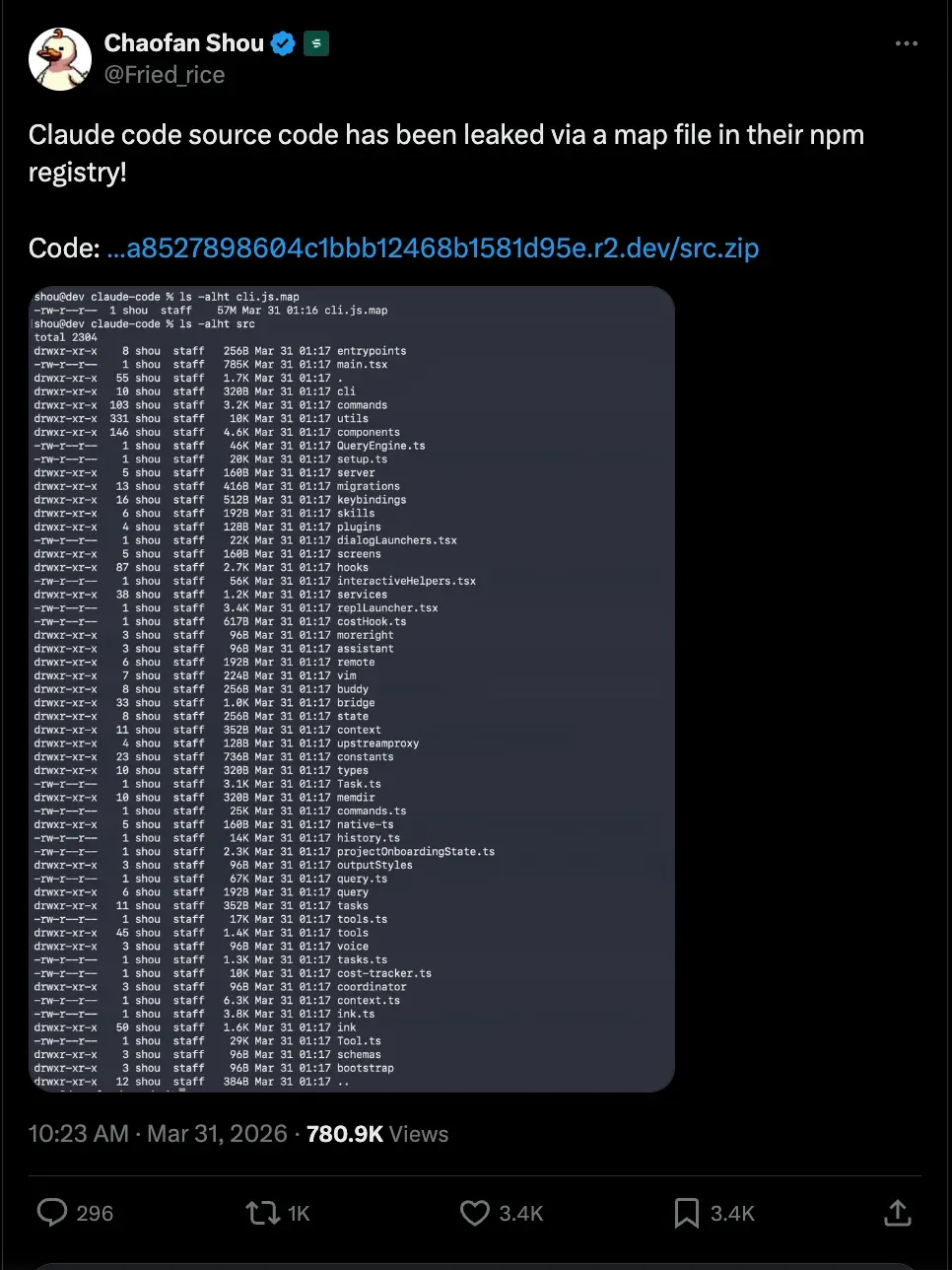
事情很简单。Anthropic的工程师往npm推包的时候,手一抖,把source map文件留在了里面。这个文件能把压缩混淆后的代码还原回源码。相当于把保险箱密码贴在了保险箱门上。
51万行TypeScript,1900多个文件,一夜之间全世界都能看。
半小时,备份仓库星标破5万。开发者们像双十一抢货一样往硬盘里塞。
我花了一整天,把这4756个文件翻了个底朝天。
翻完之后我确认了一个判断——你把Claude Code的prompt原封不动抄走,把它用的工具一个个接上,你照着搭一遍,做出来的东西跟它的差距依然是巨大的。
那个差距藏在哪?藏在prompt怎么组装、工具怎么管、Agent怎么分工、上下文怎么省钱这些你从外面根本看不到的地方。
如果你在做AI产品,或者你想搞明白AI编程工具为什么有的丝滑有的拉胯——接下来这些内容值得你认真看完。
打开src/目录,第一感觉是——这不像一个AI工具,更像一个操作系统。
光顶层模块就有十几个:负责启动的入口层、存放所有提示词的常量库、四十多个工具的定义文件、各种运行时服务、一套完整的命令系统、终端UI组件、多Agent协调器、独立的记忆模块、插件框架、Hook拦截器、初始化引导、任务管理器。
启动入口就有四个——命令行模式、初始化向导、MCP协议模式、SDK编程接口。一套内核,四张脸。普通的AI编程工具有个main.js就不错了,这边直接上了平台架构。
命令系统注册了十几个斜杠命令:/mcp管协议连接、/memory管记忆、/permissions管权限、/hooks管拦截器、/plugin管插件、/skills管技能包、/tasks管任务、/plan做规划、/review做审查。而且这套命令系统不光跑自己的指令,还统一接管了所有插件和技能包注册进来的命令。
你平时用的那些开源coding agent,一般就一个入口文件加几个工具。Claude Code跟它们完全不在一个世界。
秘密一:Prompt是活的,不是死的
这是我翻源码时最意外的发现。
你以为prompt就是一段写好的长文本对吧?写完塞进去,模型照着干。
Claude Code的prompt是一个函数现场拼出来的。每次对话开始,这个函数会像流水线一样,先把固定零件装上,再根据你当前的状态加装可选零件。
固定零件有七个——
一个管身份:你是谁,你叫什么,你的能力边界在哪。一个管系统规则:什么环境,什么限制。一个管做事原则:什么该做什么不该碰。一个管风险意识:哪些操作必须停下来问人。一个管工具纪律:每个工具什么时候用、怎么用。一个管说话的调子:什么语气,什么风格。一个管输出效率:别废话,直奔重点。
可变零件有十一个——
当前会话的特殊指引、用户的记忆偏好、运行环境信息、语言设置、输出格式、连接着的MCP服务说明、临时草稿板、历史结果清理策略、工具输出摘要策略、token额度、简洁模式开关。
这两组零件之间有一条明确的分界线。源码里给这条线起了个名字,大意是”动态边界”。分界线以上的内容每次都一样,API可以把这部分缓存起来,不用每次都重新算token。分界线以下的内容每次都不一样,单独计算。
