 夜雨聆风
夜雨聆风





Claude Code 源码曝光 :1884 个文件拆完之后,Claude Code 到底是什么?
Claude Code 的官方定位是”AI 编程助手”。但如果你把它的 1884 个 TypeScript 源文件完整拆开看一遍——架构、记忆、安全、多 Agent 编排逐层拆解——会得到一个不太一样的答案:它本质上是一个完整的 Agent Runtime,那句定位某种程度上低估了它自己。

它的核心是一个无限循环
很多人用 Claude Code 的感受是”对话式的”——你说一句,它回一句,然后去改文件。但在代码层面,这个过程是一个 while(true) 循环在驱动。
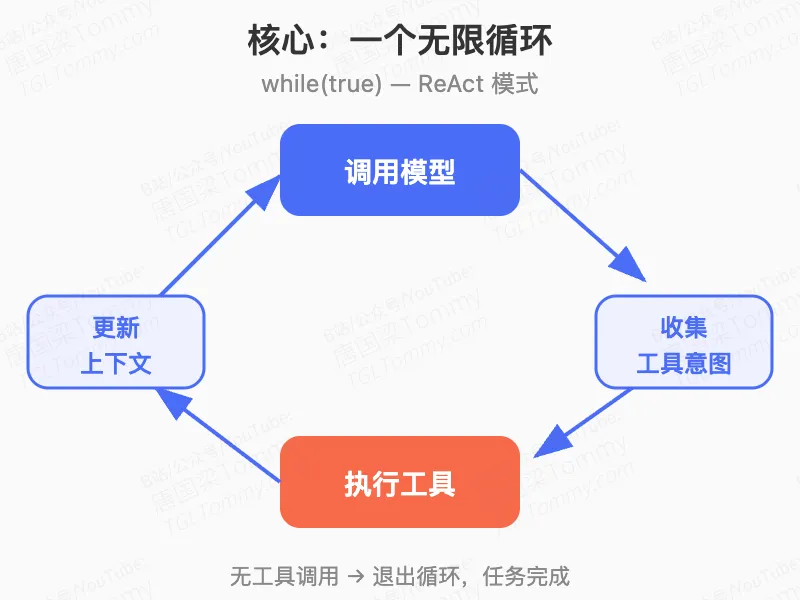
主体逻辑在 query.ts(1729 行),叫做 queryLoop()。每一轮循环:调用模型 → 收到工具调用意图 → 执行工具 → 把结果塞回上下文 → 再次调用模型。如果没有工具调用了,循环终止,任务完成。
这是 ReAct(Reasoning + Acting)范式的标准实现,但 Claude Code 在这个基础上叠加了相当多的工程设施。比如终止条件就有 8 种,恢复机制有 5 层(API 级重试、输出 Token 恢复、响应式压缩、上下文排空、Fallback 模型切换),还有一个”无人值守持久重试”机制,最大退避 5 分钟,最长跑 6 小时不中断。
更直白一点看:这不是一个问答系统,而是一个设计上就准备长时间、高自主度运行的 Agent 框架。
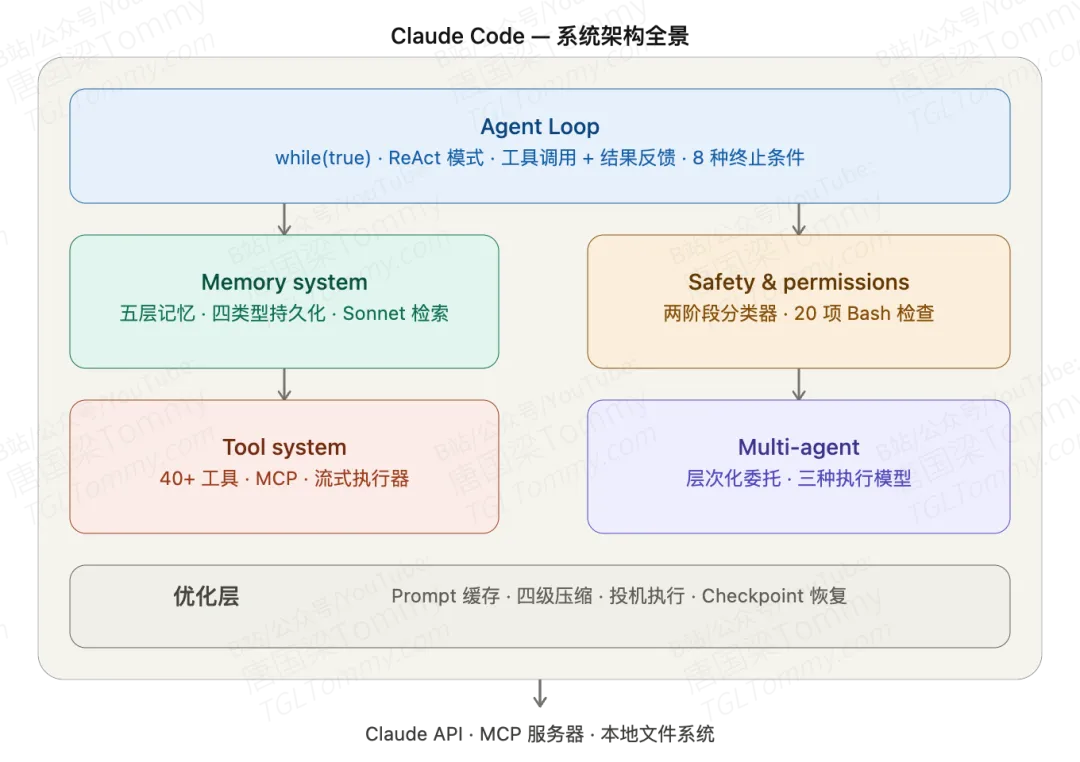
记忆系统比你以为的成熟
