 夜雨聆风
夜雨聆风





Claude Code 源码泄露后,我发现了 3 个跨界通用心法

01 一个意外事件
2026 年 3 月底,AI 圈出了个”大瓜”:Anthropic 的 Claude Code 源码意外泄露了。
一个叫@tvytlx 的博主下载了 npm 包里的 4756 个源码文件,从入口、提示词、工具、权限、Agent 调度、插件、Hook 一路拆下去,写了篇深度分析报告。
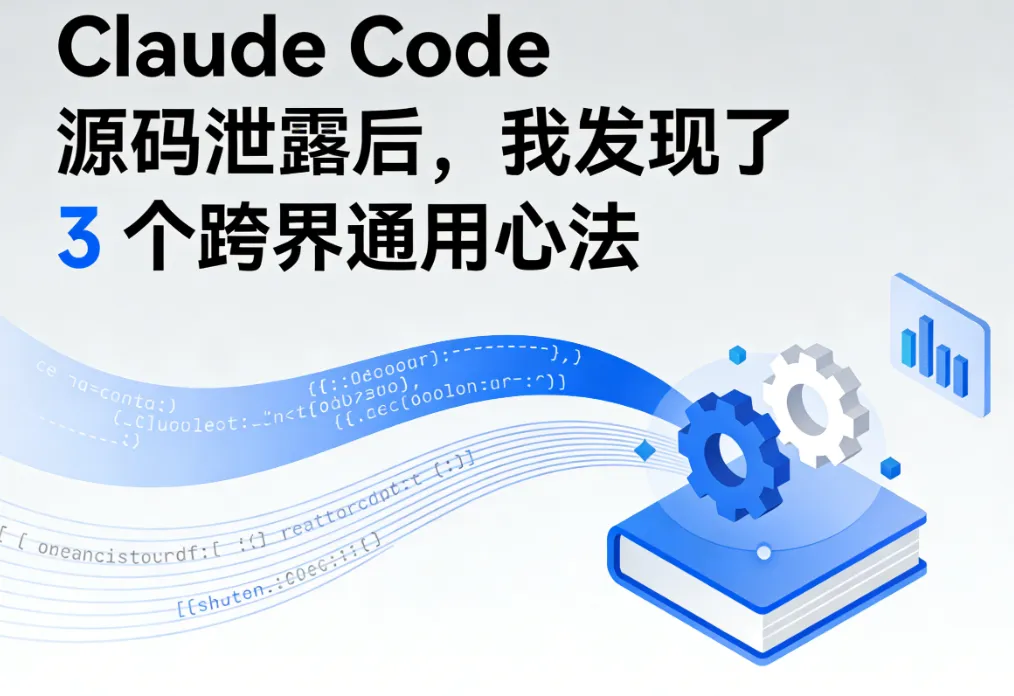
读完这篇文章,我有个强烈的感受:市面上对 Claude Code 的分析,90% 都搞错了方向。
大部分人盯着两件事:
-
System Prompt 写了什么 -
它调了哪些工具
但这两件事,只是这个系统的”皮肤”。你拿到同样的 prompt,接上同样的工具,照着写一遍,出来的东西和 Claude Code 的体验差距会非常大。
差在哪?
