 夜雨聆风
夜雨聆风





Claude Code 源码解析 – 记忆系统
想象你是一个刚入职的程序员。第一天老大丢给你一个任务,你辛辛苦苦做了三天,临走前老大问你:”记住了吗?”
你说记住了。
第三天你回来了,老大问:”之前那个任务,继续做吧。”
你一脸懵——三天前的事,全忘了。
这就是 AI Agent 的「失忆症」问题。每次对话,Agent 从零开始;每次重启,上下文烟消云散。怎么让 AI 记住「三天前做的事」?
Claude Code 给了答案:文件即记忆。
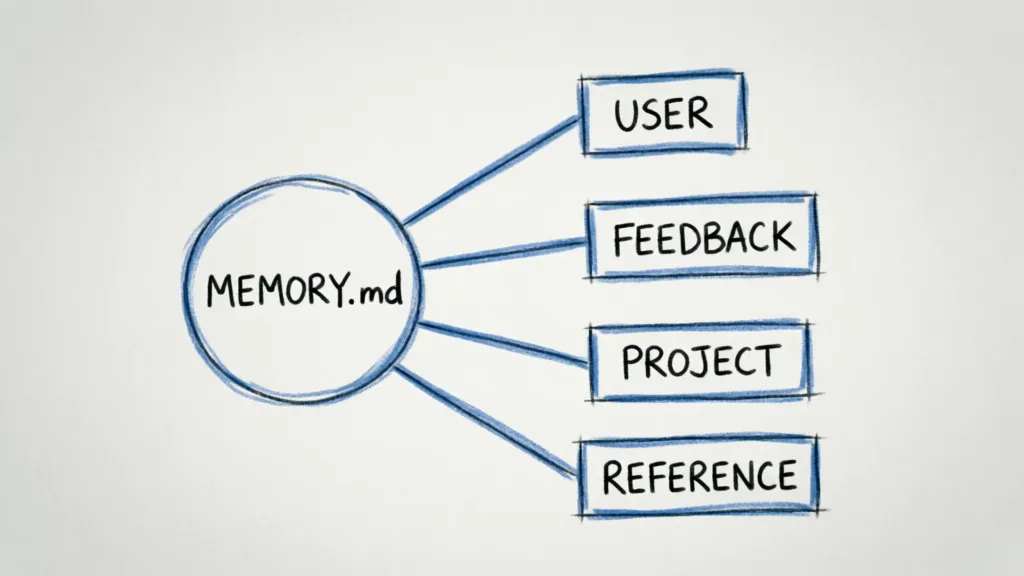
一、四类记忆:精妙的类型设计
Claude Code 的记忆系统把「记忆」分成四类,每类都有明确的职责边界:
// src/memdir/memoryTypes.ts
export const MEMORY_TYPES = [
'user', // 用户角色、偏好、知识
'feedback', // 用户的纠正和确认
'project', // 项目上下文、正在做的事
'reference', // 外部系统指针
] as const
1.1 user 记忆:懂你的角色
user 记忆存放「用户是谁」的信息:
---
name: user_experience_level
description: 用户是资深 Go 开发者,首次接触 React
type: user
---
深度 Go 经验,但 React 是新手。
解释前端概念时,用后端类比帮助理解。
核心原则:避免负面评判。不要记录「这个用户很菜」,只记录如何更好地帮助他。
1.2 feedback 记忆:纠正和确认都要记
feedback 是最重要也最容易被忽视的记忆类型。Claude Code 要求:
记录失败也记录成功。如果你只记录纠正,你会避开错误,但也会逐渐偏离已经被验证有效的方法。
feedback 记忆的结构:
---
name: feedback_pr_style
description: 用户偏好单个打包 PR
type: feedback
---
**规则**:这个领域的重构,用户偏好一个打包 PR 而不是多个小 PR。
**Why**:之前我选了分拆方案,用户确认「这次是对的选择,分拆只会增加无谓的消耗」——经过验证的判断。
**How to apply**:面对这个区域的 refactor 任务时,倾向单个打包 PR。
注意 Why 和 How to apply 的分离。知道原因,才能在边界情况下做出正确判断。
1.3 project 记忆:项目上下文
存放「谁在做什么、为什么、什么时候」的信息:
---
name: project_merge_freeze
description: 3月5日后移动团队将切断 release 分支
type: project
---
**事实**:3月5日(周四)之后冻结所有非关键 merge。
**Why**:移动团队要切 release 分支。
**How to apply**:标记在此日期之后安排的非关键 PR 工作。
关键点:相对日期必须转绝对日期。「下周四」在两周后阅读时可能变成「上上周四」。
1.4 reference 记忆:外部系统指针
存放「去哪里找信息」而不是信息本身:
---
name: ref_pipeline_bugs
description: pipeline bugs 在 Linear 项目 INGEST 追踪
type: reference
---
pipeline bugs 在 Linear 项目「INGEST」追踪。
查看这里获取上下文。
二、记忆的边界:什么不该记
Claude Code 的记忆系统有一条铁律:只记不可推导的信息。
以下内容明确禁止存入记忆:
-
代码模式、架构、约定 -
Git 历史、谁改了什么 -
调试方案(fix 在代码里) -
CLAUDE.md 已有的内容 -
临时任务细节
换句话说:如果 grep 能找到,就不要浪费记忆。
这条规则防止记忆系统变成「代码索引的垃圾堆」。
三、文件存储:最简单的持久化
3.1 目录结构
~/.claude/projects/<sanitized-git-root>/memory/
├── MEMORY.md # 入口索引
├── user_role.md # 用户记忆
