 夜雨聆风
夜雨聆风





ggml 源码剖析(tensor)
前序
明日复明日,明日何其多。
我生待明日,万事成蹉跎。
世人若被明日累,春去秋来老将至。
朝看水东流,暮看日西坠。
百年明日能几何?请君听我明日歌。
总是有很多事想做,且总找理由拖延,光阴虚度,一事无成…
这几年 AI 发展迅猛,之前都是在讲一些关于 Vibe Coding 相关应用层面的东西。都在恐慌程序员将被 AI 编程所取代,而对我来说,则是有了更多的学习内容。
我更关注的是相对 AI 的底层原理,机器学习、深度学习、数学算法,这些基建的内容。
过年整理书籍,收拾出一堆技术过时的书籍,反而那些数学相关的书籍还很保值。无奈本人数学中庸,但多少还能比划比划。
自认为有些 3D 数学基础的底子,勇闯一下 AI 领域,结果啪啪打脸,结果重温线性代数、恶补微积分、概率论…
本想直接脚踢 AI 数学、手撕深度学习、生吞大模型。但是感觉过度的有些突兀,而 ggml 项目是一个学习 AI 很好的下手点,因此决定先从《 ggml 源码剖析》开始,先了解,后编写。
GGML 简介
GGML 是一个专注于机器学习的张量库,它的核心目标是让大型语言模型(LLM)能够在普通的消费级硬件(如个人电脑、树莓派)上高效运行。
著名开源项目 llama.cpp 的创建者 Georgi Gerganov 开发,名字中的 “GG” 正是他名字的首字母缩写,当然 “ML” 便是指机器学习啦~
GGML 为 llama.cpp 等项目提供强大的底层支持,这也是先学 GGML 的原因。
个人学习 GGML 主要得益于以下几个关键技术特性:
-
• 支持 16bit 浮点数、支持整数量化 (比如4-bit, 5-bit, 8-bit) -
• CPU 优化:针对 Apple Silicon(M系列芯片)和 x86 架构(利用 AVX / AVX2 指令集)优化 GPU 优化:通过 Vulkan、CUDA等后端利用GPU加速计算
-
• 可以自动微分,内置优化算法 (例如 ADAM, L-BFGS 等) -
• 纯 C / C++ 编写,无三方依赖库,而且运行时零内存分配
源码剖析
物以类聚
概念
ggml 包含了一系列的计算图构建、张量的算子操作、自动微分、以及基础的优化算法。
-
1. 计算图(Computation Graph):计算图,也称为计算图或数据流图,是数学操作的表示,其中节点代表操作(例如加法、乘法)或函数,边代表这些操作之间的数据流动(张量或变量)。计算图用于定义和可视化复杂数学函数中的数据和操作流动。 -
2. 张量操作(Tensor Operations):张量操作是对张量执行的数学操作。张量是多维数组,可以表示各种类型的数据,如标量、向量、矩阵或更高维数组。张量操作可以包括加法、乘法、卷积和其他在机器学习和数值计算中常用的操作。 -
3. 函数定义(Function Definition):在你描述的上下文中,函数是使用计算图中的一系列张量操作来定义的。该函数表示一个数学模型,将输入数据(张量)映射到输出,并且可能会相当复杂,特别是在深度学习模型中。 -
4. 梯度(Gradient):计算函数相对于其输入变量的梯度对于优化和训练机器学习模型至关重要。梯度提供了关于函数的输出如何随其输入变化而变化的信息。它在优化算法(如梯度下降)中使用,以迭代方式更新模型参数并最小化损失函数。 -
5. 优化算法(Optimization Algorithms):优化算法用于调整函数的参数(例如神经网络权重),以最小化或最大化某个特定目标(例如最小化损失函数)。常见的优化算法包括梯度下降、Adam、RMSprop等。这些算法使用梯度信息以迭代方式更新参数,直到收敛。 -
6. 前向计算(Forward Computation):前向计算函数接受输入张量的值,并根据定义的张量操作计算输出张量的值。这是对输入执行一系列操作以获得输出的过程,通常是模型的正向传播。 -
7. 反向计算、反向传播(Backward Computation):反向计算函数接受输出张量的伴随值(也称为梯度)并计算输入张量的伴随值。这是为了计算函数相对于输入的梯度,通常是为了在优化过程中更新模型参数(例如使用反向传播算法) -
8. 行优先储存(Row-Major Order):行优先是一种多维数组元素存储方式,其中数组的元素按照行的顺序存储在内存中。这意味着每一行的元素都相邻存储,而不同行之间的元素可能不相邻。
GGML将数学函数定义为计算图,在这些图中执行张量操作,计算函数值,计算梯度,并使用各种优化算法优化函数。这种库在机器学习和科学计算中非常基础,用于构建和训练模型。
阅读源码,总结按照宏、枚举、结构体分类。
宏
|
|
|
|---|---|
|
|
0x67676d6c(”ggml”) |
|
|
2 |
|
|
2 |
|
|
1000 |
|
|
4 |
|
|
2048 |
|
|
10 |
|
|
64 |
|
|
512 |
|
|
64 |
|
|
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
枚举
|
|
|
|---|---|
|
|
GGML_TYPE_F32, GGML_TYPE_F16 |
|
|
|
|
|
GGML_OP_ARGMAX |
|
|
GGML_UNARY_OP_ABS |
|
|
|
|
|
ggml_object_type, GGML_OBJECT_GRAPH, GGML_OBJECT_WORK_BUFFER |
|
|
|
|
|
|
结构体
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
GGUF
GGUF(GPT-Generated-Unified-Format) 是一种文件格式,用于存储使用 GGML 进行推理的模型以及基于 GGML 的执行器。
GGUF 是一种二进制格式,旨在快速加载和保存模型,并且易于读取。
模型传统上是使用 PyTorch 或其他框架开发的,然后转换为 GGUF 以用于 GGML。
格式
GGUF 遵循 <基础名称>< 尺寸标签 >< 微调 >< 版本 >< 编码 >< 类型 >< 分片 >.gguf 的命名约定,其中每个组件如有存在则以 – 分隔。最终目标是让人们能够一目了然地获取模型最重要的细节。由于现有 gguf 文件名的多样性,它并非旨在完全适用于字段解析。
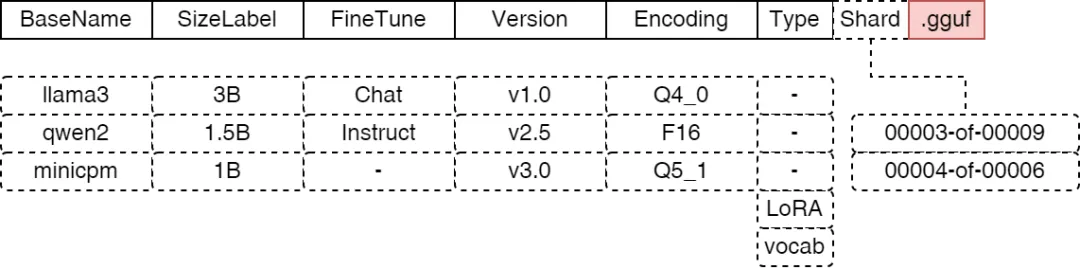
<基础名称><参数量><微调状态><版本号><编码><类型><分片>.gguf
其中,每个字段由 - 连接,下面这个表格可以帮你快速理解每个部分的含义:
|
|
|
|
|---|---|---|
| 基础名称 |
|
Llama-3
DeepSeek-R1、Distill-Qwen |
| 参数量 |
<数量><量级前缀>,常用量级有 B(十亿,Billion)和 M(百万,Million)。如果是MoE模型,还会包含专家数,如 8x7B。 |
7B
0.5B、8x7B |
| 微调状态 |
Instruct、Chat。 |
Instruct
Chat、Base(基础版) |
| 版本号 |
v + 主版本号.次版本号。 |
v1.0
v2.1 |
| 编码 |
|
Q4_K_M
F16、Q8_0 |
| 类型 |
|
LoRA
vocab(词表文件) |
| 分片 |
<编号>-of-<总数>。 |
00001-of-00003 |
提到量化,这里多说几句,量化分为:
-
• 训练后量化(Post – Training Quantization) 用一个已经训练好的原始模型(通常是FP32或BF16精度),给它喂一小部分数据,观察一下数据的分布范围,然后直接把它高精度的权重转换成低精度整数。
这是让模型变小的最直接、最常用的方法,尤其是在GGUF这样的格式中。
-
• 量化感知训练(Quantization – Aware Training) 在训练的前向和反向传播中,模拟量化带来的误差。模型在更新权重时,会考虑到未来要被量化这件事,从而调整参数,使得最终量化后的损失降到最低
-
• 混合精度量化(Mixed – Precision Quantization) 在同一个模型中,一部分权重和计算使用较低的精度(如4-bit),另一部分关键部分使用较高的精度(如8-bit或16-bit)。
例如,Transformer 模型中的 Attention 层通常比 FFN 层对精度更敏感,因此可以给 Attention 层分配更高的精度。
|
|
|
|
|
|
|---|---|---|---|---|
| 训练后量化 | 事后压缩 |
|
快速、通用
|
GGUF模型最常见的生产方式 |
| 量化感知训练 | 事前排练 |
|
精度高
|
|
| 混合精度量化 | 区别对待 |
|
平衡性好
|
|
下面是量化对照表,供参考:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
源码
这里先看图,再对照代码,看一下 gguf 文件的内部数据结构:

gguf 文件中各字节代表的含义如上图所示,它们使用在 general.alignment 元数据字段中指定的全局对齐方式,在需要时,gguf 文件会以 0x00 字节填充到 general.alignment 的下一个倍数。
除非另有说明,否则字段(包括数组)都是按顺序写入的,不会对齐。
gguf.cpp
// 用于存储从 GGUF 文件读取的张量信息的结构体,包括一个 ggml_tensor 结构体和一个偏移量,偏移量表示张量数据在数据缓冲区中的位置。
struct gguf_tensor_info {