差在 prompt 背后有一整套编排机制,工具背后有一整条治理流水线,Agent 背后有一套分工和调度系统。
这些东西加在一起,才构成了你用 Claude Code 时感受到的那个”稳“。这个稳不是来自某段神奇文案,是来自工程。
拆完这 4756 个文件后,我提炼出 5 条设计原则。意外的是,这些原则不仅适用于 AI 系统,对企业流程优化和文史研究方法,同样有启发。
02 Claude Code 的 5 条核心设计原则
原则一:不要信任模型的自觉性
Claude Code 不指望模型”聪明”,而是把行为规范写成制度。
比如它有个 getSimpleDoingTasksSection() 模块,明确规定:
-
不要加用户没要求的功能 -
不要过度抽象 -
不要瞎重构 -
不要乱加注释 -
先读代码再改代码 -
不要轻易创建新文件
如果你用过其他 coding agent,你一定遇到过这些问题:你让它改一个 bug,它顺手给你重构了半个文件。你让它测一下,它说”测试通过了”,但其实它根本没跑。
这些问题的根源不是模型笨,是模型的行为没有被约束。
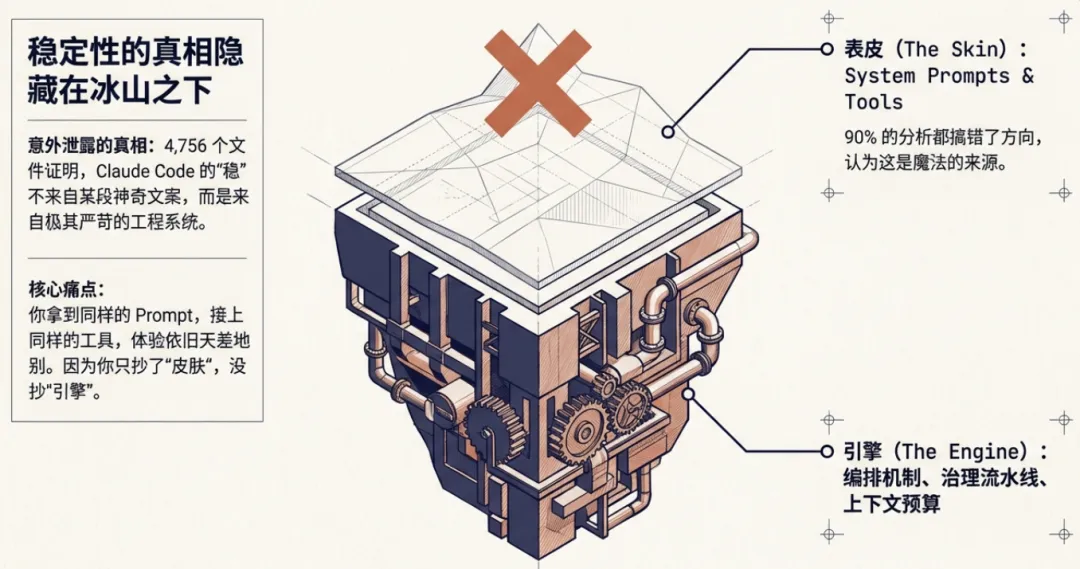
原则二:把角色拆开
Claude Code 源码里确认了至少 6 个内建 Agent:
-
Explore Agent:纯只读,不能改任何东西 -
Plan Agent:架构师,只规划不执行 -
Verification Agent:验证者,任务是”想办法搞坏它” -
General Purpose Agent:通用执行 -
其他专业 Agent… 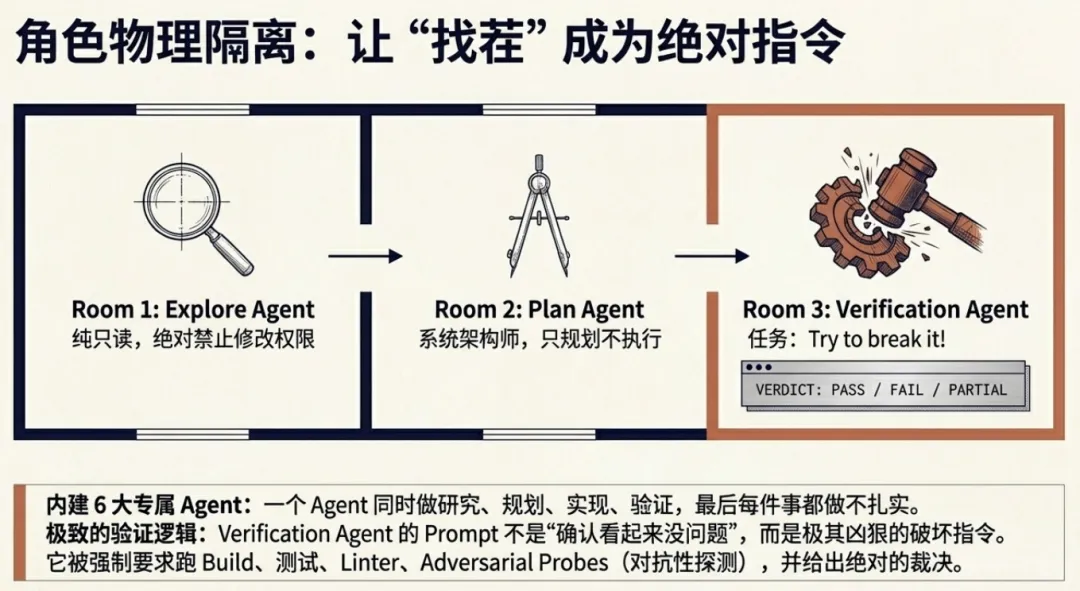
让一个 Agent 同时做研究、规划、实现、验证,最后每件事都做不扎实。
尤其是 Verification Agent,它的 prompt 可能是整个源码里写得最狠的一个:
它的核心方向不是”确认实现看起来没问题”,而是 try to break it。
它强制要求:跑 build、跑测试、跑 linter、做 adversarial probes 找边界情况。每个检查必须带实际执行的命令和观察到的输出。最后必须给出 VERDICT: PASS/FAIL/PARTIAL。
这个设计解决了 LLM 验证工作中最常见的问题:”差不多就算了”。
原则三:工具调用要有治理
当模型决定调用一个工具时,Claude Code 不是直接执行对应的函数。实际链路是这样的:
输入校验 → 风险预判 → 权限决策 → Hook 拦截 → 执行 → 记录分析 → 后处理 → 失败恢复这条链路里最有意思的是 Hook 系统。PreToolUse Hook 不只能记日志,它能:
-
改写输入 -
直接放行或拒绝 -
阻止后续流程 -
补充上下文信息
但 Hook 的权力也不是无限的。如果工具本身要求用户交互,Hook 不能绕开核心安全模型。
强大但受控,这是工程成熟度的体现。
原则四:上下文是预算
Claude Code 的 system prompt 是由一个叫 getSystemPrompt() 的函数动态拼装出来的。
它分两部分:
-
静态部分:身份定位、系统规范、语气风格…这些是”宪法”,不管什么会话都一样 -
动态部分:session guidance、memory、环境信息、语言设置…这些是”当期政策”,根据当前会话调整
源码里有一个叫 SYSTEM_PROMPT_DYNAMIC_BOUNDARY 的标记,注释里写得很清楚:
边界之前的内容尽量保持 cache 友好,边界之后是用户和会话特定的内容,不能乱改,否则会破坏缓存。
这意味着 Anthropic 在管理 system prompt 的时候,已经在考虑 token 经济学 了。边界之前的内容因为稳定,可以被 API 层缓存,不用每次都重新计算。
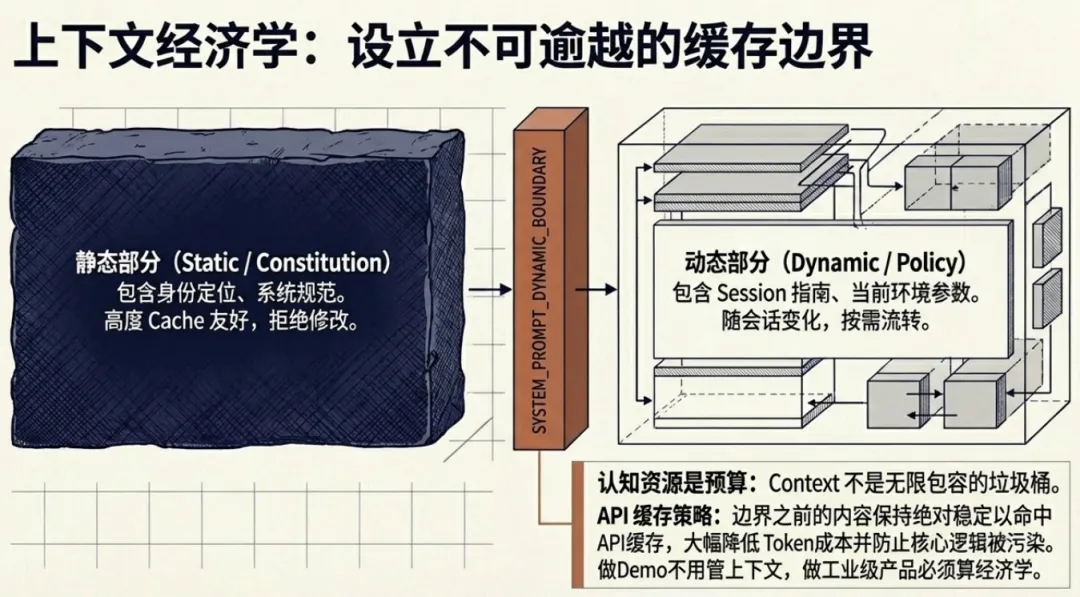
对于做 Demo 的人来说,上下文管理不是问题。但对于做产品的人来说,上下文经济学直接关系到成本和体验。
原则五:生态的关键是模型感知
Claude Code 有三套扩展机制:Skill、Plugin、MCP。
这三套机制有一个共同点:它们都不只是”挂载到系统上”。它们会通过 skills 列表、agent 列表、MCP instructions、session-specific guidance 这些通道,让模型感知到自己当前有哪些扩展能力、什么时候该用、怎么用。
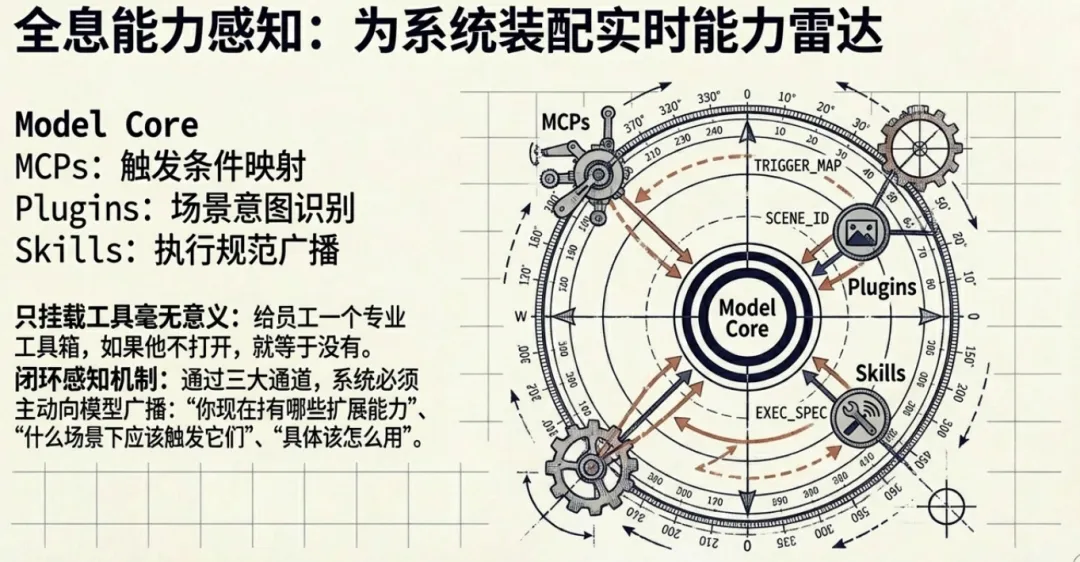
很多平台也有插件系统,也有工具市场,但模型本身不知道这些东西存在。这就像你给一个人配了一整套专业工具箱,但他不知道箱子里有什么,也不知道什么时候该打开。
扩展机制的最后一步,是让模型看到自己的能力清单。
03 企业流程优化的 5 个落地应用