├── feedback_pr_xxx.md # 反馈记忆
├── project_freeze.md # 项目记忆
└── ref_bugs.md # 引用记忆
为什么用文件系统?
-
版本控制 — Git 天然支持,可以 review 记忆变更 -
简单直观 — 不需要额外的数据库 -
可验证 — 用户可以直接打开文件确认 -
可协作 — Git 的团队共享机制天然适配 team memory
3.2 两步写入法
Claude Code 的记忆写入是两步:
Step 1:写入独立文件
---
name: feedback_summary_style
description: 用户不想在结尾看到总结
type: feedback
---
用户希望回复简洁,不要在结尾重复总结工作内容。
可以直接给出结论。
---
Step 2:在 MEMORY.md 添加索引
- [用户不喜欢总结](feedback_summary_style.md) — 简洁直接
为什么要这么麻烦?因为 MEMORY.md 是入口索引,不是记忆本体。索引必须简洁(每行 ~150 字符),正文放在独立文件里。
3.3 路径安全
记忆路径的解析优先级:
-
CLAUDE_COWORK_MEMORY_PATH_OVERRIDE— 环境变量(Cowork 场景) -
settings.json中的autoMemoryDirectory— 用户配置 -
默认路径 — ~/.claude/projects/<project>/memory/
安全设计亮点:projectSettings(项目内配置文件)不能设置 autoMemoryDirectory。防止恶意仓库通过设置 ~/...ssh 访问敏感目录。
四、团队记忆:private 和 team 的双轨制
Claude Code 支持两种记忆 scope:
// 私人记忆:只有自己可见
~/.claude/projects/xxx/memory/
// 团队记忆:项目成员共享
~/.claude/projects/xxx/team/
每种记忆类型都有 scope 指导:
| 类型 | 默认 scope | 说明 |
|---|---|---|
| user | always private | 用户信息不应该共享 |
| feedback | default private | 只有项目通用约定才是 team |
| project | strongly bias team | 项目上下文应该共享 |
| reference | usually team | 外部系统指针应该共享 |
关键原则:team memory 禁止存敏感信息(API keys、用户凭证等)。
五、智能召回:按需获取
记忆系统不能「一股脑全塞给 LLM」。Claude Code 用 Sonnet 模型辅助选择:
// src/memdir/findRelevantMemories.ts
export async function findRelevantMemories(
query: string,
memoryDir: string,
signal: AbortSignal,
): Promise<RelevantMemory[]> {
// 1. 扫描所有 .md 文件,读取 frontmatter
const memories = await scanMemoryFiles(memoryDir, signal)
// 2. 让 Sonnet 选择最相关的 5 个
const selectedFilenames = await selectRelevantMemories(
query,
memories,
signal,
)
return selectedFilenames.map(filename => /* 返回路径和 mtime */)
}
Sonnet 会根据 query 内容和记忆的 description,选择真正相关的记忆。
防噪音设计:
-
最近使用的工具不显示其 reference docs -
但 warnings、gotchas、known issues 仍然保留 -
MEMORY.md 入口文件不参与召回(已在 system prompt)
六、对话压缩:上下文空间的守护者
记忆系统解决的是「跨会话持久化」,但单会话内的上下文膨胀怎么办?
