 夜雨聆风
夜雨聆风





Claude Code 源码解析(一):从工具调用到 Agent Harness
AI应用实录 · Claude Code 源码拆解 · 第一章
Claude Code 51 万行代码拆解第一章——它不是 API 封装,而是一个完整的 Agent 运行时。
2025 年以前,我们跟 AI 的交互方式基本就一件事:打字 → 等回复 → 手动操作。
想让 AI 帮你改代码?它只能告诉你”你可以在第 42 行加一个 if 判断”——真正动手改的还是你自己。想让它帮你整理文件、调试报错?它只能给建议,真正去做的是你。
LLM 能”说话”,但不能”做事”。 无法读取文件系统,无法执行命令,无法创建 Git 分支,更无法在遇到错误时自主调整策略。每一次与外部世界的交互,都需要人类充当中间人。不管理解力多强、推理多精准,它的能力止步于文本输出。
2025 年之后,事情变了。LLM 开始有了”工具调用”(Tool Use / Function Calling)能力——它不仅能理解你的需求,还能自己决定调用哪个工具、传什么参数、怎么处理返回结果。
举个具体例子:你说”帮我把项目里所有的 console.log 都删掉”。以前 AI 会回复”你可以用正则搜索替换……”。现在它会:
1.调用文件搜索工具,找到所有包含 console.log 的文件
2.逐个调用文件编辑工具,删除对应行
3.调用终端工具运行测试,确认没有破坏功能
4.汇报结果:”已删除 23 个文件中的 47 处 console.log,测试全部通过。”
