 夜雨聆风
夜雨聆风





Marker:高效 PDF 文档解析与结构化提取工具
👇 连享会 · 推文导航 | www.lianxh.cn
连享会:2026五一论文班 · 线上
时间:4月15日(先导课),5月2-4日(正式课)
嘉宾:郭士祺 (上海交通大学)、戚树森 (厦门大学)、李学恒 (中山大学)
咨询:王老师 18903405450(微信)

先导课:Claude Code / Opencode 快速上手
-
第一部分:安装与配置(25分钟)
-
Claude Code 与 Opencode 的定位与区别 -
两条安装路径:Claude Code(需特殊网络)vs Opencode(国内推荐,自带免费模型) -
完整工具链:AI 本体 + VS Code + Git + Miniconda + Pandoc -
现场演示:从零启动、界面介绍、常见问题排查 -
配套教程:《Opencode 套件安装指南》 -
第二部分:Skill 生态(35分钟)
-
什么是 Skill:从重复 prompt 到可复用工作规则 -
Skill 的三类分类:文档资产型、流程自动化型、MCP 增强型 -
发现、安装与触发机制(渐进式披露) -
演示 1:文件格式自由切换(PDF ↔ Markdown ↔ Word) -
演示 2: web-research深度网络调研,自动生成带引用的研究报告 -
演示 3: marp-slides-creator将调研报告一键转为演示文稿 -
串联效果:调研报告 → Markdown Slides → PDF

温馨提示: 文中链接在微信中无法生效。请点击底部「阅读原文」。或直接长按/扫描如下二维码,直达原文:

作者: 王烨文(武汉大学)邮箱: yw990818@163.com
Github:https://github.com/datalab-to/marker项目主页:https://www.datalab.to/
1. Marker 简介
Marker 是一款高性能的开源文档解析工具。它支持将多种格式的输入文件(包括 PDF、PNG、PPTX、DOCX 等)快速准确地转换为结构化的 Markdown、JSON 等格式。
-
支持所有语言的 PDF、图片、PPTX、DOCX、XLSX、HTML、EPUB文件解析 -
按照自定义 JSON schema进行结构化抽取(测试版) -
格式化输出 表格、表单、公式、行内数学、链接、参考文献和代码块 -
自动提取并保存 图片 -
移除 页眉、页脚及其他干扰元素 -
支持自定义格式化与处理逻辑,便于扩展 -
可选集成 LLM提升解析准确率 -
兼容 GPU、CPU和MPS等多种计算环境
下面是一些 Marker 的转换效果实例:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Marker 拥有卓越的文档理解与结构化输出能力,主要体现在以下几个方面:
-
广泛格式与复杂布局兼容:支持多语言文本及主流文档格式,能够精准解析多栏排版等复杂布局,并自动过滤页眉、页脚等干扰元素。 -
高精度内容还原:可完整保留表格结构,自动合并跨页表格,准确提取数学公式为 LaTeX 格式,有效保留代码块和文献引用,同时维护原始图文的对应关系。 -
安全高效的系统架构:支持本地化运行,保障数据隐私安全,并兼容 GPU、CPU 及 Apple Silicon (MPS) 等多种计算环境。 -
精度增强机制:集成大型语言模型(LLMs),进一步提升解析准确率。 -
便捷灵活的接入方式:同时提供命令行工具(CLI)和图形用户界面(GUI),满足不同用户的使用需求。
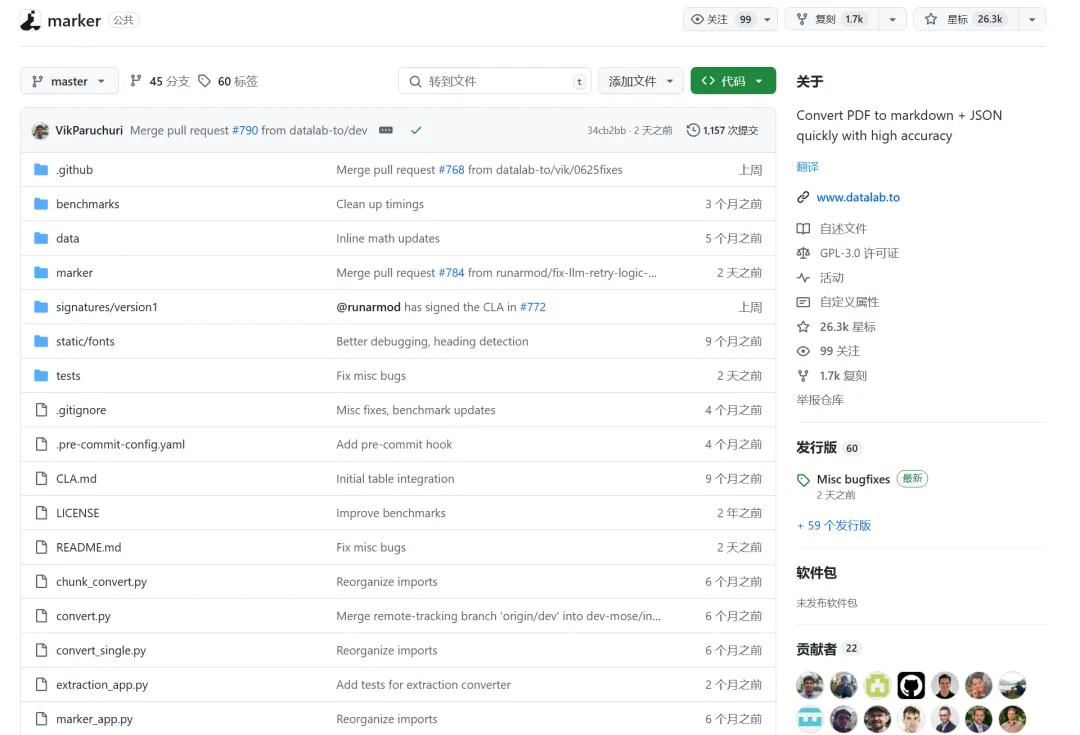
