Embedding(嵌入) 这个词在我最近的几篇文章中绝对是高频词了,因为讲现在的 RAG 系统是绝对绕不开词嵌入的。但是我一直没有说明的是,这个 embedding 本身是怎么来的,为什么一个词,或者一句话能够对应一个向量,或者说为什么这个存在于数学空间中的向量,能够相对准确的代表文字在语义世界中的含义。
Embedding 这个词本身的含义就是某样东西嵌入另一样东西的表征,而且保留这个东西原本的内在性质跟相对关系。举个不完全准确例子来说,我们可以说生物化石就是生物在岩石中的 embedding,因为这个生物被 “嵌入” 了岩石中,且几乎完整的保留了它原本的内在信息。
如果说我们有能力将文字信息的含义转化成其对应在向量空间中的某个向量的话,那么用 embedding 这个词来表述这个对应的向量,可以说是再合适不过了。因为我们首先将文字信息保存在了这个向量空间中,且保留了文字本身的内在含义性质。
接下来我们就讲讲 embedding 到底是怎么计算出来的,如今的 embedding 都是基于注意力机制的编码器算出来的,但是要说词嵌入算法的鼻祖,在我看来那肯定要从大名鼎鼎的 Word2Vec 说起。
Word2Vec,源自于 2013 年的论文 《Efficient Estimation of Word Representations in Vector Space》,从它的名字就能看出 Word(词),2 谐音 to(到),Vec,即 Vector(向量)的简写,连起来的意思就是把 “词” 变成 “向量”。
可能有人会说,在这之前不是也有 one-hot 编码的形式吗,能把所有词汇用所谓的 “独热” 方法编码为向量,比如如果我们一共有三个词 [苹果,香蕉,橘子] 的话,我们可以使用如下的编码方式:
苹果 = [1, 0, 0]
香蕉 = [0, 1, 0]
橘子 = [0, 0, 1]
这样我们就可以用一个数学上的向量来表示一个文字信息了。虽然如此,我为什么说 Word2Vec 在我看来才是真正意义上的第一个 Embedding 呢,因为上面的这种编码方式除开维度爆炸跟稀疏的问题以外,最重要的就是它完全 “不表意”,或者说每个词对应的向量完全跟这个词本身的含义没有任何关系,这只是一个单纯的排序编码操作,就好像我们可以管小明叫 1 号,管小红叫 2 号,1 和 2 这两个数字本身没有任何有关小明和小红的含义信息。
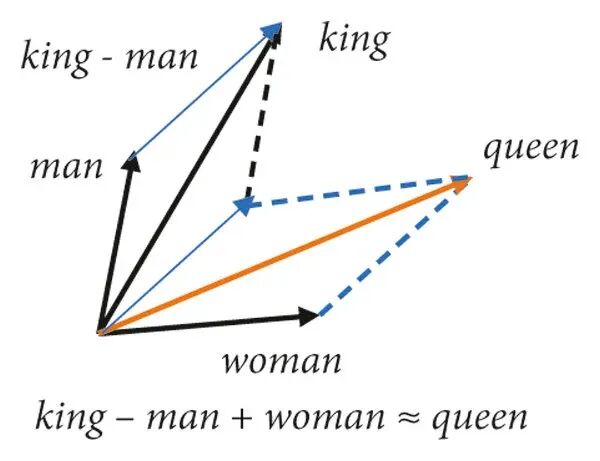
那么一个很自然的问题就是,我们所谓的 “表意” 到底是什么意思,这些数字要有什么特征才算是表意呢?将文字信息转换为向量最大的用处就是我们可以对向量直接进行数学运算,也就是说如果我们能找到含义对应的向量的话,我们可以对含义进行逻辑运算,跟文字含义的模糊性相比,数学运算是清晰直观的。这里就不得不提到 Word2Vec 中最有名的案例了。
这个式子告诉我们,“国王” 中去除 “男人” 的含义后,再加上 “女人” 的含义,可以大致得到 “女王” 这个词的含义。
我第一次看到这个逻辑关系时候我是震惊的,我从来没想过人类的语言的含义也可以做如此精确的计算,而且它的结果是那么符合我们的直觉。类似的例子还有很多:
巴黎 – 法国 + 中国 = 北京
啤酒 – 德国 + 俄罗斯 = 伏特加
父亲 – 男人 + 女人 = 母亲
苹果 – 乔布斯 + 微软 = 比尔盖茨
虽然有的不是完全准确,但是它基本能表示普罗大众对于这些概念的理解,而这样的的语义关系,one-hot 的编码方式是完全做不到的。
Word2Vec 的核心思想在今天看来还是比较朴素的,但是绝对是今天语言表征奠基性的思想,Word2Vec 提出:
一个词的含义 = 它周围出现的词
那么周围的词相似的词之间则含义也类似
直白的讲,Word2Vec 就是说,一个词的含义完全取决于它经常跟什么词一起出现。这个判断其实我们从直觉上也可以理解,如果某些词总是一起在句子中出现的话,起码说明他们需要被放在一起,从而才能起到表达某些含义的作用,那么他俩的含义大概率是有关联的。
而对于这个假设的完美背书则是语言学家 J.R. Firth 在 1957 年说过一句:
You shall know a word by the company it keep.