struct ggml_tensor t; // for holding the equivalent info // ggml_tensor 结构体,用于存储张量的维度、数据类型等信息
// 偏移量,表示张量数据在数据缓冲区中的位置,必须是对齐的
uint64_t offset; // offset from start of `data`, must be a multiple of `ALIGNMENT`
};
// 用于存储从 GGUF 文件读取的所有信息的主上下文结构体,包括键值对、张量信息以及张量的原始数据缓冲区。
struct gguf_context {
uint32_t version = GGUF_VERSION; // GGUF 文件的版本号,默认为当前支持的版本 GGUF_VERSION
std::vector<struct gguf_kv> kv; // 存储从 GGUF 文件读取的键值对,每个键值对包含一个字符串键和一个对应的值(可以是基本类型或字符串)
std::vector<struct gguf_tensor_info> info; // 存储从 GGUF 文件读取的张量信息,每个张量信息包含一个 ggml_tensor 结构体和一个偏移量
size_t alignment = GGUF_DEFAULT_ALIGNMENT; // 数据对齐方式,默认为 GGUF_DEFAULT_ALIGNMENT
size_t offset = 0; // offset of `data` from beginning of file // 数据部分相对于文件开头的偏移量,单位为字节
size_t size = 0; // size of `data` in bytes // 数据部分的大小,单位为字节
void* data = nullptr; // 指向存储张量原始数据的缓冲区的指针,数据从 GGUF 文件中读取后存储在这里
};
// gguf 键值对
struct gguf_kv {
std::string key; // 键,表示 GGUF 文件中 KV 对应的键,是一个字符串
bool is_array; // 表示值是否是一个数组,如果为 true,则值是一个数组;如果为 false,则值是一个单一的基本类型或字符串
enum gguf_type type; // 值的数据类型,表示 GGUF 文件中 KV 对应的值的数据类型,是一个 gguf_type 枚举值
// 数据缓冲区,用于存储 GGUF 文件中 KV 对应的值的数据,如果值是一个基本类型,则数据缓冲区存储该基本类型的二进制表示;
// 如果值是一个数组,则数据缓冲区存储数组中所有元素的二进制表示,元素之间没有间隔
std::vector<int8_t> data;
// 字符串数据缓冲区,用于存储 GGUF 文件中 KV 对应的值是字符串时的数据,如果值是一个字符串数组,则数据缓冲区存储数组中所有字符串
std::vector<std::string> data_string;
...
};gguf.h
// types that can be stored as GGUF KV data
enum gguf_type { // GGUF 文件中 KV 对应的值的数据类型枚举,表示 GGUF 文件中 KV 对应的值的数据类型
GGUF_TYPE_UINT8 = 0, // 无符号 8 位整数类型
GGUF_TYPE_INT8 = 1, // 有符号 8 位整数类型
GGUF_TYPE_UINT16 = 2, // 无符号 16 位整数类型
GGUF_TYPE_INT16 = 3, // 有符号 16 位整数类型
GGUF_TYPE_UINT32 = 4, // 无符号 32 位整数类型
GGUF_TYPE_INT32 = 5, // 有符号 32 位整数类型
GGUF_TYPE_FLOAT32 = 6, // 32 位单精度浮点数类型
GGUF_TYPE_BOOL = 7, // 布尔类型
GGUF_TYPE_STRING = 8, // 字符串类型
GGUF_TYPE_ARRAY = 9, // 数组类型
GGUF_TYPE_UINT64 = 10, // 无符号 64 位整数类型
GGUF_TYPE_INT64 = 11, // 有符号 64 位整数类型
GGUF_TYPE_FLOAT64 = 12, // 64 位双精度浮点数类型
GGUF_TYPE_COUNT, // marks the end of the enum // 枚举的结束标志,表示 GGUF 文件中 KV 对应的值的数据类型枚举的数量
};
// gguf 初始化参数结构体定义了在初始化 GGUF 上下文时可以使用的参数选项,包括是否分配张量数据以及是否创建 ggml_context。
struct gguf_init_params {
// 如果为 true,则不分配张量数据,用户需要自己分配并提供一个指向它的指针(通过 mem_buffer),并且在每个张量信息中正确设置数据偏移(offset)以指向对应的数据
bool no_alloc;
// if not NULL, create a ggml_context and allocate the tensor data in it
struct ggml_context** ctx; // 如果不为 NULL,则创建一个 ggml_context 并在其中分配张量数据
};gguf.cpp 中较为重要的函数 gguf_init_from_file_impl(),讲述了读取 gguf 文件的整个过程:
...
// 从给定的文件中读取 GGUF 数据并初始化 gguf_context 结构体,返回指向该结构体的指针。如果读取过程中发生错误,则返回 nullptr。
struct gguf_context * gguf_init_from_file_impl(FILE * file, struct gguf_init_params params) {
const struct gguf_reader gr(file); // 创建一个 gguf_reader 对象 gr,用于从给定的文件中读取数据
struct gguf_context* ctx = new gguf_context; // 创建一个 gguf_context 对象 ctx,用于存储从 GGUF 文件中读取的所有信息
bool ok = true;
// file magic
{
// 读取 “gguf” 文件魔术字符串,验证文件格式是否正确
std::vector<char> magic;
ok = ok && gr.read(magic, 4);
if (!ok) {
GGML_LOG_ERROR("%s: failed to read magic\n", __func__);
gguf_free(ctx);
return nullptr;
}
// 验证读取的魔术字符串是否与预期的 GGUF_MAGIC 匹配,如果不匹配,则记录错误日志并返回 nullptr
for (uint32_t i = 0; i < magic.size(); i++) {
if (magic[i] != GGUF_MAGIC[i]) {
char c0 = isprint(magic[0]) ? magic[0] : '?';
char c1 = isprint(magic[1]) ? magic[1] : '?';
char c2 = isprint(magic[2]) ? magic[2] : '?';
char c3 = isprint(magic[3]) ? magic[3] : '?';
GGML_LOG_ERROR("%s: invalid magic characters: '%c%c%c%c', expected 'GGUF'\n", __func__, c0, c1, c2, c3);
gguf_free(ctx);
return nullptr;
}
}
}
// header
int64_t n_kv = 0; // 声明一个 int64_t 类型的变量 n_kv,用于存储 GGUF 文件中 KV 对应的键值对的数量,初始值为 0
int64_t n_tensors = 0; // 声明一个 int64_t 类型的变量 n_tensors,用于存储 GGUF 文件中张量的数量,初始值为 0
// 读取 GGUF 文件的版本号,并进行一系列验证检查,确保版本号的有效性和兼容性。如果版本号无效或不兼容,则记录错误日志并返回 nullptr
if (ok && gr.read(ctx->version)) {
if (ok && ctx->version == 0) {
GGML_LOG_ERROR("%s: bad GGUF version: %" PRIu32 "\n", __func__, ctx->version);
ok = false;
}
/*
* bit layout is different when reading non-native endian models.
* assuming that the GGUF version is 3, the non-native endian model
* would read it as 0x30000000. we can use the AND operation against
* the last 4 hexadecimal digits to check if the model is the same
* endianness as the host system.