得益于强大的解析能力与优化设计,Marker 在处理速度和准确率方面均领先于同类工具。平均处理速度可达 2.84 秒/页,相较 Llamaparse 提升 8.2 倍,较 Mathpix 提升 2.2 倍。在 H100 GPU 环境下,吞吐量高达 122 页/秒。基础模式下表格准确率为 81.6%,结合 LLM 优化后可提升至 90.7%。
2. 本地部署
Marker 基于 Python 和 PyTorch 实现,需要 Python 3.10 或更高版本。为避免依赖冲突,强烈建议使用 Anaconda 创建独立虚拟环境。以下为 Marker 本地部署的标准流程:
第一步:创建 Python 环境
通过 Anaconda 创建并激活 Python 环境:
conda create -n `Marker` python=3.10conda activate marker第二步:安装 PyTorch
根据硬件配置安装相应的 PyTorch 版本。推荐 GPU 用户安装兼容 CUDA 的 PyTorch 版本以获得最佳性能,详细安装命令可参考 PyTorch 官网。
-
CPU 版本:
pip install torch torchvision torchaudio-
GPU 版本(示例:CUDA 11.8):
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
第三步:安装 Marker
安装 Marker 核心功能(PDF 格式支持):
pip install marker-pdf若需完整支持 PPTX、DOCX、图像等多种格式,建议安装完整依赖:
pip install "marker-pdf[full]"第四步:安装 GUI 支持(可选)
若希望使用 Marker 提供的图形界面,额外安装以下依赖:
pip install streamlit streamlit-ace至此,Marker 的本地部署完成,可以通过命令行或 GUI 界面开始解析文档。
3. 使用方法
Marker 提供了两种主要的本地使用方式:图形用户界面(GUI)和命令行(CLI),以满足不同用户的需求。
3.1 GUI 界面使用
对于不熟悉命令行的用户或需要快速预览转换效果的场景,可以使用 Marker 内置的 GUI。确保已安装 streamlit 相关依赖后,在终端运行以下命令启动 Marker 的 GUI 应用:
marker_gui这将启动一个基于 Streamlit 的本地 Web 应用。终端中会显示本地访问链接,通常为 http://localhost:8501,在浏览器中打开该地址即可进入 Marker 的交互界面。
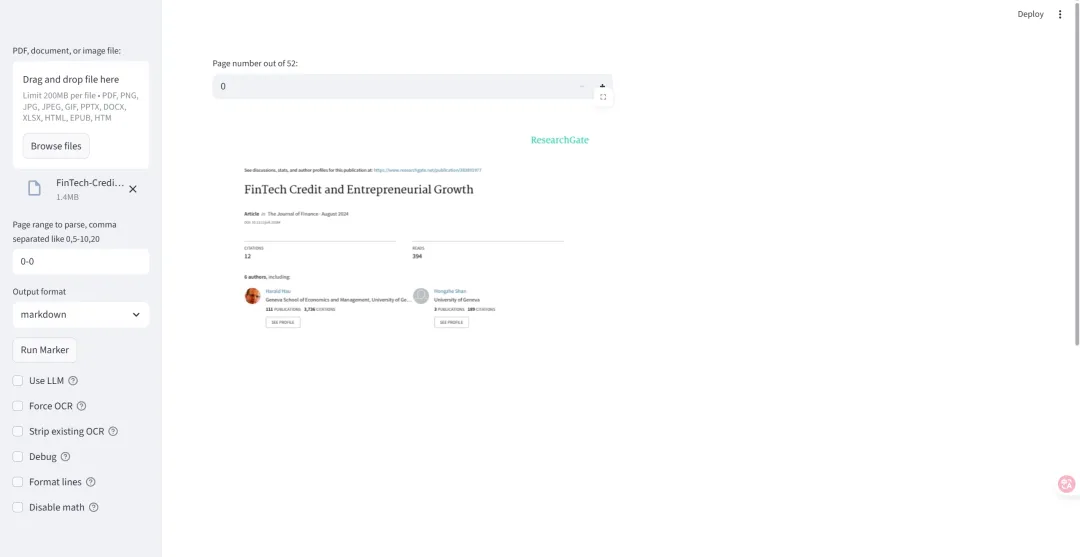
文件上传与选项设置
在 Marker GUI 中,通过“上传文件”按钮选择需要转换的文档。支持格式包括 PDF、图片(PNG、JPG、JPEG、GIF)、PPTX、DOCX、XLSX、HTML、EPUB、HTM 等。
上传后,用户可直接在界面中配置以下核心选项:
-
页面范围:指定需要解析的页面范围,例如 0-5或10,20,支持单页或多页解析。 -
输出格式:支持导出为 Markdown、JSON、HTML 等格式。
此外,界面左侧提供高级设置选项,以便针对具体文档进行更精细的定制:
-
Use LLM:启用大语言模型辅助解析,提升复杂文档的理解和结构化精度(需配置相应的 LLM 服务及 API 密钥)。 -
Force OCR:强制进行 OCR 识别,适用于图像型 PDF 或 OCR 质量较差的文件。 -
Strip existing OCR:删除现有 OCR 层并重新解析内容,提升输出准确性。 -
Debug:开启调试模式,显示详细的中间输出,有助于问题排查。 -
Format lines:自动优化文本行结构,移除多余换行,提升输出整洁性。 -
