 夜雨聆风
夜雨聆风





Claude Code 源码泄露,我从里面学到了什么
大家好,我是蘑菇先生。
自 3 月 31 日 Anthropic Claude Code 源码泄露后,我每天都在“蒸馏”这份代码,我花了几天时间对着源码和公开材料[1]做了一轮自己的梳理,分享给大家。
一、整体规模
Claude Code 的交互界面是一个终端,但它背后的工程量远超一个 CLI 工具。
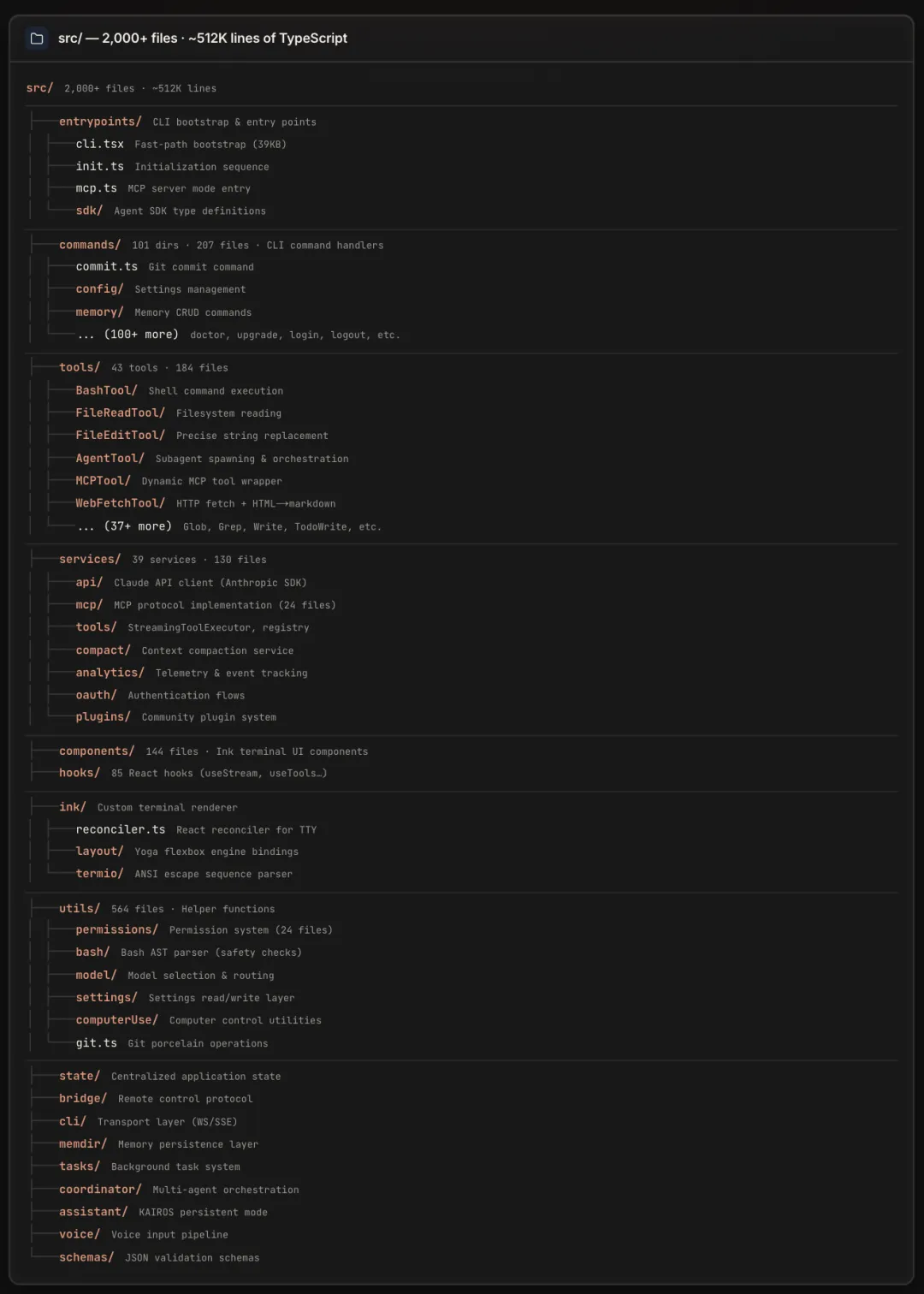
512K 行 TypeScript,2000+ 个文件。拣几个关键目录看:
-
src/tools/— 43 个内置工具,文件读写、Bash 执行、Web 搜索、子 Agent 调度都在这里 -
src/services/— 39 个服务模块,API 客户端、MCP 协议、上下文压缩、OAuth 各一套 -
src/components/+src/hooks/— 144 个 UI 组件、85 个 React hooks -
src/ink/— 自定义的终端渲染引擎,React Reconciler + Yoga flexbox -
src/coordinator/— 多 Agent 编排 -
src/utils/permissions/— 单独 24 个文件处理权限 -
src/memdir/— 记忆持久化层 -
src/bridge/— 远程会话协议(其中bridgeMain.ts一个文件 115K 行)
代码量大不一定说明什么,但它反映了一件事:围绕 LLM API 调用,需要处理的工程问题远比”发请求、拿响应”多得多。这 51 万行代码里,真正跟 API 通信相关的只占一小部分,其余都在处理”怎么决定调什么工具”、”怎么控制权限”、”怎么管理有限的上下文窗口”、”怎么让多个 Agent 协作”这些问题。
下面就沿着一次完整的使用流程来看这些模块:从启动,到核心循环,到循环里涉及的工具、权限、上下文、记忆,再到多Agent、扩展、安全。
二、启动
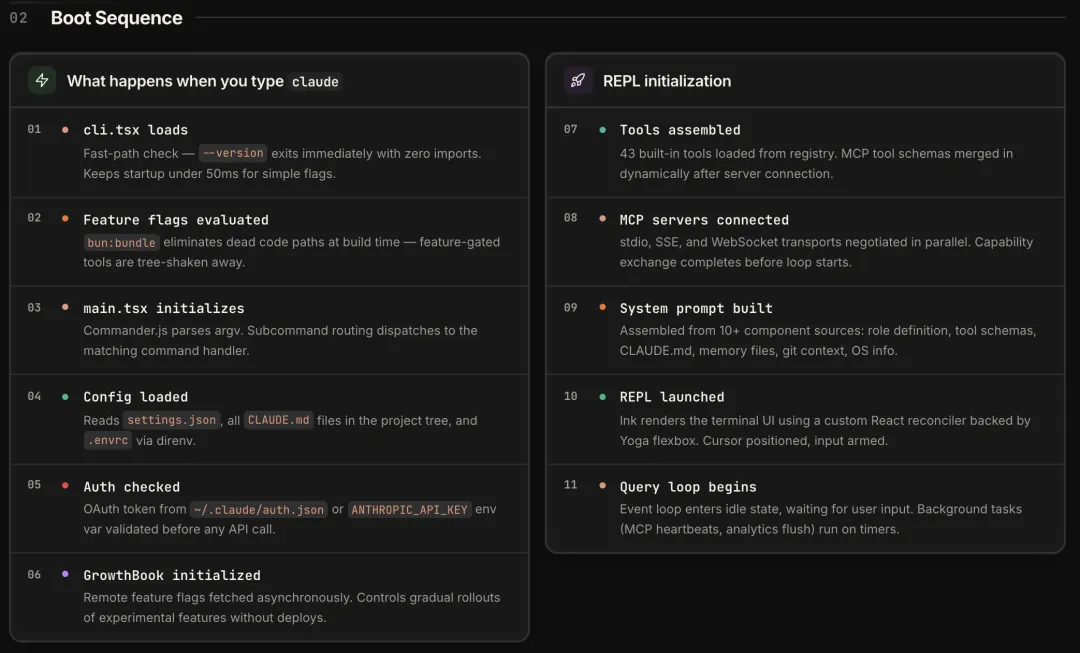
一切从启动开始。设计原则是:简单请求快进快出,复杂初始化按需延后。在终端输入 claude 回车,到光标闪烁可以打字,中间走了 11 步。
挑几个有意思的讲:
Step 1,cli.tsx 加载后先看是不是 --version 这种简单 flag,如果是,什么都不加载,直接打印退出。响应 < 50ms。查个版本号等两秒是不可接受的。
Step 2,构建时用 bun:bundle 做 tree-shaking (移除无关逻辑),被 feature flag 关掉的工具代码直接从产物中移除。所以不同账号装到的 Claude Code,二进制内容可能不一样。
Step 6,启动时异步拉 GrowthBook 的远程 feature flag,Anthropic 可以不发新版就开关功能做A/B Test。同一个版本号,不同用户看到的功能集可以不一样。
Step 7–8,工具注册和 MCP 服务器连接。43 个内置工具从注册表加载后,MCP 工具的 schema 还要等服务器连上才能动态合并进来。
Step 9,System Prompt 组装。不是读一个文件那么简单——它从 10 多个来源拼出最终的系统提示词,后面会专门说。
简单请求在第一步就退出了,不为复杂场景付启动成本;昂贵的网络操作放在后面并行跑。
启动完成后,系统进入核心循环——这才是 Agent 真正干活的地方。
三、核心循环
整个系统的核心是一个自动循环:模型调用工具 → 拿到结果 → 再调一次 API → 直到没有工具要调。这个循环决定了 Agent 的自主性和执行深度。
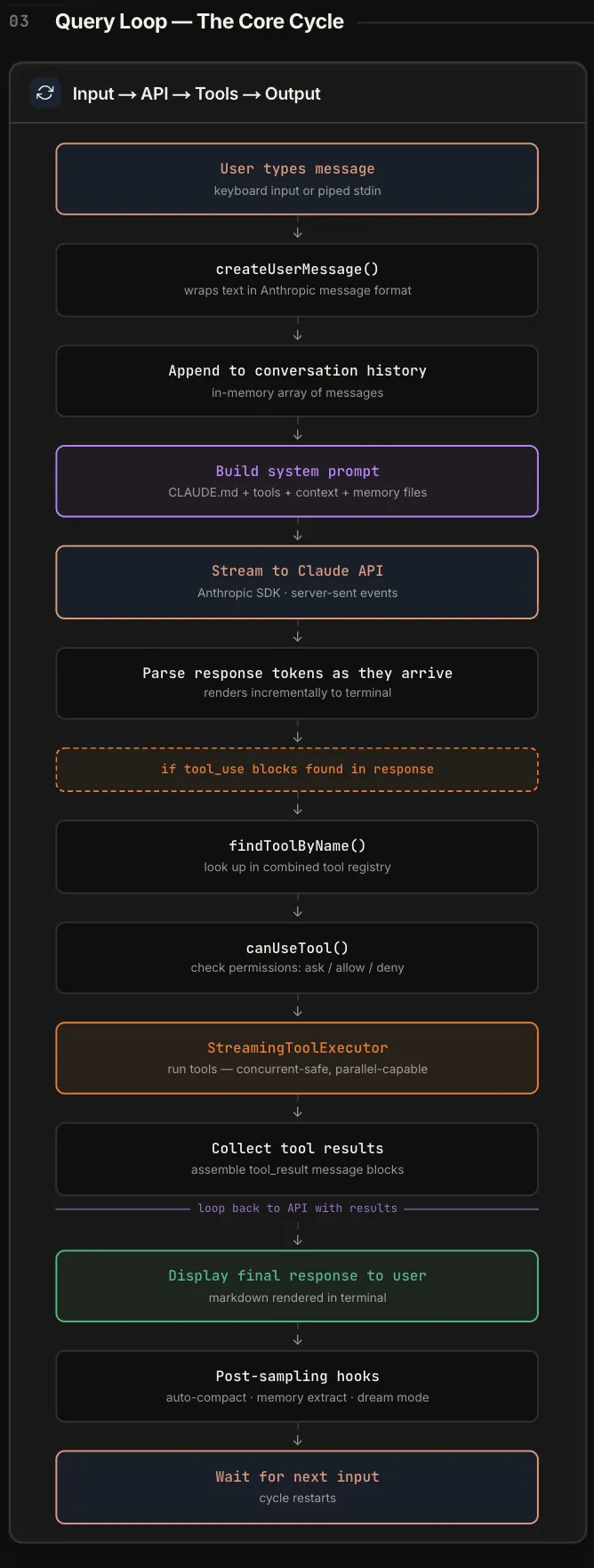
用文字描述一下这个循环:
用户输入 → 封装成 Anthropic 消息格式 → 拼上 System Prompt → 流式调 Claude API → token 边到边渲染 → 如果响应里有工具调用,走权限检查,然后执行工具 → 把工具结果拼回去,再调一次 API → 如此往复 → 直到 Claude 的响应里不再包含工具调用 → 显示最终结果 → 跑一些后处理(上下文压缩检查、记忆提取)→ 回到等待输入。
这个循环是 Claude Code 能”自主干活”的核心。一次用户输入之后,它可以自己连续调用多轮工具、多次请求 API,直到任务完成才停下来。循环赋予了自主性——Agent 和 chatbot 的区别,就在这个自动循环上。
几个工程细节:
-
token 到了就渲染,不等整个响应生成完。Agent 场景下一次响应可能包含大段 thinking,等完了再显示,用户会觉得卡住了。
-