Claude Code 的记忆体系是这份报告里描述得最细的部分之一,覆盖了五个层面。

短期记忆是会话内的对话消息,保存在内存里,进程退出即丢失。工作记忆是当前任务的状态,比如正在运行的子 Agent 任务、文件变更追踪。
真正值得关注的是长期记忆的设计。它是三层结构:记忆目录(按项目隔离的 ~/.claude/projects/ 路径)→ MEMORY.md 索引文件(最多 200 行,始终加载进系统提示)→ 独立的主题文件。
主题文件有四种封闭类型:user(角色偏好)、feedback(用户纠正行为)、project(进行中工作)、reference(外部系统指针)。这个分类不是随意的——每种类型对应不同的隐私级别和团队共享策略,user 类型始终私有,project 类型则偏向团队可见。
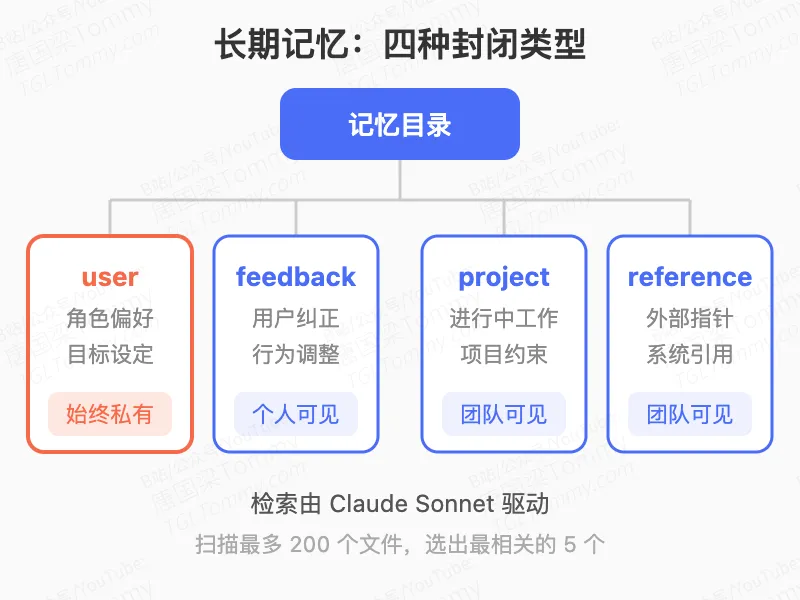
更有意思的是记忆的检索方式:系统不是把所有记忆都塞进上下文,而是用 Claude Sonnet 本身去扫描记忆目录(最多 200 个文件),选出最相关的 5 个。换句话说,记忆的检索也是模型驱动的。
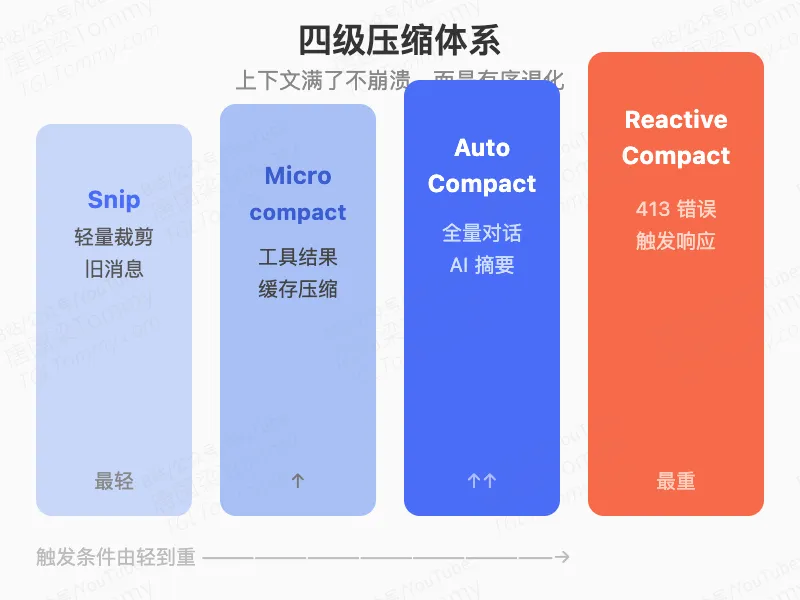
摘要记忆层面则是四级压缩体系:轻量裁剪(Snip)→ 工具结果缓存(Microcompact)→ 全量对话摘要(Auto Compact)→ 413 错误响应式压缩(Reactive Compact)。每一级触发的条件和恢复策略都不同,整体上是一个”优雅退化”的设计——上下文窗口满了,不是崩溃,而是有序地压缩最不重要的内容。
一个很少被提到的优化:投机执行
这份报告里让我觉得最有工程意思的发现,是”投机执行”(Speculation)机制。
