 夜雨聆风
夜雨聆风





Claude Code源码被"开源",重视网络安全的Anthropic为何屡次犯这种低级错误?
3月31号,又出事了。
Anthropic的Claude Code,整个源码泄露了。
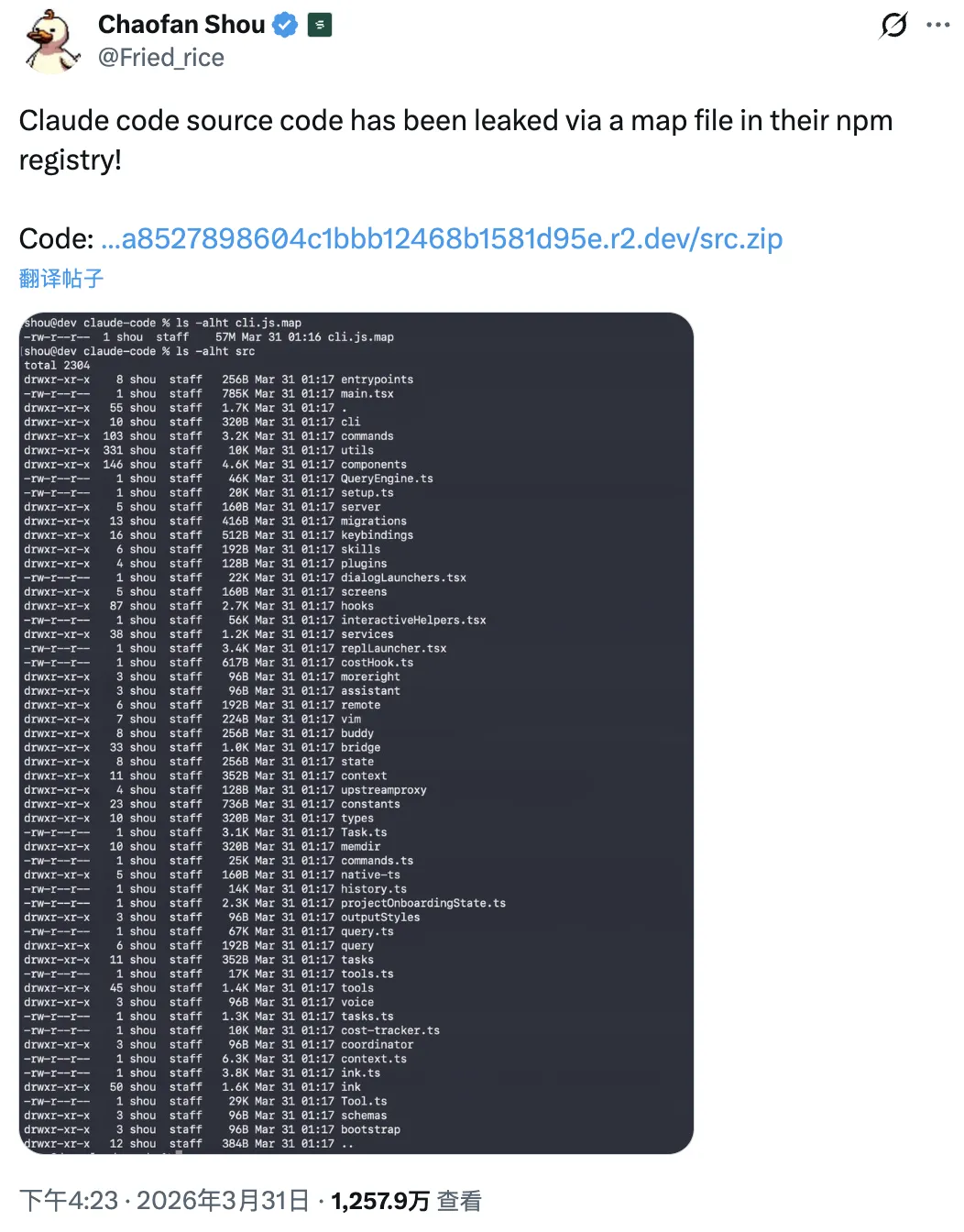
51.2万行TypeScript代码,近2000个文件,60MB的源码映射文件,就这么明晃晃地躺在npm包里,任何人都能下载。
安全研究员Chaofan Shou发现这个问题的时候,估计都懵了。
因为这不是Anthropic第一次犯这种低级错误了。
就在5天前,3月26号,Anthropic刚刚因为CMS配置错误,泄露了近3000个内部文件,包括一个还没发布的超级模型Claude Mythos的完整资料。
一周之内,两次重大泄露。
而且都是最低级的人为失误。
一个是忘了关CMS的公开访问权限,一个是打包的时候把源码映射文件一起发布了。
这要是发生在一家普通的创业公司身上,二叔可能也就笑笑过去了。
但问题是,这是Anthropic。
一家把”AI安全”写进公司使命的公司,一家因为”对OpenAI的安全理念不满”而从OpenAI分裂出来的公司,一家制定了业内最严格的”负责任扩展政策”的公司。
结果现在,连自己的源码都保护不好。
这事儿,二叔觉得值得好好聊聊。
不是为了嘲讽Anthropic,而是因为这背后,暴露了一个很多AI公司都在面临的矛盾。
就是,你把所有精力都花在研究”AI会不会失控”上了,结果自己家的门都忘了锁。
二叔今天就花10分钟时间,跟你拆解一下这件事。
也希望,能对你理解AI公司的真实处境有点帮助。
一. 这次泄露到底有多严重
先说这次源码泄露本身。
3月31号,Anthropic发布了Claude Code的2.1.88版本,这是一个npm包,开发者可以通过npm安装来使用Claude Code的命令行工具。
但这个版本里,包含了一个59.8MB的JavaScript源码映射文件(cli.js.map)。
什么是源码映射文件?