*/
if (ok && (ctx->version & 0x0000FFFF) == 0x00000000) {
GGML_LOG_ERROR("%s: failed to load model: this GGUF file version %" PRIu32 " is extremely large, is there a mismatch between the host and model endianness?\n", __func__, ctx->version);
ok = false;
}
if (ok && ctx->version == 1) {
GGML_LOG_ERROR("%s: GGUFv1 is no longer supported, please use a more up-to-date version\n", __func__);
ok = false;
}
if (ok && ctx->version > GGUF_VERSION) {
GGML_LOG_ERROR("%s: this GGUF file is version %" PRIu32 " but this software only supports up to version %d\n",
__func__, ctx->version, GGUF_VERSION);
ok = false;
}
} else {
ok = false;
}
// 读取 GGUF 文件中 KV 对应的键值对的数量和张量的数量,并进行验证检查,确保它们的值在合理范围内。如果数量无效,则记录错误日志并返回 nullptr
if (ok && gr.read(n_tensors)) {
static_assert(sizeof(size_t) <= 8 && sizeof(gguf_tensor_info) >= 2, "int64_t insufficient for indexing");
if (n_tensors < 0 || n_tensors > int64_t(SIZE_MAX/sizeof(gguf_tensor_info))) {
GGML_LOG_ERROR("%s: number of tensors is %" PRIi64 " but must be in [0, %zu]\n",
__func__, n_tensors, SIZE_MAX/sizeof(gguf_tensor_info));
ok = false;
}
} else {
ok = false;
}
// 读取 GGUF 文件中 KV 对应的键值对的数量,并进行验证检查,确保它的值在合理范围内。如果数量无效,则记录错误日志并返回 nullptr
if (ok && gr.read(n_kv)) {
static_assert(sizeof(size_t) <= 8 && sizeof(gguf_tensor_info) >= 2, "int64_t insufficient for indexing");
if (n_kv < 0 || n_kv > int64_t(SIZE_MAX/sizeof(gguf_kv))) {
GGML_LOG_ERROR("%s: number of key value pairs is %" PRIi64 " but must be in [0, %zu]\n",
__func__, n_kv, SIZE_MAX/sizeof(gguf_kv));
ok = false;
}
} else {
ok = false;
}
if (!ok) {
GGML_LOG_ERROR("%s: failed to read header\n", __func__);
gguf_free(ctx);
return nullptr;
}
// KV pairs 键值对
{
// 循环读取 GGUF 文件中 KV 对应的键值对的数量 n_kv,每次迭代读取一个键值对的信息,包括键、值的数据类型、是否是数组以及数组的元素数量等,并将其存储在 gguf_context 结构体的 kv 成员中。
// 如果在读取过程中发生错误,例如读取键或值时遇到长度错误或内存分配错误,或者遇到重复的键,或者键的数据类型无效,则记录错误日志并返回 nullptr
for (int64_t i = 0; ok && i < n_kv; ++i) {
std::string key;
gguf_type type = gguf_type(-1);
bool is_array = false;
uint64_t n = 1;
try {
ok = ok && gr.read(key);
} catch (std::length_error &) {
GGML_LOG_ERROR("%s: encountered length_error while reading key %" PRIi64 "\n", __func__, i);
ok = false;
} catch (std::bad_alloc &) {
GGML_LOG_ERROR("%s: encountered bad_alloc error while reading key %" PRIi64 "\n", __func__, i);
ok = false;
}
for (size_t j = 0; ok && j < ctx->kv.size(); ++j) {
if (key == ctx->kv[j].key) {
GGML_LOG_ERROR("%s: duplicate key '%s' for tensors %zu and %" PRIi64 " \n", __func__, key.c_str(), j, i);
ok = false;
}
}
if (!ok) {
break;
}
ok = ok && gr.read(type);
if (type == GGUF_TYPE_ARRAY) {
is_array = true;
ok = ok && gr.read(type);
ok = ok && gr.read(n);
}
if (!ok) {
break;
}
// 根据读取的键值对的信息,调用 gguf_read_emplace_helper 函数将键值对存储在 gguf_context 结构体的 kv 成员中。
// 根据值的数据类型,选择相应的模板实例化来处理不同类型的值。如果遇到无效的数据类型,则记录错误日志并返回 nullptr
switch (type) {
case GGUF_TYPE_UINT8: ok = ok && gguf_read_emplace_helper<uint8_t> (gr, ctx->kv, key, is_array, n); break;
case GGUF_TYPE_INT8: ok = ok && gguf_read_emplace_helper<int8_t> (gr, ctx->kv, key, is_array, n); break;
case GGUF_TYPE_UINT16: ok = ok && gguf_read_emplace_helper<uint16_t> (gr, ctx->kv, key, is_array, n); break;
case GGUF_TYPE_INT16: ok = ok && gguf_read_emplace_helper<int16_t> (gr, ctx->kv, key, is_array, n); break;
case GGUF_TYPE_UINT32: ok = ok && gguf_read_emplace_helper<uint32_t> (gr, ctx->kv, key, is_array, n); break;
case GGUF_TYPE_INT32: ok = ok && gguf_read_emplace_helper<int32_t> (gr, ctx->kv, key, is_array, n); break;
case GGUF_TYPE_FLOAT32: ok = ok && gguf_read_emplace_helper<float> (gr, ctx->kv, key, is_array, n); break;
case GGUF_TYPE_BOOL: ok = ok && gguf_read_emplace_helper<bool> (gr, ctx->kv, key, is_array, n); break;
case GGUF_TYPE_STRING: ok = ok && gguf_read_emplace_helper<std::string>(gr, ctx->kv, key, is_array, n); break;
case GGUF_TYPE_UINT64: ok = ok && gguf_read_emplace_helper<uint64_t> (gr, ctx->kv, key, is_array, n); break;
case GGUF_TYPE_INT64: ok = ok && gguf_read_emplace_helper<int64_t> (gr, ctx->kv, key, is_array, n); break;
case GGUF_TYPE_FLOAT64: ok = ok && gguf_read_emplace_helper<double> (gr, ctx->kv, key, is_array, n); break;
case GGUF_TYPE_ARRAY:
default:
{
GGML_LOG_ERROR("%s: key '%s' has invalid GGUF type %d\n", __func__, key.c_str(), type);
ok = false;
} break;
}
}
if (!ok) {
GGML_LOG_ERROR("%s: failed to read key-value pairs\n", __func__);
gguf_free(ctx);
return nullptr;
}
GGML_ASSERT(int64_t(ctx->kv.size()) == n_kv);
// 读取 GGUF 文件中一个特殊的键 GGUF_KEY_GENERAL_ALIGNMENT 的值,用于设置数据对齐方式。
// 如果该键存在,则将其值存储在 gguf_context 结构体的 alignment 成员中;如果该键不存在,则使用默认的对齐方式 GGUF_DEFAULT_ALIGNMENT。然后验证对齐方式是否为 0 或者不是 2 的幂,如果是,则记录错误日志并返回 nullptr
const int alignment_idx = gguf_find_key(ctx, GGUF_KEY_GENERAL_ALIGNMENT);
ctx->alignment = alignment_idx == -1 ? GGUF_DEFAULT_ALIGNMENT : gguf_get_val_u32(ctx, alignment_idx);
if (ctx->alignment == 0 || (ctx->alignment & (ctx->alignment - 1)) != 0) {
GGML_LOG_ERROR("%s: alignment %zu is not a power of 2\n", __func__, ctx->alignment);
gguf_free(ctx);
return nullptr;
}
}
// read the tensor info
// 读取 GGUF 文件中张量的信息,包括张量的名称、形状、数据类型以及数据在文件中的偏移量等,并将这些信息存储在 gguf_context 结构体的 info 成员中。
// 如果在读取过程中发生错误,例如读取张量名称时遇到长度错误或内存分配错误,或者张量名称过长,或者存在重复的张量名称,或者张量的维度数量无效,或者张量的数据类型无效,或者张量的行大小不符合要求,或者张量的元素总数超过了 int64_t 的表示范围,则记录错误日志并返回 nullptr
for (int64_t i = 0; ok && i < n_tensors; ++i) {
struct gguf_tensor_info info;
// tensor name 张量名称
{
std::string name;
try {
ok = ok && gr.read(name);
} catch (std::length_error &) {
GGML_LOG_ERROR("%s: encountered length_error while reading tensor name %" PRIi64 "\n", __func__, i);
ok = false;
} catch (std::bad_alloc &) {
GGML_LOG_ERROR("%s: encountered bad_alloc error while reading tensor name %" PRIi64 "\n", __func__, i);
ok = false;
}
if (name.length() >= GGML_MAX_NAME) {
GGML_LOG_ERROR("%s: tensor name %" PRIi64 " is too long: %zu >= %d\n", __func__, i, name.length(), GGML_MAX_NAME);
ok = false;
break;
}
ggml_set_name(&info.t, name.c_str());
// make sure there are no duplicate tensor names
for (int64_t j = 0; ok && j < i; ++j) {
if (strcmp(info.t.name, ctx->info[j].t.name) == 0) {
GGML_LOG_ERROR("%s: duplicate tensor name '%s' for tensors %" PRIi64 " and %" PRIi64 "\n", __func__, info.t.name, j, i);
ok = false;
break;
}
}
}
if (!ok) {
break;
}
// tensor shape 张量形状
{
uint32_t n_dims = -1;
ok = ok && gr.read(n_dims);
if (n_dims > GGML_MAX_DIMS) {
GGML_LOG_ERROR("%s: tensor '%s' has invalid number of dimensions: %" PRIu32 " > %" PRIu32 "\n",
__func__, info.t.name, n_dims, GGML_MAX_DIMS);
ok = false;
break;
}
for (uint32_t j = 0; ok && j < GGML_MAX_DIMS; ++j) {
info.t.ne[j] = 1;
if (j < n_dims) {
ok = ok && gr.read(info.t.ne[j]);
}
// check that all ne are non-negative
if (info.t.ne[j] < 0) {
GGML_LOG_ERROR("%s: tensor '%s' dimension %" PRIu32 " has invalid number of elements: %" PRIi64 " < 0\n",
__func__, info.t.name, j, info.t.ne[j]);
ok = false;
break;
}
}
// check that the total number of elements is representable
// 校验张量的元素总数是否在 int64_t 的表示范围内,避免出现溢出。
// 如果元素总数超过了 int64_t 的最大值,则记录错误日志并返回 nullptr
