 夜雨聆风
夜雨聆风





从自由软件到开源AI
破除信息茧房,为您介绍熟悉的陌生人~
从1980s反对专有软件圈地,到90年代末意识形态的分裂,再到2020s抵御云计算巨头与生成式人工智能资本的“捕获”,以及Digital Commons数字公地/资源共享运动的泛化分支的兴起(Creative Commons知识共享、Open Hardware开放硬件),都在不断重塑着知识生产与分配的底层逻辑。
在历史唯物主义视角中,这一系列资源共享运动是先进的、分布式的生产力(全球协作的互联网开发者群体)与封闭的、垄断的生产关系(专有软件许可证与知识产权壁垒)之间不可调和矛盾的产物。



01
以软件共享为核心的运动

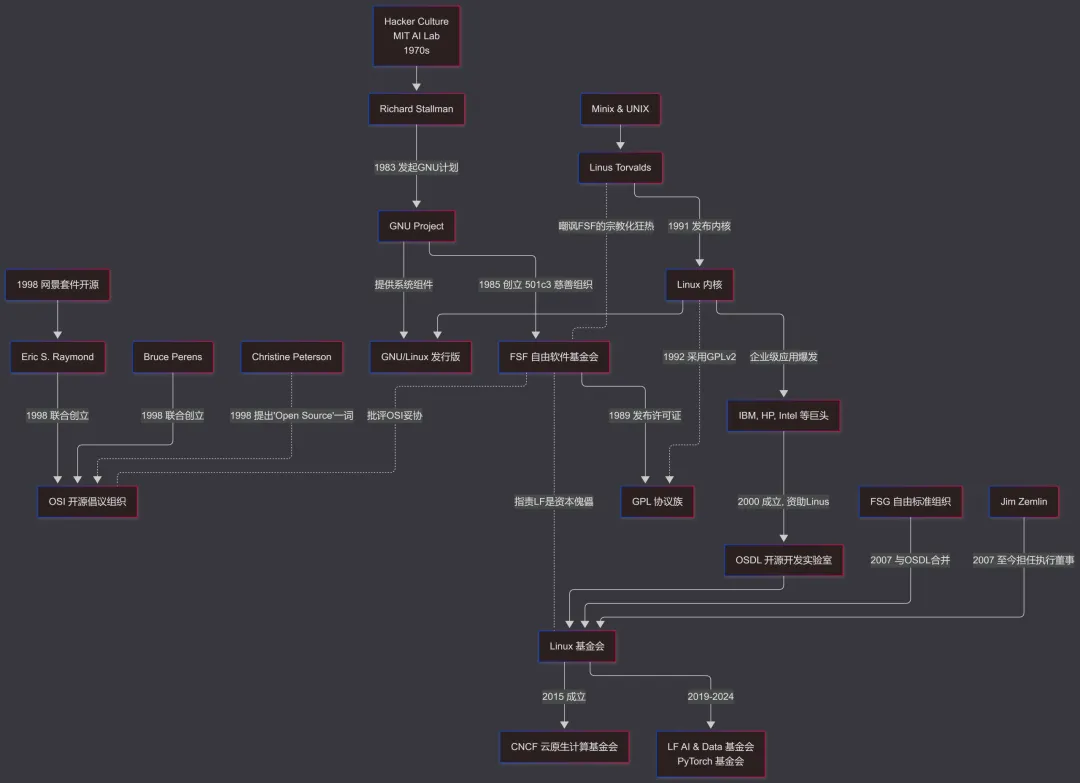
20世纪70年代至80年代初期,软件作为昂贵硬件的强绑定附属品发布,主要用于科学计算和前沿探索。因此,MIT 和 Berkeley 等美国高校实验室间流行着让源代码在学术界自由分发和使用的极客文化 (Hacker Culture)。随着商业计算机市场的成熟,软件开始被视为独立的高价值商业资产,于是在1980年代初,发生了 Xerox施乐激光打印机驱动程序闭源,和 AT&T (Bell Lab) UNIX OS 闭源商业化两大软件私有化标志性事件,引发了当时极客社群的强烈反对,最终导致了 GNU/Linux Distro (取被公认的狭义) 和FreeBSD家族与NetBSD家族的产生。
施乐事件的主角 Richard Stallman (下称RMS) 认为,“限制用户检查、修改和分享软件的权利,不仅阻碍了技术进步,更是一种破坏了社会协作结构的道德恶行”,并于1983年宣布开发兼容 UNIX OS 的 GNU OS 自由项目,于1984年离开 MIT AI Lab 正式开发该项目,于1985年成立了支撑组织——FSF自由软件基金会。
FSF持续推进GNU OS开发,并在开发过程中发布了 GNU GPL 和 GNU LGPL 两大Copyleft许可证(与Copyright相呼应) 用于GNU项目软件包的授权。1992年,GNU用户层工具基本具备,但内核迟迟未能开发出来,此时由 Linus Torvalds 发起的Linux内核项目得到了广泛关注,因此,两大社区尝试结合两者形成完整的OS。然而,两大社区的繁荣和大量非GNU软件生态的加入却引发了针对基于Linux内核Distro的命名争议,对此的详细介绍可以访问文末Bibliography中的网址进行查看。
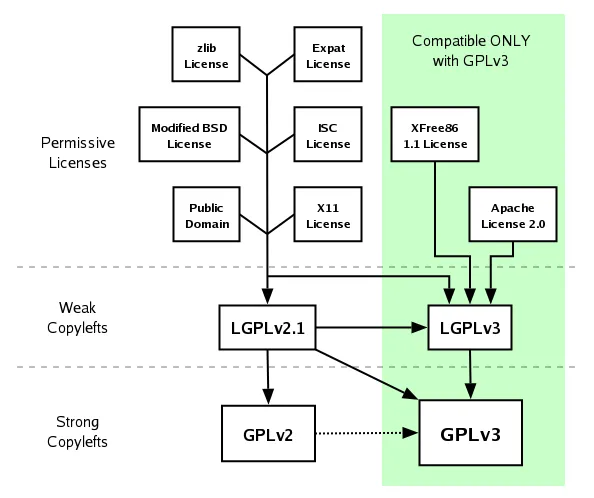
随着生产力的发展,这样一场资源共享运动因为道德纯粹性与商业实用主义的对立迎来了历史性的转折与分裂。1998年,Netscape Communicator 4.5 开放源码,此前 Linus Torvalds、Eric S. Raymond 和 Bruce Perens及多位编程语言领导者等参与了其开源而非自由许可的讨论,接着 Raymond 和 Perens等人则借此契机成立了OSI开源倡议组织/开源促进会,发布了基于Debian自由软件指南(DFSG)的OSD开源定义。
自此,自由与开源的争论拉开序幕,FSF 坚持自由是基本人权,主张彻底推翻专有软件;而 OSI 则认为开源是一种极其高效的工程方法论,通过允许企业剥离不产生核心竞争力的底层代码以降低研发成本,共同推动技术进步。

