 夜雨聆风
夜雨聆风





Claude Code 源码揭秘:AI 偷偷帮你把活干了,Speculation 预判执行系统全拆解
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 73 篇,Claude Code 源码揭秘系列第 5 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let’s explore。无界探索,有术而行。
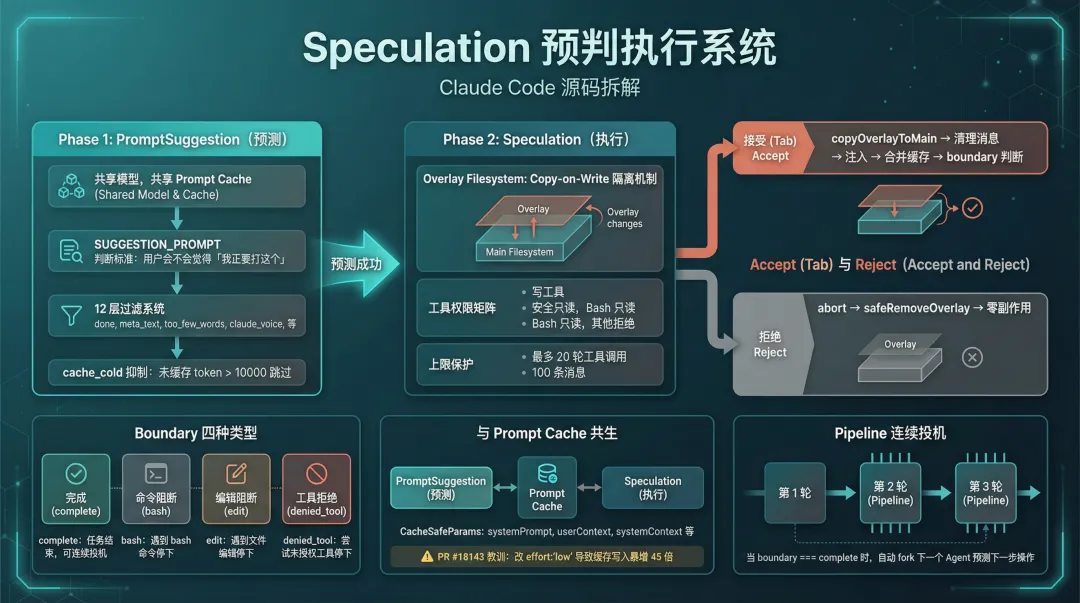
图 1:Speculation 预判执行系统全流程概览
Fortune 杂志那篇报道出来之后,Claude Code 的源码就被扒了个底朝天。
前 4 篇我们拆了 5 个 Agent 设计模式、Buddy 宠物系统、Skills 技能系统和三级压缩系统。这一篇,我们来看整个代码库里设计感偏重的一个模块 – Speculation(投机型执行)。
想象一下这个场景:你在 Claude Code 里敲了一半需求,还没按回车,它已经帮你把代码改好了。你按下 Tab 键接受建议的瞬间,背后 20 轮工具调用已经跑完,文件已经编辑过了,测试也跑通了。
这不是科幻。这是 speculation.ts(991 行)、promptSuggestion.ts(523 行)、forkedAgent.ts(689 行)三个文件协同工作的结果。
1. Speculation 到底在干什么
一句话说清楚:在你确认下一步操作之前,AI 已经 fork 了一个子代理,在后台偷偷把活干完了。
整个系统分两个阶段,是一条流水线:
用户正在思考下一步 → Phase 1: PromptSuggestion(预测你要说什么) ↓ 预测成功 Phase 2: Speculation(提前帮你执行) ↓ 执行完毕 用户按 Tab → 结果到手这和传统的自动补全完全不是一回事。传统的补全只是帮你省了几次键盘敲击,而 Speculation 是在后台跑了一个完整的 Agent – 读文件、改代码、跑命令,全都做完了,等你一个 Tab 确认。
更精妙的是它和 Prompt Cache 的配合。fork 出来的子代理共享父级的缓存,也就是说预测执行的额外成本很低 – 缓存命中率高的时候,几乎等于白拿了一次 Agent 调用。
这个设计思路其实不新鲜。CPU 里有分支预测,数据库里有乐观并发控制(OCC),编译器里有投机优化。但把这些思路搬到 AI Agent 里,Claude Code 是目前能看到代码实现里做得比较完整的一个。
2. Phase 1:预测你要说什么
Speculation 的第一步,是猜你接下来要输入什么。这一步由 promptSuggestion.ts(523 行)负责。
为什么不用小模型?