二叔给你打个比方。
你写了一封信,为了防止别人看懂,你把每个字都换成了密码。但你自己要能看懂,所以你留了一个”密码本”,记录着每个密码对应的原文。
源码映射文件,就是这个”密码本”。
现代前端开发,代码都会被压缩、混淆、打包,变成人类看不懂的一坨。但开发者自己调试的时候,需要看到原始代码,所以就有了源码映射文件。
正常情况下,这个文件只应该在开发环境使用,绝对不应该发布到生产环境。
但Anthropic这次,把它一起打包发布了。
结果就是,任何人下载这个npm包,解压源码映射文件,就能还原出Claude Code的完整源码。
51.2万行TypeScript代码,近2000个文件,包括:
-
LLM API调用的核心引擎 -
流式响应处理逻辑 -
工具调用循环机制 -
思考模式(Thinking Mode)的实现 -
重试逻辑和token计数 -
权限模型 -
所有内置工具的代码
甚至,还有一些未发布的功能,比如:
-
Buddy系统(AI宠物,有18种物种和稀有度) -
Kairos模式(24小时在线的主动助手) -
Auto-Dream(后台自动整理记忆的”做梦”功能) -
Daemon模式(后台守护进程) -
Teleport(跨机器传送工作会话) -
Ultraplan和Ultrareview(云端多Agent协作)
这些功能,本来应该是Anthropic的产品路线图,现在全暴露了。
更有意思的是,有Hacker News的用户发现,源码里有一个超长的正则表达式,专门用来检测用户输入里的脏话和负面情绪。
这个正则表达式里,包含了几百个脏话和攻击性词汇。
Anthropic的回应很快,发言人Christopher Nulty说:”这是一个发布打包问题,由人为失误导致,不是安全漏洞。没有敏感的客户数据或凭证被泄露。”
但二叔觉得,这个回应有点避重就轻。
是,客户数据没泄露,但你的核心产品逻辑、未发布功能、技术架构,全泄露了。
这对一家科技公司来说,杀伤力不比客户数据泄露小。
二. 5天前的那次泄露,可能更严重
但这次源码泄露,还不是最严重的。
更严重的,是5天前的那次CMS泄露。
3月26号,安全研究员Roy Paz(LayerX Security)和Alexandre Pauwels(剑桥大学)发现,Anthropic的内容管理系统(CMS)配置错误,导致近3000个内部文件可以被公开访问。
这些文件里,包括一篇还没发布的博客草稿,详细介绍了一个代号为”Mythos”(内部也叫”Capybara”)的超级模型。
根据泄露的文档,Mythos是Anthropic有史以来最强大的模型,定位在Opus之上,是一个全新的能力层级。
和Claude Opus 4.6相比,Mythos在编程、学术推理、网络安全等测试中,得分”显著更高”(dramatically higher)。
Anthropic自己的描述是,这是一个”阶跃式变化”(step change)。
但更关键的是,泄露的文档里还提到,Mythos在网络安全能力上的提升,可能带来”前所未有的网络安全风险”。
这句话,让整个网络安全行业都炸了。
为什么?