这里举争论一例,对于Tivoization硬件锁定技术(包括验签和禁止写入,参照前几年引起关注的手机Bootloader锁)对GPL软件的使用(比如Linux内核),FSF表示强烈反对,认为这违背了基本自由,并推出了GPLv3堵住该漏洞,而开源阵营的代表人物之一Linus认为这无关紧要,指责FSF的做法过于“政治化”(回旋镖已丢出)。接下来的自由软件与开源软件的具体差异不便展开,请阅读下期文章——软件常见分发与授权模式。
随着“开放、协作、共享”模式的成功,共享运动向文艺领域、硬件领域等非软件领域蔓延。
2000年,Jimmy Wales 和 Larry Sanger 创立了采用传统同行评审机制的 Nupedia,但其邀请博士和专家撰写的方式效率低下,故在2001年,他们引入了面向任何人的 Wiki(夏威夷语“快”)协同写作软件以快速提供草稿,风靡一时,最终反客为主成为Wikipedia维基百科,并采用GNU自由文档许可证(GFDL)授权,实现了RMS在1999年提出的基于自由软件理念的知识库设想。
2001年,FSF董事 Lester Lawrence Lessig 洞察到严苛的传统版权法正在阻碍数字文化的传播,创立了Creative Commons知识共享组织,简称CC,并通过提供模块化的许可协议(BY 署名、SA 相同方式共享、NC 禁止商业性使用、ND 禁止衍生修改),在“保留所有权利”和“公共领域”之间划定了一个灵活的缓冲带。在2009年,经 FSF 的妥协与重新授权,维基百科全面迁移至 CC BY-SA 许可协议,标志着“文化与知识共享”正式脱离了软件许可框架,确立了独立运作的法理基础。现在,Open Access学术开放获取也广泛使用CC许可。