LLM 的角色从”对话伙伴”变成了”任务编排器”——从回答问题,变成了解决问题。
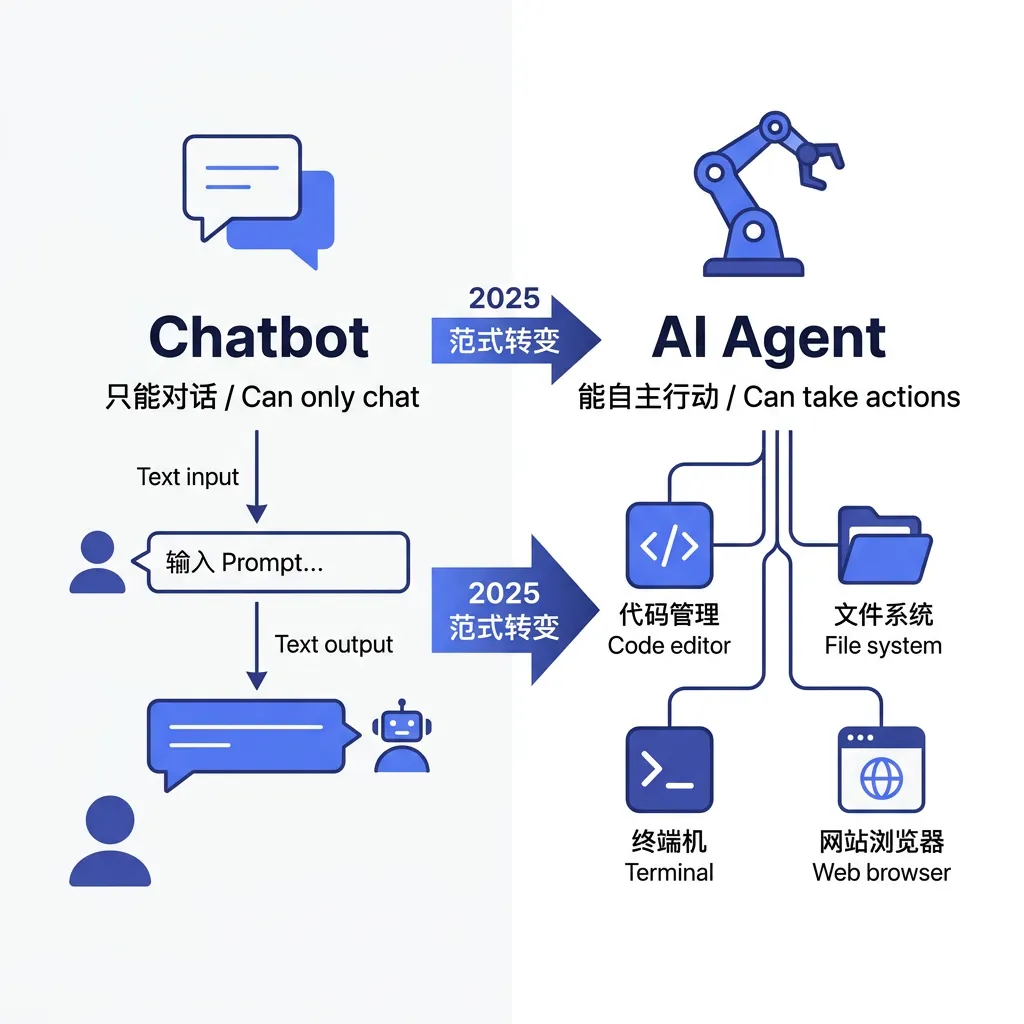
▲ LLM 角色演进:从 Chatbot 到 Agent
但这也意味着,我们需要一套全新的工程体系来支撑这种”行动能力”。
一旦 LLM 能操作真实世界,工程问题就来了。实际生产环境中,至少有六个硬骨头要啃:
🔧 工具管理:几十上百个工具,怎么注册、怎么动态添加?Token 是有限的,工具越多,模型选错的概率越大。需要一套智能的工具发现和过滤机制。
🛡️ 参数校验:LLM 生成的参数是不可预测的——类型错误、字段缺失、数值越界。你让它传文件路径,它可能传成 URL;让它传数字,它可能传字符串 “42”。
🔐 权限管控:模型可能要求执行 rm -rf /,你总不能真的执行吧?更微妙的是——rm -rf node_modules 是安全操作,rm -rf ~/.ssh 是灾难。权限不是简单的”允许/禁止”,要根据命令、参数、上下文做细粒度判断。
🔄 错误恢复:API 超时、工具崩溃、输出格式乱了——每种错误都需要不同的恢复策略,否则 Agent 会陷入死循环直到 Token 用完。
📦 状态一致性:多轮工具调用操作同一份资源,如何保证不出现”改了一半”的脏状态?
⚡ 并发调度:读 5 个文件可以同时进行,但”先建目录再写文件”必须串行——怎么智能地判断?
这六个挑战催生了一个新概念——Agent Harness。

▲ Agent 生产级六大工程挑战
一个常见误解:Agent Harness 不就是对 LLM API 包了一层吗?
