 夜雨聆风
夜雨聆风





Claude Code 源码拆解第四篇:为什么聊久了它还没失忆?自动压缩与上下文续命机制
为什么聊久了它还没失忆?自动压缩与上下文续命机制
不是把历史删掉,而是在上下文快炸的时候,把任务接力棒稳稳传下去。
前两天,一个朋友给我发来一段很典型的 Claude Code 对话。
前面四十分钟都很顺:读文件、跑命令、改代码、查报错,节奏一点问题没有。
结果到后面,味道开始变了:
-
明明刚看过的文件,它又想再读一遍。 -
刚定下来的计划,它开始答非所问。 -
回答没有完全错,但越来越飘,越来越慢。
是不是模型状态掉了?
我说,不是模型状态掉了,是上下文快满了。
第三篇我们刚讲完:工具多不一定更强,上下文脏了,agent 就会越来越笨。
第四篇更值得讲的是另一半问题:
那 Claude Code 为什么没有像很多 AI 工具那样,聊久了就直接失忆?
答案不是“它的模型更聪明”,而是它在源码里专门做了一整套自动压缩与上下文续命机制。

这篇你会看到什么
-
为什么上下文不能简单截断 -
自动压缩在什么阈值触发 -
为什么 compact 本质上是“续命”而不是“摘要” -
连 compact 请求自己都超长时,Claude Code 怎么救火 -
压缩后文件、计划、技能、工具状态怎么补回去
一、上下文快炸的时候,为什么不能简单截断
很多人对“压缩”的直觉是:把最早的对话删掉,只留最近几轮继续聊。
这个想法看起来很合理,但对 agent 来说其实很危险。因为长任务里真正重要的,不只是“最近一句话”,还包括文件状态、plan mode、skill 状态、deferred tools、后台 agent 状态这些工作现场。
所以 Claude Code 在 src/services/compact/compact.ts 里干的事,不是简单“删旧消息”,而是:先总结历史,再把继续工作所必需的状态重新补回来。
二、自动压缩不是等爆了再救火,而是提前留缓冲区
在 src/services/compact/autoCompact.ts 里,Claude Code 先算的是 effective context window,也就是模型标称上下文扣掉预留给压缩摘要输出的空间之后,真正还能用的预算。
export function getEffectiveContextWindowSize(model: string): number {
const reservedTokensForSummary = Math.min(
getMaxOutputTokensForModel(model),
MAX_OUTPUT_TOKENS_FOR_SUMMARY,
)
return contextWindow - reservedTokensForSummary
}源码里默认给 summary 预留了 20_000 token。原因很直接:compact 本身也是一次模型调用,如果你把窗口吃到满格,再去请求 compact,compact 请求自己都有可能先炸。
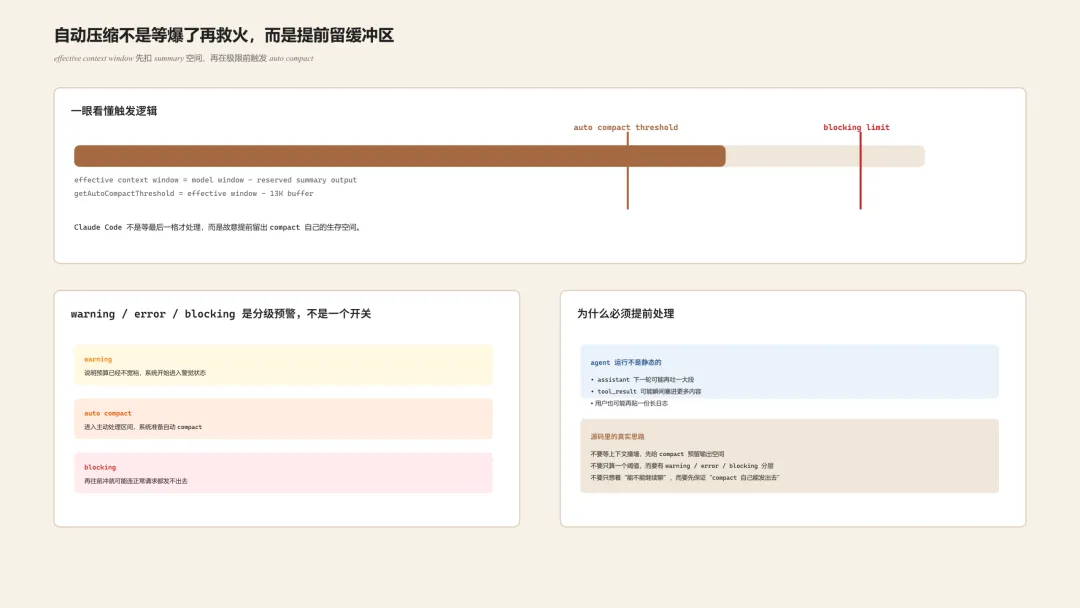
接着它会继续算自动压缩阈值:
export const AUTOCOMPACT_BUFFER_TOKENS = 13_000
export function getAutoCompactThreshold(model: string): number {
const effectiveContextWindow = getEffectiveContextWindowSize(model)
return effectiveContextWindow - AUTOCOMPACT_BUFFER_TOKENS
}翻译成人话就是:Claude Code 会故意在真正极限之前,提前空出一块缓冲区。
为什么这一步很关键
agent 运行是动态的。你刚算完 token,下一轮 assistant、多段 tool_result、用户新贴的长日志,都可能立刻把窗口打满。系统如果总等到最后一格才处理,基本注定来不及。
三、它不只算一个阈值,而是分成 warning、error、blocking 三层
在 calculateTokenWarningState() 里,Claude Code 不是只判断“要不要 compact”,而是把上下文状态拆成 warning、error、auto compact threshold 和 blocking limit 四层。