1970s,Homebrew计算机俱乐部和业余无线电社区内部便存在着共享电路设计的传统。1997年,Perens发起了开放硬件认证计划,但很快以失败告终。1999年,OpenCores EDA社区成立,并在后来发起OpenRISC项目。2001年,MIT发起 Fab Lab 个人制造实验室运动,并获得美国国家科学基金的支持。
随着互联网的普及和硬件制造成本的初步下降,Fab Lab 等创客空间的铺垫导致创客运动爆发。2005年,类似研究所的意大利IDII公开了Arduino单片机平台的IDE源码和电路设计的CAD文件(CC BY-SA),允许自由克隆,极大地降低了单片机编程的门槛,成为物联网开源的先驱。

同年,英国巴斯大学讲师Adrian Bowyer发起了 RepRap 开放3D打印机项目,打破了传统工业机床的垄断,直接催生了 MakerBot 等商业公司。2007年,TRAP发布了第一个专为PCB文档设计的开放许可TAPR OHL。2010-2011年,Berkeley Par Lab开放了 RISC-V ISA指令集架构和一些IP知识产权内核(具体硬件设计),后来发展为庞大而分散的社区。2011年,CERN欧洲核子研究中心针对电路设计发布了 CERN OHL开放硬件许可证,并在2020年发布了更泛化更易懂的第二版。2012年,Alicia Gibb 创立了OSHWA开源硬件协会,并与OSI签署共存协议。
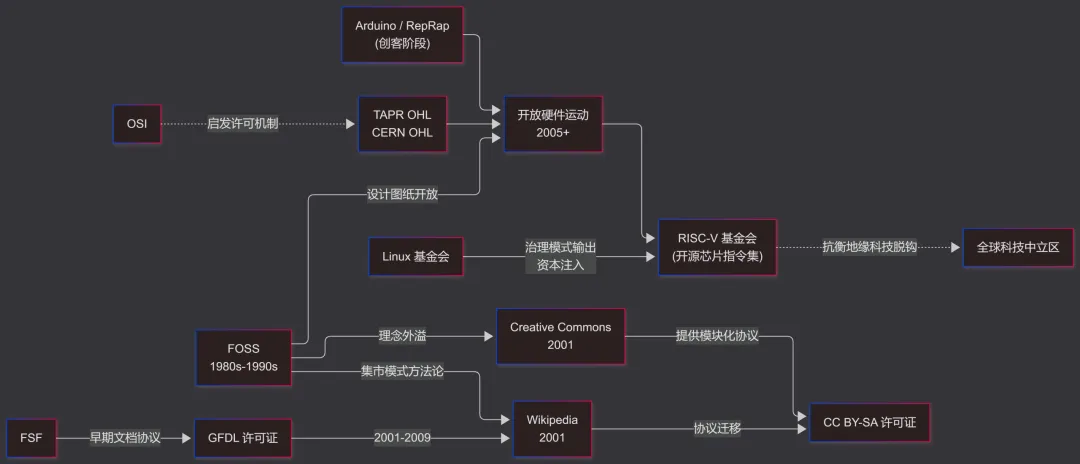
需要注意的是,硬件开放对于低技术力产品效果显著,但对于一些需要高级制造能力和强大供应链支撑的设计效果甚微,即物理制造资料仍被行业巨头垄断。


02
商业生态的转变
与GenAI时代的漏洞



①
1990s-2000s 服务与支持模式
比如红帽公司和Canonical公司免费提供基于Linux内核的发行版源码(可惜2023年开始不再免费提供RHEL的源码,并设置再分发将触发订阅终止的条款),并通过提供企业级技术支持、认证和维护服务获利。这一阶段开源与资本实现了初步的和谐共生。

②
2010s 付费扩展模式
企业开发产品,并开源其基础版本吸引免费测试和外围代码开发、增加市占率,而在高级安全、集群管理等企业级功能上采用闭源收费。这一模式以数据库引擎和CI/CD等基础设施为主,比如MongoDB、Elasticsearch、Redis、Neo4j、GitLab、Docker。