多工具并行执行。Claude 可以在一次响应里同时调多个工具,
StreamingToolExecutor会并发跑它们。但每个工具要声明自己是否并发安全(isConcurrencySafe()),默认是false。文件写入、Bash 执行这些确实不能随便并发,保守一点是对的。 -
后处理(Post-sampling hooks) 在每轮 Agent 响应之后触发:检查上下文是否该压缩了、从对话中提取值得记住的信息写入记忆文件、可选的 “dream” 模式做知识整合。这些后处理用户感知不到,但它们让 Agent 在长时间工作中不会”遗忘”。这些后处理共享同一个基础设施——
forkedAgent:fork 出的子 Agent 与主 Agent 使用完全相同的 system prompt、工具列表和消息前缀,保证 prompt cache 命中,不额外付 cache creation 的钱。记忆提取、后台整理、投机执行、Session Memory、Magic Docs——五个子系统都建立在这个模式上。
投机执行
循环赋予了自主性,但 Agent 仍然要等用户按下回车。投机执行(Speculative Execution)把这个限制也去掉了——用户还在想下一步,Agent 已经猜到你要说什么并开始干了。
做法是:每轮结束后,系统生成一个”预测的用户下一条消息”,然后启动 forked agent 提前执行。关键问题是安全——如果猜错了,已经写的文件怎么办?
答案是 Overlay Filesystem。写操作不落到真实文件系统,而是写入一个临时目录(~/.claude/tmp/speculation/<pid>/<id>/)。读操作先查 overlay,没有才读主目录——这是个 copy-on-write 机制。用户接受猜测时,overlay 里的文件 copyFile 回主目录;拒绝时,整个 overlay 直接删除。
这个特性目前仅限 Anthropic 内部员工,但它指出了一个方向:Agent 不再被动等待指令,而是主动预测并提前行动。overlay filesystem 让这种主动性是安全的——猜错了,代价为零。
循环和投机执行描述了 Agent 怎么运转,但循环里每一步调用的是什么?答案是工具。
四、工具系统
Agent 能做什么,不取决于 prompt 里怎么描述,而取决于注册了哪些工具。工具系统是 Agent 的能力注册表,也是能力边界的硬约束。
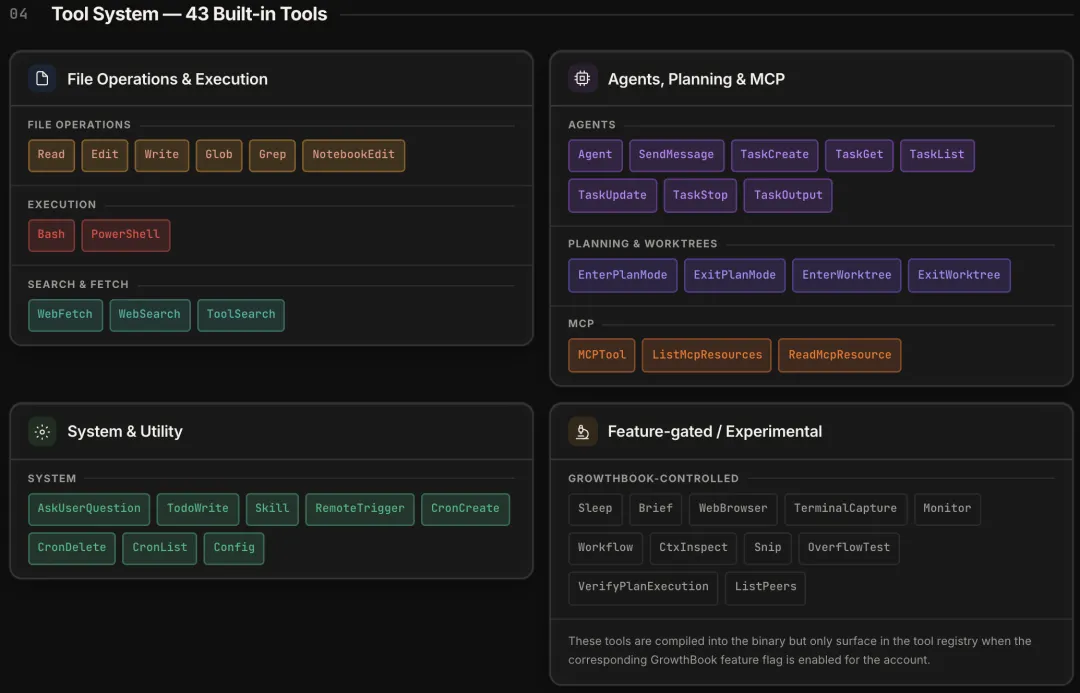
Claude Code 有 43 个内置工具,所有工具实现同一个接口(src/Tool.ts,793 行)。
接口里几个关键字段:
-
call()— 执行逻辑 -
checkPermissions()— 这个工具需要什么权限 -
isConcurrencySafe()— 能不能并发,默认 false -
isReadOnly()/isDestructive()— 只读还是有破坏性,默认都是 false -
shouldDefer/alwaysLoad— 是否惰性加载 -
searchHint— 3–10 个词描述这个工具能干嘛,供 ToolSearch(工具搜索)匹配
buildTool() 工厂函数合并默认配置和工具特定的覆写。新增工具只要实现接口、注册进去,不用改核心循环的代码。
工具按功能分组:
-
文件操作(Read/Edit/Write/Glob/Grep) -
执行(Bash/PowerShell) -
搜索(WebFetch/WebSearch) -
Agent 任务管理(Agent/SendMessage等) -
规划与隔离(EnterPlanMode/EnterWorktree) -
MCP(MCPTool/ListMcpResources等) -
系统(CronCreate/Skill/AskUserQuestion)
还有一组被特性开关关着的实验性工具:Sleep、WebBrowser、Monitor、Workflow、TerminalCapture 等。它们编译进了产物,但 Claude 看不到它们——看不到就调不了,可见性决定了可调用性。这个原则在后面权限系统里会反复出现。
值得一提的是,Agent 不只是盲写代码。src/services/lsp/ 实现了完整的 Language Server Protocol 客户端,Agent 编辑文件后,LSP 服务器会推回编译错误和警告,这些诊断信息被转成附件注入下一轮上下文。Agent 写完代码能”看到”红线,不用等用户告诉它哪里报错。
工具赋予了 Agent 强大的能力——读写文件、执行 shell 命令、访问网络。但能力越大,失控的风险也越大。
下一个问题自然是:怎么控制这些工具的使用?
