 夜雨聆风
夜雨聆风





Claude Code的源码证明记忆不是简单“存下一切”,而是采用约束性、结构化和自我修复的机制
大多数AI Agent一遇到长期任务,就爱把所有历史记录、日志、代码结构一股脑塞进上下文。结果呢?上下文窗口迅速膨胀、噪声增多、模型开始“幻觉”或遗忘关键信息。Claude Code的反其道而行之:它把记忆当作索引,而不是仓库。
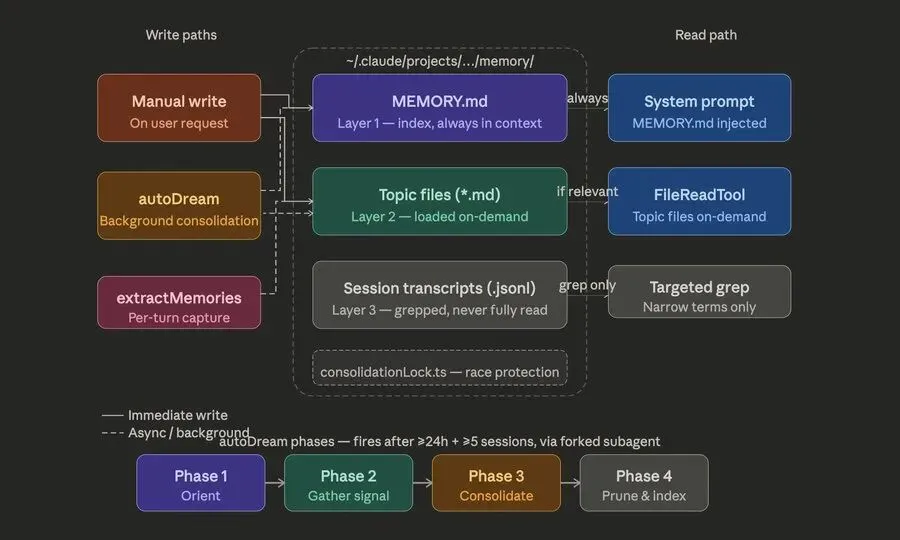
核心架构:三层设计,极致带宽优化
- 索引层(MEMORY.md)——始终加载这是一个轻量级的指针文件,每行大约150字符,硬性限制在200行左右。里面只存关键指针、总结和路由信息,从不塞完整内容。它像大脑的“目录”,一启动就自动加载,确保每次会话都有清晰的起点。
- 主题文件层(Topic Files)——按需加载实际知识分散存储在外部主题文件中。只有当模型真正需要某个具体主题时,才会读取对应文件。这种懒加载方式极大减少了不必要的token消耗。
- 会话记录层(Transcripts)——从不直接读取,仅grep搜索完整对话记录永远不全量加载,只通过关键字搜索(grep)快速定位相关片段,避免上下文污染。
严格的写入纪律:写完就更新,绝不乱塞每次写入新内容后,必须立即更新索引。绝不允许把大段内容直接dump进MEMORY.md。这种“先写文件、再更新指针”的纪律,防止了信息熵爆炸和上下文逐渐变脏。最亮眼的功能:后台autoDream(自动梦境)Claude Code引入了一个叫autoDream的后台机制,像给AI装了一个“潜意识”:
- 在fork出的子代理中独立运行(隔离主上下文,防止污染)
- 自动合并重复、去重、解决矛盾
- 把模糊表述转为明确事实
- 激进修剪无用信息
- 记忆不是简单追加,而是持续被编辑和重写
这个过程类似于人类睡眠中的记忆巩固(REM睡眠),能在你不使用的时候,悄悄把记忆库打扫干净。触发条件通常是24小时以上或多次会话后,也支持手动调用。“陈旧性”优先:记忆错了,就该被怀疑系统把“陈旧性”当作一等公民:
- 如果记忆与当前现实(代码、事实)冲突,优先认为记忆是错的
- 能从现有代码中推导出来的事实,绝不存储
- 索引会被强制截断,确保干净
检索时也不是盲信:记忆只是“提示”(hint),模型必须验证其真实性后再使用。这大大降低了长期漂移的风险。真正的高明之处:不存什么这套系统的精髓在于什么都不存:
- 不存调试日志
- 不存代码结构细节
- 不存PR历史
- 任何可推导的信息,都坚决不持久化
这种极简主义,是最难的工程决策。它让系统保持轻量,同时避免了“存得越多,越容易出错”的陷阱。
Claude Code的记忆系统告诉我们:
- 隔离与保护至关重要:后台整合用独立子代理 + 有限工具
- 最小化才是王道:带宽意识、严格纪律、自我清理
- 怀疑态度是长期可靠性的基础:记忆是助手,不是权威
对于正在构建自主Agent、长期编码助手或多智能体系统的开发者来说,这套架构提供了宝贵参考。无论是用Markdown文件实现类似结构,还是结合向量数据库,都可以借鉴其“索引+按需+清理”的思路。在AI越来越强大的今天,决定成败的往往不是模型本身,而是工程层面的智慧。Claude Code用一个“自我清洁的知识库”,证明了:好的记忆系统,不是存得更多,而是忘得更聪明、管得更严谨。你正在用Claude Code开发项目吗?欢迎在评论区分享你的记忆管理经验,一起交流如何让AI Agent更持久、更可靠!