夜雨聆风
夜雨聆风





Claude Code 51万行源码意外泄露,扒出了AI Agent最难的部分

这事发生在 2026 年 3 月 31 日,挺荒诞的。
Anthropic 的 CI/CD 流水线打包 Claude Code v2.1.88 时,没有正确配置.npmignore,把一个 59.8MB 的cli.js.map文件一起发布到了 npm 。
Source Map 是开发调试用的工具,里面有原始源码的完整内容。 Bun 打包器生成的 Source Map 默认附带sourcesContent字段——只要有这个文件,任何人用标准工具几分钟内就能还原所有 TypeScript 源码。
不是黑客,不是内鬼,就是一个流水线配置失误。
消息扩散速度极快。 30 分钟内, GitHub 上的克隆仓库积累了超过 5000 个 Star 。后来多个分析仓库的 Star 总数超过 50,000 。量子位、 36 氪、新智元全部跟进,标题都是”51 万行代码全部泄露””全网狂欢”。
全网狂欢了两天。但狂欢之后,真正有价值的部分开始浮出水面。
01 真正难的,不是模型,是 Harness
很多人看到 51 万行代码的第一反应是:这模型封装了多少东西?
但翻完源码之后,更准确的答案是:Claude Code 本质上是一个给模型套了一层精密外壳的系统。
这个外壳叫 Harness 。
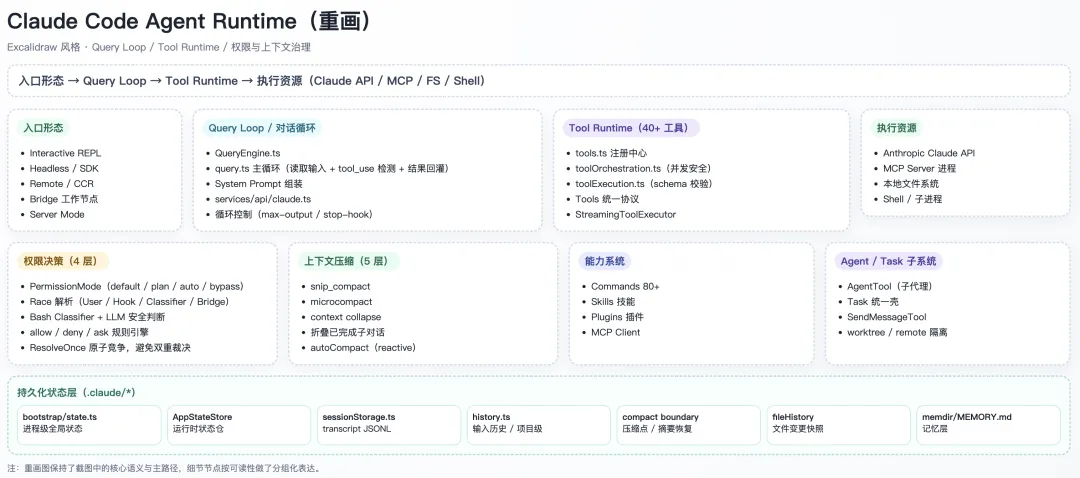
1884 个 TypeScript 源文件, 512,000 行严格类型的代码,基于 Bun 运行时, React 和 Ink 驱动终端 UI 。它不是一个聊天壳子,而是一个”本地运行时”——工具注册表、权限管理、记忆层、后台任务、 IDE 桥接、 MCP 集成、多代理编排,全部在这里。
逆向工程师 Vikash Rungta 的比喻很准确:Harness = Brain ( LLM )+ Body (工具、记忆、编排)。 模型是大脑, Body 负责让它在真实世界里行动。
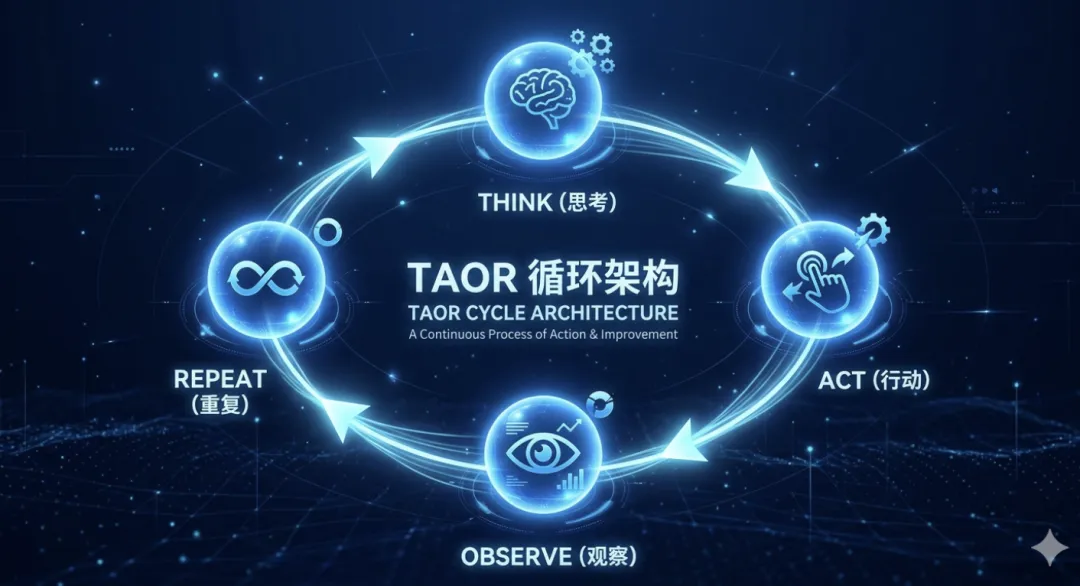
执行引擎叫 TAOR 循环: Think-Act-Observe-Repeat 。听起来复杂,核心逻辑大约只有 50 行代码。
更值得注意的是设计哲学:Orchestrator 越笨,架构越稳定。
它的 Orchestrator 被设计得极其”愚蠢”,只负责驱动循环、执行工具调用、感知结果。所有推理、决策、何时停止——全部交给模型自己。这和早期 LangChain 试图在框架层做各种”聪明编排”的路线截然相反。
工具层同样遵循”笨”哲学:不给模型配 100 个专项工具,只有 4 种能力原语——Read 、 Write 、 Execute 、 Connect。其中 Bash 是通用适配器,让模型能用任何开发者会用的工具: git 、 npm 、 docker ,通过 shell 自己组合。