这个设计解决的是钱的问题。
当你的产品一天跑几十万次对话,prompt开头那几千个token如果能命中缓存,一个月下来省的算力费是真金白银。普通人写prompt只想”怎么让AI听话”,Anthropic写prompt的时候已经在算”这段话值多少钱”了。
秘密二:AI不自律,就给它立规矩
你肯定有过这种经历——让AI帮你改一个函数,它把整个文件给你翻新了。让它加个按钮,它造了一套组件库。让它确认代码能跑,它拍着胸脯说”没问题”,但你一跑就崩。
为什么会这样?因为没人告诉它”这些事不能干”。
Claude Code源码里有一整个模块,专门干这件事——给AI立规矩。
这些规矩写得极其具体:
别人没让你加的功能,不准加。代码能用三行写完的,不准搞一层抽象。已有的代码没让你重构就别碰。文件能改就改,别动不动新建一个。注释和文档没让你写就别写。错误处理不需要面面俱到,真正会出问题的地方才加。方法跑不通的时候先查原因,别急着换方案。确认没用的东西直接删干净,不要留一堆注释掉的废代码。最重要的一条——结果必须诚实,没跑过测试就不准说测试通过了。
另一组规矩管的是”什么操作必须停下来问人”。分了五档:
第一档,后果不可逆的操作——删文件、删分支、清数据库、杀进程。第二档,很难撤回的操作——强推代码、重置commit历史、改已经发出去的提交。第三档,别人能看到的操作——推代码、开关PR、发issue评论。第四档,对外发消息——发邮件、发Slack、发GitHub通知。第五档,往第三方上传内容。
碰到这五档里的任何一个,必须先告诉用户你要干什么,等确认了再动手。
还有一组管工具使用的铁律:要读文件必须走专用的读取工具,不准用shell命令cat去读。要改代码必须走专用的编辑工具,不准用sed这种文本替换去改。要搜代码必须走专用搜索工具,不准调shell的grep。只有真正需要跑shell命令的场景才准用命令行。多个工具之间没有先后依赖的,必须同时调,不准一个个排队。
为什么管这么细?因为一个AI用sed改代码,正则写错了就是灾难。 用专用编辑工具改,至少有输入校验和回滚机制。工具选错比逻辑错更致命,所以必须从源头卡死。
秘密三:六个角色各管各的,找茬的那个最狠
Claude Code内部不是一个AI在干所有的事。它养了六个不同的角色,每个角色有自己的能力边界和行事风格。
探索型角色——只准看,碰都不准碰。
这个角色存在的唯一目的就是帮你搞清楚代码库是什么情况。它能读文件、能搜索、能看git记录。但它不能写任何东西。不能改文件,不能建文件,不能删文件,连shell里的输出重定向都被禁了。
为什么要这么极端?因为”先调查清楚再动手”这个原则,如果你不在权限层面卡死,AI一边查一边就顺手改了。改完之后再去实现的时候,你都不知道它已经偷偷动过了。权限隔离是最朴素但最管用的保险。
规划型角色——只准想,不准动手。
这个角色负责理解你的需求、梳理代码架构、拆解实施步骤、标出关键文件。它被设定成建筑师,不是施工队。
把规划和实施拆开的好处是——想的时候不会被”赶紧写代码”的冲动带偏。很多AI编程工具出问题就出在这:还没想清楚就开始写,写到一半发现路不通,推倒重来。