Disable math:关闭数学公式识别功能,避免公式密集文档中可能产生的干扰。
3.2 命令行使用(CLI)
命令行是 Marker 最强大且高效的使用方式,尤其适合自动化处理和批量任务。
3.2.1 单个文件转换
使用 marker_single 命令处理单个 PDF 或图片文件时,需要创建两个文件夹:pdf 用于存放待转换文件,output 用于存放转换结果。
基本用法
marker_single pdf/FinTech-Credit-and-Entrepreneurial-Growth.pdf --output_dir output-
marker_single为单文件处理命令。 -
pdf/FinTech-Credit-and-Entrepreneurial-Growth.pdf为输入文件路径。 -
--output_dir output将结果保存至当前目录下的output文件夹。
解析完成后,输出目录中将生成提取的图片、表格结构化信息的 JSON 文件和 PDF 详细内容的 Markdown 文件。
高级参数说明
|
|
|
|
|---|---|---|
--output_format |
|
--output_format json |
--page_range |
|
--page_range "0,5-10,20" |
--use_llm |
|
--use_llm |
--force_ocr |
|
--force_ocr |
--langs |
|
--langs zh |
以上参数可自由组合,满足多种复杂需求。示例:
marker_single pdf/FinTech-Credit-and-Entrepreneurial-Growth.pdf --output_dir output --output_format html --page_range "0,5-10,20" --force_ocr3.2.2 批量处理文件夹
marker 工具具备批量处理能力,能够对一个指定文件夹内的全部文档进行转换。其基本操作方式是将包含源文件的输入文件夹路径,即 pdf,作为命令的主要参数。而转换后文件的存放位置,则需要通过 --output_dir 参数来明确指定,在此例中为 output 文件夹。因此,执行批量转换的基础指令构建如下。
`Marker` --output_dir output pdf为进一步提升处理效率,尤其是在处理大量文档时,可以启用并行处理功能。正确的参数是 --pdftext_workers,该参数用于设定在 PDF 文本提取环节并行执行的工作进程数量。通过设定一个整数值,可以有效利用计算设备的多核处理能力,加速文档内容的读取过程。例如,若需指定 4 个工作进程来执行文本提取,则应使用如下命令。
`Marker` --output_dir output --pdftext_workers 4 pdf3.3 LLM 增强模式
Marker 独特之处在于能够与大型语言模型(LLM)结合,进一步提升文档解析质量。当启用 --use_llm 参数时,Marker 会在常规解析基础上调用 LLM 进行结果优化,以更精准地还原文档的原始语义。
在 LLM 增强模式下,Marker 能智能处理跨页内容,例如自动拼接跨页表格、准确识别复杂公式与特殊符号、优化表格排版,并从图表或表单中提取关键信息。这种 LLM 提供的智能后处理,有效提高了输出文档的准确性和易用性。
配置 LLM 服务
默认情况下,Marker 使用 Google Gemini 2.0 模型作为 LLM 服务(需要提供 Google API 密钥)。使用前,需将 Google API Key 写入环境变量 GOOGLE_API_KEY。