你可以用一个词的邻居来判断这个词。
他在半多个世纪前的洞见终于在 2013 年被人们用数学方法实践了。
这里我还想多说一点,我们其实早就在对于人的判断上使用了一模一样的方法,常用的几个判断人成语比如说,“物以类聚,人以群分”,“一丘之貉”,“狐朋狗友”,“近朱者赤,近墨者黑” 等都是在描述一个人的性质是由他周边的人塑造的。而我这些年对于一个人的描述最喜欢的一句话是:
一个人是他周围所有社交关系的总和
这几乎完美对应了我们今天对于一个词语义的使用场景,一个词的含义属性由它经常 “混” 在一起的别的词共同决定。
讲到这里,Word2Vec 的算法也就不言自明了,我们能不能通过一个中心词,去预测那些经常跟它一起出现的词,而这个训练过程就是在提取这个中心词语义的过程,在原始的论文中这个方法也被叫做 “Skip-gram”。
具体举例来说,给定一句 “猫喜欢吃鱼和骨头”,假定我们此刻关注的词是 “吃”,我们只想预测它周围 4 个词,也就是左边 2 个跟右边 2 个。
句子: "猫 喜欢 吃 鱼 和 骨头" ↑ 中心词 "吃",窗口=2训练目标: "吃" → 预测 ["猫", "喜欢", "鱼", "和"]
我们对句子中的每个词都做一样的操作,类似的,当我们的关注词从 “吃” 到 “鱼” 的话:
句子: "猫 喜欢 吃 鱼 和 骨头" ↑ 中心词 "鱼",窗口=2训练目标: "鱼" → 预测 ["喜欢", "吃", "和","骨头"]
而模型的结构就是最简单的神经网络结构,我们每个词使用我们前面提到的 one-hot 编码作为输入,假设我们一共有 10 万个不同的字,我们的 one-hot 编码就有 10 万维,如果我们想让最终编码的词向量的维度是 128 的话,那么在在训练 “吃” 的时候如下:
"吃" 的 one-hot 向量: [0,0,0,1,0,0,...] (词表大小,如 10万维) ↓ 乘以矩阵 W (10万 × 128) hidden: [0.3, 0.7, -0.2, ..., 0.5] (128维) ↓ 乘以矩阵 W' (128 × 10万) output: softmax → 词表上的概率分布 ↓ loss: 让 "猫"、"喜欢"、"鱼"、"和" 的概率最高
当我们训练了无数句子的所有中心词之后,我们的第一个矩阵 W 的每一行,就是我们对应编码位置词的 embedding。实际上,我们使用 one-hot 向量乘以这个矩阵 W 后,我们只会保留这个矩阵其中的一行,即 one-hot 中是 1 的那一行,这一步的矩阵乘法其实也就对应着这个词在我们的 W 矩阵中 “查表” 找到自己的向量。
这里有一个细节,很多时候人们会直接忽略掉,但是却是一个很好的问题,就是我们的网络中有分明两个矩阵 W 和 W’,为什么在最终 embedding 的选择时候,第 i 个词的 embedding 我们选择的是 W 的第 i 行,而不是 W’ 的第 i 列。
这里我说说我的理解,我上面提到,其实第一步的矩阵 W 的操作就是一个查表的过程,第 i 个词在 W 中找到了自己所代表的第 i 行,这一步主观描述来说有一点像是第 i 个词在告诉别人说 “我是谁”。而后面的矩阵 W’ 在计算的过程中被使用的方式是找到那些跟 W 第 i 行点积最大的列,也就是说 W’ 中的某一列被使用的时候是当它作为周围词汇时候跟中心词的关系,W’ 的第 i 列的词主观的表述就是 “别人眼中的我是什么样子”。所以 W 中的每一行是中心词的 “主动编码”,而 W’ 中的每一列是周围词的 “被动解码”。那么如果我想找到一个向量代表这个词的话,选择主动编码是更加自然的选择。说的更明白一点 W 是我自己选择的身份,W’ 是别人给我的身份,虽然说选择哪个都不算错,但是工程上人们习惯使用 W 作为 embedding 的查询表。
相比简单的 one-hot 编码,使用 Word2Vec 得到的 embedding 可以说是史诗级加强了,因为向量现在也能代表词的含义了。但是它有一个致命的缺点就是每个词对应的 embedding 是固定的,而这在实际应用中是有缺陷的。比如 “苹果” 这个词,在 “苹果公司新发布的手机” 这句话中代表的含义就跟 “我爱吃苹果” 这句话中代表的含义完全不同。但是训练好的 Word2Vec 给出的 embedding 是固定不变的含义,而这也是后继新算法试图解决的最大问题。
下周我们会继续根据 embedding 算法的发展介绍基于 Word2Vec 演化的 embedding 方法,最终会介绍到现今基于 attention 的 embedding。
 夜雨聆风
夜雨聆风