这 5 条原则,听起来很技术,但完全可以迁移到企业流程优化中。
应用一:角色分离 → 部门职责重构
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
落地建议:
ERP 升级项目:调研→方案→实施→验收,每个阶段换人,前阶段输出是后阶段输入。
网络变更:操作人不能是审批人,验收人不能是实施人。
应用二:风险动作清单 → 权限分级制度
CC 定义了什么叫”需要确认的风险动作”:破坏性操作、难以回滚、修改共享状态、对外可见。
企业映射:
【一级风险 - 需审批】- 删除生产数据- 修改核心配置- 对外发布信息- 修改共享权限【二级风险 - 需双人确认】- 批量操作- 跨部门影响- 新供应商接入【三级风险 - 可自主】- 本地测试- 只读查询- 文档更新关键点: 把”风险动作清单”写进操作手册,不是靠员工”自己注意”。系统层面做权限控制,不是靠自觉。
应用三:工具治理流水线 → 操作 SOP
CC 的工具调用链路:输入校验→风险预判→权限决策→执行→后处理→失败恢复
企业映射(以网络变更为例):
变更前: □ 变更申请单填写完整(输入校验) □ 影响范围评估(风险预判) □ 审批流程通过(权限决策)变更中: □ 按 SOP 执行(执行) □ 每步记录日志(后处理)变更后: □ 验证测试通过(验证) □ 回滚方案待命(失败恢复)应用四:上下文管理 → 知识传承系统
CC 的 system prompt 分静态(宪法)和动态(当期政策),能缓存的缓存。
企业映射:
-
静态知识:公司制度、SOP、架构文档 → 长期维护,新人入职统一学习 -
动态知识:项目背景、当期任务、临时决策 → 项目结束后归档,不污染静态库
落地建议:
建立”项目上下文文档”模板:背景→目标→已排除方案→当前状态→下一步
项目交接时,不是口头说,而是按模板填好,新人自己读文档就能上手。
应用五:能力感知 → 技能地图
CC 让模型知道自己有哪些扩展能力,知道什么场景用什么。
企业映射:
很多员工学了很多技能,但不知道什么时候用。
建议建一个”技能触发器”清单:
【问题类型】→【推荐技能/工具】- 数据分析问题 → Excel 透视表 / Python pandas- 流程优化问题 → 价值流图 / 瓶颈分析- 跨部门协作 → RACI 矩阵 / 沟通计划- 风险评估 → FMEA / 风险矩阵定期 review 团队的能力清单:我们会什么?什么场景用什么?
