 夜雨聆风
夜雨聆风





qmd:本地文档三路混合检索工具,可接入 Claude Code,约 19.5K Star

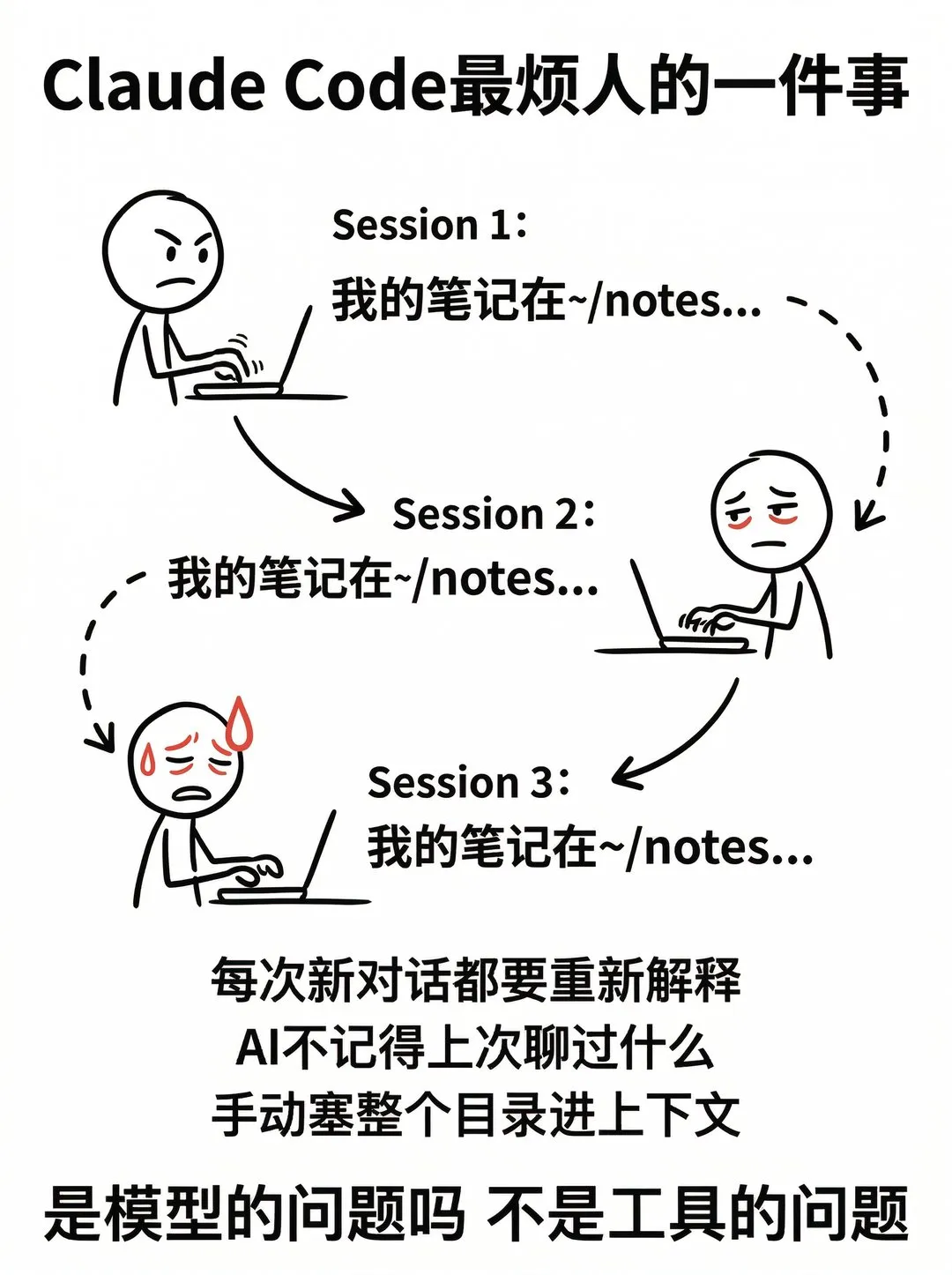
每次打开 Claude Code 新对话,我都得重新说一遍:笔记在 ~/notes,文档在 ~/docs,上周的会议纪要在另一个目录。说到第五次的时候我真的烦了。
不是 Claude Code 不行。Claude Code 已经很强。问题是它不知道你的本地资料结构,每次对话都是一张白纸。你要么手动塞整个目录进上下文(超长超贵),要么每次都给它讲一遍”我的东西在哪”。这两条路都不好受。
qmd 干的就是这事:把你本地的笔记、文档、会议记录先索引好,让 Claude Code 需要的时候自己去翻。
qmd 全称 Query Markup Documents。README 里的定义很克制:”mini cli search engine for your docs, knowledge bases, meeting notes, whatever”——给你本地的笔记、知识库、文档做的全本地检索引擎。
它是 MIT 协议的开源项目,2025 年 12 月上线,截至本文截稿 GitHub 大概 19.5K Star、约 1.1K Fork,数字会动以 GitHub 为准。
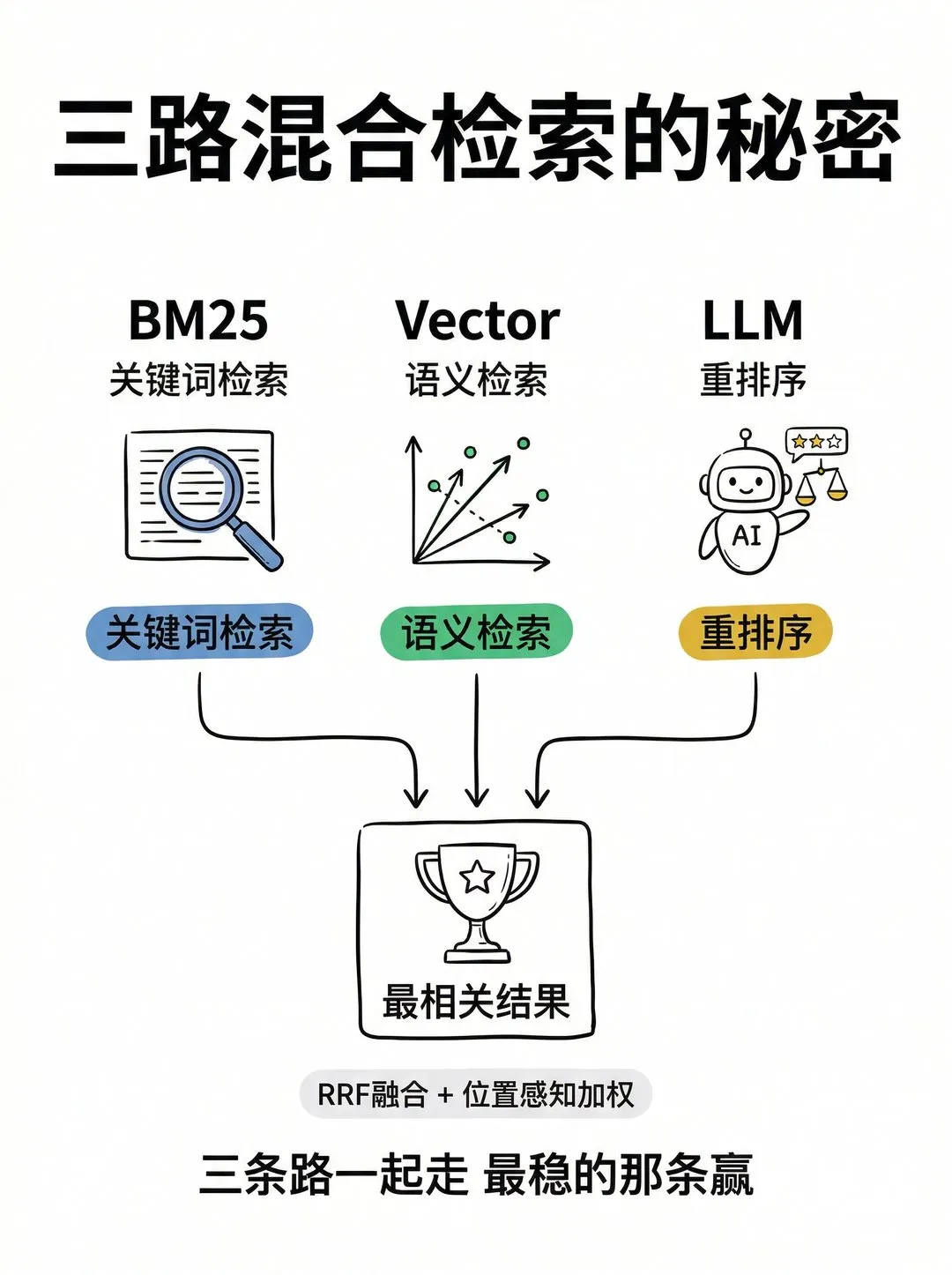
核心组合是三路混合:
-
• BM25 全文检索(传统关键词匹配,FTS5 实现) -
• 向量语义检索(本地 embedding 模型) -
• LLM 重排序(本地 reranker 模型给结果打分重排)
三种检索路线融合成一个查询接口,对外通过 CLI 和 MCP 服务器提供。所有模型通过 node-llama-cpp 加载 GGUF 格式本地运行,完全不调任何云端 API,也不上传任何文件。
需要说清楚的是:qmd 的定位很窄,就是做”本地文档混合检索”这一件事。它不处理 agent 循环、不管跨会话状态,也不是什么大而全的平台。作者自己在 README 里写的就是 “mini cli search engine”,很克制。
二、解决的是什么真实场景
我自己最常碰到的有三个瞬间:
-
• 新开对话时,又得重新解释目录结构 -
• 想让 Claude Code 看某次会议纪要,但不知道该塞哪几份进去 -
• 资料散在 notes、docs、transcripts 里,关键词搜得到的语义未必搜得到,语义能搜到的又可能不够准
qmd 干的事其实很朴素:先把这些资料变成一个能查的入口,然后把查询能力通过 MCP 暴露给 Claude Code。Claude Code 在回答你的问题时,可以主动调用 qmd 的搜索工具,按相关度拉回你本地的文档,再基于文档回答。
三、三路混合检索 + 位置感知融合
qmd 的 query 命令大致做了这些事:
-
1. 查询扩展:原始查询 + LLM 生成的变体 -