这个问题第一反应是:预测几个词而已,用个小模型不就行了?
不行。因为 runForkedAgent 必须和父级共享 Prompt Cache,换模型就意味着缓存全部失效。源码里有个明确的约束:canUseTool 直接返回 deny,预测阶段不执行任何工具,纯靠模型自身的理解力来生成建议。
用同一个模型还有个好处:它完全知道当前对话的上下文、你的编码风格、项目的文件结构。小模型拿不到这些信息,预测准确率会断崖式下降。
说到底,这不是一个简单的文本预测问题,而是一个上下文理解问题。模型需要知道你之前在做什么、项目的文件结构是什么、哪些文件刚被修改过,才能预测你下一步想干什么。这些信息都存在 Prompt Cache 里,换个模型就全丢了。
SUGGESTION_PROMPT 的设计哲学
源码里给建议生成设计的 prompt 很有意思,核心只有一句话:
THE TEST: Would they think "I was just about to type that"?Format: 2-12 words, match the user's style. Or nothing.翻译过来就是:判断标准是用户会不会觉得「我正要打这个」。2 到 12 个词,匹配用户风格。如果不确定,就什么都不要输出。
这个”Or nothing”很关键。宁可不做预测,也不要乱预测。乱预测的代价不是浪费算力,而是打断用户思路 – 你正在想怎么写一个函数,突然蹦出来一个不相关的建议,比没有建议还烦。
这个 prompt 设计哲学里还有一层意思:匹配用户风格。如果你平时习惯用英文和 AI 对话,建议就是英文;如果你习惯用中文,建议就是中文。这不是什么高深的 NLP,而是在 prompt 里直接要求模型这么做。简单粗暴,但有效。
12 层过滤系统
预测结果生成后,还要过 12 层过滤。源码里的 shouldFilterSuggestion 函数写得像安检一样,一层一层筛:
// 源码路径:promptSuggestion.ts → shouldFilterSuggestion// 12 层过滤的完整列表:1. done → 过滤 "done"2. meta_text → 过滤 "nothing found", "no suggestion", "silence" 等元文本3. meta_wrapped → 过滤括号包裹的 (silence) 或 [no suggestion]4. error_message → 过滤 API 错误消息5. prefixed_label → 过滤 "word: text" 格式6. too_few_words → 单词数 < 2(但允许 / 命令和 yes/no/ok)7. too_many_words → 单词数 > 128. too_long → 字符数 >= 1009. multiple_sentences → 多句10. has_formatting → 含换行或加粗11. evaluative → 过滤 "thanks", "looks good", "great" 等评价性回复12. claude_voice → 过滤 "Let me...", "I'll...", "Here's..." 等 Claude 语气这 12 层过滤解决了一个很实际的问题:大模型有时候会自言自语。它可能输出一段解释、一个错误信息、甚至一个 Claude 语气的客套话。这些都不能给用户看。
第 11 层过滤评价性回复也值得细看。如果用户刚完成了一轮修改,模型可能觉得该说句 “looks good!” 之类的鼓励话。但在 Speculation 的语境下,这种建议毫无意义 – 你要的是下一步操作,不是 AI 对你上一轮工作的评价。
第 12 层过滤尤其有意思 – 专门过滤 Claude 自己的语气。说明 Anthropic 的工程师很清楚,用户想看到的是自己的语言风格,不是 AI 的。这层过滤确保建议看起来像是用户自己会打出来的话,而不是 AI 的客套话。
cache_cold 抑制
还有个细节:如果父级对话的未缓存 token 超过 10000(MAX_PARENT_UNCACHED_TOKENS),直接跳过建议生成。
为什么?因为缓存命中率太低,fork 出来的子代理要重新处理大量 token,延迟会很高。预测结果还没出来,用户可能已经自己输入了指令。与其生成一个过时的建议,不如什么都不做。
这个阈值设在 10000 而不是更大或更小,应该是实际测试后权衡的结果。太小会错过很多可以预测的机会,太大又会导致预测延迟不可接受。
3. Phase 2:Overlay Filesystem 与隔离执行
如果说 Phase 1 是猜你要干嘛,Phase 2 就是偷偷帮你干了。但有个问题:万一猜错了呢?