验证型角色——这个最值得细说。
这个角色的工作不是”看看还行不行”。它的工作目标用三个字概括:找毛病。
它的行动指南开头就点了两种常见的偷懒行为。第一种:光看代码不实际跑一遍,觉得逻辑没问题就直接盖章通过。第二种:前面80%看着挺好,就自动忽略剩下20%的隐患。
然后给了一份强制执行的检查清单:
代码写完必须编译。编译过了必须跑测试。测试过了必须跑代码风格检查和类型检查。改了前端界面的,必须验证页面能正常渲染和交互。改了后端接口的,必须用真实请求打一遍看返回对不对。改了命令行工具的,必须检查输出内容、错误输出和退出码。动了数据库的,必须验证升级和回滚都能跑通,还要拿已有数据测一遍。重构过的代码,必须确认对外暴露的接口没有变化。
做完这些还不够。还要求主动去构造刁钻的测试场景——边界值、异常输入、极端组合,想办法把代码搞崩。每一项检查都要附上实际执行的命令和真实的输出结果。
最后给结论只有三个选项:通过、不通过、部分通过。没有”差不多行了”这个选项。
为什么一定要用单独的角色来干这件事? 因为写代码的那个AI天然觉得自己写的没问题——它刚写完,它对自己的代码有感情。让它自己验自己,就像让厨师品尝自己做的菜,永远觉得味道刚好。必须换一个没有感情包袱的角色来找茬,才找得出真问题。
这个”干活的人和验收的人必须分开”的道理,搞工程的人都懂。但你去看看市面上的AI编程产品,几乎全是一个AI从头干到尾,写完自己说”搞定了”。
秘密四:调工具不是一句话的事,中间有14道关卡
AI说”我要读一下这个文件”,在Claude Code里面不是直接就读了。中间要过一条长长的流水线:
执行前的9道关卡: 先确认这个工具存在、解析它的协议信息、校验AI传过来的参数格式对不对、跑工具自带的输入检查、如果是要执行shell命令还要先做一次风险预判、然后触发所有预处理拦截器、分析拦截器的反馈来决定权限、走正式的权限判定流程、根据判定结果可能还要修正输入参数。
到了第10步,工具才真正执行。
执行后的4道关卡: 记录这次调用的数据用于分析和追踪、触发所有后处理拦截器、整理输出格式、如果执行失败了还有专门的失败处理拦截器。
这套拦截器机制特别值得说。
执行前的拦截器不只是个旁观者。它能干这些事:直接改写AI传过来的参数、直接放行或者直接拒绝这次调用、中断整个后续流程、往上下文里补充额外信息。
但它的权力也有天花板。有一条硬规则:拦截器说”放行”,不一定真能绕过系统设置里的拒绝规则。但拦截器说”拒绝”,那就是一票否决,立刻生效。
能放权但不能越权。 这个分寸感是整套系统工程水平的缩影。
执行后的拦截器也不是走过场。成功了可以追加信息、更新输出、甚至叫停后面的操作。失败了可以补充失败原因、给出恢复建议、通知用户下一步怎么办。
这14步背后的逻辑就一条:它从设计上就假定每一步都可能出问题。 参数可能是乱的、操作可能是危险的、执行可能会崩、成功了也可能需要善后。把所有”可能翻车”的地方都提前安排好应对方案,系统才经得起真实场景的摔打。
秘密五:上下文窗口是账本,每个token都要精打细算
这个发现贯穿了整个源码,不是某一个模块,而是一种渗透到每个角落的思维方式。