2. 并行检索:每个查询同时走 BM25 和向量两条路 -
3. RRF 融合:用 Reciprocal Rank Fusion 合并多路结果 -
4. LLM 重排序:用本地的 reranker 模型给前若干个候选打分 -
5. 位置感知混合:排名越靠前的文档,越相信原始检索结果;排名越靠后,越相信重排分数
这套设计的关键巧思是:纯 RRF 可能会稀释精确匹配。如果你查了一个非常具体的关键词,RRF 把所有扩展查询拉进来一平均,反而可能把最相关的那条压下去。位置感知混合相当于给前排留了一个”保护席位”。
对读者来说,你不需要记住每个超参数,只要知道结果是:混合检索 + 重排,尽量同时兼顾关键词的精确匹配和语义的模糊匹配。
四、本地跑的 GGUF 模型
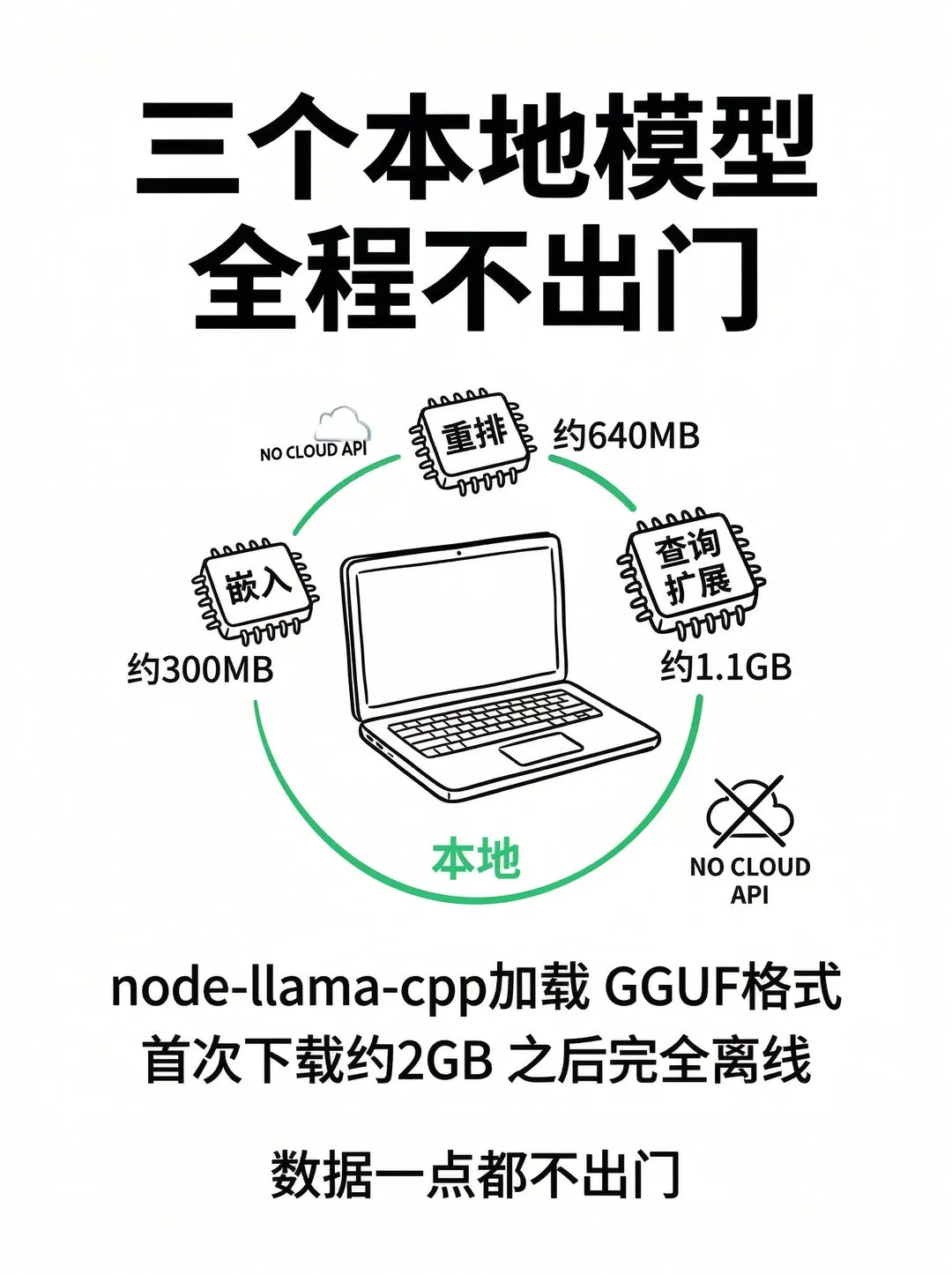
qmd 默认用三个本地 GGUF 模型,首次运行会自动从 HuggingFace 下载到本地缓存:
-
• 嵌入模型 embeddinggemma 300M(默认) -
• 重排模型 qwen3-reranker 0.6B -
• 查询扩展模型(作者微调,约 1.7B)
三个加起来大概 2GB。首次下载要等一会儿,之后完全离线可用。
中文支持是很多中文用户会关心的点。默认的 embeddinggemma 是英文优化的,对中文效果一般。qmd 支持通过环境变量切换到 Qwen3-Embedding-0.6B:
export QMD_EMBED_MODEL="hf:Qwen/Qwen3-Embedding-0.6B-GGUF/Qwen3-Embedding-0.6B-Q8_0.gguf"qmd embed -fQwen3-Embedding-0.6B 支持多语言,包括中日韩。对中文笔记为主的用户基本是必换项。换模型之后一定要跑 qmd embed -f 重建索引,因为不同模型的向量空间不兼容。
五、Claude Code 集成:两条命令

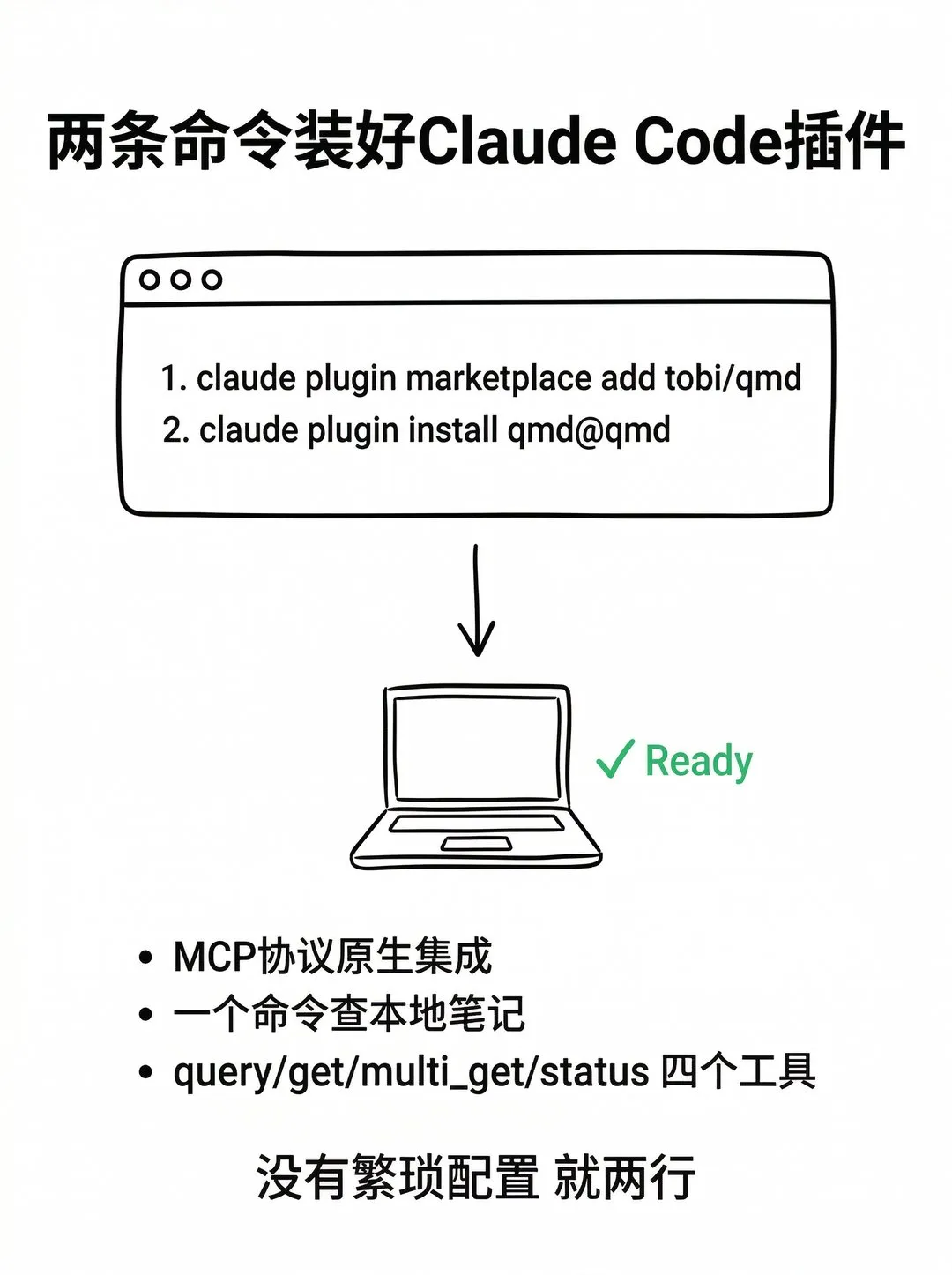
qmd 让我觉得最友好的一个点就是 Claude Code 集成非常简单,README 给的官方命令是:
claude plugin marketplace add tobi/qmdclaude plugin install qmd@qmd装好之后 Claude Code 会直接把 qmd 的 MCP 工具挂进来:
-
• query— 混合检索 + 重排 -
• get— 按路径或 docid 拿单个文档 -
• multi_get— 批量拿文档 -
• status— 索引健康度和 collection 信息
如果你不用 Claude Code 但用 Claude Desktop,README 里也给了 claude_desktop_config.json 的配置方式。qmd 还支持 HTTP 长驻模式,让 MCP 服务常驻不用每次重新加载模型,这对多 agent 同时用的场景更省时间。