我之前搭过一个 LangChain 工作流,写了七八个专项工具节点,改一次需求要改四个文件。换成这种”给个 shell 让它自己搞”的思路之后,反而稳多了。框架越聪明,越脆。
这里有一个反直觉的结论:随着模型变强,脚手架应该变薄,而不是变厚。 如果你每次模型升级都要往框架里加更多脚手架,说明你在对抗模型,而不是利用模型。
02 Context 是稀缺品,越干净越好
Context Collapse 是 Agent 系统最普遍的失败模式——上下文越来越满,记忆退化,幻觉增加, Agent 开始在自己积累的噪音里迷失方向。
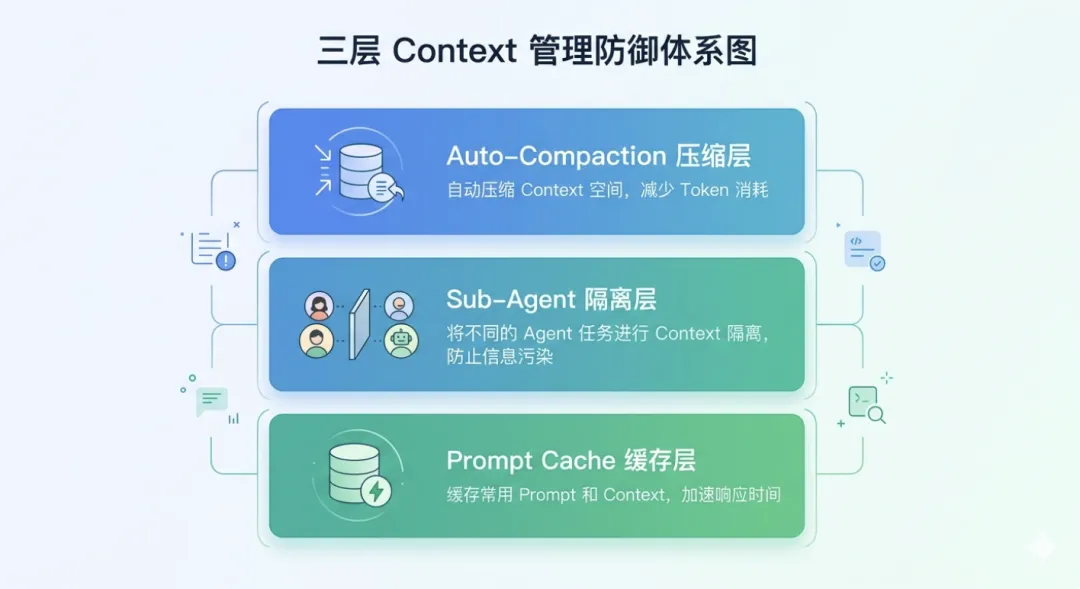
Claude Code 对 Context 的态度不是”越大越好”,而是把它当成需要主动管理的稀缺资源,建了三层防御体系。
第一层: Auto-Compaction 。 当 Context 使用量达到约 50%时自动触发,用 LLM 摘要替换原始对话轮次。不是简单截断,是压缩——重要信息不丢失,空间腾出来了。
第二层: Sub-Agent 隔离。 把重型探索、研究任务卸载给独立的子 Agent 。子 Agent 有自己的 Context 预算和 TAOR 循环,任务完成只返回一个摘要给主 Agent 。无论子任务消耗多少 token ,主 Agent 的 Context 完全不被污染。
第三层: Prompt Cache 经济学。 源码里有一个文件promptCacheBreakDetection.ts,追踪了 14 个 cache-break 向量——14 种会让 Prompt 缓存失效的情况。里面有一个函数名叫DANGEROUS_uncachedSystemPromptSection(),光是这个命名本身就是一种文档:这里加东西要小心,会破坏缓存。
一个血泪细节:源码注释里记录,每天有 1279 个 session 连续压缩失败超过 50 次,最严重的一个 session 失败了 3272 次,浪费了约 25 万次 API 调用。修复方案是 3 行代码——连续失败 3 次就停止重试。
Token 就是钱。这种细节,决定 AI 产品能不能活下去。
03 AI 的记忆,比你想的复杂 100 倍
大多数人想象”AI 记忆”就是:我纠正它,它记住了,下次不犯。
Claude Code 的设计者想得更深。
源码里有一段话,让我看了很久:
“Record from failure AND success. If you only save corrections, you will avoid past mistakes but drift away from approaches the user has already validated, and may grow overly cautious.”