③
2018-2024 商业竞争与许可变更
AWS亚马逊等具有大量客源的云巨头将企业主导的开源软件包装为基础支持更好、集成更方便的“SaaS软件即服务”出售,导致与开发厂商自己推出的托管服务形成竞争性冲突。
因此,MongoDB 在2018年10月(v4.0.4 / v4.1.5)放弃 GNU Affero通用公共许可证(AGPLv3),转而以新发布的明令以SaaS方式使用则必须开源其支持设施的 SSPL服务器端公共许可 v1 (SSPLv1) 重新授权。
类似的,Elasticsearch 和 Kibana (v7.11) 于2021年变更为 Elastic License v2 / SSPLv1 双重许可,并于2024年新增 AGPLv3 许可。
HashiCorp则更加直白,于2023年将旗下包括Terraform在内的所有产品从 Mozilla公共许可 2.0 (MPL-2.0) 转移到明令发布4年内不得构成商业竞争的 MariaDB商业源码许可证(BUSL-1.1)。
2024年,Redis 8.0 开始从 新Berkeley软件发行版许可(BSD-3-Clause) 全面转向 Redis源码可用许可 2.0 (RSALv2) 与 SSPLv1 双重许可。
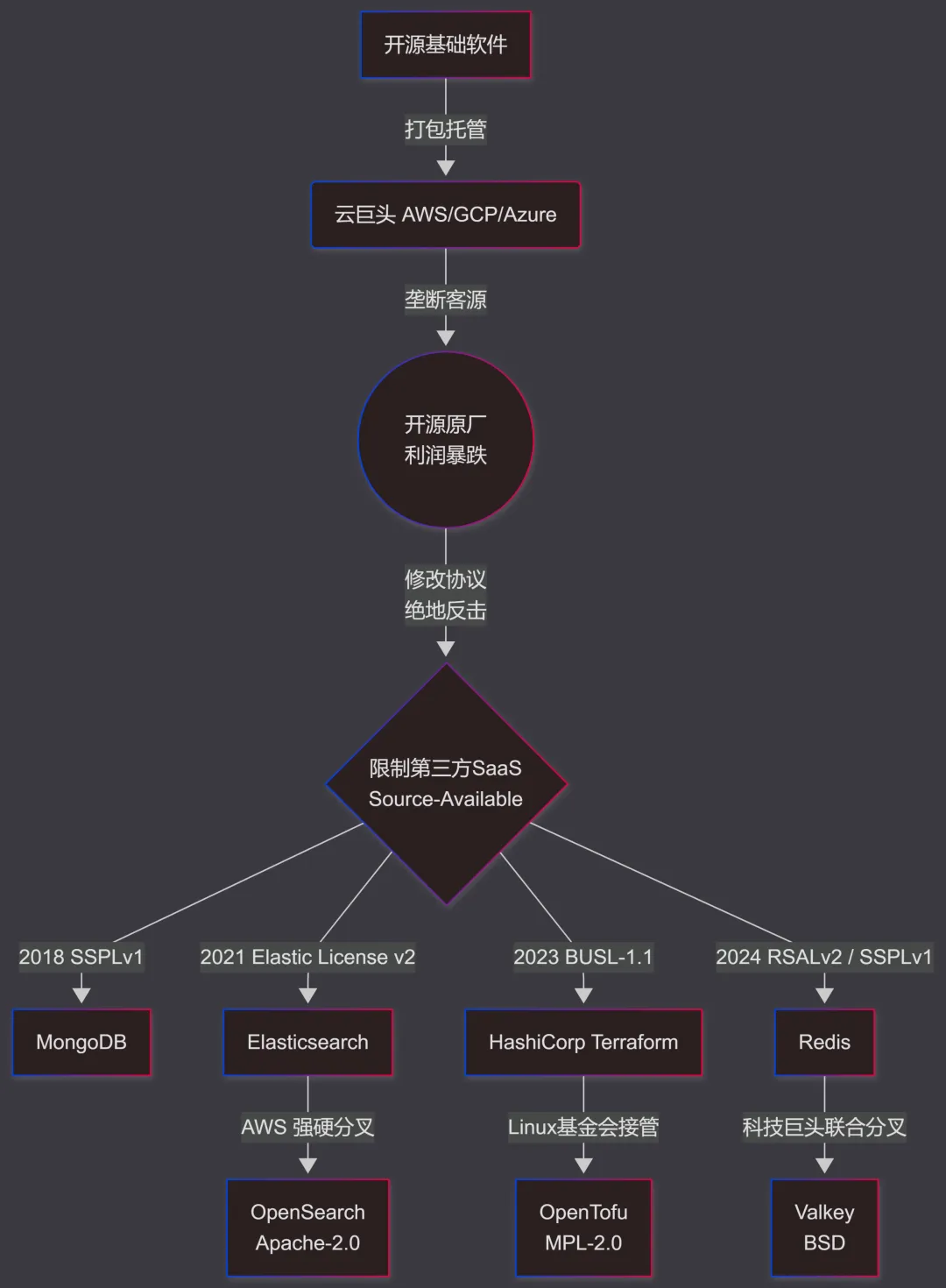
当然,这些带有商业歧视的协议都不被 OSI 认可。作为反击,云厂商和开源基金会硬分叉或者重新开发了兼容性替代品,如OpenSearch、OpenTofu、Valkey。