这种理解停留在理想世界里——假设 API 永不超时,模型输出永远正确,上下文窗口无限大,所有操作都安全。真实环境会逐一打破这些假设。来看看差距到底有多大:
|
|
|
|
|---|---|---|
| API 调用 |
|
|
| 工具执行 |
|
|
| 上下文 |
|
|
| 错误处理 |
|
|
| 状态管理 |
|
|
| 安全 |
|
|
一句话总结:Agent Harness 是围绕 LLM 构建的运行时框架,它把 LLM 从文本生成器提升为能够安全、可靠、高效地与外部世界交互的自主智能体。
类比:LLM 是发动机,Agent Harness 是整辆车——包括变速箱、刹车、悬挂、仪表盘、安全气囊。你不能只有发动机就上路。
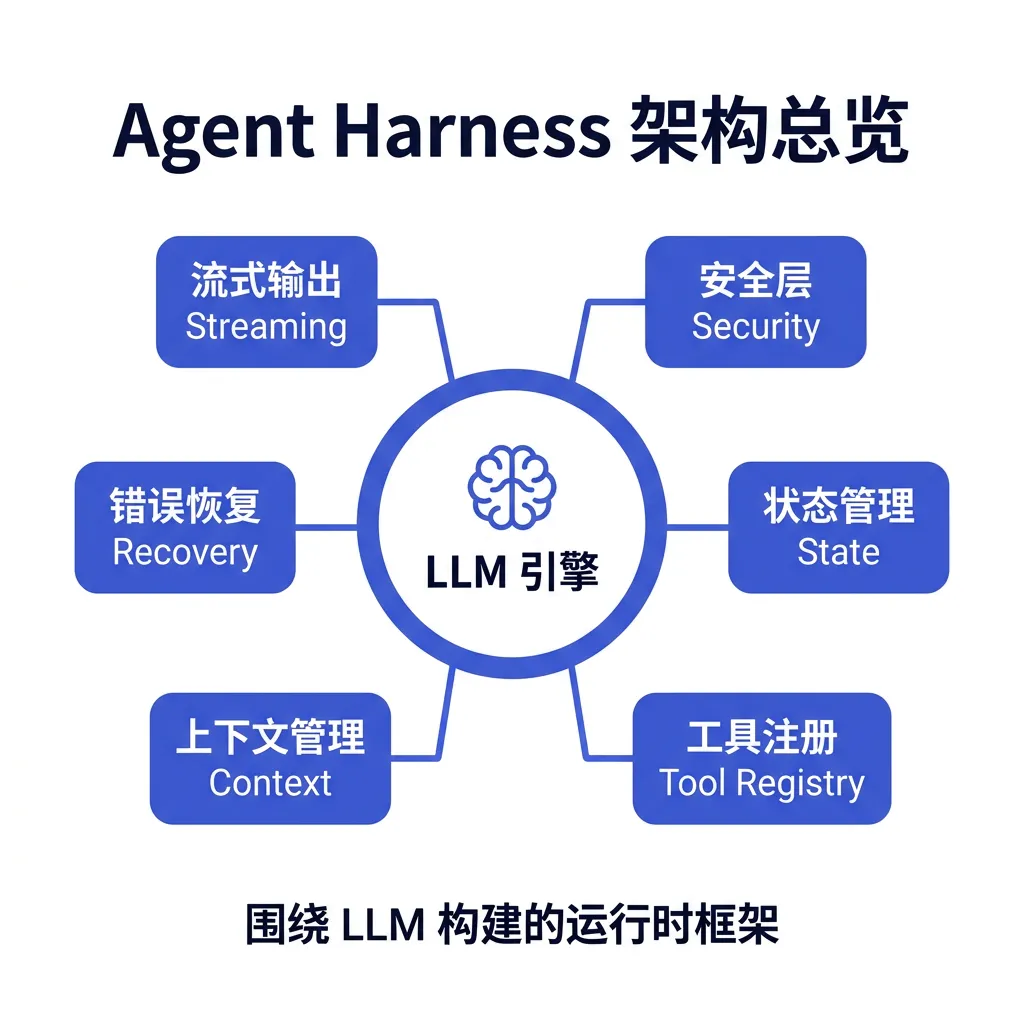
▲ Agent Harness 架构总览
项目规模
Claude Code 的 src 目录包含 1,884 个 TypeScript 文件,总计 512,664 行代码。
做几个对比:VS Code 核心约 50 万行(体量相当)、React 约 20 万行(Claude Code 是它的 2.5 倍)、Express.js 约 1 万行(50 倍)。说明一个成熟的 Agent Harness,工程复杂度不亚于一个完整的编辑器框架。
但代码多不等于臃肿。Claude Code 的组织表现出高度模块化特征:每个工具是独立模块,每个子系统有清晰边界,职责划分遵循单一职责原则。
技术选型:为什么选这些?