核心思路是:当 Claude Code 向你展示一个操作建议、等待你确认时,它已经在后台开始执行这个操作了。
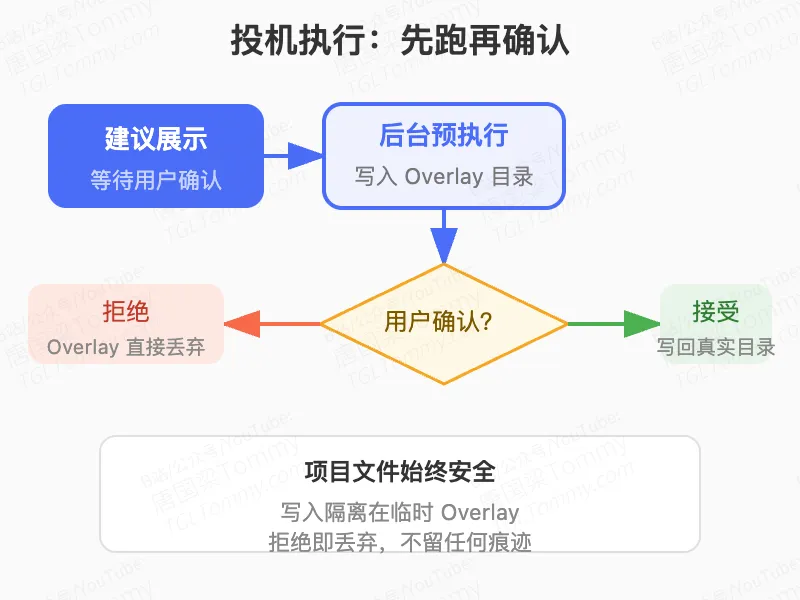
为了让这件事是安全的,它实现了一个 Copy-on-Write 的覆盖文件系统。所有投机执行的文件写入不会真正落到你的项目目录,而是写入一个临时的 overlay 目录。读取时,如果文件已经在 overlay 里有副本,就从 overlay 读;否则从真实文件系统读。
如果你点了”接受”:overlay 的内容被复制回真实目录,完成。 如果你点了”拒绝”:overlay 直接丢弃,你的项目文件完全没有被动过。
在此基础上,还有流水线化的投机:系统在等你确认建议 A 时,会根据 A 完成的结果推断出建议 B 并提前开始执行。你接受 A 的时候,B 可能已经准备好了。
这个机制显著降低了”等待感”,但实现代价是相当重的——一个完整的 COW 文件系统抽象,加上 Abort Controller 和清理逻辑。整个 speculation.ts 文件长达 992 行。
Shell 安全:20 项检查,不是夸张
BashTool 是 Claude Code 里风险最高的工具,报告里专门列出了 bashSecurity.ts 里的 20 项安全检查清单。覆盖范围包括:命令替换模式、IFS 注入攻击、Unicode 空白技巧、Zsh 特有的危险命令(如 zmodload)、中间词哈希注释等等。
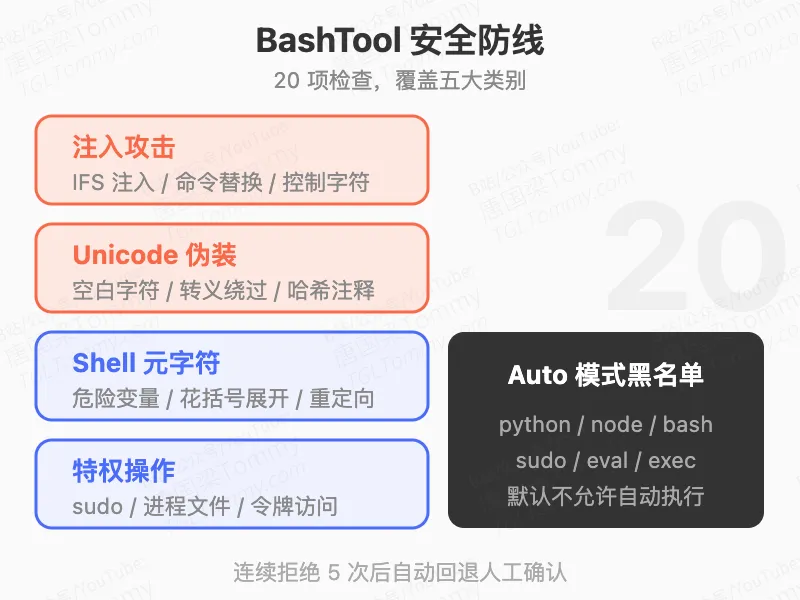
Auto 模式(自动放行操作)下还有一个解释器黑名单,python、node、bash、eval、exec、sudo、ssh 等解释器默认不允许自动执行,必须回退到用户确认。