04 文史研究方法的 4 个改进
我本人是历史系毕业,深耕企业信息化多年。这套理念在文史研究领域,同样有应用空间。
改进一:探索者角色 → 纯阅读阶段
文史研究常见问题:读材料时边读边想观点,容易被先入为主的观念带偏。
CC 启发:
【阶段一:Explore Only】- 只读不写观点- 只摘录不解读- 只标注不归纳- 输出:资料卡片(原文 + 出处)【阶段二:Plan】- 基于资料卡片找模式- 提出假设/论点- 设计论证路径【阶段三:Execute】- 按论证路径写作【阶段四:Verify】- 找反例- 交叉验证- 请同行挑刺落地建议:
用 Zotero/Notion 建”资料卡片库”,强制自己第一阶段只能建卡片,不能写解读。
卡片模板:原文摘录 + 出处 + 关键词,**不允许有”我认为”**。
改进二:验证者角色 → 证伪思维
CC 的 Verification Agent 被要求”try to break it”,不是”确认看起来没问题”。
文史研究映射:
常见陷阱:找到一个支持自己论点的材料就满足了。
验证清单:
□ 有没有相反记载的史料?□ 同时期其他地区的记录是否一致?□ 史料作者的立场是否可能影响记载?□ 有没有后世篡改/误传的可能?□ 我的论证有没有循环论证?□ 有没有过度解读?落地建议:
论文写完初稿后,换一天再用”验证者模式”重读,专门找漏洞。
或者请同行当”验证 Agent”,他的任务就是挑刺。
改进三:上下文管理 → 史料分层系统
CC 的上下文经济学:能缓存的缓存,按需加载,不一股脑塞进去。
文史研究映射:
【L1 - 核心史料】(静态,长期缓存)- 与研究主题直接相关的一手史料- 反复精读,做详细笔记【L2 - 背景史料】(动态,按需加载)- 同时期相关记载- 需要时再查,不占用日常认知【L3 - 研究文献】(按需注入)- 前人研究成果- 写到相关部分时再参考,避免被带偏落地建议:
用卡片盒笔记法(Zettelkasten),但**区分”核心卡”和”参考卡”**。
写作时只打开当前章节需要的卡片,不是把所有资料都摊在桌上。
改进四:能力感知 → 方法论工具箱
很多研究者学了很多方法(计量史学、GIS、文本挖掘…),但不知道什么时候用。
建议建一个”方法触发器”清单:
【研究问题类型】→【推荐方法】- 时空分布问题 → GIS + 时空可视化- 人物关系网络 → 社会网络分析- 文本演变 → 版本校勘 + 文本挖掘- 制度变迁 → 制度分析框架 + 比较研究- 经济数据 → 计量史学 + 统计分析定期 review 自己的能力清单:我会什么方法?什么场景用什么?