if (ok && ((INT64_MAX/info.t.ne[1] <= info.t.ne[0]) ||
(INT64_MAX/info.t.ne[2] <= info.t.ne[0]*info.t.ne[1]) ||
(INT64_MAX/info.t.ne[3] <= info.t.ne[0]*info.t.ne[1]*info.t.ne[2]))) {
GGML_LOG_ERROR("%s: total number of elements in tensor '%s' with shape "
"(%" PRIi64 ", %" PRIi64 ", %" PRIi64 ", %" PRIi64 ") is >= %" PRIi64 "\n",
__func__, info.t.name, info.t.ne[0], info.t.ne[1], info.t.ne[2], info.t.ne[3], INT64_MAX);
ok = false;
break;
}
}
if (!ok) {
break;
}
// tensor type 张量数据类型
{
ok = ok && gr.read(info.t.type);
// check that tensor type is within defined range
// 验证张量的数据类型是否在定义的范围内,如果数据类型无效,则记录错误日志并返回 nullptr
if (info.t.type < 0 || info.t.type >= GGML_TYPE_COUNT) {
GGML_LOG_ERROR("%s: tensor '%s' has invalid ggml type %d (%s)\n",
__func__, info.t.name, info.t.type, ggml_type_name(info.t.type));
ok = false;
break;
}
const size_t type_size = ggml_type_size(info.t.type);
const int64_t blck_size = ggml_blck_size(info.t.type);
// check that row size is divisible by block size
// 验证张量的行大小是否是块大小的倍数,如果不是,则记录错误日志并返回 nullptr
if (blck_size == 0 || info.t.ne[0] % blck_size != 0) {
GGML_LOG_ERROR("%s: tensor '%s' of type %d (%s) has %" PRId64 " elements per row, "
"not a multiple of block size (%" PRId64 ")\n",
__func__, info.t.name, (int) info.t.type, ggml_type_name(info.t.type), info.t.ne[0], blck_size);
ok = false;
break;
}
// calculate byte offsets given the tensor shape and type
// 根据张量的形状和数据类型计算字节偏移量,并将其存储在 gguf_tensor_info 结构体的 nb 成员中。
// nb[0] 表示每个元素的字节大小,nb[1] 表示每行的字节大小,nb[2] 和 nb[3] 分别表示每个维度的字节大小。
// 如果在计算过程中发生错误,例如块大小为 0,或者行大小不是块大小的倍数,则记录错误日志并返回 nullptr
info.t.nb[0] = type_size;
info.t.nb[1] = info.t.nb[0]*(info.t.ne[0]/blck_size);
for (int j = 2; j < GGML_MAX_DIMS; ++j) {
info.t.nb[j] = info.t.nb[j - 1]*info.t.ne[j - 1];
}
}
if (!ok) {
break;
}
// tensor data offset within buffer
// 张量数据在数据缓冲区中的偏移量,表示张量数据在 GGUF 文件中的位置。
// 读取该偏移量并存储在 gguf_tensor_info 结构体的 offset 成员中。
// 如果在读取过程中发生错误,例如读取偏移量时遇到问题,或者偏移量不是对齐的,则记录错误日志并返回 nullptr
ok = ok && gr.read(info.offset);
ctx->info.push_back(info);
}
if (!ok) {
GGML_LOG_ERROR("%s: failed to read tensor info\n", __func__);
gguf_free(ctx);
return nullptr;
}
GGML_ASSERT(int64_t(ctx->info.size()) == n_tensors);
// we require the data section to be aligned, so take into account any padding
// 计算数据部分的对齐方式,并根据对齐方式调整文件指针的位置,以确保数据部分的开始位置是对齐的。
// 如果在调整文件指针位置时发生错误,例如无法寻找到正确的位置,则记录错误日志并返回 nullptr
if (fseek(file, GGML_PAD(ftell(file), ctx->alignment), SEEK_SET) != 0) {
GGML_LOG_ERROR("%s: failed to seek to beginning of data section\n", __func__);
gguf_free(ctx);
return nullptr;
}
// store the current file offset - this is where the data section starts
ctx->offset = ftell(file);
// compute the total size of the data section, taking into account the alignment
// 计算数据部分的总大小,考虑到对齐方式。
// 对于每个张量,根据其形状和数据类型计算所需的字节数,并根据对齐方式进行调整,以确保每个张量的数据在数据缓冲区中是对齐的。
{
ctx->size = 0;
for (size_t i = 0; i < ctx->info.size(); ++i) {
const gguf_tensor_info & ti = ctx->info[i];
if (ti.offset != ctx->size) {
GGML_LOG_ERROR("%s: tensor '%s' has offset %" PRIu64 ", expected %zu\n",
__func__, ti.t.name, ti.offset, ctx->size);
GGML_LOG_ERROR("%s: failed to read tensor data\n", __func__);
gguf_free(ctx);
return nullptr;
}
size_t padded_size = GGML_PAD(ggml_nbytes(&ti.t), ctx->alignment);
if (SIZE_MAX - ctx->size < padded_size) {
GGML_LOG_ERROR("%s: tensor '%s' size overflow, cannot accumulate size %zu + %zu\n",
__func__, ti.t.name, ctx->size, padded_size);
gguf_free(ctx);
return nullptr;
}
ctx->size += padded_size;
}
}
// load the tensor data only if requested
// 根据参数 params 中的 ctx 成员是否为 nullptr 来决定是否加载张量数据。
if (params.ctx != nullptr) {
// if the provided gguf_context is no_alloc, then we create "empty" tensors and do not read the binary blob
// otherwise, we load the binary blob into the created ggml_context as well, and point the "data" members of
// the ggml_tensor structs to the appropriate locations in the binary blob
// compute the exact size needed for the new ggml_context
// 计算创建新的 ggml_context 所需的确切大小。根据参数 params 中的 no_alloc 成员来决定是否需要为张量数据分配内存。
const size_t mem_size =
params.no_alloc ?
(n_tensors )*ggml_tensor_overhead() :
(n_tensors + 1)*ggml_tensor_overhead() + ctx->size;
// 初始化 ggml_context,用于存储张量信息和数据。
// 如果 params 中的 no_alloc 成员为 true,则创建 "empty" 张量,不分配内存;否则,加载张量数据到创建的 ggml_context 中,并将 ggml_tensor 结构体的 "data" 成员指向二进制数据缓冲区中的适当位置。
struct ggml_init_params pdata = {
/*mem_size =*/ mem_size,
/*mem_buffer =*/ nullptr,
/*no_alloc =*/ params.no_alloc,
};
*params.ctx = ggml_init(pdata); // 调用 ggml_init 函数初始化 ggml_context,并将其指针存储在 params.ctx 中,以便后续使用
if (*params.ctx == nullptr) {
GGML_LOG_ERROR("%s: failed to initialize ggml context for storing tensors\n", __func__);
gguf_free(ctx);
return nullptr;
}
// 如果 params 中的 no_alloc 成员为 false,则创建一个新的 ggml_tensor 结构体 data,用于存储张量数据的二进制 blob,并将其指针存储在 ggml_context 中。然后从 GGUF 文件中读取张量数据的二进制 blob,并将其存储在 data 中。
// 如果在读取过程中发生错误,例如无法分配内存或者无法读取数据,则记录错误日志并返回 nullptr
struct ggml_context * ctx_data = *params.ctx;
// 张量数据的二进制 blob,存储从 GGUF 文件中读取的张量数据。
// 如果 params 中的 no_alloc 成员为 false,则创建一个新的 ggml_tensor 结构体 data,并将其指针存储在 ggml_context 中;否则,data 将保持为 nullptr,不分配内存。
struct ggml_tensor * data = nullptr;
if (!params.no_alloc) {
data = ggml_new_tensor_1d(ctx_data, GGML_TYPE_I8, ctx->size);
ok = ok && data != nullptr;
if (ok) {
ggml_set_name(data, "GGUF tensor data binary blob");
}
// read the binary blob with the tensor data
ok = ok && gr.read(data->data, ctx->size);
if (!ok) {
GGML_LOG_ERROR("%s: failed to read tensor data binary blob\n", __func__);
ggml_free(ctx_data);
*params.ctx = nullptr;
gguf_free(ctx);
return nullptr;
}
ctx->data = data->data;
}
ggml_set_no_alloc(ctx_data, true); // 设置 ggml_context 的 no_alloc 标志为 true,表示不分配内存,因为我们已经将张量数据的二进制 blob 存储在 ctx->data 中,并且不需要 ggml_context 进行内存管理
// create the tensors
// 创建张量,根据 gguf_context 中存储的张量信息,为每个张量创建一个 ggml_tensor 结构体,并将其名称设置为张量的名称。
// 如果 params 中的 no_alloc 成员为 false,则将 ggml_tensor 结构体的 "data" 成员指向二进制数据缓冲区中的适当位置;否则,"data" 成员将保持为 nullptr,不分配内存。
for (size_t i = 0; i < ctx->info.size(); ++i) {
const struct gguf_tensor_info & info = ctx->info[i];
struct ggml_tensor * cur = ggml_new_tensor(ctx_data, info.t.type, GGML_MAX_DIMS, info.t.ne);
ok = ok && cur != nullptr;
if (!ok) {
break;
}
ggml_set_name(cur, info.t.name);
// point the data member to the appropriate location in the binary blob using the tensor info
if (!params.no_alloc) {
cur->data = (char *) data->data + info.offset;
}
}
if (!ok) {
GGML_LOG_ERROR("%s: failed to create tensors\n", __func__);
ggml_free(ctx_data);
*params.ctx = nullptr;
gguf_free(ctx);
return nullptr;
}
ggml_set_no_alloc(ctx_data, params.no_alloc);
}
return ctx;
}
struct gguf_context * gguf_init_from_file(const char * fname, struct gguf_init_params params) {
FILE * file = ggml_fopen(fname, "rb");
if (!file) {
GGML_LOG_ERROR("%s: failed to open GGUF file '%s'\n", __func__, fname);
return nullptr;
}
struct gguf_context * result = gguf_init_from_file_impl(file, params);
fclose(file);
return result;
}
...张量
ggml_tensor 是 ggml 框架中用于表示 n 维张量(tensor)的结构体。
ggml.h
...