五、权限系统
Claude Code 的答案是做三层,每一层都不信任前面的层。可以叫它渐进式信任——默认不信任,逐层验证,只有全部通过才放行。
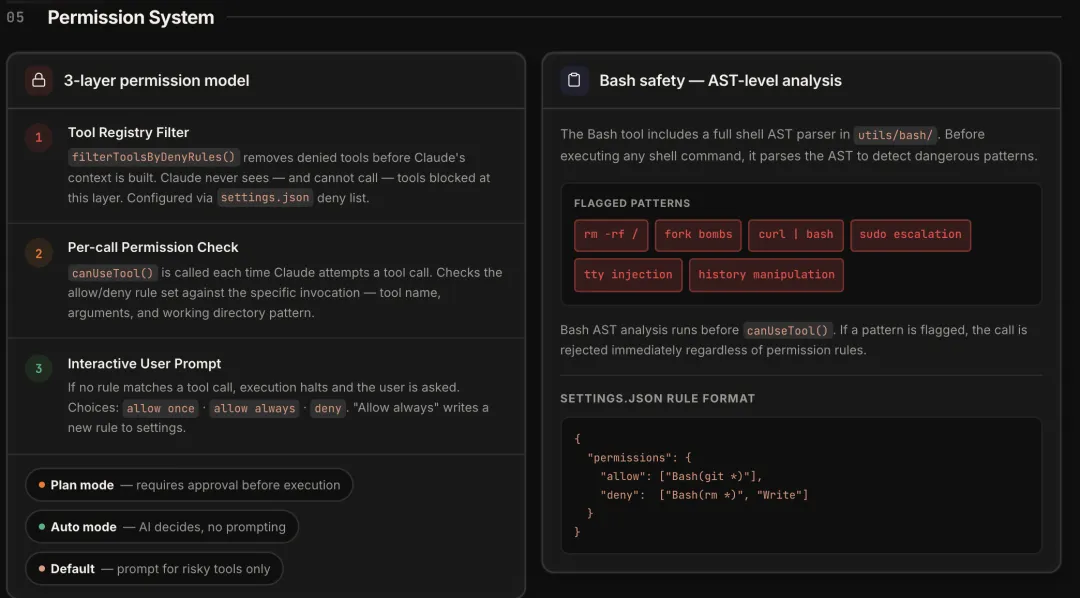
第一层,工具注册表过滤。filterToolsByDenyRules() 在给 Claude 构建上下文之前,就把被禁的工具从列表里去掉。Claude 根本不知道这个工具存在。这比在 prompt 里写”不要用这个工具”靠谱得多——从协议层面消除可能性,而不是靠模型自觉。
第二层,逐次调用检查。每次 Claude 尝试调用工具,canUseTool() 都会跑一遍规则匹配。规则来源有八层优先级(user > project > local > flag > policy > cli > command > session),行为分 allow(放行)/ deny(拒绝)/ ask(询问用户)/ passthrough(交给下一层)四种。
第三层,用户确认。前两层都没命中规则时,暂停执行问用户。Auto 模式下有个特别的做法:classifyYoloAction() 让 Claude 自己评估这次工具调用是否安全——用一个快速的分类模型给操作打风险等级(LOW / MEDIUM / HIGH)。
权限模式有六种,从交互式确认(default)到完全绕过(bypassPermissions),中间还有 plan(需要明确批准)、auto(AI 自主分类)、dontAsk(自动拒绝)、acceptEdits(只放行编辑操作)。
Bash 单独做了更重的处理。utils/bash/ 里有一个完整的 shell AST 解析器,在执行命令前做静态分析。不是用正则匹配命令字符串,而是解析成语法树再检查。会拦截的模式包括 rm -rf /、fork bomb、curl | bash、sudo 提权、TTY 注入、历史记录篡改。sleep N(N ≥ 2 秒)也会被拦——防止 Agent 用 sleep 阻塞执行流。这个 AST 分析跑在 canUseTool() 之前——即使用户配置了允许所有 Bash 命令,这些模式照样被拒。
配置长这样:
{"permissions": {"allow": ["Bash(git *)"],"deny": ["Bash(rm *)", "Write"] }}工具和权限决定了 Agent “能做什么”。但 Agent 做得好不好,还取决于它当前”知道什么”——也就是上下文窗口里有哪些信息。
六、上下文管理
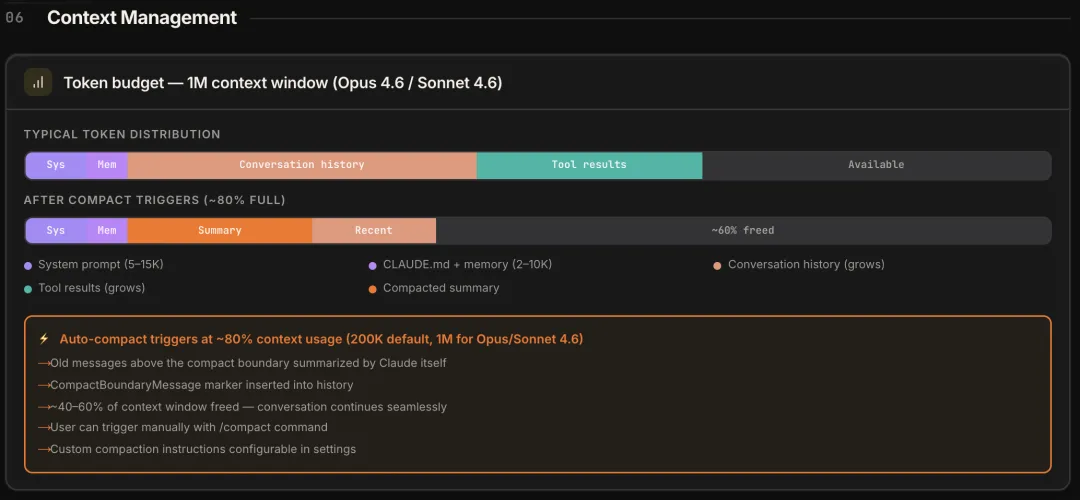
上下文窗口是有限的——默认 200K token,Opus 4.6 / Sonnet 4.6 可以开到 1M。上下文里有什么信息,Agent 就能参考什么;被压缩掉的,就”忘了”。围绕这个有限窗口,要解决三个问题:往里面放什么、满了怎么办、怎么控制成本。
构建:往上下文里放什么
每次 API 调用的上下文由 System Prompt + 对话历史 + 工具 schema 组成。其中 System Prompt 占 5K–15K token,是最稳定也最重要的部分。
Claude Code 的 System Prompt 从六层来源动态拼装:
-
Override — --system-promptflag 或 loop 模式,最高优先级 -
Coordinator — 多 Agent 协调模式专用 -
Agent — 子 Agent 专用 -
Custom — 用户自定义 -
Default — 默认角色定义和能力描述 -
Append — 追加内容
除了系统层的 prompt,用户通过 CLAUDE.md 注入项目级指令,同样加载进上下文。加载有四层优先级:
/etc/claude-code/CLAUDE.md(组织级)→ ~/.claude/CLAUDE.md(用户级)→ 项目 CLAUDE.md / .claude/CLAUDE.md / .claude/rules/*.md(项目级)→ CLAUDE.local.md(本地覆写,通常 gitignore)
支持 @include 指令引用其他文件,frontmatter 里的 paths: 字段可以做 glob 匹配控制生效范围(比如只对 src/**/*.ts 生效),有环形引用检测。HTML 注释会被剥离。
压缩:满了怎么办
对话历史和工具返回结果会不断增长,总有撑满的时候。Claude Code 用三层策略应对,粒度从粗到细:
AutoCompact(全局压缩)。token 用量到 ~80%(200K 窗口下约 187K,有 13K 缓冲 AUTOCOMPACT_BUFFER_TOKENS)时自动触发。把旧消息发给 Claude 自己做摘要,插入一个 CompactBoundaryMessage 标记,释放 40%–60% 空间。设了断路器:连续 compact 失败 3 次就不再尝试(MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3)。到达 20K 剩余时给 early warning,到 3K 时阻塞新请求。
MicroCompact(单条压缩)。不等到全局阈值,对单个工具返回的大块结果做即时压缩——但只对 Bash、FileRead、Grep 的输出做。一个 cat 命令输出了 3000 行日志,MicroCompact 当轮就把它压成摘要,避免一次大输出直接撑满窗口。还有一个时间维度的触发条件:当距离上次 API 调用超过 60 分钟(用户离开又回来),服务端 prompt cache 已经过期,这时候主动清理旧的 tool results——反正 cache 要重建了,不如趁机减负。
Post-compact 恢复。压缩不可避免地丢信息,但有些信息丢了会出问题——比如正在改的文件内容。compact 之后,自动重新读取最近用到的 5 个文件(每个 ≤ 5K token,总计 25K),把关键上下文补回来。
成本:Prompt Cache 管理
构建和压缩解决了”放什么”和”怎么腾空间”,但还有成本问题。System Prompt + 工具 schema 每次 API 调用都要发送,Agent 一个任务可能循环调用十几次,如果每次都重新计算这些 token 的费用,成本很高。prompt cache 让相同前缀的 token 只付一次钱,cache 命中和 miss 之间差的就是真金白银。