这就是 Overlay Filesystem 要解决的核心问题。
Copy-on-Write:猜错了不留痕迹
speculation.ts(991 行)的核心设计是一个覆盖文件系统,路径在 /tmp/claude/speculation/<pid>/<id>/ 下。
工作原理用一句话概括:写文件时不动原文件,先 copy 一份到 overlay 目录,然后只改 overlay 里的副本。读文件时优先读 overlay,没改过的读原文件。
这就是经典的 Copy-on-Write(COW)模式。
读文件流程: overlay 里有改过? → 读 overlay overlay 里没有? → 读原文件写文件流程: copy 原文件到 overlay → 在 overlay 中修改 → 原文件纹丝不动Accept(用户确认): copyOverlayToMain → 把 overlay 合并到真实文件系统Reject(用户拒绝/超时): safeRemoveOverlay → 直接删 overlay 目录 → 零副作用这套设计的聪明之处在于:不管 AI 在后台跑了多少轮工具调用、改了多少文件,只要用户不按 Tab,真实文件系统完全不受影响。连一个字节都不会被修改。
但 overlay 机制解决的不只是猜错了怎么办。它还解决了一个更微妙的问题:一致性。假设 Speculation 过程中 AI 先改了 A 文件、再读 B 文件、然后基于 A 和 B 的内容改了 C 文件。如果它读到的 B 文件是修改前的版本,那 C 文件的修改逻辑可能就是错的。overlay 机制确保 AI 在整个 Speculation 过程中看到的是一个一致的文件系统视图 – 它自己的修改它能看到,而原文件不会被污染。
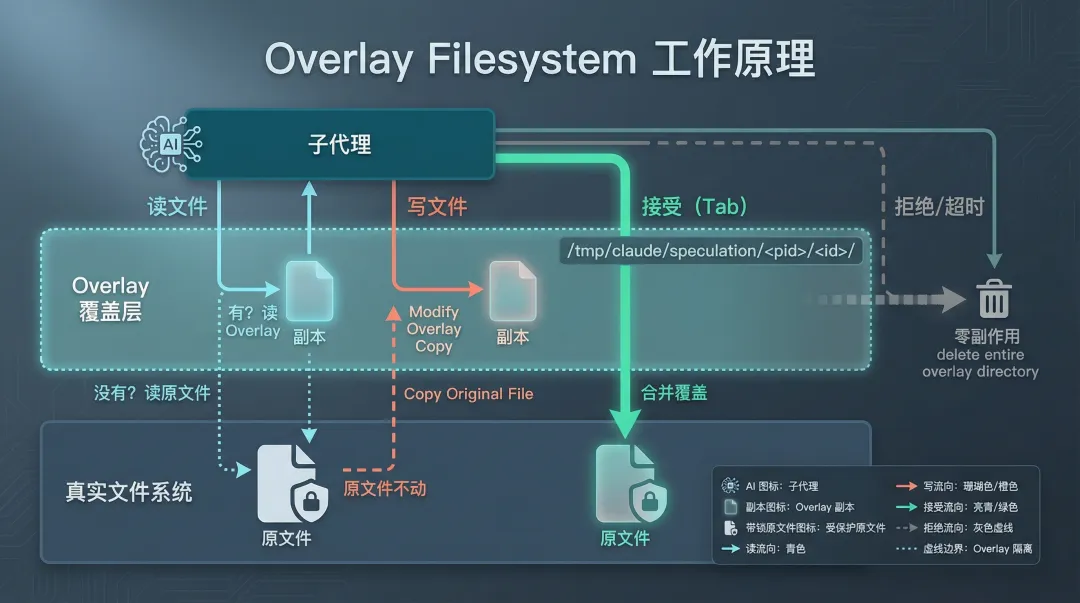
图 2:Overlay Filesystem 的 Copy-on-Write 读写流程
状态隔离
forkedAgent.ts 里的 createSubagentContext 函数负责把子代理的状态和父级隔离开:
// 源码路径:forkedAgent.ts → createSubagentContext// 子代理的状态隔离:- readFileState: 从父级 clone(浅拷贝)- abortController: 新建子控制器- setAppState: 默认 no-op(不影响父级 UI 状态)- 所有 mutation callbacks: 默认 no-op(不影响父级副作用)其中 readFileState 从父级 clone 这一步是关键。它让子代理能知道父级之前读过哪些文件、文件内容是什么。这样子代理在读文件的时候,可以直接从缓存里拿,不需要真的去读磁盘 – 既省时间,又能保证和父级看到的是同一个版本。
而 setAppState 和 mutation callbacks 都设成 no-op,是因为子代理的执行不应该触发任何 UI 更新或副作用。用户在主界面不应该看到子代理在跑 – 对用户来说,子代理是透明的。
工具权限矩阵