struct ggml_tensor {
enum ggml_type type; // 数据类型,fp32 fp16 int8等
struct ggml_backend_buffer* buffer; // 张量数据所在的后端缓冲区,包含实际的张量数据 可以是metal、cpu、gpu
// 元素维度信息,表示张量在每个维度上的元素数量
// GGML_MAX_DIMS = 4,表示张量最多支持 4 个维度
/* 例如,对于一个形状为(2, 3, 4) 的张量,
ggml 里要特别注意:ne[0] 是最内层(连续)维度,ne[0] = 4,ne[1] = 3,ne[2] = 2,和 NumPy 矩阵是反着存的
[ [[0,4,8,6], [1,3,5,5], [2,6,4,8]] ,
[[1,4,6,8], [3,6,7,1], [2,3,5,5]] ]
表示该张量在第一个维度上有 2 个元素,在第二个维度上有 3 个元素,在第三个维度上有 4 个元素
*/
int64_t ne[GGML_MAX_DIMS]; // number of elements
// 字节步长,表示在内存中沿每个维度移动一个元素所需的字节数
/* 字节步长的计算方式如下:
nb[0] = ggml_type_size(type) 沿第一个维度移动一个元素所需的字节数,等于数据类型的大小
nb[1] = nb[0] * (ne[0] / ggml_blck_size(type)) + padding 沿第二个维度移动一个元素所需的字节数,等于沿第一个维度移动一个元素所需的字节数乘以第一个维度的元素数量除以数据类型的块大小,再加上填充字节数
nb[i] = nb[i-1] * ne[i-1] 沿第 i 个维度移动一个元素所需的字节数,等于沿第 i-1 个维度移动一个元素所需的字节数乘以第 i-1 个维度的元素数量
nb 数值 记录了每一个维度的地址偏移量,用于计算高维矩阵元素的地址,以及reshape、transpose、permute等操作,只需要交换nb数组即可
示例:矩阵A = [[[0,4,8], [2,6,10]], [[1,5,9], [3,7,11]]] , 其中A维度为(2,2,3)的一个三维矩阵
假设 ggml_type为int8,只占一个字节。假设 padding=0, 则 nb=[1, 3, 6, 12]
那么
A[0][0][0] 的地址偏移量为 0*nb[0] + 0*nb[1] + 0*nb[2] = 0
A[0][0][1] 的地址偏移量为 1*nb[0] + 0*nb[1] + 0*nb[2] = 1
A[0][1][0] 的地址偏移量为 0*nb[0] + 1*nb[1] + 0*nb[2] = 3
A[1][0][2] 的地址偏移量为 2*nb[0] + 0*nb[1] + 1*nb[2] = 8
A[1][1][2] 的地址偏移量为 2*nb[0] + 1*nb[1] + 1*nb[2] = 11
*/
size_t nb[GGML_MAX_DIMS]; // stride in bytes:
// nb[0] = ggml_type_size(type)
// nb[1] = nb[0] * (ne[0] / ggml_blck_size(type)) + padding
// nb[i] = nb[i-1] * ne[i-1]
// compute data
enum ggml_op op; // 张量的计算操作类型,表示该张量在计算图中执行的操作类型
// op params - allocated as int32_t for alignment
// 用于存储操作参数的数组,按照 int32_t 对齐
int32_t op_params[GGML_MAX_OP_PARAMS / sizeof(int32_t)];
int32_t flags; // 张量标志,表示该张量的属性和用途,例如是否是输入、输出、参数或损失张量等
struct ggml_tensor* src[GGML_MAX_SRC]; // 指向源张量的指针数组,表示该张量在计算图中依赖的其他张量
// source tensor and offset for views
// 对于视图张量,指向源张量的指针和偏移量,表示该视图张量是基于哪个源张量创建的,以及在源张量中的偏移位置
struct ggml_tensor* view_src; // 指向源张量的指针,表示该视图张量是基于哪个源张量创建的
size_t view_offs; // 视图张量在源张量中的偏移位置,表示该视图张量在源张量中的起始位置,以字节为单位
void* data; // 指向张量数据的指针,表示该张量在内存中的实际数据位置
char name[GGML_MAX_NAME]; // 张量名称,表示该张量的名称或标识符,通常用于调试和日志记录等目的
// 用于存储额外信息的指针,表示该张量可能需要存储一些额外的信息,例如在使用 ggml-cuda.cu 时可能需要存储 CUDA 相关的信息
void* extra; // extra things e.g. for ggml-cuda.cu
char padding[8]; // 填充字节,用于确保结构体的对齐,避免内存访问错误
};维度 & 步长
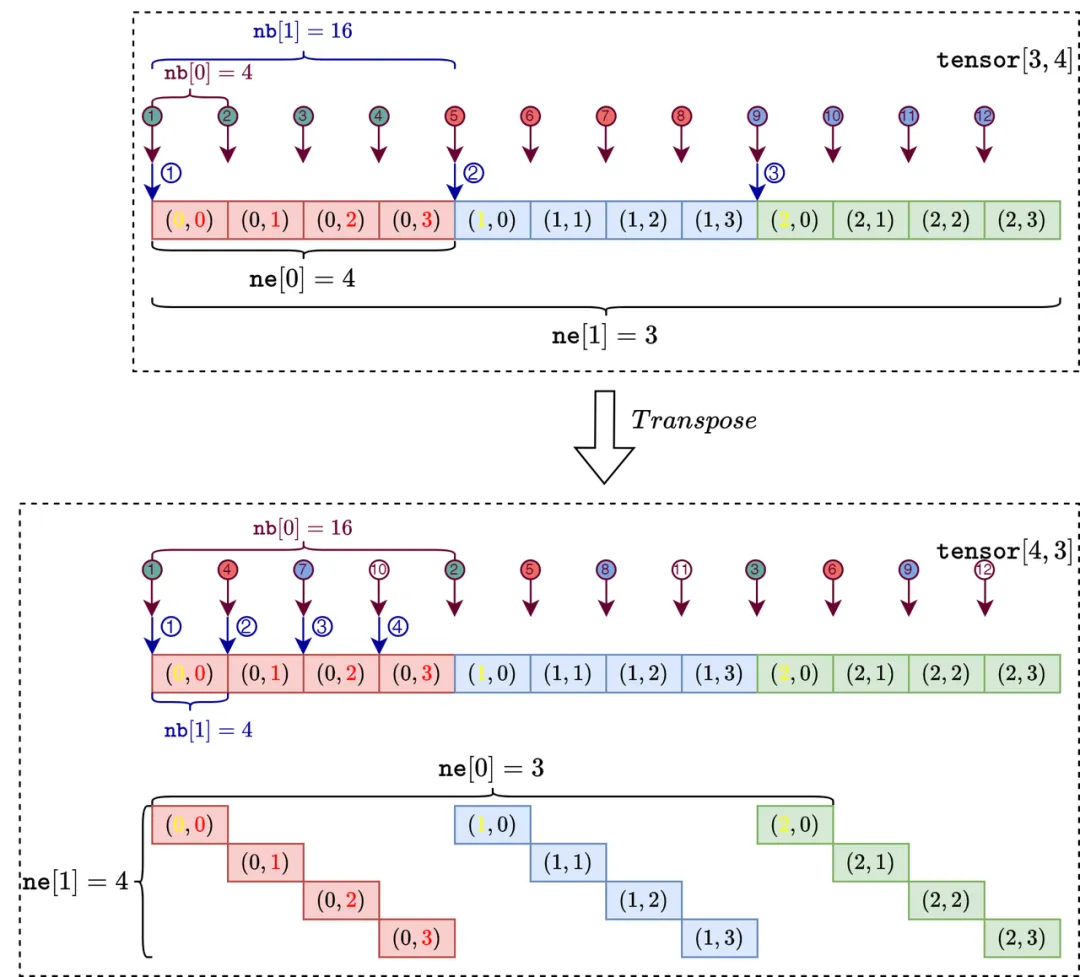
ne 字段比较容易理解,包含每个维度元素的数量的数组,由于 ggml 采用行主序,意味着 表示每一行的元素个数, 表示每一列的元素个数。其中,支持的最大维度为 4。
难点在于 对 nb 数组的理解:数组表示每一维度的字节步长(stride)。步长用于描述内存中不同维度元素的存储距离。
-
• 第一个维度的步幅计算为原始元素的字节大小,通常使用 ggml_type_size 函数获得: -
• 第二个维度的步幅计算考虑了阻塞 (可能是为了性能和对齐) 和填充: -
• 后续维度的步幅计算为:
例如,nb[0] 是类型元素的大小,nb[1] 是跨越第一维度所需的字节数,依此类推。
它用于高效地访问多维数组中的元素,对于一个 4x3x2 的 tensor 来说,其步长 nb 计算如下:

数据结构中使用步幅的目的是为了执行某些张量运算时无需数据拷贝操作。
对一个二维矩阵进行转置操作就是将行转换为列,在 ggml 中可以通过简单地翻转 ne 和 nb 并指向相同的基础数据来实现,详细代码如下:
// ggml_transpose
// 张量转置,交换前两个维度(行列交换)
struct ggml_tensor * ggml_transpose(
struct ggml_context * ctx,
struct ggml_tensor * a) {
struct ggml_tensor* result = ggml_view_tensor(ctx, a); // 创建一个新的张量视图,指向输入张量a
ggml_format_name(result, "%s (transposed)", a->name);
result->ne[0] = a->ne[1]; // 交换第0维和第1维的元素数量
result->ne[1] = a->ne[0]; // 交换第0维和第1维的元素数量
result->nb[0] = a->nb[1]; // 交换第0维和第1维的字节步长
result->nb[1] = a->nb[0]; // 交换第0维和第1维的字节步长
result->op = GGML_OP_TRANSPOSE; // 设置操作类型为转置
result->src[0] = a; // 设置输入张量a为操作的源张量
return result;
}转置函数中,result 是一个新张量,它被初始化为指向与源张量 a 相同的多维数字数组。
运算
前面讲了张量的定义,现在看一下张量的计算。
// available tensor operations:
// 张量运算枚举,表示 GGML 中支持的各种张量运算类型
enum ggml_op {
GGML_OP_NONE = 0,
GGML_OP_DUP, // 复制张量
GGML_OP_ADD, // 张量加法
GGML_OP_ADD_ID, // 张量加法,带有标量参数
GGML_OP_ADD1, // 张量加法,带有一个标量参数
GGML_OP_ACC, // 累加张量
GGML_OP_SUB, // 张量减法
GGML_OP_MUL, // 张量乘法
GGML_OP_DIV, // 张量除法
GGML_OP_SQR, // 张量平方
GGML_OP_SQRT, // 张量平方根
GGML_OP_LOG, // 张量对数
GGML_OP_SIN, // 张量正弦
GGML_OP_COS, // 张量余弦