源码分析里专门把 prompt cache 管理列为”significant competitive differentiator”。做法是两阶段检测:调用前,recordPromptState() 记录完整快照(系统提示词、工具 schema 哈希、模型、effort 等级等)。调用后,checkResponseForCacheBreak() 检测 cache miss,并做归因分析——定位是哪个维度变了导致缓存失效。
这也解释了为什么 System Prompt 的动态内容(当前时间、工作目录)要单独标记为 DANGEROUS_uncachedSystemPromptSection(),通过 SYSTEM_PROMPT_DYNAMIC_BOUNDARY 和缓存友好的内容隔开——叫 DANGEROUS_ 不是因为内容危险,而是因为它”对 cache 有害”。构建影响缓存,缓存影响成本,三个子问题环环相扣。
七、记忆系统
上下文管理解决的是单次会话内的信息存活问题。但 Agent 不只工作一个会话——今天改了一半的代码,明天接着改,上周踩过的坑下周不应该再踩。跨会话的信息持久化,就是记忆系统要解决的问题。
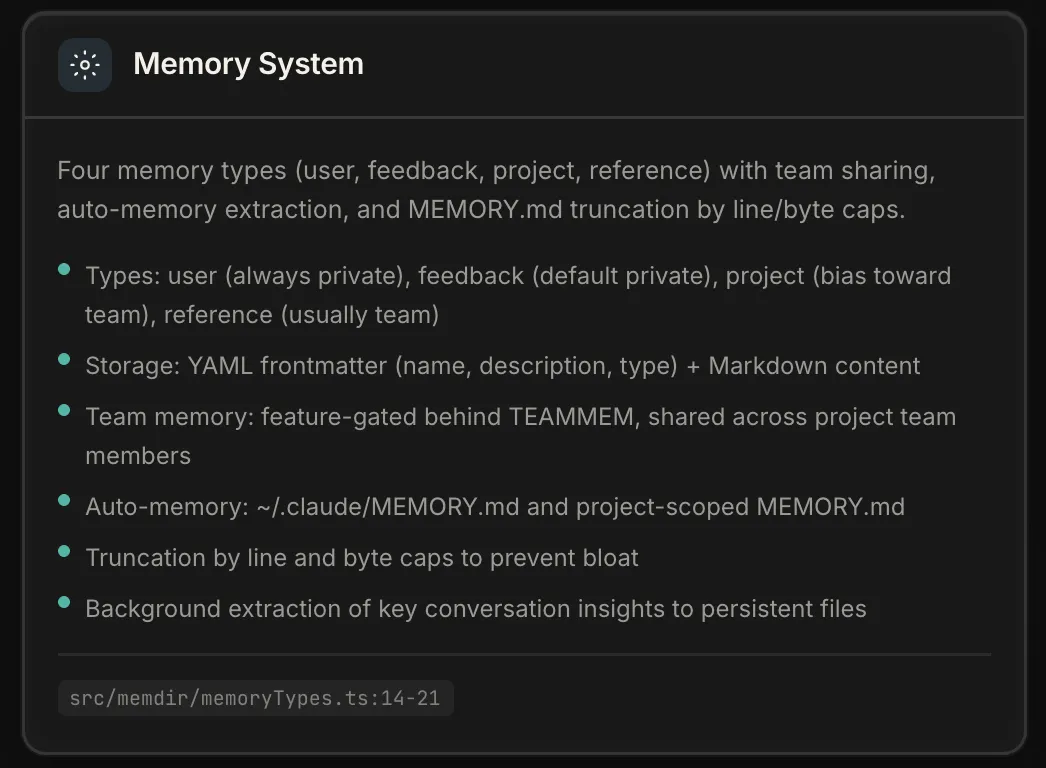
记忆系统要回答四个问题:存在哪、存什么、怎么取、怎么维护。
存储与类型:文件系统 + 四种信息
整套记忆没有 embedding,没有向量检索,没有 RAG。就是一个目录里的 markdown 文件,存在 ~/.claude/projects/<sanitized-git-root>/memory/ 下。每个记忆文件的格式是 YAML frontmatter + Markdown 正文。
存什么有明确边界。
源码注释写得很直白:”Memories are constrained to four types capturing context NOT derivable from the current project state“(记忆只存不能从项目当前状态推导出来的信息)。代码模式、架构、git 历史,这些能 grep 到的东西,不该存为记忆。
-
user(用户画像)— 始终私有。角色、偏好、知识背景。让 Agent 对资深工程师和编程新手用不同方式协作。 -
feedback(行为反馈)— 默认私有。纠正和认可都要记。源码强调:”Record from failure AND success: if you only save corrections, you will avoid past mistakes but drift away from approaches the user has already validated“(只记纠错会让 Agent 越来越保守,丢掉被验证过的好做法)。每条 feedback 要求写 Why: 和 How to apply:,让 Agent 遇到边界情况能自己判断,而不是盲目套规则。 -
project(项目动态)— 倾向团队共享。在做什么、为什么做、截止时间。相对日期要转绝对日期——记忆跨会话存活,”周四” 过几天就没意义了。 -
reference(外部指针)— 通常团队共享。Linear 哪个项目跟踪 bug、Grafana 哪个 dashboard 值得关注。
团队共享记忆在 TEAMMEM 特性开关后面,启用后记忆分 private 和 team 两个目录。团队记忆路径做了路径遍历和符号链接逃逸检测;projectSettings 被排除在记忆路径覆写之外——防止恶意仓库通过设置 autoMemoryDirectory: "~/.ssh" 获得敏感目录写权限。
检索:模型即检索引擎
存进去的记忆怎么在需要时找到?MEMORY.md 是索引文件,每行一条 - [Title](file.md) — 一句话描述,限制 200 行 / 25KB,始终加载在上下文里。具体内容存在各个 topic 文件中。
检索分两层:常驻层——MEMORY.md 索引始终可见;按需层——findRelevantMemories.ts 扫描目录读所有文件的 frontmatter,把清单发给 Sonnet 做一次 side query(旁路查询),让 Sonnet 选出最多 5 个最相关的文件加载进上下文。策略是宁缺毋滥——不确定有用就不加载。搜索历史上下文时用 Grep 在 .md 和 .jsonl 里做关键词匹配。
记忆还有新鲜度标注:超过 1 天的记忆附带过时警告,提醒 Agent 在断言事实前先验证当前代码。这是因为用户反馈旧记忆里的 file:line 引用让过时信息听起来更权威而不是更可疑。
维护:两个后台 Agent
记忆的写入和整理不靠用户手动管理,有两个后台机制自动维护:
extractMemories——每轮 Agent 响应结束后触发的 forked agent,与主对话共享 prompt cache。分析最近的对话,提取值得记住的信息写入记忆文件。它和主 Agent 互斥——如果主 Agent 本轮已经写过记忆,extractMemories 就跳过,避免重复。工具集严格限制为只读操作 + 记忆目录内写入,最多跑 5 轮。
autoDream——后台记忆整理。触发条件:距上次整理 ≥ 24 小时 + 期间 ≥ 5 个新会话 + 无其他进程在整理。触发后启动 forked subagent 做四步:Orient(读已有记忆)→ Gather(grep 会话记录搜关键信息)→ Consolidate(合并新信息、删过时内容、相对日期转绝对日期)→ Prune(保持索引在 200 行内)。这个 subagent 同样只有只读 Bash + 记忆目录写入权限。
KAIROS(常驻 Agent)模式下策略不同:日常记忆 append 到日志文件(logs/YYYY/MM/YYYY-MM-DD.md),由 Dream 统一蒸馏成索引和 topic 文件——常驻会话是永续的,追加写比维护实时索引更合适。
除了跨会话的长期记忆,还有一层会话内的工作记忆——Session Memory。它用 forked subagent 定期从对话中提取关键信息,写入一个 per-session 的 markdown 文件。长期记忆记住”这个用户偏好 TypeScript”,Session Memory 记住”这次会话正在重构 auth 模块,已经改了三个文件”。两层配合,构成完整的”长期记忆 + 工作记忆”体系。
到这里,循环、工具、权限、上下文、记忆——Agent 运转的核心机制都讲完了。接下来看几个支撑性的系统:模型选择与成本、多 Agent 协作、扩展体系、安全。
八、模型、定价与成本
上面这些机制都在调用模型 API,但调哪个模型、花多少钱?