Speculation 阶段不是所有工具都能用。源码里把工具分成了四类:
|
|
|
|
|---|---|---|
|
|
Edit
Write, NotebookEdit |
|
|
|
Read
Glob, Grep, ToolSearch, LSP, TaskGet, TaskList |
|
|
|
|
|
|
|
|
|
注意最后一行:没有在白名单里的工具,在 Speculation 阶段一律拒绝。 这是一个安全边界 – 宁可少做一些,也不要越权执行。
Bash 命令的只读判断也挺有意思。源码里对只读的定义是:不会改变文件系统状态的命令。像 ls、cat、grep 这些是只读的,rm、mkdir、npm install 这些是非只读的。非只读命令一出现,立即设 boundary 为 bash 并 abort 整个 Speculation。
Boundary:投机什么时候停下来
Speculation 不是无限跑下去的。源码里定义了四种Boundary(完成边界),表示投机在什么条件下被打断:
|
|
|
|
|---|---|---|
complete |
|
|
bash |
|
|
edit |
|
|
denied_tool |
|
|
complete 是最好的情况 – 意味着 AI 完整地完成了所有操作,用户的 Tab 按下去,结果直接到手。
其他三种都是半途而废,但即便如此,已经完成的部分也不会浪费 – Accept 流程会截断尾部不完整的消息,保留前面有效的部分。
这个设计思路和 CPU 里的分支预测非常像。CPU 做分支预测的时候,也不是每次都能预测对。预测错了就要 flush 掉错误的指令,但已经执行完的正确部分是可以保留的。Boundary 机制做的就是同样的事 – 标记在哪出错,然后保留出错前的有效部分。

图 3:Boundary 四种完成边界类型对比
上限保护
源码里还有两个硬上限:
// 源码路径:speculation.tsconst MAX_SPECULATION_TURNS = 20// 最多 20 轮工具调用const MAX_SPECULATION_MESSAGES = 100// 最多 100 条消息这两个数字防止投机失控。如果 AI 在后台陷入循环或者执行了一个超长任务,到上限就强制停止。20 轮工具调用对一个正常的编程任务来说已经很充裕了 – 读完几个文件、改几个地方、跑个测试,差不多就是这个量级。如果 20 轮还没做完,说明这个任务本身不适合投机执行。
4. Pipeline:投机完了还能继续投机
到这里,系统已经能做到猜你要干嘛 + 偷偷帮你干了。但源码里还有更激进的一步:Pipeline 连续投机。
当一轮 Speculation 完整执行完毕(boundary === complete),系统会调用 generatePipelinedSuggestion,fork 另一个 Agent 来预测用户的下一步操作。
也就是说:
第 1 轮:预测 "改 A 文件" → 执行完 → boundary=complete ↓第 2 轮(Pipeline):预测 "改 B 文件" → 继续执行 ↓第 3 轮(Pipeline):预测 "跑测试" → 继续执行用户按 Tab 接受第 1 轮结果后,第 2 轮的 pipelined suggestion 自动 promote,变成正式的建议。如果用户继续 Tab,第 3 轮的结果也准备好了。
这就是源码里 pipelinedSuggestion 字段的作用 – 它让投机可以像流水线一样连续运转,用户每次 Tab 都能拿到下一轮的结果。
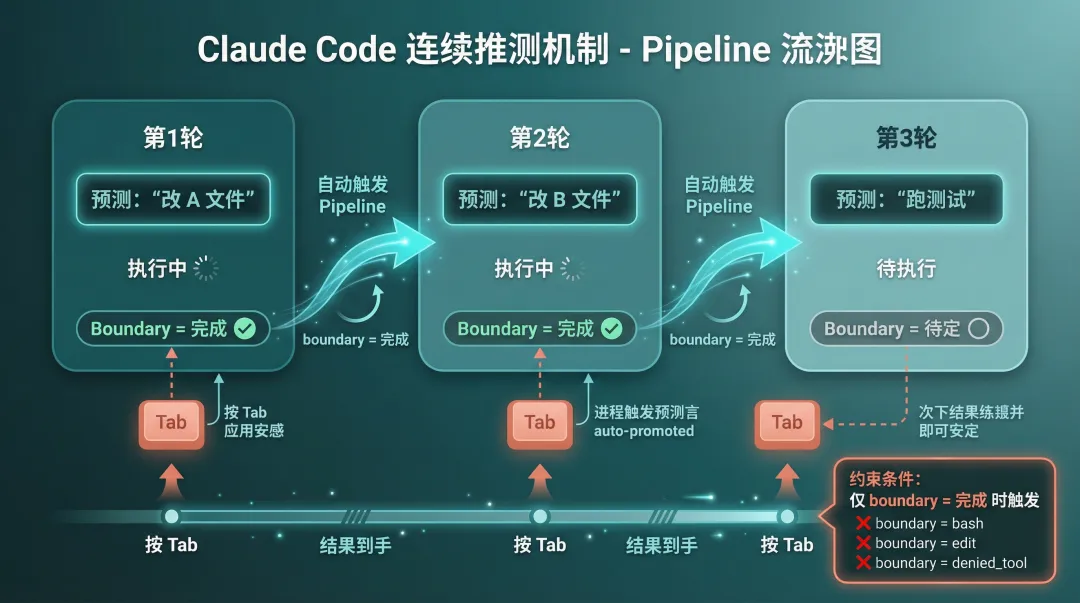
图 4:Pipeline 连续投机,Tab 一下结果到手
说实话,翻到这段代码的时候确实愣了一下。这不就是 CPU 里的流水线吗?指令还没执行完,下一条指令已经在解码了。Anthropic 的工程师把 CPU 流水线的思路搬到了 AI Agent 里,这个抽象层级的映射确实精妙。
不过 Pipeline 也有个天然的限制:只有 boundary === complete 的时候才会触发。如果第一轮就被非只读命令打断了,Pipeline 不会启动。这也是合理的设计 – 如果第一轮都没做完,预测第二轮的准确率就更低了,不如不做。
5. Accept 与 Reject:两条截然不同的路径
用户按下 Tab 或忽略建议,触发的是完全不同的处理流程。
Accept 五步流程
// 源码路径:speculation.ts → acceptSpeculation + handleSpeculationAccept// 简化的 Accept 流程:Step 1: copyOverlayToMain(合并 overlay 到真实文件系统)Step 2: prepareMessagesForInjection(清理消息) - 去掉 thinking blocks - 去掉失败的工具调用 - 去掉中断消息Step 3: 注入用户消息 + speculated 消息到主对话Step 4: 合并 readFileState 缓存Step 5: 判断 boundary 类型 - !== complete → 截断尾部 assistant 消息,触发正常 query 补完 - === complete → 有 pipelinedSuggestion?→ promote 并开始新一轮 speculation第 1 步 copyOverlayToMain 很直白:把 overlay 目录里的文件 copy 回真实文件系统。这是用户确认这一动作在文件系统层面的体现。
第 2 步的清理消息是个容易被忽略但很关键的步骤。Speculation 过程中产生的 thinking block、失败的工具调用、中途中断的消息 – 这些都不应该出现在主对话历史里。清理完之后,注入到主对话的消息看起来就像用户自己输入的一样干净。
为什么不能直接把原始消息注入?因为主对话的历史记录会影响后续所有的 AI 响应。如果里面包含了失败的尝试、重复的 thinking block,会让后续对话的质量下降。清理消息就是保证注入不留痕。
第 4 步合并 readFileState 缓存也很巧妙。子代理在执行过程中可能读了很多文件,这些文件的内容和 hash 都缓存在子代理的 readFileState 里。合并到父级后,父级后续读这些文件时可以直接从缓存拿,不用再访问磁盘。