这意味着它在处理上下文时,更像一套分级预警系统,而不是一个二元开关。很多 AI 工具的痛点就在这里:平时没预算意识,真超长了才突然丢给你一句 prompt too long,任务直接断掉。
四、自动压缩到底什么时候触发
触发判断在 shouldAutoCompact():
const tokenCount = tokenCountWithEstimation(messages) - snipTokensFreed
const threshold = getAutoCompactThreshold(model)
const { isAboveAutoCompactThreshold } = calculateTokenWarningState(
tokenCount,
model,
)
return isAboveAutoCompactThreshold这里最重要的两个点是:
-
它用的是估算 token,而不是每次等 API 的精确统计回来。 -
它有递归保护,避免 compact、session_memory、某些 context collapse / reactive compact 模式里再触发 compact,防止系统死循环。
五、真正开始压缩时,它不是本线程硬做,而是 fork 一个 agent 去总结
在 compactConversation() 里,Claude Code 不是在当前主线程里直接把历史改写掉,而是发起一次专门的压缩流程,生成 summary,再用新的消息结构替换旧上下文。
源码注释里有一句很关键:
// forked-agent path reuses main conversation's prompt cache.这表示 compact 不是完全额外再开一份陌生请求,而是尽量复用主对话已有的 prompt cache。这样不仅更省 token,也能避免 compact 自己变成新的成本黑洞。

六、压缩前先做减法:图片、文档、重复注入的附件先剥掉
在真正发起 compact 请求之前,Claude Code 会先做减法。
stripImagesFromMessages() 会把图片和文档替换成 [image]、[document] 这样的标记;stripReinjectedAttachments() 会剥掉一些后面本来就会重新注入的 attachment。
这里非常能看出工程思路:不让 summarizer 背不该背的负担。 要压缩的是任务历史,不是把所有上下文原封不动再跑一遍。
七、最危险的情况:连压缩请求自己都超长了,怎么办
很多系统做到“自动压缩”这一步就停了,但 Claude Code 继续往前想了一层:如果上下文已经脏到一种程度,连 compact 请求自己都发不出去怎么办?
在 compact.ts 里,答案是 truncateHeadForPTLRetry()。
它会先按 API round 分组,再从最老的一批 group 开始裁掉,然后重试 compact。配合的分组函数在 src/services/compact/grouping.ts:
export function groupMessagesByApiRound(messages: Message[]): Message[][]这一步的关键不是“裁掉最早的东西”这么简单,而是要保证切分点依然对 tool_use / tool_result 链是安全的,不把一个未闭合的调用链硬拆开。
这里最值得学的不是 happy path
最值钱的是 Claude Code 连“救火流程自己都着火了”这件事都提前想到了。成熟 agent 系统的上限,很多时候就藏在这些坏路径里。
八、压缩完成后,真正难的不是“生成摘要”,而是“怎么继续干活”
从 buildPostCompactMessages() 的返回结构就能看出来,compact 之后留下来的不只是 summary:
return [
result.boundaryMarker,
...result.summaryMessages,
...(result.messagesToKeep ?? []),
...result.attachments,
...result.hookResults,
]它真正干的是:压缩不是清空上下文,而是重建一个“还能工作的上下文”。
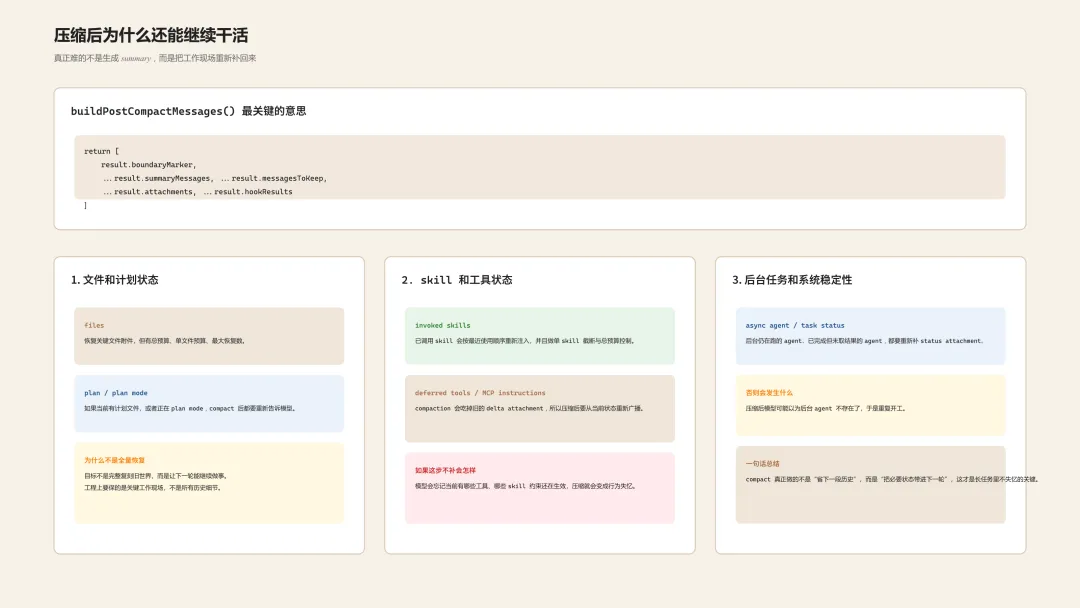