prompt拼装那条分界线—— 固定内容放前面可以缓存,变化内容放后面单独算。省的是重复计算的钱。
子任务继承主线程的上下文—— 不是为了方便,是为了让API请求的开头部分跟主线程保持一模一样,这样缓存可以复用。普通人创建子任务想的是”能跑就行”,这边想的是”能跑,而且不多花一分钱”。
技能包按需装载—— 你这次用不到的技能,它的说明不会占你的上下文空间。MCP服务也一样,没连上的服务不会把使用说明塞进来。
历史对话有压缩和裁剪机制—— 太早的对话内容会被摘要压缩,工具返回的大段结果会被精简。
还有一套完整的会话恢复机制—— 上下文快满的时候不是直接崩掉,而是保存关键状态后重新开一轮。
所有这些机制在干同一件事:在有限的上下文窗口里,装尽可能有用的信息,扔掉所有冗余,让每一个token都花在刀刃上。
一个子Agent从被创建到执行完毕,背后的状态管理也是个大工程——初始化专属的协议连接、过滤和复制上下文、处理文件缓存、给只读角色做内容瘦身、配置权限、组装工具集、注册拦截器、预加载技能包、创建中断控制器。跑完之后还要记录日志、清理协议连接、清理拦截器、清理性能追踪、清理后台任务。
一个子Agent的启停流程,复杂程度已经赶上了一个微服务的生命周期管理。
这也是为什么我说Claude Code更像一个运行平台,而不是一个接了API的聊天窗口。
额外的发现:给子任务写指令也有规矩
源码里有一段专门教主AI怎么给子Agent下达任务,这段规则特别有意思。
核心意思是:子Agent是一个新人,什么背景都不知道,你得像给新同事做入职培训一样把事情交代清楚。
具体要求:说清楚目标是什么、为什么要做这件事、你已经试过什么方案排除了、给够背景信息让它能独立判断、如果只需要一个简短答案就明说。
特别禁止的行为:不准把”理解需求”这件事甩给子Agent去猜、不准写”根据你的发现去修bug”这种模糊指令、必须给出具体的文件路径、代码行号、明确的修改要求。
这条规矩在防什么?防主AI偷懒。
多Agent系统最常见的翻车方式:主AI不想思考,把一个没想清楚的任务丢出去,子Agent理解错了,做出来的东西不对,主AI拿到结果也不知道问题在哪。一来一回,时间全浪费了。
强制要求主AI”想清楚了再分配”,看着增加了它的负担,但实际上砍掉了大量返工。
还有三套扩展系统
Claude Code能接外部能力进来,有三种方式,层层递进。
第一层叫技能包。 不是普通文档,是一个打包好的工作流。它用markdown写成,但带着元数据标记,能声明自己需要哪些工具、在什么场景下被触发。相当于把”遇到这类问题按这个步骤处理”封装成了可复用的能力单元。
第二层叫插件。 比技能包重得多。它能注册自己的命令、提供自己的技能包目录、带配置界面、声明自己需要什么模型和资源、控制自己能不能被AI主动调用。这不是CLI意义上的插件,这是在模型的行为层面做扩展。
第三层是MCP协议。 外部服务通过这个协议接进来,不光能提供新工具,还能附带使用说明。这些说明会被自动拼进prompt里,让AI知道”我现在多了一个什么能力、什么时候该用”。
这三层有一个共同的设计理念:光把能力挂上去没用,必须让AI知道它多了什么能力、什么时候该用、怎么用。