权限判定本身也是两阶段的:先用 Claude Haiku 快速判断(低延迟),置信度不够时再用 Claude Sonnet 开启扩展思考做深度分析。连续拒绝 5 次后,分类器自动退出,改为要求用户手动确认,防止因分类器问题进入死循环。
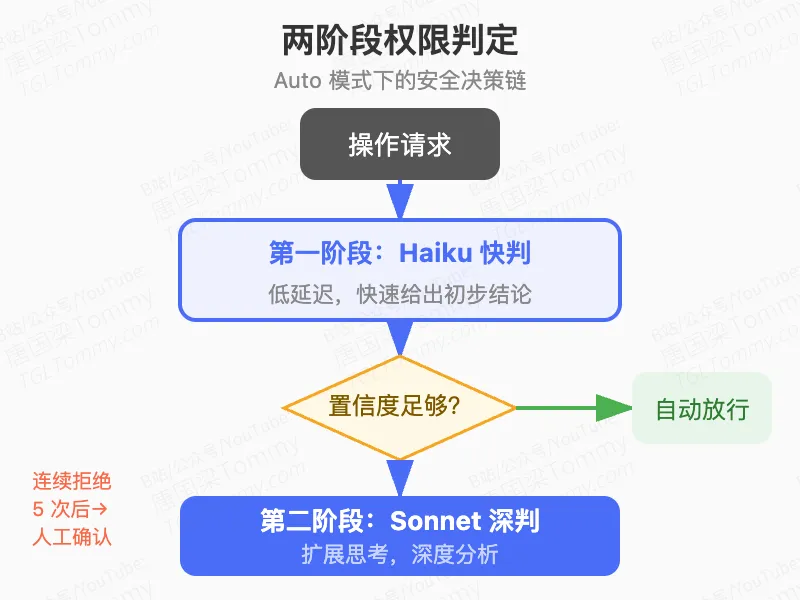
这背后的关键在于:”自动化”不是没有边界的。Claude Code 的 auto 模式是有安全网的自动化,不是盲目放行。
成本优化藏在架构里
报告里提到的一个细节值得单独拿出来说:SYSTEM_PROMPT_DYNAMIC_BOUNDARY。
Claude Code 把系统提示分成静态段和动态段,静态段(身份声明、系统规则、任务执行哲学等)在会话内只计算一次,并打上 cache_control 标记,命中 Anthropic API 的提示缓存后可以大幅降低 Token 成本。动态段(当前工作目录、Git 状态、记忆内容等)每轮重算,不走缓存。

多 Agent 场景里,Fork 子 Agent 会使用字节相同的占位结果(FORK_PLACEHOLDER_RESULT),确保所有子 Agent 共享同一个提示缓存前缀,缓存命中率因此更高。
这是对 Anthropic 自家 API 提示缓存机制的深度利用,而且是在系统设计层面就做进去的,不是事后优化。
最后的判断
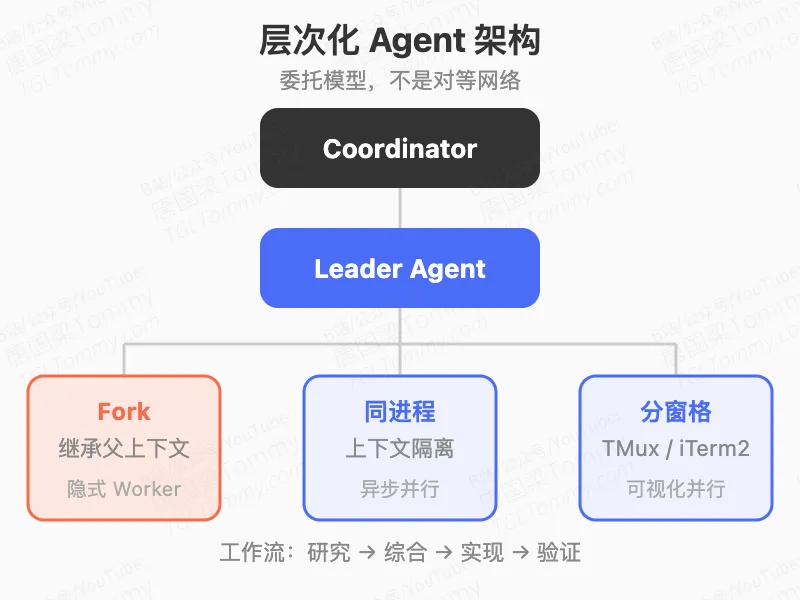
这份报告最后给出的总结我觉得比较准确:Claude Code 的记忆体系和安全机制,在当前业界 Agent CLI 实现里属于领先水平;工具调用体系(42+ 工具 + MCP + 流式执行器 + Pre/PostToolUse 钩子)达到了工程级成熟度;多 Agent 架构是层次化委托模型,不是对等网络,这个定位很关键。