GGML_OP_SUM, // 张量求和
GGML_OP_SUM_ROWS, // 张量按行求和
GGML_OP_CUMSUM, // 张量累积求和
GGML_OP_MEAN, // 张量求平均值
GGML_OP_ARGMAX, // 张量求最大值的索引
GGML_OP_COUNT_EQUAL, // 张量元素计数,满足条件的元素数量
GGML_OP_REPEAT, // 张量重复
GGML_OP_REPEAT_BACK, // 张量重复的反向传播
GGML_OP_CONCAT, // 张量连接
GGML_OP_SILU_BACK, // SiLU 激活函数的反向传播
GGML_OP_NORM, // normalize // 张量归一化
GGML_OP_RMS_NORM, // 张量均方根归一化
GGML_OP_RMS_NORM_BACK, // 张量均方根归一化的反向传播
GGML_OP_GROUP_NORM, // 张量分组归一化
GGML_OP_L2_NORM, // 张量 L2 归一化
GGML_OP_MUL_MAT, // 张量矩阵乘法
GGML_OP_MUL_MAT_ID, // 张量矩阵乘法,带有标量参数
GGML_OP_OUT_PROD, // 张量外积
GGML_OP_SCALE, // 张量缩放
GGML_OP_SET, // 张量设置为标量值
GGML_OP_CPY, // 张量复制
GGML_OP_CONT, // 张量连接,按指定维度连接
GGML_OP_RESHAPE, // 张量重塑
GGML_OP_VIEW, // 张量视图,改变张量的形状但不改变数据
GGML_OP_PERMUTE, // 张量置换,改变张量的维度顺序
GGML_OP_TRANSPOSE, // 张量转置,交换张量的两个维度
GGML_OP_GET_ROWS, // 从张量中获取指定行
GGML_OP_GET_ROWS_BACK, // 从张量中获取指定行的反向传播
GGML_OP_SET_ROWS, // 在张量中设置指定行的值
GGML_OP_DIAG, // 张量对角线,提取或设置张量的对角线元素
GGML_OP_DIAG_MASK_INF, // 张量对角线掩码,设置对角线元素为无穷大
GGML_OP_DIAG_MASK_ZERO, // 张量对角线掩码,设置对角线元素为零
GGML_OP_SOFT_MAX, // 张量激活函数,计算张量的 softmax
GGML_OP_SOFT_MAX_BACK, // 张量激活函数的反向传播,计算 softmax 的梯度
GGML_OP_ROPE, // 张量位置编码,应用旋转位置编码(RoPE)到张量
GGML_OP_ROPE_BACK, // 张量位置编码的反向传播,计算 RoPE 的梯度
GGML_OP_CLAMP, // 张量截断,限制张量的值在指定范围内
GGML_OP_CONV_TRANSPOSE_1D, // 一维卷积转置
GGML_OP_IM2COL, // 图像到列的转换
GGML_OP_IM2COL_BACK, // 图像到列的转换的反向传播
GGML_OP_IM2COL_3D, // 三维图像到列的转换
GGML_OP_CONV_2D, // 二维卷积
GGML_OP_CONV_3D, // 三维卷积
GGML_OP_CONV_2D_DW, // 二维卷积,深度可分离卷积
GGML_OP_CONV_TRANSPOSE_2D, // 二维卷积转置
GGML_OP_POOL_1D, // 一维池化
GGML_OP_POOL_2D, // 二维池化
GGML_OP_POOL_2D_BACK, // 二维池化的反向传播
GGML_OP_UPSCALE, // 张量上采样,增加张量的分辨率
GGML_OP_PAD, // 张量填充,在张量的边界添加指定值的填充
GGML_OP_PAD_REFLECT_1D, // 张量填充,使用反射模式在一维张量的边界添加填充
GGML_OP_ROLL, // 张量滚动,沿指定维度滚动张量的元素
GGML_OP_ARANGE, // 张量范围,创建一个包含指定范围内元素的张量
GGML_OP_TIMESTEP_EMBEDDING, // 张量时间步嵌入,生成时间步嵌入张量
GGML_OP_ARGSORT, // 张量排序,返回张量元素的排序索引
GGML_OP_TOP_K, // 张量 Top-K,返回张量元素的 Top-K 索引和对应值
GGML_OP_LEAKY_RELU, // 张量激活函数,计算张量的 Leaky ReLU
GGML_OP_TRI, // 张量三角形,提取或设置张量的上三角或下三角部分
GGML_OP_FILL, // 张量填充,使用指定值填充张量的元素
GGML_OP_FLASH_ATTN_EXT, // 张量 Flash Attention 扩展,计算 Flash Attention 的前向传播
GGML_OP_FLASH_ATTN_BACK, // 张量 Flash Attention 的反向传播,计算 Flash Attention 的梯度
GGML_OP_SSM_CONV, // 张量 SSM 卷积
GGML_OP_SSM_SCAN, // 张量 SSM 扫描
GGML_OP_WIN_PART, // 张量窗口分割
GGML_OP_WIN_UNPART, // 张量窗口合并
GGML_OP_GET_REL_POS, // 获取相对位置编码
GGML_OP_ADD_REL_POS, // 添加相对位置编码
GGML_OP_RWKV_WKV6, // 张量 RWKV WKV 计算,版本 6
GGML_OP_GATED_LINEAR_ATTN, // 张量门控线性注意力,计算门控线性注意力的前向传播
GGML_OP_RWKV_WKV7, // 张量 RWKV WKV 计算,版本 7
GGML_OP_SOLVE_TRI, // 张量三角求解
GGML_OP_UNARY, // 张量一元运算,操作数为一个张量
GGML_OP_MAP_CUSTOM1, // 张量映射自定义操作 1,允许用户定义自定义的张量映射操作
GGML_OP_MAP_CUSTOM2, // 张量映射自定义操作 2,允许用户定义自定义的张量映射操作
GGML_OP_MAP_CUSTOM3, // 张量映射自定义操作 3,允许用户定义自定义的张量映射操作
GGML_OP_CUSTOM, // 张量自定义操作,允许用户定义任意的张量操作
GGML_OP_CROSS_ENTROPY_LOSS, // 张量交叉熵损失,计算交叉熵损失的前向传播
GGML_OP_CROSS_ENTROPY_LOSS_BACK, // 张量交叉熵损失的反向传播,计算交叉熵损失的梯度
GGML_OP_OPT_STEP_ADAMW, // 张量优化步骤,使用 AdamW 优化算法更新模型参数
GGML_OP_OPT_STEP_SGD, // 张量优化步骤,使用 SGD 优化算法更新模型参数
GGML_OP_GLU, // 张量 GLU,计算门控线性单元(GLU)的前向传播
GGML_OP_COUNT, // 表示张量运算的数量,用于数组大小和边界检查
};ggml_op 定义了张量的操作 (矩阵乘、加法或激活等),如果设置为 GGML_OP_NONE,表明该张量持有数据,否则表明是某个运算的结果值。
GGML_OP_MUL_MAT 意味着该张量不持有数据,而仅代表两个其他张量之间矩阵乘法的结果。
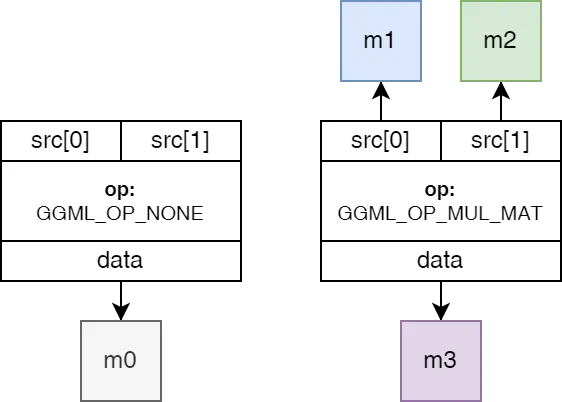
这里要对前端(Frontend)、后端(Backend)有一些了解:
-
• 前端(Frontend):负责“描述要做什么” -
• 后端(Backend):负责“具体怎么算”
结合你当前代码:
-
• 前端:ggml.c
例如 :ggml_mul_mat(ctx, a, b)
它主要是创建一个计算图节点:result->op = GGML_OP_MUL_MAT; result->src[0]=a; result->src[1]=b;
这里不做真正乘法运算,只是把算子和依赖关系记下来(建图)。 -
• 后端:ggml-cpu/ggml-cpu.c、ggml-cuda/ggml-cuda.cu
执行计算图时,根据节点 op 分发到具体实现。
CPU 路径:ggml_compute_forward(…) -> case GGML_OP_MUL_MAT -> ggml_compute_forward_mul_mat(…)
CUDA 路径:ggml_backend_cuda_graph_compute(…) -> ggml_cuda_compute_forward(…) -> case GGML_OP_MUL_MAT -> ggml_cuda_mul_mat(…)
后端代码待讲到 backend 时再细说。