第 5 步的分支处理也很有意思。如果 Speculation 被中途打断(boundary 不是 complete),系统不会扔掉已经完成的部分,而是截断不完整的尾部,然后触发一次正常的 query 来补完剩下的工作。用户感受到的就是:按了 Tab,结果虽然不完整,但 AI 会自动补完。
Reject:零副作用
Reject 流程简单得多:abort → safeRemoveOverlay → 重置状态。
没有文件被修改,没有对话历史被污染,没有缓存被破坏。整个 Speculation 就像从来没发生过一样。
这个零副作用的保证是整个系统能被信任的基础。如果 Reject 之后可能留下什么残留(比如临时文件、进程、缓存污染),那用户每次看到建议都会犹豫 – 这个建议会不会影响到我的项目?零副作用的设计消除了这个顾虑。
时间节省计算
源码里还有个 timeSavedMs 的计算:
timeSavedMs = min(acceptedAt, boundary.completedAt) - startTime取用户接受时间和边界完成时间的较小值,减去投机开始时间。用 min 的原因是:如果 Speculation 还没执行完用户就 Tab 了,那真正省下来的时间只到用户接受那一刻;如果 Speculation 早就执行完了但用户过了很久才 Tab,省下来的时间也只算到 Speculation 完成那一刻。
这个公式反映了 Anthropic 工程师对用户体验的精确理解:真正省下来的时间,是 AI 提前开始工作到用户本来要等的时间之间的差值。
你如果在自己的项目里做过类似的预判执行,欢迎在评论区聊聊实现思路。
6. 与 Prompt Cache 的共生关系
整个 Speculation 系统能成立,有一个前提条件:fork 出来的子代理必须共享父级的 Prompt Cache。 如果每次 fork 都要重新加载全部上下文,延迟会高到用户自己都输完指令了,Speculation 毫无意义。
CacheSafeParams 设计
forkedAgent.ts(689 行)里定义了一个 CacheSafeParams 类型:
// 源码路径:forkedAgent.ts → CacheSafeParams// 只包含不影响缓存键的参数:- systemPrompt- userContext- systemContext- toolUseContext- forkContextMessages源码里有一条硬性规则:DO NOT override any API parameter that differs from the parent request。唯一允许的 override 是 abortController、skipTranscript、skipCacheWrite、canUseTool – 这些参数不影响缓存键。
