 夜雨聆风
夜雨聆风





NIPS 2025 | 刷新多模态文档理解SOTA!ALIGNVLM:用LLM语言先验解锁视觉-语言对齐新范式


论文信息
题目:ALIGNVLM: Bridging Vision and Language Latent Spaces for Multimodal Document Understanding
ALIGNVLM:桥接视觉与语言潜在空间的多模态文档理解方法
作者:Ahmed Masry, Juan A. Rodriguez, Tianyu Zhang, Suyuchen Wang, Chao Wang, Aarash Feizi, Akshay Kalkunte Suresh, Abhay Puri, Xiangru Jian, Pierre-André Noël, Sathwik Tejaswi Madhusudhan, Marco Pedersoli, Bang Liu, Nicolas Chapados, Yoshua Bengio, Enamul Hoque, Christopher Pal, Issam H. Laradji, David Vazquez, Perouz Taslakian, Spandana Gella, Sai Rajeswar
一、痛点直击:传统VLM连接器的三大“致命伤”
视觉语言模型处理文档理解任务时,通常由视觉编码器、LLM、连接器三大模块构成(如下图)。其中连接器是跨模态对齐的核心,但现有方案始终存在难以突破的瓶颈:
1. 深度融合:参数爆炸,效率拉胯
NVLM、Flamingo等深度融合方法,需要在LLM每一层加交叉注意力和前馈层,直接让模型参数和计算量飙升,商业落地的部署成本居高不下。