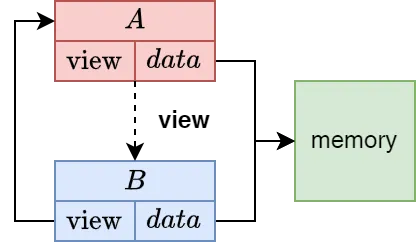
视图
-
• view_src:如果此张量是另一个张量的视图,则此指针指向原始(源)张量。视图与源张量共享数据,而无需创建副本。 -
• view_offs:如果此张量是视图,则此字段表示从源张量数据开始到此视图数据开始的字节偏移量。 -
• data :指向实际张量数据的指针。根据实现的不同,这可能直接指向 buffer或view_src张量中的特定位置。
源码
这里看一下张量的构建过程:
ggml.c
...
static struct ggml_object * ggml_new_object(struct ggml_context * ctx, enum ggml_object_type type, size_t size) {
// always insert objects at the end of the context's memory pool
// 这样可以保持对象在内存中的连续性,避免碎片化,并且简化内存管理
struct ggml_object * obj_cur = ctx->objects_end;
const size_t cur_offs = obj_cur == NULL ? 0 : obj_cur->offs; // 当前对象的偏移,如果没有对象则为0
const size_t cur_size = obj_cur == NULL ? 0 : obj_cur->size; // 当前对象的大小,如果没有对象则为0
const size_t cur_end = cur_offs + cur_size; // 当前对象的结束位置,即下一个对象的起始位置,如果没有对象则为0
// align to GGML_MEM_ALIGN
// 对齐到 GGML_MEM_ALIGN,确保新对象的起始位置满足内存对齐要求,以提高访问效率和性能
size_t size_needed = GGML_PAD(size, GGML_MEM_ALIGN);
char* const mem_buffer = ctx->mem_buffer; // 内存缓冲区指针,指向上下文的内存池,用于存储对象数据
// 新对象的指针,指向内存缓冲区中当前对象的结束位置,即新对象的起始位置
struct ggml_object* const obj_new = (struct ggml_object*)(mem_buffer + cur_end);
// 检查上下文的内存池是否有足够的空间来存储新对象,如果没有则返回 NULL,并在调试模式下触发断言失败
if (cur_end + size_needed + GGML_OBJECT_SIZE > ctx->mem_size) {
GGML_LOG_WARN("%s: not enough space in the context's memory pool (needed %zu, available %zu)\n",
__func__, cur_end + size_needed + GGML_OBJECT_SIZE, ctx->mem_size);
#ifndef NDEBUG
GGML_ABORT("not enough space in the context's memory pool");
#endif
return NULL;
}
*obj_new = (struct ggml_object) {
.offs = cur_end + GGML_OBJECT_SIZE, // 新对象的偏移位置,即当前对象的结束位置加上一个对象头的大小
.size = size_needed, // 新对象的大小,经过对齐处理后的大小
.next = NULL, // 新对象的下一个对象指针,初始化为 NULL,因为新对象将被插入到链表的末尾
.type = type, // 新对象的类型,指定为函数参数传入的类型
};
GGML_ASSERT_ALIGNED(mem_buffer + obj_new->offs); // 断言新对象的起始位置满足内存对齐要求
// 将新对象插入到上下文的对象链表中,如果当前对象不为 NULL,则将当前对象的下一个对象指针指向新对象,否则将上下文的对象链表开始指针指向新对象
if (obj_cur != NULL) {
obj_cur->next = obj_new;
} else {
// this is the first object in this context
ctx->objects_begin = obj_new;
}
ctx->objects_end = obj_new; // 将上下文的对象链表结束指针指向新对象,因为新对象现在是链表的最后一个对象
//printf("%s: inserted new object at %zu, size = %zu\n", __func__, cur_end, obj_new->size);
return obj_new;
}
// 在上下文中创建一个新的张量对象,指定类型、维度、尺寸等信息,并返回指向新张量的指针
static struct ggml_tensor * ggml_new_tensor_impl(
struct ggml_context* ctx, // 上下文指针,管理内存和对象
enum ggml_type type, // 张量的数据类型,如浮点数、整数等
int n_dims, // 张量的维度数量
const int64_t * ne, // 每个维度的大小
struct ggml_tensor * view_src, // 源张量(用于视图张量)
size_t view_offs) { // 视图张量的偏移量
GGML_ASSERT(type >= 0 && type < GGML_TYPE_COUNT); // 断言类型有效
GGML_ASSERT(n_dims >= 1 && n_dims <= GGML_MAX_DIMS); // 断言维度数量有效
// find the base tensor and absolute offset
// 查找基础张量和绝对偏移量
if (view_src != NULL && view_src->view_src != NULL) {
view_offs += view_src->view_offs;
view_src = view_src->view_src;
}
// 计算张量数据的总大小
size_t data_size = ggml_row_size(type, ne[0]);
for (int i = 1; i < n_dims; i++) {
data_size *= ne[i];
}
// 断言视图张量的数据大小和偏移量不超过源张量的总字节数
GGML_ASSERT(view_src == NULL || data_size == 0 || data_size + view_offs <= ggml_nbytes(view_src));
// 数据指针,如果是视图张量则指向源张量的数据,否则为NULL
void* data = view_src != NULL ? view_src->data : NULL;
if (data != NULL) {
data = (char *) data + view_offs;
}
size_t obj_alloc_size = 0;
if (view_src == NULL && !ctx->no_alloc) {
// allocate tensor data in the context's memory pool
// 如果不是视图张量且上下文允许分配内存,则在上下文的内存池中分配张量数据
obj_alloc_size = data_size;
}
// 创建一个新的张量对象,大小为张量对象本身加上数据大小(如果需要分配的话)
struct ggml_object * const obj_new = ggml_new_object(ctx, GGML_OBJECT_TYPE_TENSOR, GGML_TENSOR_SIZE + obj_alloc_size);
GGML_ASSERT(obj_new);
// 计算新张量对象在内存中的位置,并将其初始化为指定的类型、维度、尺寸等信息
struct ggml_tensor * const result = (struct ggml_tensor *)((char *)ctx->mem_buffer + obj_new->offs);
*result = (struct ggml_tensor) {
/*.type =*/ type, // 张量的数据类型