因为这意味着,Mythos可能具备自动化发现和利用漏洞的能力,而且这个能力强到Anthropic自己都觉得有风险。
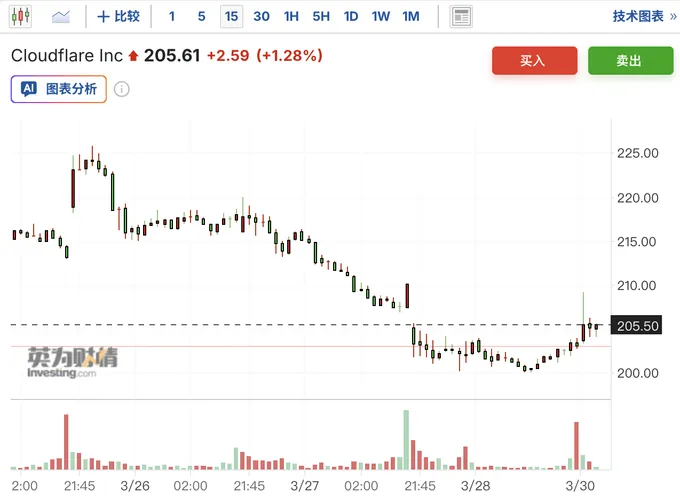
泄露发生后的第二天,3月27号,网络安全相关的股票集体暴跌。
市场担心什么?
担心如果这种级别的AI模型被滥用,现有的网络安全防御体系可能会被降维打击。
Anthropic的回应是,这是”CMS配置的人为失误”,泄露的是”考虑发布的早期草稿”。
但问题是,这些”早期草稿”,包含了Anthropic最核心的产品战略和技术细节。
而且,Mythos现在已经在早期测试阶段了,这不是一个遥远的概念,是一个即将发布的产品。
三. 这已经是第三次了
更让人无语的是,这已经不是Anthropic第一次犯这种错误了。
据Axios报道,Claude Code的源码泄露,是”一年多以来的第二次”。
也就是说,在2025年的某个时候,Claude Code的源码就泄露过一次。
加上这次的CMS泄露和源码泄露,一年多时间里,Anthropic至少发生了三次重大的信息泄露事件。
而且,每一次的原因都是最低级的人为失误。
-
第一次:具体原因不详,但也是源码泄露 -
第二次(3月26日):CMS配置错误,忘了关公开访问权限 -
第三次(3月31日):打包时忘了排除源码映射文件
这三个错误,放在任何一家有基本安全意识的公司,都不应该发生。
CMS配置错误?
这是运维的基本功。
二叔以前做设计的时候,公司的运维工程师,每次上线新系统,第一件事就是检查权限配置。
有个checklist,一项一项勾,勾完了才敢上线。
源码映射文件打包进生产环境?
这是前端工程师的基本常识。
二叔见过一个前端团队,他们的打包脚本里,专门有一行配置,就是排除所有.map文件。
这是写在新人培训手册里的。
但Anthropic,一家把”AI安全”作为核心使命的公司,一家制定了业内最严格的”负责任扩展政策”的公司,却在这些基础安全问题上,屡次翻车。
这就很讽刺了。
四. 当你盯着AI安全的时候,谁在盯着你的安全
二叔觉得,这背后暴露的问题,比泄露本身更值得关注。
就是,Anthropic可能陷入了一个”灯下黑”的困境。
什么意思?
Anthropic的创始团队,是从OpenAI分裂出来的。
分裂的原因,就是他们觉得OpenAI在AI安全上不够重视,太激进了。
所以Anthropic成立的时候,就把”AI安全”作为核心使命,制定了业内最严格的”负责任扩展政策”(Responsible Scaling Policy,简称RSP)。
这个政策的核心是,如果AI模型的能力超过了安全措施,Anthropic会暂停训练,直到安全措施跟上。
这在当时,是一个非常激进的承诺。
因为这意味着,Anthropic可能会因为安全问题,主动放慢产品迭代速度,甚至暂停新模型的发布。
但问题是,AI行业的竞争太激烈了。
OpenAI、Google、Meta,都在疯狂推进。
Anthropic如果真的严格执行RSP,就会在竞争中落后。
所以,2026年2月24号,Anthropic更新了RSP 3.0版本。
新版本最大的变化是,取消了”硬性暂停”的承诺,改成了更灵活的”前沿安全路线图”(Frontier Safety Roadmap)。
翻译成人话就是,以前是”做不到就不做”,现在是”边做边看”。
这个变化,在AI安全社区引发了巨大争议。
很多人觉得,Anthropic在商业压力下,放弃了自己的核心原则。
但二叔觉得,这个变化本身不是问题。
真正的问题是,Anthropic把所有精力都花在研究”AI会不会失控”上了,结果自己家的门都忘了锁。
我自己以前做设计的时候,见过类似的情况。
有些团队,天天开会讨论用户体验、交互细节、视觉规范,结果网站上线第一天,服务器就挂了。
为什么?
因为团队里全是设计师和前端工程师,没人管后端和运维。
Anthropic也是一样。
他们的团队,大部分是AI研究员、机器学习工程师、AI安全专家。
这些人的专长,是研究AI模型的对齐问题、越狱攻击、提示注入、模型滥用。
但CMS配置?npm打包?源码映射文件管理?