不过报告也标出了 20 个”值得继续深挖”的点,包括一个名字叫 yoloClassifier.ts(52KB)的自动模式安全分类器,和几个仅对内部用户开放的工具(TungstenTool、SuggestBackgroundPRTool)。这些尚未完全还原。
从开源生态的视角看,Claude Code 选择了把大量架构复杂度封装进一个单体 CLI,而不是拆成可组合的模块。这个选择让它的开发者体验相当完整,但也意味着外部开发者想在此基础上做深度定制,门槛不低。
对做 Agent 系统开发的人来说,这份审计报告里的几个设计值得认真研究:投机执行的 COW 隔离思路、记忆的分类型 + 相关性检索设计、提示缓存分割策略,以及四级压缩体系的优雅退化逻辑。不一定要照搬,但这些设计背后的取舍思路是可以借鉴的。
。
进阶学习
👉如果你希望系统掌握大模型核心技术、以及Agent应用开发,推荐你学习我最新上线的精品课程:
📚这是一套从模型微调、部署,到强化学习训练的系统学习路线,课程以企业级落地为目标,你将掌握LLM核心原理、Agentic RAG、MoE/MLA/MTP机制拆解、PPO/GRPO强化学习与工业级DeepSeek-OCR多模态实战等,想系统掌握并落地这些能力,就从这门课开始。
💡本课程已在我的个人官网以及B站课堂上线,点击链接了解课程详情:
📺B站课堂(点击左下角“阅读原文”直接跳转)https://www.bilibili.com/cheese/play/ss556613313
🌐官网链接(国内访问需科学上网):https://www.tgltommy.com/p/deepseek