2. 浅层融合:无归纳偏置,易“脱轨”
MLP、卷积映射等浅层融合方案,虽参数更高效,但无法约束视觉特征落在LLM文本嵌入的有效区域——投影后的特征常跳出训练分布,导致噪声、错位,且极度依赖海量训练数据。
3. 视觉嵌入表:新增参数多,对齐难保障
Ovis等方法引入独立视觉嵌入表,虽试图缓解对齐问题,但额外的嵌入矩阵大幅增加参数,且无法保证与LLM语义空间的精准对齐,训练成本依旧高昂。
简言之,传统连接器要么“重到用不起”,要么“轻但不好用”,低资源场景下更是直接失效。而ALIGNVLM的核心创新,正是直击这一痛点。
二、核心突破:ALIGN连接器的三大设计巧思
ALIGNVLM的整体架构如下图所示,核心是用ALIGN模块替代传统连接器,通过“概率分布+凸组合”的思路,让视觉特征天然融入LLM的语义体系:
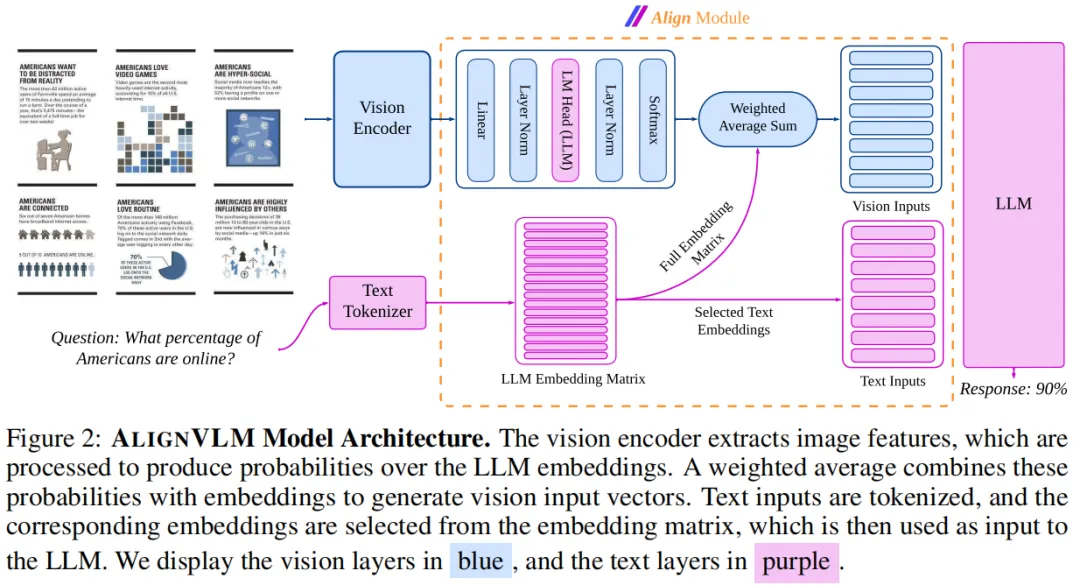
1. 不做“直接投影”,做“加权融合”
ALIGN模块摒弃了将视觉特征直接映射到LLM嵌入空间的思路,转而先通过线性层将视觉特征转化为LLM词汇表上的概率分布——简单说,就是让每个视觉特征“对应”词汇表中一系列词的概率权重,再用这些权重对LLM预训练的文本嵌入做加权求和。
这种设计的关键在于:视觉特征被严格约束在LLM文本嵌入的凸包内,相当于借用了LLM海量预训练积累的语言先验知识,从根源上避免了“分布外投影”问题。
2. 归纳偏置加持,低资源也能打
传统MLP连接器的参数完全从头学,而ALIGN的核心线性层从LLM的语言模型头初始化,自带“语义对齐”的归纳偏置——无需海量数据,就能让视觉特征快速贴合LLM的语义逻辑。实验证明,仅用779K样本的低资源场景下,ALIGN的性能增益远超MLP、Perceiver Resampler等方案。