|
|
|
|
|
|---|---|---|---|
| 运行时 |
|
|
|
| 终端 UI |
|
|
|
| CLI 框架 |
|
|
|
| Schema 验证 |
|
|
|
| LLM SDK |
|
|
|
React + Ink —— 用写网页的方式写终端 UI。工具执行进度条、权限确认对话框、多列搜索结果展示,背后都是 React 组件。Web 领域验证过的组件化思维,直接搬到终端里来。
Zod v4 —— LLM 生成的参数完全不可预测。你定义了 { path: string, line: number },模型可能传回 { filepath: "src/index.ts", lineNumber: "42" }。Zod 写一份 Schema,同时获得 TypeScript 类型、运行时校验、API 文档三种能力,而且参数错了能给模型精确的错误信息让它自我修正。
Claude Code 的核心架构可以拆成五个模块,严格的层次调用关系:
入口 → 查询引擎 → 对话主循环 → 工具类型系统 → 工具注册中心
上层依赖下层,下层不感知上层。替换任何一层的实现,不影响其他层。

▲ 五大核心模块层次架构
① 入口点模块
三个职责:启动优化、CLI 解析、React/Ink 初始化。
启动优化值得单独说——性能探针最先执行,MDM 配置读取与 Keychain 预取并行展开,把原本串行的 I/O 操作叠在一起。传统做法每一步等上一步完成;Claude Code 让配置、密钥、UI 初始化同时进行。
工程原则很明确:启动路径是用户体验的第一印象。 打开等 3 秒和打开就能用,是两种完全不同的体验。用户不会因为”启动慢但功能强”而原谅你——他们会直接关掉。
② LLM 查询引擎(QueryEngine)
对话的”生命周期管理者”——管理消息历史、文件缓存、用量统计、权限记录。你可以把它想象成一个”数据库管理员”:所有跟对话状态相关的数据都由它统一管理。
关键设计:同时服务于 交互式 REPL 和 无头 SDK 两种运行模式。一个核心、多种入口,避免两套逻辑跑不同步。如果 REPL 和 SDK 各维护一套查询逻辑,bug 修复就要改两个地方,时间一长两套代码一定会跑偏。
③ 异步生成器对话主循环
整个系统最核心的模块。 一个 AsyncGenerator,每轮迭代依次执行:
构建请求 → 流式接收响应 → 解析工具调用 → 权限校验 → 执行工具 → 注入结果 → 判断是否继续