这个约束意味着 fork 出来的子代理在 API 层面和父级请求几乎一模一样。同样的模型、同样的 system prompt、同样的上下文。唯一的区别是 canUseTool 被替换了 – 子代理的工具权限被限制了,这是 Speculation 安全机制的一部分。
PR #18143 的教训
源码注释里提到了一个具体的 PR,是很好的工程教训:
设置
effort:'low'导致缓存写入暴增 45 倍,命中率从 92.7% 跌到 61%。
原因很简单:改变了任何一个 API 参数,都会导致缓存键不匹配。原本能命中缓存的请求全部变成 cache miss,每个 fork 出来的子代理都要重新写入一份完整的上下文缓存。
这个教训说明:在共享缓存的设计中,任何参数的修改都不是小事。一个看起来无害的 effort:'low',就能把整个缓存策略打穿。45 倍的缓存写入意味着 45 倍的 token 成本和 45 倍的延迟增加 – Speculation 从白嫖变成了血亏。
这个教训对任何做 AI Agent 开发的人都有参考价值:如果你的系统依赖 Prompt Cache 来控制成本和延迟,fork 子代理的时候一定要确保参数完全一致。哪怕只是改了一个看起来无关紧要的参数,都可能导致缓存全部失效。
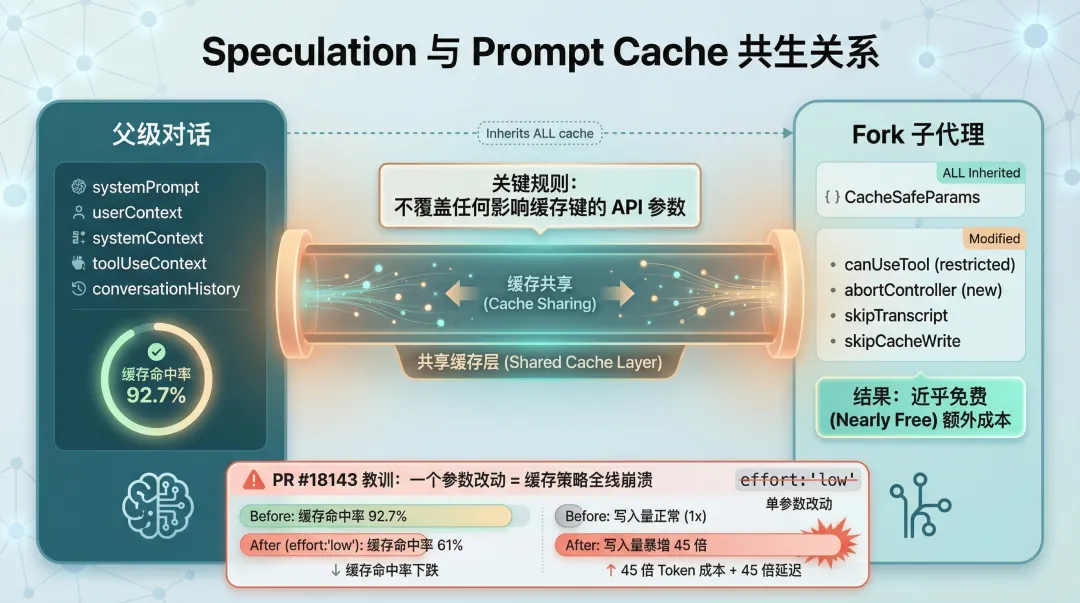
图 5:Speculation 与 Prompt Cache 的共生关系
总结
读完 Speculation 系统的源码,有四条启示:
1. Overlay Filesystem 是整个系统的基石。 没有 COW 的隔离机制,Speculation 就是在玩火 – 万一猜错了,用户的文件就被改坏了。Overlay 让先干了再说变成了安全的操作。这个思路可以迁移到任何需要预执行的场景:先在沙盒里跑一遍,确认了再合并。
2. 本质是数据库里的乐观并发控制(OCC)。 数据库里 OCC 的思路是:先假设不会冲突,把事务做完,提交时再检查。Speculation 完全是同一个思路 – 先假设用户会接受,把活干完,Tab 的时候再确认。理解了这个类比,整个系统的设计逻辑就通了。
3. 缓存共享是经济性的前提。 没有 Prompt Cache 的支撑,Speculation 的成本会让它不划算。这也是为什么必须用同一个模型、不能改任何 API 参数。缓存共享让 Speculation 从昂贵的前瞻执行变成了近乎免费的性能优化。
4. Or nothing 比「宁滥勿缺」好。 SUGGESTION_PROMPT 的设计哲学和 12 层过滤系统说明了一件事:乱预测比不预测更糟糕。宁可什么都不做,也不要打断用户。这个原则在很多产品设计里都适用 – 推荐系统、自动补全、智能助手,都应该是这个思路。
Speculation 系统的代码量不大(三个文件加起来 2200 行左右),但设计密度很高。每一个判断、每一个边界条件、每一层过滤都有明确的工程原因。这种代码读起来很过瘾 – 不需要猜作者为什么这么写,注释和代码结构把意图交代得清清楚楚。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
扫码关注,获取更多 AI 工具的实战经验和最佳实践。不错过每一篇干货!