用哪个模型
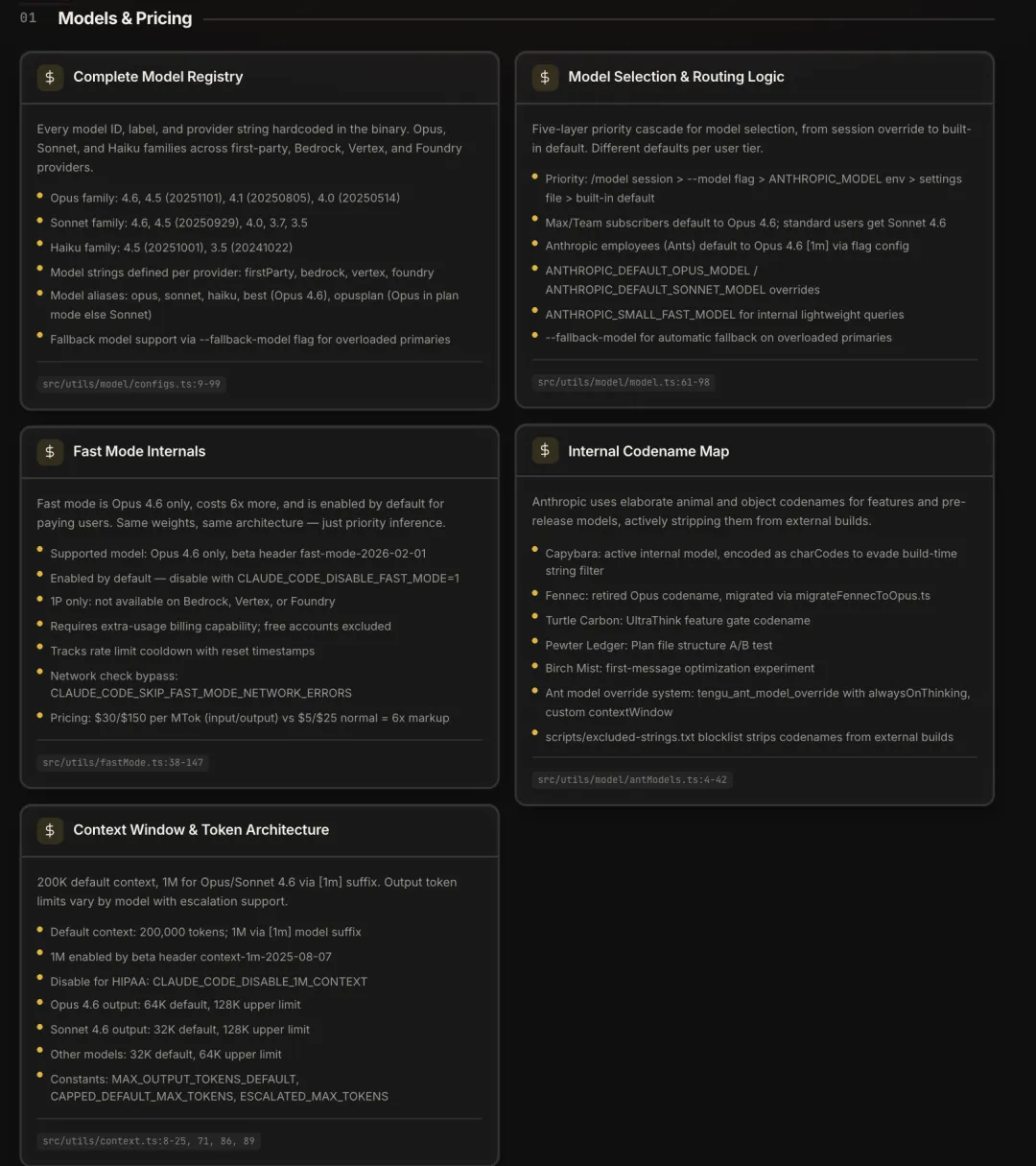
源码里硬编码了完整的模型列表:Opus 4.6/4.5/4.1/4.0,Sonnet 4.6/4.5/4.0/3.7/3.5,Haiku 4.5/3.5。每个模型在四个 provider 下各有 ID:firstParty(Anthropic 直连)、bedrock(AWS)、vertex(Google Cloud)、foundry。
模型选择有五层优先级:/model > --model > ANTHROPIC_MODEL 环境变量 > settings > 内置默认。默认值跟账号等级挂钩:Max/Team 用 Opus 4.6,普通用户用 Sonnet 4.6,Anthropic 内部员工(Ants)默认 Opus 4.6 [1m](100 万上下文)。还有 --fallback-model 参数在主模型过载时自动切备选。
花多少钱:Fast Mode
选好模型后,还有定价模式的选择。Fast Mode 只支持 Opus 4.6,通过 beta header fast-mode-2026-02-01 启用,对付费用户默认开。
定价是普通模式的 6 倍——input $30/MTok,output $150/MTok,对比普通的 $5\$25。模型权重和架构完全一样,付的是优先排队的钱。仅限 Anthropic 一方(1P)可用,Bedrock/Vertex/Foundry 不行。可以用 CLAUDE_CODE_DISABLE_FAST_MODE=1 关掉。
钱花到哪儿了
cost-tracker.ts 按模型分别记录各类 token 数,对照定价表算出 USD 成本。同时追踪代码行变更、API 耗时和墙钟耗时(可以算出等待队列的时间)。数据按 session 持久化,恢复会话时自动加载。
内部代号
源码里散落着各种内部代号:Capybara(当前活跃模型名,用 charCode 编码躲过构建时的字符串过滤器)、Fennec(已退役的 Opus 代号)、Turtle Carbon(UltraThink)、Pewter Ledger(Plan Mode A/B 测试)等。还有 11 个活跃的 migration 脚本处理这些迁移。
前面讲的都是单个 Agent 的运转。但复杂任务往往需要分工——一个 Agent 改前端,另一个改后端,第三个跑测试。
九、多 Agent 协作
Claude Code 的多 Agent 设计核心是:所有 Agent 跑在同一进程内共享状态,但权限严格分级——只有 Coordinator 能跟用户交互和做最终决策。
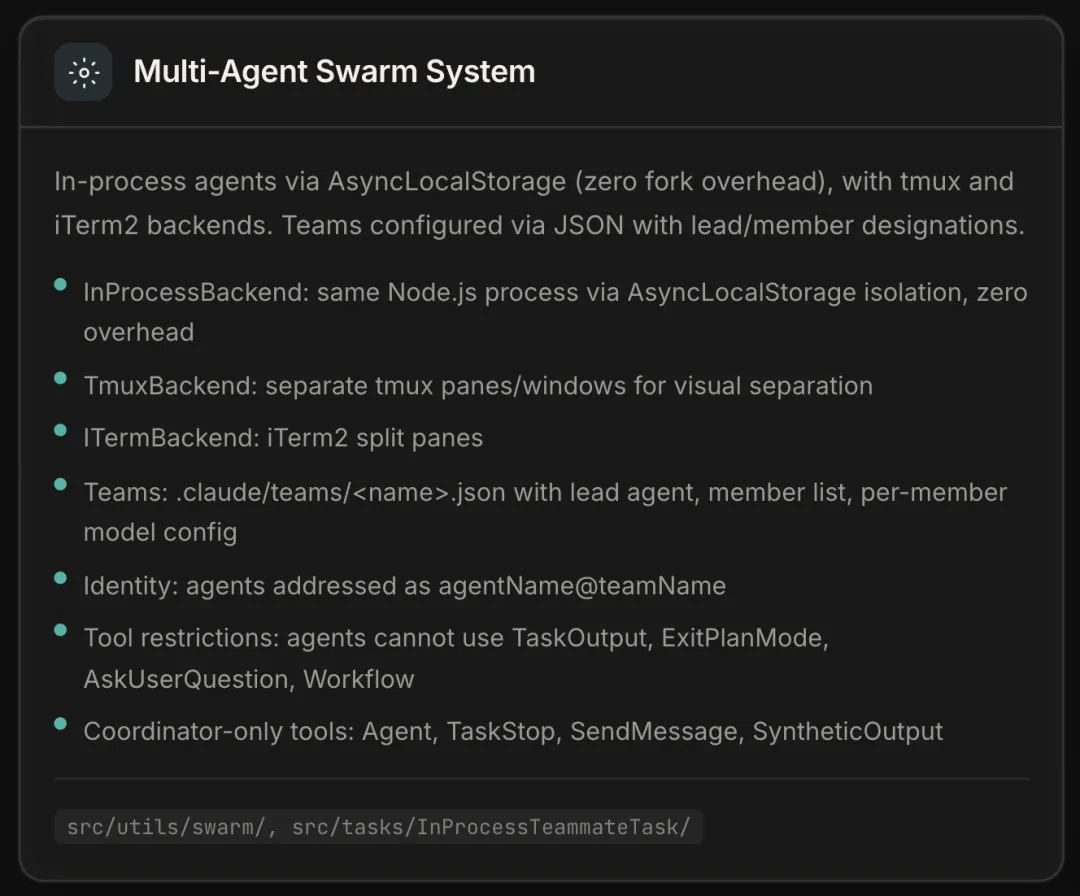
运行时:三种后端
多个 Agent 怎么跑起来?有三种后端:
-
InProcessBackend(默认)— 同一 Node.js 进程内,用 AsyncLocalStorage隔离各 Agent 的上下文,零 fork 开销 -
TmuxBackend — 用 tmux pane 做视觉分离 -
ITermBackend — 用 iTerm2 split pane
进程内隔离做默认是合理的——Agent 之间要频繁通信和状态共享,AsyncLocalStorage 给每个 Agent 独立的上下文链,但共享同一个事件循环和内存,通信不需要序列化。
组织与分权
Agent 跑起来之后,谁干什么、谁有什么权限?Teams 通过 .claude/teams/<name>.json 配置,指定 lead agent 和成员列表,每个成员可以独立配模型。Agent 之间用 agentName@teamName 的格式寻址。
