 夜雨聆风
夜雨聆风





Claude Code 51万行源码泄露,我从里面看到了 AI 编程的真实水位
最近有个事挺炸的:Anthropic 的 Claude Code,整个源码被人从 npm 包里扒了出来。
不是黑客攻击,不是内鬼泄密。就是打包的时候忘了删 source map 文件。一个 60MB 的 cli.map,静静躺在 npm 仓库里,谁都能下载。安全研究员 Chaofan Shou 发现之后发了条推,然后整个技术圈都炸了。
51万行代码,将近 1900 个文件。这可能是目前为止,我们能看到的最完整的工业级 AI Coding Agent 内部实现。
大家在讨论什么
泄露之后,技术社区的反应基本分两派。
一派在嘲笑 Anthropic。堂堂 AI 安全公司,连自己的代码都保护不好,source map 这种低级错误都能犯。Anthropic 官方回应说是”人为失误导致的发布打包问题”,已经修复。
另一派在疯狂拆解源码。掘金上一天冒出来七八篇分析文章,GitHub 上有人把反混淆后的代码整理成了可浏览的仓库。
但我觉得这两个角度都太表面了。
打包失误这种事,哪个团队没干过?重点不在于怎么泄的,在于泄出来的东西告诉了我们什么。

源码里藏着的反蒸馏陷阱
最让我意外的发现是 Claude Code 里埋了一套”假工具”系统。
什么意思呢?代码里定义了一批看起来像正常功能的工具接口,但实际上是陷阱。如果有人试图用这些接口来训练自己的模型(也就是所谓的”蒸馏”),生成的数据会带上特定的指纹,Anthropic 就能追踪到。
这招挺狠的。
等于说 Anthropic 在产品里预埋了反盗版机制,而且不是简单的水印,是功能层面的诱饵。你以为你在学它的能力,其实你在给自己埋雷。
还有一个”挫败检测”机制。代码里有一组正则表达式,专门匹配用户的负面情绪——比如反复报错、表达不满、要求重试。一旦触发,系统会切换到更保守的响应策略。
说白了,Claude Code 在实时监测你的情绪状态。

真正值钱的是架构设计
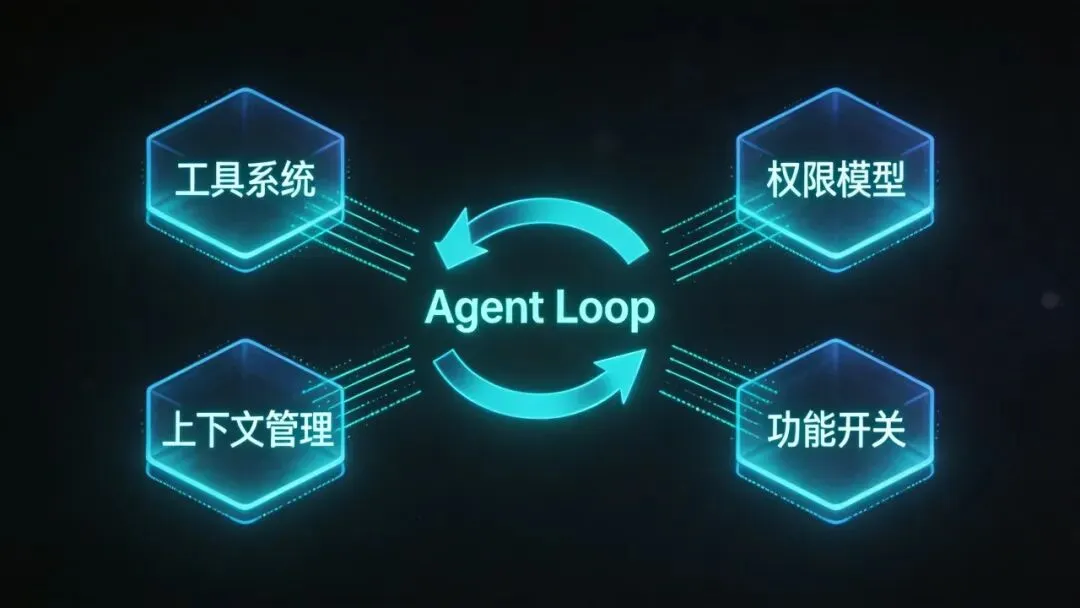
假工具和情绪检测是花边新闻,真正值得看的是 Claude Code 的整体架构。
核心是一个 Agent Loop。接收用户指令,模型决定调用哪个工具,执行完拿到结果,再决定下一步。循环一直转,直到任务完成或者触发退出条件。听起来简单,但细节全在循环里面。
工具系统是模块化的。每个工具独立注册,统一的输入输出格式,加新工具不用改核心逻辑。这个设计在开源 Agent 框架里不多见。
权限模型分了好几层。自动放行的、需要用户点确认的、直接禁止的。大多数开源方案要么全放开要么全锁死,Claude Code 按风险等级做了分级,这个思路比较成熟。
上下文管理是我觉得最有意思的部分。它会在接近 token 上限时自动压缩历史对话做摘要,还有个”自愈记忆”机制,上下文被截断后能恢复关键状态。长对话场景下,这个能力直接决定了 Agent 能不能干完一个复杂任务。
另外代码里有 44 个 feature flag。我们看到的只是 Claude Code 的一部分,后面还藏着不少没开放的实验功能。
对普通开发者意味着什么
如果你在做 AI Agent 相关的开发,这次泄露其实是一份免费的架构参考。
我自己从里面学到了几个东西。
工具注册机制值得抄。别把工具调用写死在主循环里,用注册表模式。Claude Code 证明了这套模式在生产环境跑得通,扩展起来也干净。
权限分级这个我之前一直偷懒没做。看了 Claude Code 的实现才意识到,按风险等级把操作分成自动执行、需确认、直接禁止三档,用户体验和安全性确实能同时照顾到。
上下文压缩的时机选择也有讲究。不是等到 token 爆了才压缩,而是在接近上限时主动触发。这个细节我之前没想到。
假工具和情绪检测呢?我觉得当反面教材看就好。在产品里埋陷阱、监控用户情绪,技术上没问题,但被发现的那天就是公关翻车的那天。这次泄露本身就是活生生的例子。
往后看
不管 Anthropic 愿不愿意,51万行源码已经被社区翻了个底朝天。Cursor、Windsurf 这些竞品的开发者肯定也在研究。AI Coding Agent 这条赛道,以后拼的是工程执行力,架构上已经没什么秘密了。
对我们用 AI 写代码的人来说,知道工具内部怎么运转的,比盲目信任它有用得多。你清楚它怎么管理上下文、什么时候会丢信息、工具调用的决策逻辑是什么,用起来才不会踩坑。
你现在用的 AI 编程工具是哪个?看完这次泄露,有没有改变你对这些工具的看法?评论区聊聊。