这些基础的工程安全问题,可能根本不在他们的雷达范围内。
结果就是,Anthropic在AI安全上做得很好,但在基础安全上,反而漏洞百出。
就像一个武林高手,天天研究如何防御绝世武功,结果被人从背后捅了一刀。
因为他忘了锁门。
五. 这不只是Anthropic的问题
但二叔觉得,这个问题不只是Anthropic的。
整个AI行业,都在面临类似的困境。
因为AI公司的核心竞争力,是模型能力、算法创新、产品体验。
基础安全?那是”传统IT”的事情。
二叔见过不少AI创业公司,团队里全是机器学习PhD、算法工程师、AI研究员。
这些人能把Transformer架构倒背如流,能用PyTorch写出各种花式模型,能在论文里讨论对齐问题、RLHF、Constitutional AI。
但你问他们npm包怎么配置.gitignore?
他们可能都不知道.gitignore是干嘛的。
我自己以前做设计的时候,见过类似的情况。
有个创业团队,产品设计得特别漂亮,交互体验也很好,拿了好几个设计奖。
结果上线第一天,网站就被黑了。
为什么?
因为他们用的是一个开源CMS,默认管理员密码是admin/admin,他们忘了改。
这种事情,在传统互联网公司,是不可能发生的。
因为传统互联网公司,有完整的安全团队、运维团队、测试团队。
有checklist,有流程,有code review,有安全审计。
但AI公司不一样。
AI公司的核心资产,是模型和数据。
他们的安全投入,主要在模型安全、数据安全、API安全。
至于CMS配置、npm打包、源码映射文件?
这些”传统IT”的基础安全问题,可能根本没人管。
或者说,管的人不够senior,话语权不够。
结果就是,AI公司在模型安全上投入巨大,但在基础安全上,反而成了短板。
这就像一个人,花了一百万买了最先进的防盗门,结果窗户忘了关。
六. 我们能从中学到什么
那这件事,对我们普通人有什么启发?
二叔觉得,至少有三点。
第一,不要迷信”AI安全公司”。
Anthropic把”AI安全”作为核心使命,但这不代表它在所有安全问题上都做得好。
AI安全和基础安全,是两回事。
一个公司可以在AI对齐问题上做得很好,但在CMS配置、npm打包这些基础问题上,照样会犯低级错误。
所以,当你选择AI服务的时候,不要只看它的AI安全承诺,也要看它的基础安全能力。
第二,专业化是把双刃剑。
Anthropic的团队,都是AI领域的顶尖专家。
但正因为太专业,他们可能会忽略一些”常识性”的基础问题。
这在任何行业都一样。
二叔以前做设计的时候,见过一些设计师,天天研究最新的设计趋势、交互模式、视觉风格。
结果做出来的东西,连基本的可用性都没有。
为什么?
因为他们太关注”高级”的东西,反而忘了”基础”的东西。
所以,不管你做什么,都要记住:基础永远比高级重要。
第三,快速迭代的代价。
AI行业的竞争太激烈了,大家都在拼速度。
Anthropic一周之内发生两次泄露,很可能就是因为太赶了。
赶着发布新功能,赶着上线新模型,赶着对标竞争对手。
结果,基础的安全检查就被跳过了。
这在创业公司很常见。
但问题是,有些东西,是不能跳过的。
CMS配置、npm打包、源码映射文件,这些都是基础中的基础。
跳过这些,就是在给自己埋雷。
收尾
说回Anthropic。
一周之内,两次重大泄露,这对任何一家公司来说,都是一个警钟。
但二叔觉得,这也是一个机会。
机会让Anthropic,也让整个AI行业,重新审视一下:
当我们把所有精力都花在研究”AI会不会失控”的时候,我们自己的基础安全,是不是被忽略了?
当我们制定了最严格的”负责任扩展政策”的时候,我们自己的CMS配置、npm打包,是不是也应该有一个checklist?
当我们在AI安全上投入巨大的时候,我们的基础安全团队,是不是也应该得到足够的重视和资源?
AI安全很重要。
但基础安全,同样重要。
因为,再先进的AI模型,也需要一个安全的基础设施来承载。
再严格的安全政策,也需要一个可靠的工程团队来执行。
否则,就像一个武林高手,天天研究如何防御绝世武功,结果被人从背后捅了一刀。
因为他忘了锁门。
希望Anthropic能从这两次泄露中吸取教训。
也希望整个AI行业,能重新审视基础安全的重要性。
毕竟,AI的未来,不只取决于模型有多强大,也取决于基础有多牢固。
和二叔一起思考:你觉得AI公司应该如何平衡AI安全和基础安全?欢迎在评论区告诉二叔你的看法。