Claude Code 有 compaction(压缩)机制:

6.1 压缩时机
-
自动压缩:上下文接近 token 限制时自动触发 -
手动压缩:用户输入 /compact命令 -
部分压缩:选中特定消息段压缩(保留前后文)
6.2 压缩流程
// src/services/compact/compact.ts
export async function compactConversation(messages: Message[]) {
// 1. 调用 LLM 生成对话摘要
const summary = await generateSummary(messages)
// 2. 保留最近文件状态(最多5个文件)
const recentFiles = getRecentReadFiles()
// 3. 重新注入必要附件(技能、计划等)
const attachments = await createPostCompactAttachments()
// 4. 返回压缩后的消息
return {
boundaryMarker: '__COMPACT_BOUNDARY__',
summaryMessages: [summary],
attachments,
}
}
6.3 压缩策略
文件恢复(最多 5 个文件):
POST_COMPACT_MAX_FILES_TO_RESTORE = 5
POST_COMPACT_MAX_TOKENS_PER_FILE = 5,000
最近读取的文件会被重新注入,避免「刚读完又忘了」的尴尬。
技能保留(最多 25K tokens):
POST_COMPACT_SKILLS_TOKEN_BUDGET = 25,000
POST_COMPACT_MAX_TOKENS_PER_SKILL = 5,000
调用的 skill 内容会被截断保留(保留头部,通常是使用说明)。
图片剥离:
用户消息中的图片不参与摘要生成——它们不是关键信息,还会导致压缩 API 本身超出 token 限制。
6.4 压缩边界标记
压缩后会在对话中插入:
__COMPACT_BOUNDARY__ (标记)
[earlier conversation truncated - 摘要内容]
这个标记让后续压缩知道「从哪里开始」,支持增量压缩。
七、设计目标:为什么这样设计?
7.1 解决什么问题?
| 问题 | 解决方案 |
|---|---|
| 上下文窗口有限 | 记忆系统持久化跨会话信息 |
| Agent 失忆症 | 文件即记忆,可以跨会话保留 |
| 团队协作 | team memory + private memory 双轨 |
| 上下文膨胀 | compaction 机制压缩单会话内历史 |
7.2 核心设计哲学
1. 持久化优先于检索
与其每次会话重建上下文,不如一开始就存下来。文件系统的设计让记忆可以像代码一样版本控制。
2. 可验证性
记忆会过时(memory drift)。Claude Code 要求:
使用记忆前,验证它是否还正确。如果记忆与当前信息冲突,相信你观察到的——更新或删除过时的记忆。
3. 隐私分层
不是所有信息都应该共享。private memory 和 team memory 的分离,让用户可以区分「只有我知道」和「团队都需要知道」。
4. 什么不该做
-
记忆不等于日志(不要记录 PR 列表) -
记忆不等于文档(文档应该在代码库) -
记忆只存「非显而易见」的信息
总结
Claude Code 的记忆系统告诉我们:简单即有效。
用文件系统做持久化、用四类类型做约束、用 Sonnet 做智能召回、用 compaction 做上下文管理。这套组合拳解决了 AI Agent 最头疼的「记不住」问题。
如果你在设计一个 Agent 系统,不妨问自己:我的 Agent 能在三天后记住今天做的事吗?
源码索引
| 功能 | 文件 | 关键函数 |
|---|---|---|
| 记忆类型定义 | src/memdir/memoryTypes.ts |
MEMORY_TYPES |
| 路径解析 | src/memdir/paths.ts |
getAutoMemPath() |
| 记忆扫描 | src/memdir/memoryScan.ts |
scanMemoryFiles() |
| 相关记忆召回 | src/memdir/findRelevantMemories.ts |
findRelevantMemories() |
| 团队记忆 | src/memdir/teamMemPrompts.ts |
buildCombinedMemoryPrompt() |
| 对话压缩 | src/services/compact/compact.ts |
compactConversation() |