/*.buffer =*/ NULL, // 张量的数据缓冲区指针,通常为NULL,因为数据可能在内存池中分配
/*.ne =*/ { 1, 1, 1, 1 }, // 张量的每个维度的大小,默认初始化为1
/*.nb =*/ { 0, 0, 0, 0 }, // 张量的每个维度的字节步长,默认初始化为0
/*.op =*/ GGML_OP_NONE, // 张量的操作类型,默认初始化为无操作
/*.op_params =*/ { 0 }, // 张量的操作参数,默认初始化为0
/*.flags =*/ 0, // 张量的标志位,默认初始化为0
/*.src =*/ { NULL }, // 张量的源张量指针,默认初始化为NULL
/*.view_src =*/ view_src, // 张量的视图源张量指针,如果是视图张量则指向源张量,否则为NULL
/*.view_offs =*/ view_offs, // 张量的视图偏移量,如果是视图张量则为相对于源张量的偏移量,否则为0
/*.data =*/ obj_alloc_size > 0 ? (void*)(result + 1) : data, // 张量的数据指针,如果需要分配内存则指向新张量对象后面的位置,否则为视图张量的数据指针
/*.name =*/ { 0 }, // 张量的名称,默认初始化为空字符串
/*.extra =*/ NULL, // 张量的额外信息指针,默认初始化为NULL
/*.padding =*/ { 0 }, // 张量的填充字节,默认初始化为0
};
// TODO: this should not be needed as long as we don't rely on aligned SIMD loads
//GGML_ASSERT_ALIGNED(result->data);
// 将张量的每个维度的大小复制到新张量对象中
for (int i = 0; i < n_dims; i++) {
result->ne[i] = ne[i];
}
result->nb[0] = ggml_type_size(type); // 计算第一个维度的字节步长,通常为数据类型的大小
result->nb[1] = result->nb[0] * (result->ne[0] / ggml_blck_size(type)); // 计算第二个维度的字节步长,通常为第一个维度的字节步长乘以第一个维度的大小(除以块大小)
for (int i = 2; i < GGML_MAX_DIMS; i++) { // 计算后续维度的字节步长,通常为前一个维度的字节步长乘以前一个维度的大小
result->nb[i] = result->nb[i - 1] * result->ne[i - 1]; // 注意:这里的计算方式假设张量是连续存储的,如果张量是视图或者有特殊的内存布局,字节步长可能需要根据具体情况进行调整
}
ctx->n_objects++; // 增加上下文中的对象计数
return result;
}上下文
对于 ggml 框架来说,无论你要做什么(例如构建 model、建立计算图等)都需要先创建一个 context 作为容器,而你所创建的任何信息结构体(tensor、graph、…)实际都存储在 context 容器包含的地址空间内。
// GGML 上下文结构体,一个装载各类对象(如张量、计算图 等数据)的容器
struct ggml_context {
size_t mem_size; // 内存大小
void * mem_buffer; // 内存缓冲区指针
bool mem_buffer_owned; // 是否拥有内存缓冲区
bool no_alloc; // 是否不分配内存
int n_objects; // 对象数量
struct ggml_object* objects_begin; // 对象链表的开始指针
struct ggml_object* objects_end; // 对象链表的结束指针
};下面以 ggml_context 为例来讲解,ggml_context 主要用于管理和存储与计算图或张量操作相关的上下文信息,可以承载三种数据类型:Tensor、Graph、Work_buffer。
它可以被看作是一个 内存管理 和 资源组织 的中心,负责管理计算中使用的所有对象和内存,内部结构如下图所示:
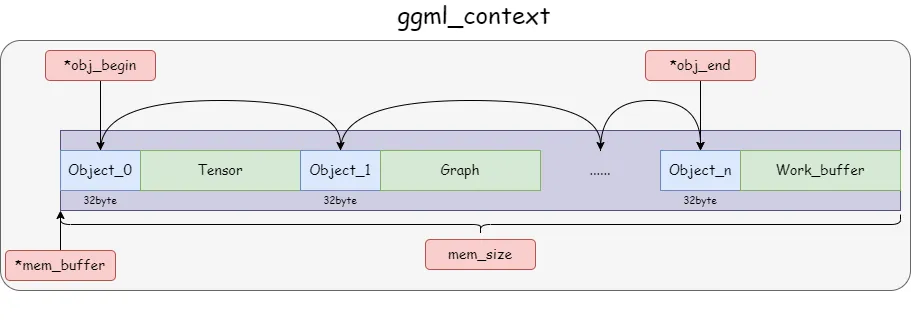
总的来说,ggml_context 类似于一个 “容器” 或 “管理器”,负责保存和组织计算图中的所有对象,它让你可以灵活地处理张量、计算图等对象的内存分配、释放和管理。
源码
上下文的创建就比较简单:
ggml.c
// GGML 上下文初始化函数,接受 GGML 初始化参数结构体作为输入,返回一个指向 GGML 上下文结构体的指针。该函数负责初始化 GGML 上下文,包括分配内存、设置内存缓冲区、初始化对象链表等,并确保线程安全。
struct ggml_context * ggml_init(struct ggml_init_params params) {
static bool is_first_call = true;
ggml_critical_section_start(); // 进入临界区,确保线程安全,防止多个线程同时初始化 GGML 上下文导致竞争条件和内存泄漏
if (is_first_call) {
// initialize time system (required on Windows)
ggml_time_init(); // 初始化时间系统,确保 GGML 在 Windows 平台上能够正确处理时间相关的功能,如性能测量和调度等
is_first_call = false;
}
ggml_critical_section_end(); // 退出临界区,允许其他线程继续执行,完成 GGML 上下文的初始化过程
// 分配内存用于 GGML 上下文结构体,使用 GGML_MALLOC 宏进行内存分配,确保分配的内存满足 GGML 的对齐要求
struct ggml_context* ctx = GGML_MALLOC(sizeof(struct ggml_context));
// allow to call ggml_init with 0 size
// 如果用户没有指定内存大小(即 mem_size 为 0),则将内存大小设置为 GGML_MEM_ALIGN 的值,以确保至少分配一个对齐块的内存。这是为了避免在后续操作中出现内存不足的情况,并且保证内存分配满足对齐要求,提高访问效率和性能。
if (params.mem_size == 0) {
params.mem_size = GGML_MEM_ALIGN;
}
// 计算实际需要分配的内存大小,如果用户提供了内存缓冲区,则使用用户指定的内存大小;如果没有提供内存缓冲区,则将内存大小调整为 GGML_MEM_ALIGN 的倍数,以满足对齐要求。这是为了确保分配的内存满足 GGML 的对齐要求,提高访问效率和性能。
const size_t mem_size = params.mem_buffer ? params.mem_size : GGML_PAD(params.mem_size, GGML_MEM_ALIGN);
// 初始化 GGML 上下文结构体,设置内存大小、内存缓冲区指针、内存缓冲区所有权标志、是否不分配内存标志,以及对象链表的开始和结束指针。根据用户提供的参数,如果用户提供了内存缓冲区,则使用用户指定的内存缓冲区;如果没有提供内存缓冲区,则分配一个新的内存缓冲区,并将所有权标志设置为 true,以便在 GGML 上下文被释放时正确释放内存。
*ctx = (struct ggml_context) {
/*.mem_size =*/ mem_size,
/*.mem_buffer =*/ params.mem_buffer ? params.mem_buffer : ggml_aligned_malloc(mem_size),
/*.mem_buffer_owned =*/ params.mem_buffer ? false : true,
/*.no_alloc =*/ params.no_alloc,
/*.n_objects =*/ 0,
/*.objects_begin =*/ NULL,
/*.objects_end =*/ NULL,
};
GGML_ASSERT(ctx->mem_buffer != NULL);
GGML_ASSERT_ALIGNED(ctx->mem_buffer);
GGML_PRINT_DEBUG("%s: context initialized\n", __func__);
return ctx;
}