这个循环会一直运行,直到模型认为任务完成(不再调用工具)或用户手动终止。一次”帮我重构这个模块”的请求,可能在这个循环里转几十轮。
为什么用 AsyncGenerator?
–增量输出:通过 yield 实时接收中间状态,每一步即时推送给 UI
–可中断性:用户按 Ctrl+C 随时取消,不留半完成的操作
–背压控制:消费者处理不过来时,生成器自动暂停
为什么不用其他方案?回调 → 回调地狱;Promise 链 → 无法取消;EventEmitter → 内存泄漏风险。AsyncGenerator 是唯一同时满足”流式”+”可取消”+”类型安全”的方案。
跨迭代状态用不可变的 State 对象封装,整体替换而非逐字段修改。
④ 工具类型系统
定义所有工具必须遵循的类型契约。几个关键设计:
• 权限检查内嵌在工具执行流程中,不可绕过
•isConcurrencySafe 声明影响调度策略——安全的可以并行
•isDestructive 标记是权限系统的重要输入
•userFacingName 决定 UI 展示——用户看到的是”读取文件”而不是 ReadFileTool.execute()
这些约束通过 TypeScript 编译器强制执行——开发者物理上无法”忘记”实现某个方法。
⑤ 工具注册中心(getAllBaseTools)
工具系统的”单一事实来源”。三个设计亮点:
–条件注册:通过 Feature Flag 控制,内部版本和外部版本可以包含不同工具
–延迟加载:工具定义通过动态 import() 按需加载,避免循环依赖,也减少启动时间——你可能注册了 50 个工具,但这次对话只用到 3 个
–工具过滤:发送给 LLM 前过滤禁止的工具——模型甚至看不到它不应该使用的工具。这比”模型看到了但告诉它不能用”安全得多
这五个原则不是孤立的技巧,而是相互支撑的架构决策网络。
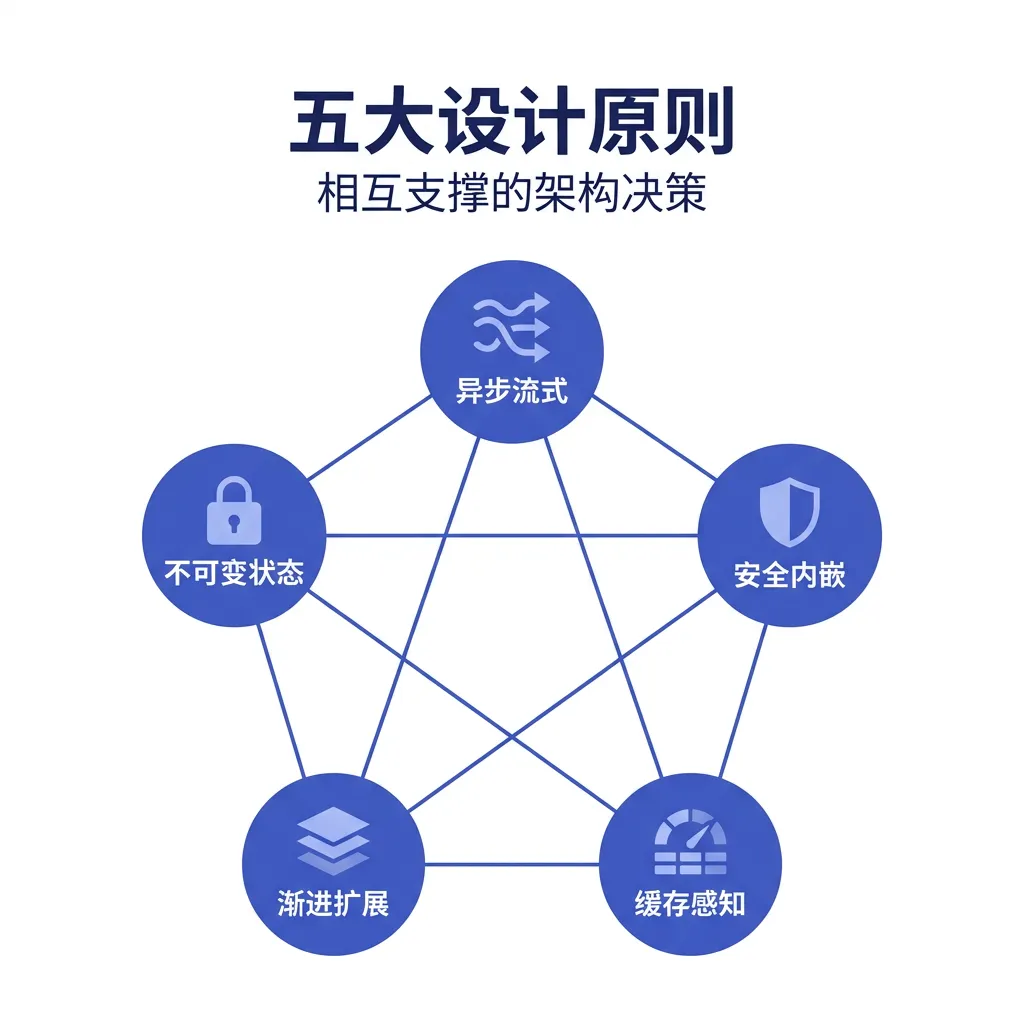
▲ 五大设计原则互联关系
原则一:异步流式优先
Agent 可能在单次请求中执行多轮工具调用,持续数分钟。如果用户在这段时间什么都看不到,体验非常糟糕。AsyncGenerator 的增量输出、可中断性和背压控制,完美匹配了这个需求。
原则二:安全边界内嵌
权限系统不是”加上去的安全层”,而是内嵌在核心管线中。很多系统的做法是:核心功能先做好,然后在外面”包一层”安全检查。问题是——这种”外挂式”安全很容易被绕过,或者在重构时不小心移除。Claude Code 的做法是:安全检查就是工具执行管线的组成部分。工具调用从 LLM 提出到执行,经过四个检查点:
1.可见性过滤:模型连看到都看不到禁止的工具
2.输入校验:参数格式不对直接拒绝
3.权限决策:综合权限模式、工具危险等级、用户历史做判断
4.运行时防护:沙箱限制、超时控制、输出大小限制
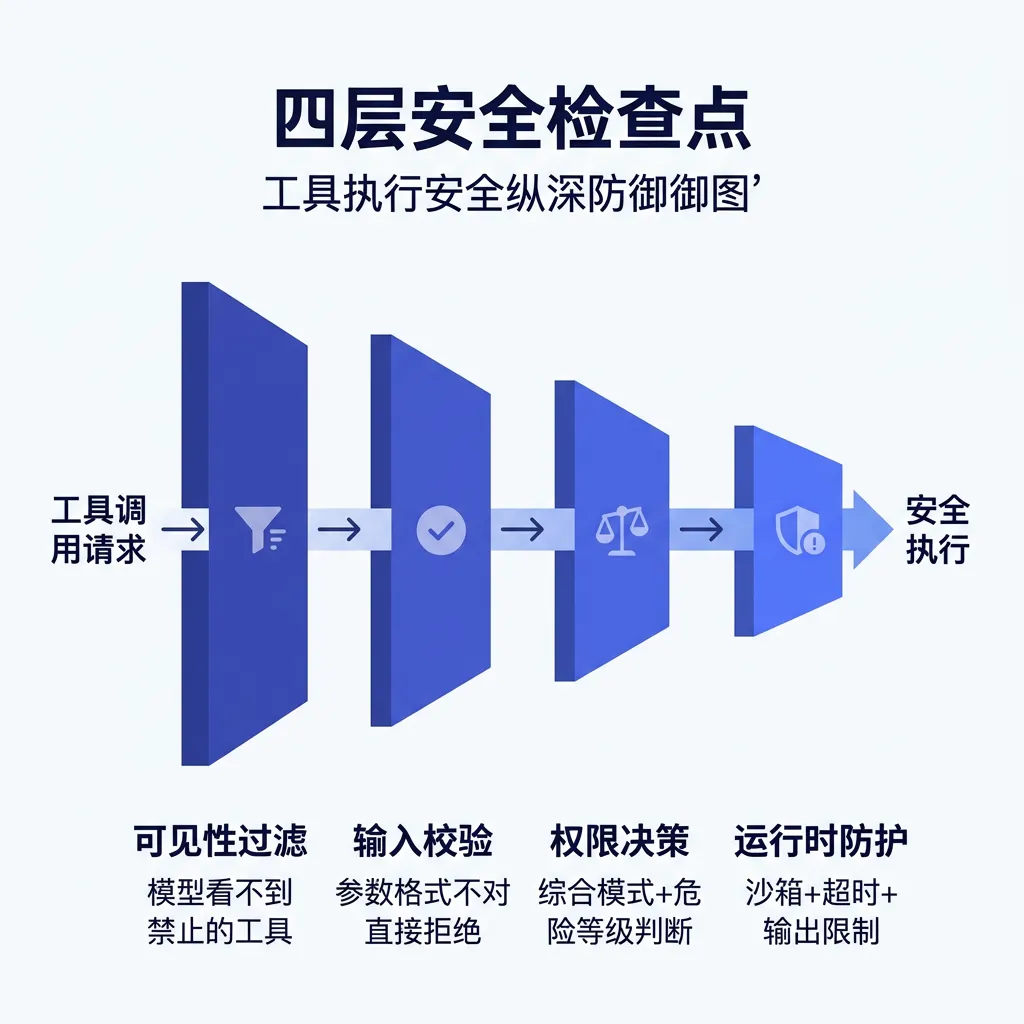
▲ 安全纵深防御四层检查点
这是纵深防御——每一层独立短路,即使某层被绕过,下一层仍然挡着。
为什么白名单不够?rm -rf node_modules 是安全操作,rm -rf /etc 是灾难。git push 在普通分支是安全的,git push --force origin main 是危险的。同一个命令,不同参数,风险等级完全不同——静态白名单无法做出这种精细判断。
原则三:缓存感知设计
Claude API 的 Prompt Caching 命中时,输入 Token 成本降低 90%,延迟降低约 80%。Claude Code 从三个层面保证缓存命中率:
–系统 Prompt 稳定性:构建方式保证字节内容一致
–子智能体缓存共享:Fork 模式继承父智能体的 Prompt
–消息历史不可变:只追加不修改,缓存键永远稳定
最容易踩坑的是系统 Prompt 稳定性。你的 Prompt 里包含”当前可用工具列表”,每次对话前动态生成。如果工具列表的排序不稳定(比如用了 Object.keys()),那么每次生成的 Prompt 字节内容都不一样——缓存永远命中不了。
微小的配置变化(如工具列表排序变了)导致的缓存失效,会迅速累积成可观的额外成本。
原则四:渐进式能力扩展
四级扩展模型,从内建到外部、从简单到复杂:
|
|
|
|
|
|---|---|---|---|
| 工具 |
|
|
|
| 技能 |
|
|
|
| 插件 |
|
|
|
| MCP 服务器 |
|
|
|
设计哲学是”渐进增强”:让每一类贡献者都能在最适合自己的抽象层次上工作。 两种极端都不可取——只有工具一级扩展,第三方必须修改核心代码;只提供 MCP 一级扩展,简单自定义需求也要搭建完整工具服务器。VS Code 有扩展 API、浏览器有 WebExtension、Kubernetes 有 Operator——都是同一个思路。
原则五:不可变状态流转
Agent 系统天然高并发:模型可能同时调用 3 个工具,流式输出在持续产生事件,用户可能随时交互。可变状态会导致经典竞态条件:工具 A 改到一半,工具 B 读到了不一致的数据。 在子智能体场景下更危险——子智能体可能意外修改父智能体的状态。这类 bug 极难复现,因为它取决于异步操作的具体调度顺序。