关键的设计决策是权限分级:子 Agent 不能用 TaskOutput、ExitPlanMode、AskUserQuestion、Workflow 这些工具——流程控制权和用户交互权只在 Coordinator 手里。Coordinator 独占 Agent、TaskStop、SendMessage、SyntheticOutput 等工具。这保证了多 Agent 系统的控制流是清晰的:只有一个角色跟用户说话,只有一个角色做最终决策。
除了横向的多 Agent 协作,还有一种纵向的协作模式——Advisor Tool(顾问工具)。主 Agent 在工作过程中可以调用一个更强的 reviewer 模型做审查。这不是本地工具,而是 server_tool_use:调用时整个对话历史被转发给 advisor 模型。Prompt 里明确要求”在写代码之前、在确定方案之前、在认为任务完成时”都应该先咨询 advisor。Swarm 是平行分工,Advisor 是垂直的”执行-审查”关系——让 Agent 在行动前多一个检查点。
数据共享与隔离
多个 Agent 并行工作时,怎么交换数据又不互相干扰?临时数据交换通过 Scratchpad 目录,权限 0o700,有路径遍历防护。需要代码隔离时,用 Git Worktree(工作树)创建独立工作目录,node_modules 用符号链接共享(避免重复安装),进入 worktree 时清空记忆和 prompt 缓存,退出时执行清理 hook。
多 Agent 是 Anthropic 自己对系统能力的扩展。但 Claude Code 也开放了四种机制让外部接入——这就是扩展体系。
十、扩展体系
四种扩展机制覆盖不同层次,思路一致:让外部能力以标准化的方式接入 Agent 的工具和行为体系。
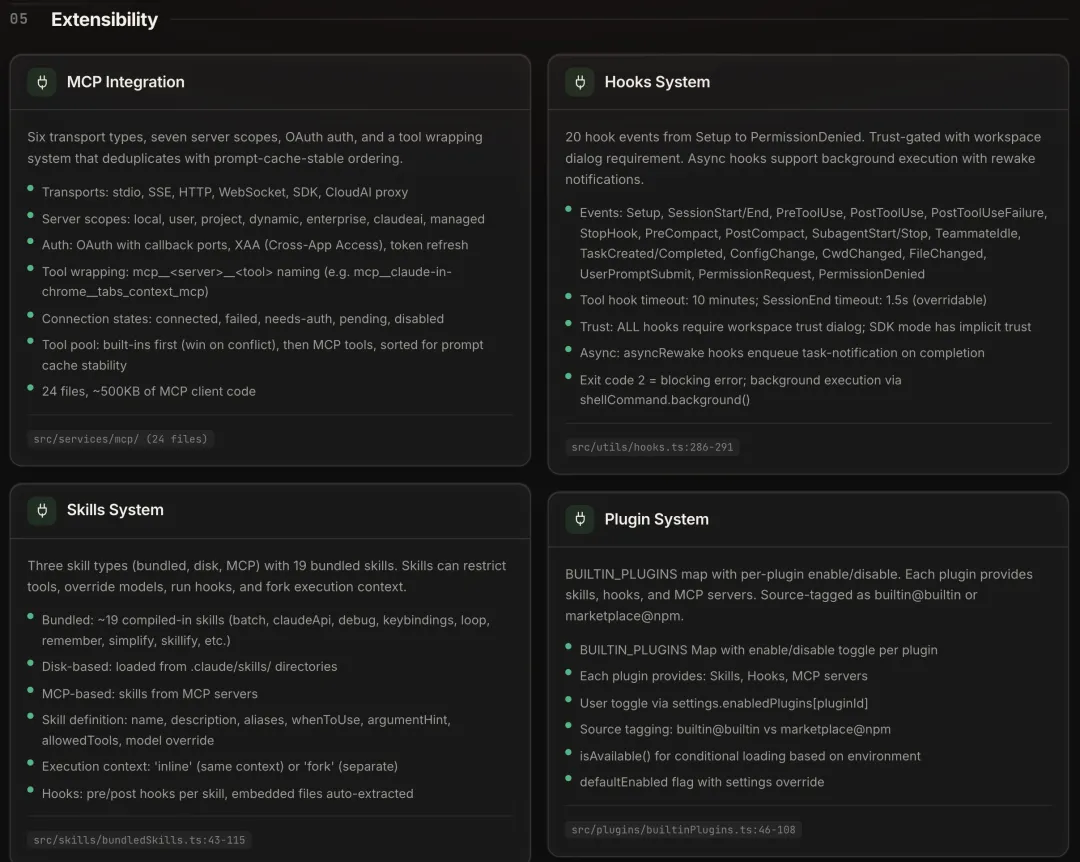
MCP(Model Context Protocol)
services/mcp/ 有 24 个文件,约 500KB 代码,实现了完整的 MCP 协议。
六种传输协议:stdio(本地子进程)、SSE、HTTP、WebSocket、SDK、CloudAI proxy。七种服务器作用域:local、user、project、dynamic、enterprise、claudeai、managed。支持 OAuth 认证(带回调端口和 token 刷新)和 XAA(Cross-App Access)。
MCP 工具在 Claude 的工具列表里以 mcp__<server>__<tool> 的格式命名。冲突时内置工具优先。工具列表的排序经过处理,保证 prompt cache 稳定——排序不变,cache 就不会因为工具列表重排而 break。
MCP 服务器的连接状态有五种:connected、failed、needs-auth、pending、disabled。
Skills
三种类型:约 19 个内置 bundled(batch、claudeApi、debug、keybindings、loop、remember、simplify、skillify 等)、用户放在 .claude/skills/ 目录的 disk-based、来自 MCP 服务器的 MCP-based。
每个 Skill 定义包括:name、description、aliases、whenToUse(触发条件描述)、argumentHint、allowedTools(工具白名单)、model 覆写。执行上下文分 inline(在当前对话上下文里跑)和 fork(开独立上下文),支持 pre/post hooks(前置/后置钩子)。
Hooks