翻译:记错误,也要记认可。只记纠正的话, AI 会越来越缩手缩脚。
你说”这个方向对”,它要记。你说”这个 PR 合并成一个是对的”,它也要记。你没有推翻它的方案,沉默本身也是认可信号。管理团队是同样道理——只有批评没有认可,下属会越来越保守, AI 也一样。
记忆系统在架构上分六层,每次会话启动时按层加载:
公司统一策略 → 项目 CLAUDE.md → 用户偏好 → Auto-Memory → 会话上下文 → 子 Agent 记忆
CLAUDE.md 是写给 AI 看的”入职手册”——你是谁、项目是什么、偏好是什么。越近的层级优先级越高:个人偏好优先于公司规范。
存储方式也反直觉:纯文件系统,不用向量数据库。 每条记忆是一个独立的 Markdown 文件,可以直接打开看、手动改、用 git 管理、 diff 、回滚。 MEMORY.md 是索引,最多 200 行,每条记忆不超过 150 字。
为什么不用向量数据库?源码没说。我的猜测是:能被人类审查的记忆,信任成本低得多。你知道 AI 在想什么、记着什么——这本身就是一种控制感。
还有一个惊艳的模块:AutoDream 。
提示词第一行写的是:”You are performing a dream — a reflective pass over your memory files.”(你正在做一个梦,对记忆文件进行反思性回顾。)
触发条件:距上次整理至少 24 小时,且期间至少有 5 个工作 session 。做梦四个阶段:
定向 → 收集 → 整合(处理”记忆漂移”)→ 修剪(删过时的,保持 200 行以内)
人脑睡眠时也是这样工作的——整理白天信息,去掉过时的,保留重要的。
我用 Claude Code 一段时间之后有个感受:同样的问题,隔两天再问它,它给的答案开始”记得”我上次的偏好了。这不是幻觉。 AutoDream 在后台一直跑着。

04 一个开源的同类实现: Velaris Agent 六层架构
看完 Claude Code 的架构,很多人的第一反应是:这能参考着自己做一个吗?
开源项目 velaris-agent[1] 走的就是这条路,定位是”AI 决策运行时框架( Decision Runtime Framework )”——把 Claude Code 这套设计思路,提炼成可复用的开源底层引擎。
架构是六层:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
和 Claude Code 的 TAOR 循环对应: Goal 解析 → 规划 → 决策 → 执行 → 评估,形成完整闭环。
两个差异点值得注意:
多维决策引擎——支持 quality/cost/speed 三维权重打分,可以按需配置,比如把成本控制放第一位:{ quality: 0.35, cost: 0.5, speed: 0.15 }。
预算闭环——会话级 token/USD 实时追踪, 80%预算时预警,超限后三个策略可选: compress (压缩上下文)、 downgrade (降级到便宜模型)、 stop (停止)。成本控制做进了运行时,不是事后看账单。
目前有两个验证案例: AI Token 成本优化( tokencost )和包机询价比价( flightcompare )。
做 AI 工具或者跨境业务的创业者,如果在考虑自建 Agent 层,这个项目值得作为起点。
写在最后
Claude Code 源码泄露这件事,本身是个意外。但它意外地完整展示了,一个成熟的自主 Agent 产品应该长什么样。
模型很重要,但模型之外的那层 Harness ,才是真正的工程壁垒: Context 怎么管、记忆怎么建、权限怎么设计、多 Agent 怎么编排——这些都是工程经验一点点堆出来的。
用 Claude Code 源码里的一行注释作结:
“随着模型变得更强,脚手架应该变薄,而不是变厚。”
但”变薄”不等于”没有”。那个薄到极致但精密到极致的外壳,才是 AI 产品能用、好用、可持续的真正基础。
你现在在用的 AI 工具, Harness 做得够精密吗?
参考链接
[1] velaris-agent: https://github.com/jiaweifreshair/velaris-agent