九、Claude Code 压缩后会主动补哪些状态
-
文件状态:恢复关键文件附件,但有单文件和总 token 预算。 -
plan 状态:如果有 plan 文件或处于 plan mode,会重新注入对应 attachment。 -
skill 状态:已调用 skill 会做截断后重新注入,避免行为规范丢失。 -
工具和指令状态:deferred tools delta、agent listing delta、MCP instructions delta 都会重新广播。 -
后台 agent 状态:仍在执行或尚未取回结果的 agent,会重新补 task status。
这套动作本质上都在做同一件事:让模型继续知道自己当前处在什么工作现场里。
十、自动压缩还自带熔断器,避免失败后反复空转
在 autoCompactIfNeeded() 里,还有一个很像分布式系统的设计:连续失败熔断器。
const MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3如果自动压缩连续失败,Claude Code 不会在每一轮都继续发起注定失败的 compact 请求,而是到阈值后停掉后续自动尝试,避免把会话拖进更坏的状态。
十一、那 micro compact 是什么
这篇主讲自动压缩,但 src/services/compact/microCompact.ts 也值得顺手提一下。
它更像“边跑边清理桌面”:对文件读取结果、shell 输出、grep / glob / web fetch 结果、部分旧 tool_result 做轻量止血。full compact 更像一次阶段总结,micro compact 更像过程中的即时整理。
十二、这套设计对我们自己写 agent,有什么直接启发
如果你自己也在做 agent,这 4 条最值得带走
-
不要把 compact 理解成摘要功能,它真正解决的是任务连续性。 -
压缩一定要带状态恢复,不然只是在高级删历史。 -
一定要给 compact 自己留缓冲区,不要吃到 99% 才想起处理。 -
一定要设计坏路径,真正能跑长任务的 agent 拼的是故障时还能不能稳住。
总结
第三篇讲的是:上下文为什么会脏。
第四篇补上的,是另一半:上下文脏了以后,Claude Code 怎么不让 agent 当场失忆。
它的答案不是简单粗暴地删历史,而是提前算预算、在阈值附近自动 compact、用 forked agent 做总结、最坏情况下继续裁老消息重试、压完以后把文件、计划、skill、工具和后台任务状态重新补回去。
所以你会发现,Claude Code 的 compact 其实不是一个“省 token 小技巧”,而是一套真正的上下文续命系统。
长任务里,真正重要的不是“模型记住了多少历史”,而是“系统有没有能力把必要状态带着活下去”。
很多人做 agent,精力都花在“多接几个工具”“多写几段 prompt”“多堆几个 workflow”。但 Claude Code 这段源码真正提醒我们的,是另一件更朴素、也更关键的事:
真正决定 agent 上限的,往往不是它最能打的时候,而是它快撑不住的时候,系统有没有办法把它救回来。
关键源码位置
src/services/compact/autoCompact.ts:33-49src/services/compact/autoCompact.ts:62-91src/services/compact/autoCompact.ts:93-145src/services/compact/autoCompact.ts:160-239src/services/compact/autoCompact.ts:241-351src/services/compact/compact.ts:145-223src/services/compact/compact.ts:243-260src/services/compact/compact.ts:330-338src/services/compact/compact.ts:387-760src/services/compact/compact.ts:1470-1599src/services/compact/grouping.ts:1-63src/services/compact/microCompact.ts:40-50, 253-260