20 种事件覆盖了 Agent 生命周期的关键节点:从 SessionStart/End、PreToolUse/PostToolUse,到 SubagentStart/Stop、FileChanged、PermissionDenied 等。所有 hook 需要通过工作区信任确认才能运行。
20 个事件不只是一个长列表,它反映的设计思路是:Agent 的每个行为节点都是可观测、可拦截的。你可以在文件写入后自动跑 eslint,在 session 结束前保存状态,在权限被拒绝时记日志。不是一个封闭的黑盒,而是一个每一步都可以被外部介入的流水线。
Plugins
通过 BUILTIN_PLUGINS Map 管理,每个 plugin 可以提供 Skills、Hooks 和 MCP servers 三类扩展。source 标签区分 builtin@builtin(随二进制发布)和 marketplace@npm(npm 市场安装)。每个 plugin 有 isAvailable() 方法做环境检测,defaultEnabled 控制默认开关状态,用户可以在 settings 里覆写。
能力越开放,安全越重要。前面权限系统管的是”Agent 调工具时怎么控制”,这一章看的是更广的安全问题:prompt injection、运行环境、通信通道。
十一、安全
安全设计的核心思路是:每个攻击面单独建模、逐层防御,不依赖单一机制。
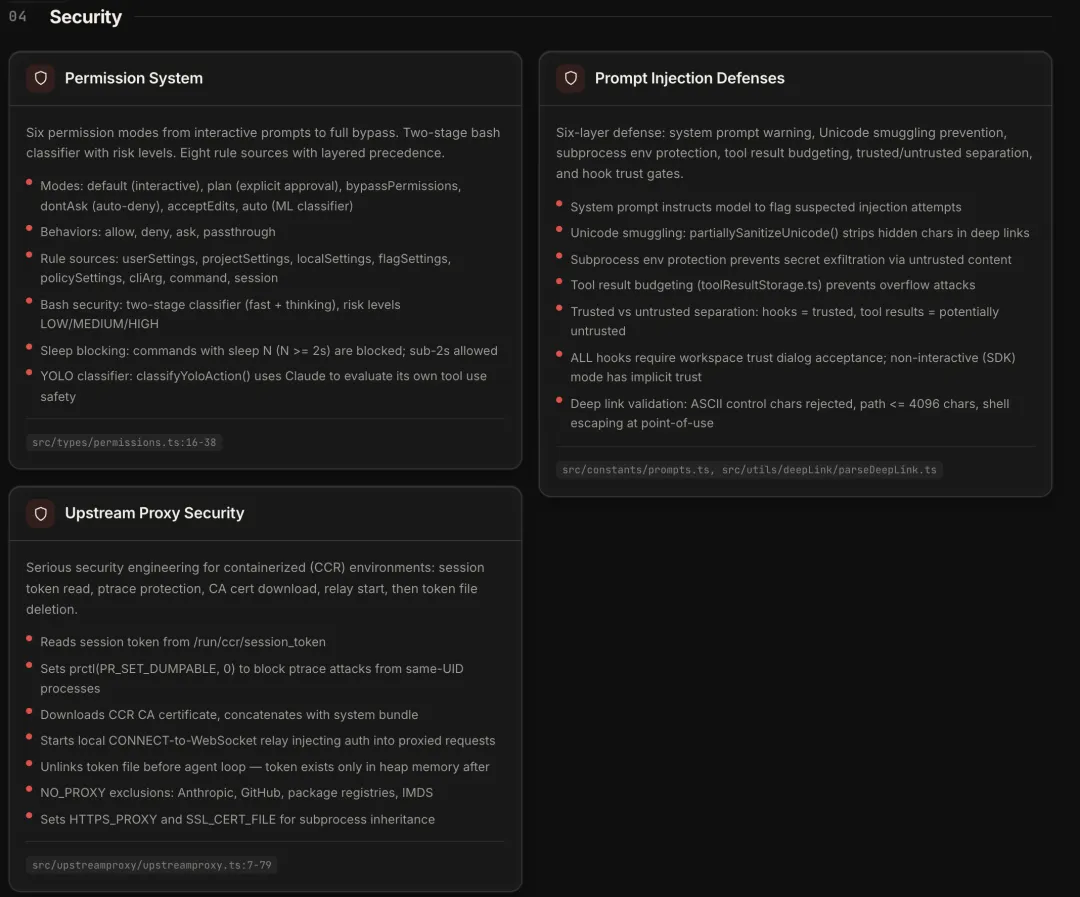
按攻击面分三块:模型层的 prompt injection、运行时环境的 credential 保护、通信通道的加固。
模型层:Prompt Injection 防御
六层处理,由外到内:
-
系统提示词里写了识别和标记注入尝试的指令 -
partiallySanitizeUnicode()剥离 deep link 中的隐藏 Unicode 字符(防 Unicode smuggling) -
子进程环境变量保护,防止不受信的工具输出泄露 secret -
toolResultStorage.ts对工具返回结果做大小预算控制,防溢出攻击 -
可信/不可信内容分开标记——hooks 产出是可信的,工具返回结果标记为潜在不可信 -
所有 hook 执行前必须通过工作区信任确认
运行时:CCR(容器化远程执行)
Prompt injection 防的是模型被误导,CCR 防的是运行环境里的 credential 泄露。容器化环境里的安全处理更细致:从 /run/ccr/session_token 读取会话 token → 设 prctl(PR_SET_DUMPABLE, 0) 阻止同 UID 进程的 ptrace → 下载 CCR CA 证书并与系统证书包合并 → 启动本地 CONNECT-to-WebSocket 中继 → 删除 token 文件,然后才进入 Agent 循环。
最后一步的用意是:删除文件后,token 只存在于进程堆内存里。即使攻击者后来拿到了文件系统权限,也找不到 token 了。减小攻击的时间窗口。
通信通道:Deep Link、Bridge 与 DirectConnect
模型和运行时之外,还有通信通道这个攻击面。Deep Link(claude-cli:// URI 方案)拒绝控制字符和 Unicode 走私、限制路径和查询长度。Bridge(bridgeMain.ts,115K 行)负责远程会话编排,JWT 每 3 小时 55 分钟刷新(有效期约 4 小时),可信设备 token 和会话 token 分开存储。DirectConnect 走 WebSocket 双向通信,服务端可以批准工具调用但同时修改输入参数——”允许你调这个工具,但我把参数改了”。
安全章节讲的是系统怎么防御外部攻击。但还有一个用户关心的问题:系统自身在后台采集了什么数据?