六、上手流程
基本工作流是 collection → context → embed → query 四步:
# 加集合qmd collection add ~/notes --name notesqmd collection add ~/Documents/meetings --name meetings# 给集合加描述(作者在 README 里特意说这个别忽视)qmd context add qmd://notes "Personal notes and ideas"qmd context add qmd://meetings "Meeting transcripts and notes"# 生成嵌入qmd embed# 查询qmd query "quarterly planning process"context add 的作用是给每个集合或路径加一句话描述,这个描述会作为树形结构返回给调用方。对 LLM 来说,知道”这是会议记录”还是”这是个人笔记”直接影响它怎么理解返回的文档。作者说这个功能别忽视,我理解下来确实是 qmd 相比普通本地检索工具多出来的一个小但关键的设计。
七、局限与适用边界
-
• 首次装要下约 2GB 模型:三个 GGUF 模型合计约 2GB,首次运行自动下载,网速慢要等。 -
• Node.js 22+ 强依赖:老版本 Node 跑不起来。Bun 也需要 1.0+。 -
• macOS 需要额外装 SQLite:用到了 FTS5 扩展,系统自带的 SQLite 可能缺支持。要 brew install sqlite。 -
• 默认 embedding 对中文一般:中文用户基本必须换 Qwen3-Embedding。 -
• 作用域很窄:qmd 就做”本地文档混合检索”这一件事。想要更复杂的 agent 能力,得配合 Claude Code 等框架一起用。 -
• 定位是 mini CLI:README 自己写的是 “mini cli search engine”,别把它想象成大而全的 AI 平台。
八、给谁用
对我来说,舒服的地方不是它让 Claude Code 更聪明了,而是不用每次重新交代背景。如果你平时用 Claude Code,而且资料散得比较开(notes、docs、会议纪要混在一起),这个东西会很顺手。
如果你主要写小工具小脚本,或者只处理单文件,qmd 的收益就不太明显——它是为”大量本地文档 + 跨文件检索”这个场景准备的。
这个项目对我最大的触动不是技术本身,而是它解决的问题抓得很准:一个非常具体、每天都在发生的小痛点,被一个非常窄的工具处理顺了。有时候最有用的东西就长这样。
项目地址:github.com/tobi/qmd
NPM:@tobilu/qmd
作者:Tobi Lütke
License:MIT
数据截至:2026 年 4 月 8 日(Star/Fork 数字会随时变动,以 GitHub 为准)
欢迎大家进群沟通交流
微信:Tinker_AI