3. 参数高效,无额外负担
相比Ovis新增视觉嵌入表的做法,ALIGN完全复用LLM已有的文本嵌入,不新增任何大规模参数,保持了浅层融合的高效性,同时规避了“新嵌入对齐难”的问题。
三、硬核实验:全方位碾压,刷新SOTA
作者在DocVQA、InfoVQA、ChartQA等9个文档理解基准上做了全面验证,从高资源、低资源、抗噪声三个维度,充分证明了ALIGNVLM的优势。
1. 高资源场景:吊打传统连接器
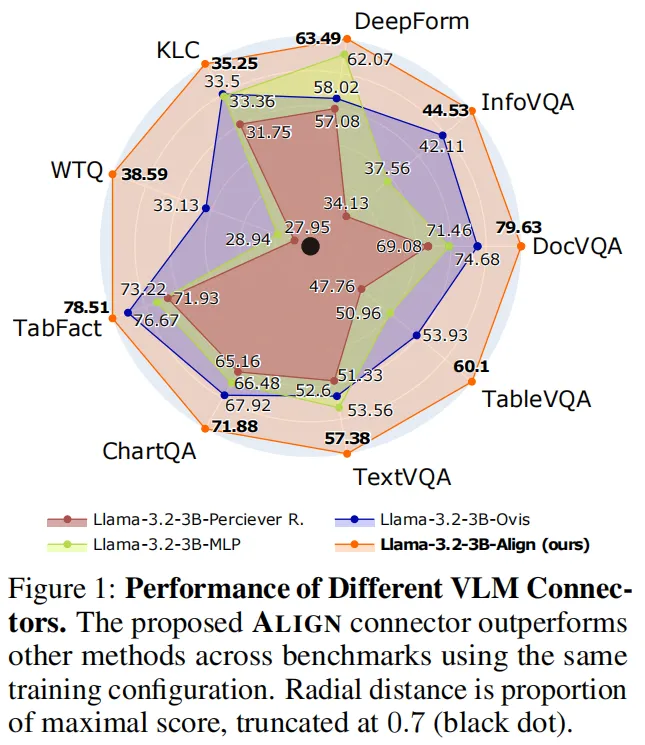
在使用BigDocs-7.5M数据集的高资源训练下,ALIGNVLM-3B以58.81%的综合准确率,大幅超越MLP(53.06%)、Perceiver Resampler(50.68%)、Ovis(54.72%)等主流连接器,如下图所示:
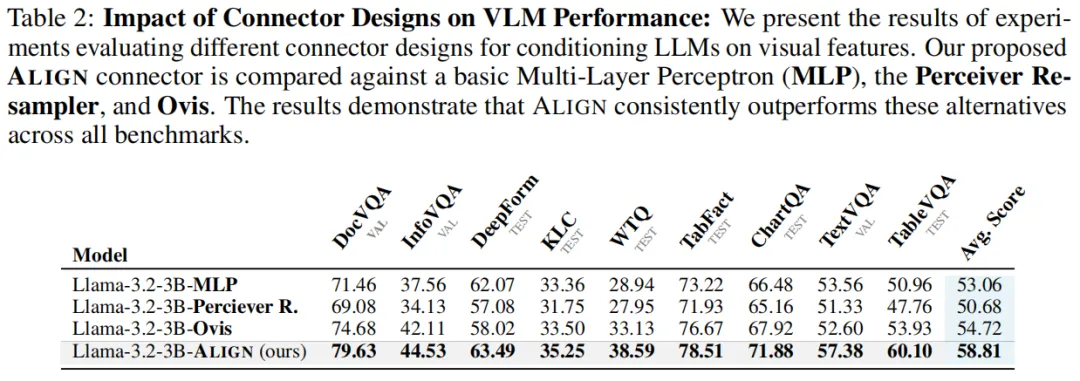
更惊艳的是,参数量仅3B的ALIGNVLM,性能直接超越8B的DocOwl1.5,甚至能和11B的Llama 3.2-Vision掰手腕——用更少的参数实现更强的性能,充分体现了对齐设计的价值。
2. 低资源场景:优势进一步放大
在仅779K样本的LLaVA-NeXT数据集上,ALIGN的性能优势比高资源场景更显著(如下图)。原因很简单:归纳偏置让它从少量数据中就能学到位,而依赖“暴力拟合”的MLP等方案,在数据不足时直接“拉胯”。
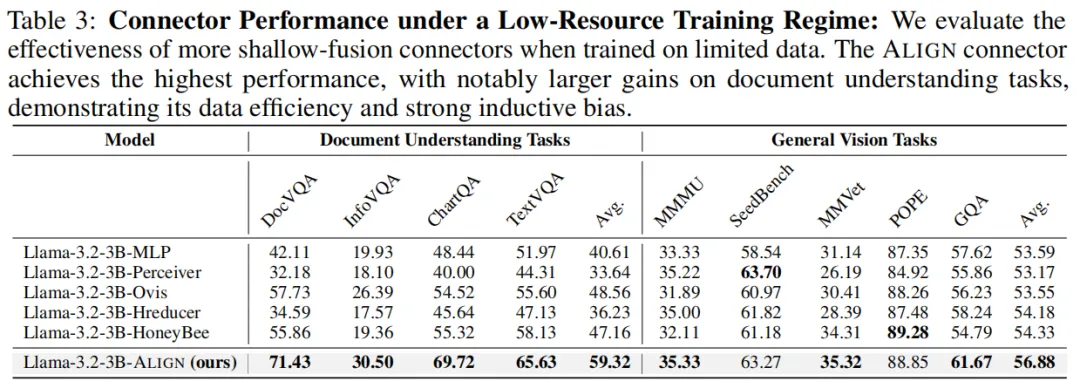
这一特性对学术研究、中小厂落地尤为友好——无需动辄百万、千万级的标注数据,就能实现工业级的文档理解效果。