十二、数据采集与隐私
Agent 在本地跑,但不代表数据只留在本地。Claude Code 内置了一套多层数据上报体系,源码里能看到它采集了什么、发往哪里、怎么脱敏。
三个数据出口
数据发往三个远程端点,仅对直连 Anthropic 的用户生效——通过 AWS Bedrock / Google Vertex / Foundry 接入的用户,采集系统完全禁用。
Anthropic 自有事件日志(主通道)。端点 api.anthropic.com/api/event_logging/batch,基于 OpenTelemetry 的 BatchLogRecordProcessor,每批最多 200 条事件、每 10 秒发送一次。发送失败的事件持久化到 ~/.claude/telemetry/ 目录做退避重试。
Datadog(二级通道)。端点 https://http-intake.logs.us5.datadoghq.com,Client Token 硬编码在源码中。受 GrowthBook 特性开关门控,仅生产环境生效,只发送约 40 种白名单事件。
BigQuery Metrics(指标通道)。端点 api.anthropic.com/api/claude_code/metrics,每 5 分钟发送 OpenTelemetry 聚合指标(成本、token 计数器),不含事件级明细。面向 API 客户和 Enterprise/Teams 用户,尊重组织级 opt-out。
采集了什么
按敏感度分三层:
身份层——你是谁。设备 UUID、账号 UUID、组织 UUID、邮箱(OAuth 登录来源)、订阅等级。GitHub Actions 环境下还采集 actor_id 和 repository_id。
行为层——你在干什么。约 100+ 种 tengu_* 事件:会话启动/退出、每次 API 调用的模型名和 token 数、每次工具调用的工具名和权限决策、文件操作的哈希路径和扩展名、取消/粘贴/对话回退等交互动作、A/B 测试分组命中。
环境层——你用什么在干。操作系统、CPU 架构、终端模拟器、Node 版本、包管理器、项目运行时、是否 CI 环境、进程内存和 CPU 占用。
用户 Prompt 是否被记录
最敏感的问题。源码里有四条数据通路,对 prompt 内容的处理各不相同:
遥测事件——不记录内容。tengu_input_prompt 每次用户输入都触发,但只发两个布尔值:is_negative(用户是否在表达挫败感)和 is_keep_going(用户是否在说”继续”)。logEvent 的类型签名限制 metadata 为 Record<string, number | boolean | undefined>——字符串类型传不进去,prompt 原文在类型层面就被挡住了。
客户 OTEL 导出——默认脱敏。redactIfDisabled() 把 prompt 替换为 <REDACTED>,必须主动设 OTEL_LOG_USER_PROMPTS=1 才记录原文,且数据发到用户自己配置的 OTEL 端点,不是 Anthropic。
Transcript 分享——唯一会传完整对话的非 API 通路。用户点了反馈调查的 👍/👎 后弹出”是否分享对话记录”,选 “yes” 才会把完整对话 POST 到 Anthropic。可以永久关闭(”Don’t ask again”),企业管理员也可以策略禁止。
API 调用本身——功能性传输。用户的 prompt 当然会发给 Claude API,模型需要看到你说了什么才能回复。服务端是否留存这些对话,取决于 Grove 数据共享开关(/privacy-settings 可切换)和 Anthropic 的数据政策,客户端源码管不到这一层。
脱敏与退出
文件路径和内容 SHA256 哈希后上报,MCP 第三方工具名默认脱敏为 "mcp_tool",仓库 URL 哈希处理。源码中用 AnalyticsMetadata_I_VERIFIED_THIS_IS_NOT_CODE_OR_FILEPATHS 这个 never 类型强制开发者在传入分析字段前签字确认不含代码或文件路径。
用户退出方式:DISABLE_TELEMETRY=1 关闭事件上报;CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1 关闭所有非核心网络流量;使用 Bedrock/Vertex/Foundry 接入则采集系统完全禁用。
一句话总结:Anthropic 知道你是谁、用什么设备、调了哪些工具、花了多少 token,但在客户端源码层面,prompt 内容被类型系统挡在了遥测事件之外。完整对话只在用户明确同意分享时才会上传。
以上都是”看不见”的后端工程。但 Claude Code 毕竟是个终端应用——用户每天盯着看的界面,也藏着不少工程量。
十三、终端渲染
终端 UI 的核心矛盾是:交互复杂度已经接近 GUI 应用,但渲染目标仍然是字符网格。Claude Code 的解法是把 Web 前端的声明式范式搬进终端。
实现方式是 React + 自定义 Reconciler + Yoga flexbox 布局引擎。
src/ink/ 里的渲染管线(pipeline):React 组件状态变化 → Yoga 算 flexbox 布局 → 双缓冲 diff(只重绘变化区域)→ ANSI 序列优化(字符串去重,减少 TTY 输出量)→ 写到终端。支持鼠标追踪、iTerm2 进度条、终端输出导出为 PNG/SVG 等特性。
甚至还实现了完整的 Vim 模式:INSERT / NORMAL 状态机、常用操作符和动作、dot-repeat(. 键重放)。
前面十三章讲的是 Claude Code 当前的架构。但源码里还有一批尚未对外开放的功能,藏在 feature flag 后面——它们透露了 Anthropic 正在探索的方向。
十四、44 个 Feature Flag
Feature flag 是同一份二进制里控制功能可见性的开关。Anthropic 用它做灰度发布和 A/B 测试,不发新版就能开关功能。泄露源码里有 44 个 flag,揭示了几个在做的方向:
KAIROS — always-on(常驻)后台 Agent,配合 Sleep 工具,在用户不活跃时继续跑任务。有对应的 src/assistant/ 目录做持久模式支持。
UltraThink — 三种思考模式(adaptive / enabled / disabled)。adaptive 下模型自己决定要不要深度思考。双重门控:编译时 + 运行时各一道开关。
Plan Mode V2 — 五阶段工作流(采访 → 规划 → 执行 → 验证 → 复查)。探索阶段可以并行开多个 Agent。
Frustration Regex(挫败感正则匹配)— 检测用户输入里的情绪化表达(”wtf”、”fuck”),据此调整行为。
BUDDY — 一个类似 Tamagotchi 的 AI 宠物。是的,这也在源码里。这个功能最新版已经上线了。
这些 flag 管理有两层:GrowthBook(A/B 测试平台)控制运行时灰度,bun:bundle 在构建时根据 flag 做 tree-shaking。同一个版本号的 Claude Code 可以给不同用户呈现完全不同的功能集。
总结
看完之后,有一些印象比较深刻的点。
工具即能力边界。Claude Code 能做什么、不能做什么,不取决于 prompt 里写了什么,而取决于注册了哪些工具、schema 怎么描述、权限怎么配。增减一个工具就是增减一项能力。这是一个比 prompt engineering 更硬的控制平面。
协议层 > 提示层。权限靠注册表过滤而不是 prompt 里写”别用这个工具”,Bash 安全靠 AST 解析器而不是”别执行危险命令”。凡是能在代码层面做的控制,都没有交给模型的”自觉”——Claude 看不到一个工具就不会调用它,比任何提示词都可靠。
渐进式信任。权限系统六种模式构成一个信任梯度,从自动拒绝到完全绕过。用户第一次调用某个工具会弹确认,选了 “allow always” 就写入规则,下次不再问。信任不是一个开关,是一个连续过程,用户可以在任意位置停下来。
上下文即智能。同一个模型,上下文里放了相关信息就表现得”聪明”,塞满无关内容就表现得”笨”。AutoCompact、MicroCompact、post-compact 恢复、Memory 跨会话沉淀、prompt cache 归因——本质上都在做同一件事:在有限的窗口里,让最有用的信息留下来。模型的能力上限由参数决定,但实际表现由上下文决定。
有损是常态。信息会丢失,而且这是预期中的事。问题不是”要不要丢”,而是”丢哪些、怎么丢、丢完怎么恢复关键部分”。四种”丢”的策略各有保留优先级,Memory 沉淀跨会话知识作为最后的安全网。
循环赋予自主性。Agent 之所以是 Agent 而不是 chatbot,就是因为一个自动循环——模型连续调用工具、自行决定下一步,直到任务完成。不是什么复杂的 AI 技术,就是一个 while 循环加终止条件。
能力是加法,安全是减法。能力扩展靠加:注册工具、接 MCP、加载 Skill。安全控制靠减:删注册表条目、deny 规则、AST 拦截、flag 关功能。加的通道标准化,减的通道分层化。
保守默认 + 处处断路器。工具默认不并发安全、不只读、不可破坏——除非自己声明。权限无规则命中时默认 ask。compact 连续失败 3 次就停,Fast Mode 有速率冷却,Bridge 有退避重试。整个系统的风格是:出了问题就收窄行为,而不是反复重试或者直接崩溃。
渐进式披露。43 个内置工具全塞进上下文要吃掉大量 token。做法是 shouldDefer 标记的工具启动时不加载,需要时通过 ToolSearch 按语义匹配按需加载。不是一次给全部菜单,而是先给常用的,剩下的需要时再找。
记忆不需要向量数据库。没有 embedding,没有 RAG,就是 markdown 文件 + MEMORY.md 索引 + Sonnet side query 选相关文件 + Grep 搜关键词。简单、可调试、不依赖额外基础设施。文件系统就是数据库,模型本身就是检索引擎。
一个 fork 模式撑起五个子系统。记忆提取、后台整理、投机执行、Session Memory、Magic Docs 看着是五个独立功能,底层都是同一个 forkedAgent——fork 出的子 Agent 与主 Agent 共享 prompt cache,不额外付 cache creation 成本。这意味着 Agent 可以”分身”做很多后台工作,而用户只为一份缓存买单。好的基础设施决定了上层功能的成本结构。
系统在观测自己。cost-tracker 记录 token 消耗和美元成本,prompt cache 有归因分析,Frustration Regex 在观测用户情绪。这些不是事后加的监控,而是和功能代码写在一起的。
命名带态度。DANGEROUS_uncachedSystemPromptSection() 告诉开发者”往这里加东西会破坏缓存”。classifyYoloAction() 直接叫 YOLO,说明团队清楚这是个冒险的做法。每个数字都有名字,不是散落的 magic number。务实,不装。
参考
[1] https://ccleaks.com/
[2] Claude Code源码