很多平台也有插件市场,但AI压根不知道这些插件存在。就像你给一个人配了一整柜子的专业工具,但他不知道柜子在哪,更不知道里面有什么。
彩蛋:没发布的隐藏功能
翻代码的时候还挖出一批没上线的功能,按成熟度分了几档。

快要出来的大招
Kairos ——一个能一直在后台活着的守护进程。它不需要你打开终端才工作。它能接消息推送、监听代码仓库的变化、跟日历和webhook联动。相当于Claude不再是”你叫它才来”,而是”它一直在旁边盯着,有事自己处理”。
多Agent协调模式 ——一个Claude当指挥官,派出多个Claude当工人,每个工人手里的工具还不一样。并行干活。
语音模式 ——用嘴跟Claude Code说话,有单独的入口。
定时任务触发器 ——可以设定时间让Agent自动执行任务,也支持外部事件触发。
正在做的
真正的浏览器控制(不是网页抓取,是Playwright级别的操控)、预制的多步自动化脚本、Agent自己能sleep然后自动醒来继续干、SSH远程连接和直连协议、资源监控自动触发、增强版规划(规划完自动验证计划可行性)。
基础设施层
三种上下文压缩策略、精确裁剪历史对话的特定片段、跨会话保存Agent记忆、根据会话行为自动推断权限级别。
最有争议的
卧底模式 ——当Anthropic自己的工程师在公开代码仓库里用Claude Code的时候,系统会自动把git提交记录里的AI痕迹全部擦干净。而且这个模式不能手动关掉。
还有一个——工程师们在写这套几十亿美金产品的核心代码时,顺手塞了一个电子宠物系统。18个物种,分稀有度等级,还有闪光变体和属性面板。在造AI编程界的航母的同时,养了只拓麻歌子。
我的五个收获
翻完4756个文件,我把最值钱的东西浓缩成五句话:
第一,不要相信AI会自觉。 你希望它做到的行为,就白纸黑字写成规矩。靠模型自己悟,它悟不出来。
第二,干活的和验收的必须分开。 一个AI写完代码自己说”没问题”,跟学生自己给自己改卷子没区别。让另一个角色来查,而且这个角色的唯一职责就是找毛病。
第三,工具不是给了就完了,得管起来。 AI调工具不能直通,中间要有参数检查、风险判断、权限审批、失败善后。这条管道决定了系统在正常情况下好不好用,在出问题的时候崩不崩。
第四,上下文是钱,不是空气。 能缓存的部分绝不重复算,用不到的信息绝不提前塞,历史对话该压缩就压缩。你的产品跑几万次之后,这些细节的差距是天文数字。
第五,AI必须知道自己兜里有什么。 你给它接了十个插件、五个技能包、三个外部服务,但如果AI不知道这些东西存在,不知道什么时候该用哪个,那它们就等于不存在。让AI”看到”自己的能力清单,是整个生态能不能转起来的前提。
这五条不只管AI编程工具。任何拿大模型做复杂事情的产品,都绕不开这五个问题。
51万行代码被扒了个精光。大多数人看到了电子宠物和卧底模式。
但真正值钱的发现是这个——
AI产品的差距,从来不在模型聪不聪明。在模型背后的系统结不结实。
同样的模型,同样的prompt,做出来天差地别。差的那部分,全是工程。
Prompt是皮肤。工程是骨架。这51万行代码,就是骨架的X光片。