④
2023-2026 OpenWashing
“伪开放”模式
2023年,OpenAI和Google在LLM领域风光无限,Meta(Facebook)选择面向学术研究“开源”LLaMA模型以博取支持者,接着又“开源” LLaMA 2 模型且允许商业使用(月活<700M),引起了大众狂欢。
但是,对于LLM而言,隐藏于架构和权重背后的高质量训练数据是更加重要的,而Meta却不愿意披露数据来源和组成概况,这在本质上是禁止社区复现和改进,当然可预测的版权诉讼也是重要因素。值得一提的是,在这之前的2020年,OpenAI因不再“开源”ChatGPT违背了此前的长期“开源”承诺,而被讽刺为ClosedAI。
虽然Meta的“开源”似乎不够纯粹,但是一系列可以免费使用的前沿预训练“开源模型”对于科研和打破垄断来说已是弥足珍贵,并且LLaMA开源后的热烈反响导致了Mistral、Gemma、DeepSeek、Qwen等越来越多的开放权重模型也效仿这一模式进行“开源”,最终形成本地部署和微调风潮。
不过,既然OpenWashing不够“Open”,OSI没有坐以待毙,通过协调各方于2024年末正式发布《开源人工智能定义》(OSAID 1.0),规定:被认定为“开源AI”的系统,必须能够使得他人自由修改该系统,因此必须提供完整的训练推理代码、预训练的权重和配置,以及最重要的训练数据说明,包括来源、范围、特性、获取方式及处理方法。
另外值得一提的是,GenAI训练过程使用的海量网络公开数据中必定不少基于 CC BY 或者更严格协议的开源文艺作品等需要标注版权的内容,因此,不少创作者的利益已在难以发现的情况下蒙受损失。
比如,作为GenAI常用训练语料的由世界各地志愿者维护的维基百科正在遭遇AI巨头的“公地悲剧式榨取”——模型汲取知识,而极少向社区回流流量和编辑者(搜索引擎入口),长此以往将导致存在危机。对此,CC正推动一项基于互惠性的协议框架,与维基媒体基金会联合探索全新的反向授权与补偿机制。
我大胆预测,绝大部分数字资源共享将不再以人类友好为首要目标,而是转型为AI友好的Agentic API端点,或许会以去中心化的知识图谱形式展现,并以授权费或算力捐赠获益。


03
历史教训

①
许可证只是许可证
单靠法律协议无法完全抵御底层生产关系的变动。云厂商利用 SaaS 漏洞绕过 AGPL,AI 公司拒绝披露数据以规避 CC 协议,证明了当资本掌握绝对算力和基础设施时,代码和数据的开放并不能转化为权利的平等。
②
警惕基础设施私有化
大型科技公司通过大量雇佣开源项目的核心维护者,实现了对事实标准(如 Kubernetes、PyTorch、TensorFlow)的隐性控制。开源虽然赢得了软件之战,却正在输掉平台治理之战。

综上所述,开源运动从未真正消灭垄断,而是被资本以更高级的形态“内化”了,这可从大量的开源变故中窥见。毕竟连AGPL授权的自由软件都有可乘之机,何况为了更多人和公司参与的大量开源软件?但总的来说,开源带动了更多人参与,不仅使得软件生态生机勃勃、技术日新月异,更使得普通用户有了相对自由的选择。下一期,我们接着谈论软件常见分发与授权模式。