除了 Gemini,Marker 还支持通过 Ollama 使用本地模型或其他兼容服务作为 LLM 后端。配置本地 Ollama 服务时,需要在命令行指定模型名称。例如,在 Ollama 中配置 qwen3:0.6b 模型时,可这样指定
marker_single pdf/FinTech-Credit-and-Entrepreneurial-Growth.pdf --output_dir output --llm_service marker.services.ollama.OllamaService --ollama_model qwen3:0.6b此外,Marker 提供 --block_correction_prompt 参数,允许用户输入自定义的 Prompt,以精确控制 LLM 行为,从而实现特定的内容输出或排版风格。例如,可通过 Prompt 指定所有公式统一转换为标准 LaTeX 格式,或按特定的 Markdown 模板优化文本排版。这种高度的可定制性,让用户能充分发挥 LLM 的潜力,更好地满足复杂文档解析需求。
4. 结语
作为一款本地可部署的文档解析工具,Marker 在速度和准确率上都表现突出,又兼具对学术内容的深度支持和结构化导出能力。无论是批量转换文献资料,还是构建论文知识库,Marker 都是不容错过的高效解决方案。项目已在 GitHub 开源,借助 Marker 的强大功能,处理繁杂的 PDF 文档将变得轻松高效。
5. 相关推文
Note:产生如下推文列表的 Stata 命令为:
lianxh 大语言 AI工具 翻译, nocat md安装最新版lianxh命令:ssc install lianxh, replace
-
吴欣洋, 2025, AI自动生成研究假设,靠谱吗?流程与挑战, 连享会 No.1588. -
张弛, 2025, 大语言模型到底是个啥?通俗易懂教程, 连享会 No.1600. -
张弛, 2025, 找不到IV?如何借助大语言模型寻找工具变量, 连享会 No.1575. -
林俊杰, 2025, 如何快速翻译英文 PDF?推荐一个超实用网站, 连享会 No.1629. -
许梦洁, 2021, Python爬虫:爬取华尔街日报的全部历史文章并翻译, 连享会 No.743. -
连小白, 2025, AI助手系列:napkin.ai-文字转换为图片和表格, 连享会 No.1540. -
连小白, 2025, AI助手系列:借助AI工具复现高质量图形, 连享会 No.1584. -
连小白, 2025, AI工具系列:英文学术论文语法检测与纠正, 连享会 No.1562. -
连小白, 2025, AI工具!AI工具分类大集合, 连享会 No.1587. -
连小白, 2025, No Chinglish:学术写作中的中式英语陷阱, 连享会 No.1563. -
陈庭伟, 2025, 2025年学术研究中的15大最佳AI工具, 连享会 No.1578.


连享会:2026五一论文班 · 线上
时间:4月15日(先导课),5月2-4日(正式课)
嘉宾:郭士祺 (上海交通大学)、戚树森 (厦门大学)、李学恒 (中山大学)
咨询:王老师 18903405450(微信)

New! Stata 搜索神器:
lianxh和songblGIF 动图介绍
搜: 推文、数据分享、期刊论文、重现代码 ……
👉 安装:. ssc install lianxh. ssc install songbl
👉 使用:. lianxh DID 倍分法. songbl all
🍏 关于我们
-
• 连享会 ( www.lianxh.cn,推文列表) 由中山大学连玉君老师团队创办,定期分享实证分析经验。 -
• 直通车: 👉【百度一下:连享会】即可直达连享会主页。亦可进一步添加 「知乎」,「b 站」,「面板数据」,「公开课」 等关键词细化搜索。