05 写在最后
Claude Code 的价值不在于某个具体实现,而在于它用工程实践验证了这些原则确实有效。
五条原则,一句话总结:
-
好行为要写成制度,不要依赖临场发挥 -
把”做事的人”和”验收的人”分开 -
关键操作要有治理流水线 -
认知资源是预算,能缓存的缓存 -
学了方法要知道什么时候用 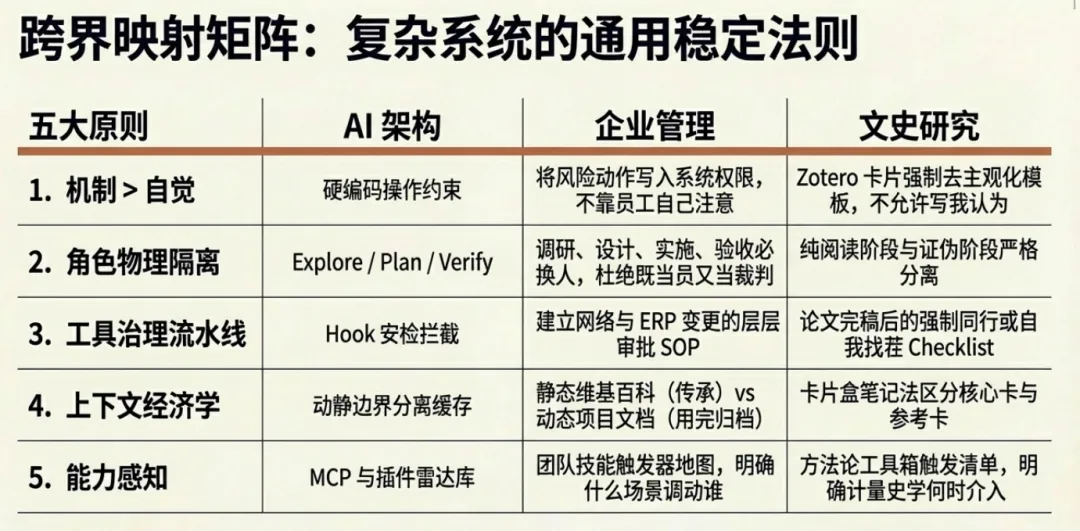
这五条原则不只适用于 coding agent,也适用于几乎所有需要处理复杂任务的系统——无论是企业流程,还是文史研究。
你不需要复刻它的全部。从最薄弱的环节开始补,每补一层,系统的”手感”就会好一个台阶。
延伸思考:
你的工作流里,哪个环节最”靠自觉”?哪个角色既当运动员又当裁判员?哪个清单写了但没人执行?
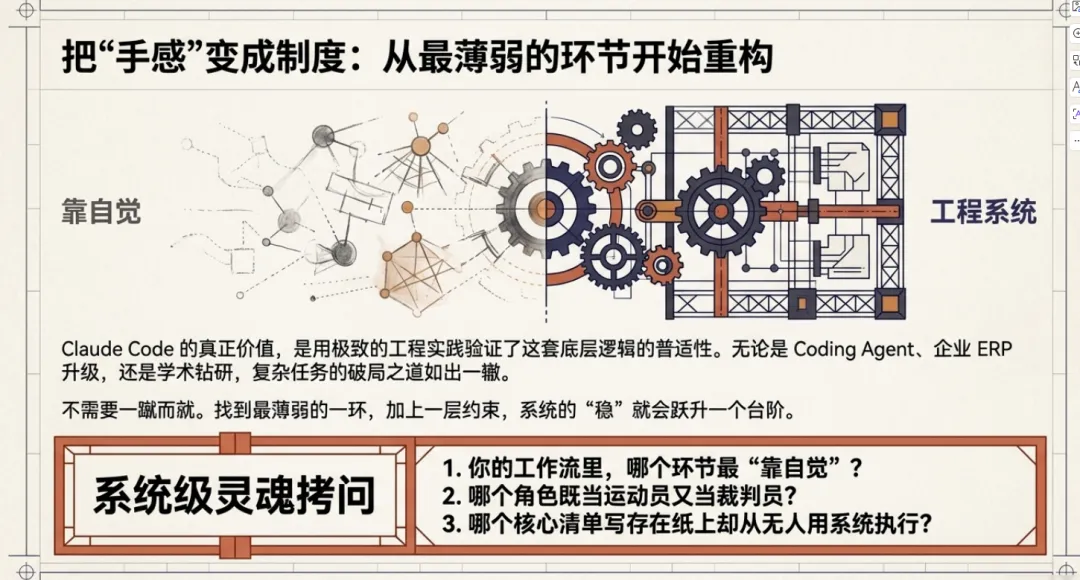
欢迎在评论区聊聊,我们一起用工程思维,把”手感”变成”制度”。