不可变状态的三个设计要素:
–Updater 函数:(prev) => next,确保基于前一状态计算,避免竞态
–引用相等性:只有真正变化才触发通知,避免无效重渲染
–订阅/取消:监听器返回清理函数,防止内存泄漏
不可变状态从架构层面消除了并发竞态问题。
1. 范式转移已经发生。 LLM 从”对话伙伴”变成”自主智能体”,核心驱动力是工具调用的标准化。简单 API 封装应对不了生产级挑战。
2. 工程复杂度不会因模型更强而消失。 51 万行代码告诉你:流式输出、权限管控、上下文管理、错误恢复、状态持久化——每一个都是独立的系统工程挑战。随着 Agent 执行更复杂的任务,这些挑战会愈发尖锐。
3. 五个模块定义架构骨架。 入口 → 查询引擎 → 对话主循环 → 工具类型 → 工具注册——这是整个系统的基本拓扑。
4. 五大原则贯穿全局。 异步流式优先、安全边界内嵌、缓存感知设计、渐进式能力扩展、不可变状态流转——几乎所有设计决策都能追溯到这五个原则。
步骤一:安装 Claude Code
确保系统已安装 Node.js 18+ 或 Bun:
BASH
npm install -g @anthropic-ai/claude-code claude --version
步骤二:运行 /doctor 诊断
BASH
cd your-project claude > /doctor
/doctor 会执行一系列系统自检,包括:
1.环境检查:Node.js 版本、Bun 可用性、Git 安装状态
2.权限配置检查:当前权限模式、工具白名单/黑名单状态
3.MCP 服务器连接状态:已配置的 MCP 服务器是否正常响应
4.API 连接性检查:与 Anthropic API 的连接是否正常
5.文件系统访问检查:工作目录的读写权限
每一项检查背后都对应着前面讲的某个模块。
步骤三:观察流式输出
注意 /doctor 的输出方式——每完成一项检查就即时显示,不等全部跑完。这正是”异步流式优先”原则的日常体现。
步骤四:观察一次完整的工具调用
发送一个简单请求:”列出当前目录下的所有 TypeScript 文件”。观察三个阶段:
1.思考 → 展示打算用哪个工具
2.工具调用 → 显示 GlobTool("*.ts") 和结果
3.回复 → 基于结果给出最终回答
这个简单交互的背后,第一章讲的五个模块全部参与了。
AI应用实录|用大白话拆解 AI 应用,让普通人也能上手。