3. 抗噪声鲁棒性:稳如磐石
给视觉特征添加高斯噪声后,ALIGN的性能仅下降1.67%,而MLP直接暴跌25.54%!原因在于ALIGN的视觉特征锚定在LLM文本嵌入的凸包内,相当于有了“语义正则化”,即便视觉特征带噪声,也能通过文本先验修正偏差。
4. 词元分布分析:精准利用核心语义
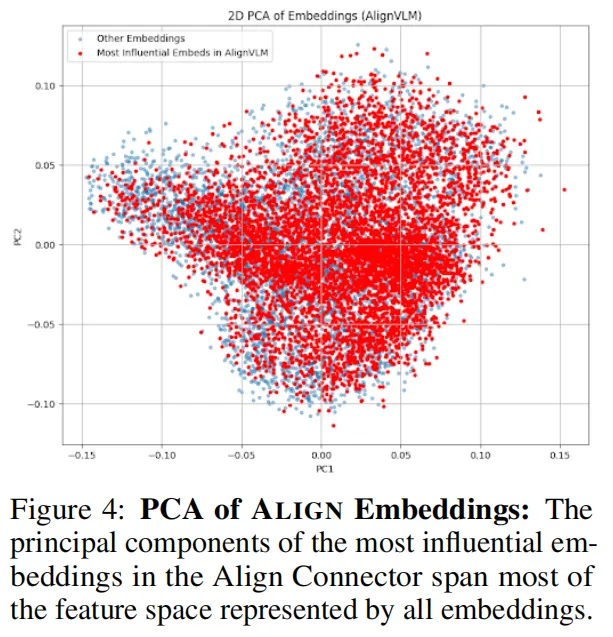
作者进一步分析发现,ALIGN会将高概率集中在3.4K个核心词元上,这些词元能全面覆盖LLM的语义空间(如下图PCA可视化结果);即便只保留这3.4K个词元,性能几乎无损失——这意味着ALIGN还能通过嵌入剪枝进一步提升效率,部署更轻量化。
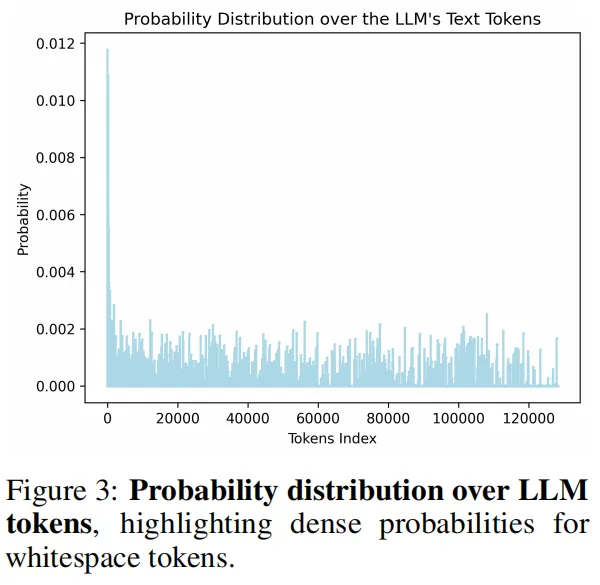
下图则展示了视觉特征转化为词汇表概率分布的特点:分布密集且无明显的单点峰值,符合视觉特征连续、高维的本质,也印证了“加权融合”比“单点映射”更贴合视觉-语言对齐的底层逻辑。
四、总结:不止是SOTA,更是对齐思路的革新
ALIGNVLM的核心贡献,远不止刷新了几个基准的SOTA,更在于它重新定义了VLM连接器的设计逻辑:与其让视觉特征“适配”LLM,不如让视觉特征“融入”LLM的语义体系。
这种思路带来的三重价值:
-
性能更强:跨模态对齐更精准,文档理解任务全面超越现有方案; -
效率更高:无额外参数,低资源场景下数据效率碾压传统方法; -
鲁棒性更好:抗噪声、抗分布偏移能力显著提升。
对于工业界而言,ALIGNVLM的轻量化、低资源适应性,让发票解析、表单读取、文档问答等场景的落地成本大幅降低;对于学术界,它为视觉-语言对齐提供了“利用LLM先验”的全新范式,后续可拓展到更多多模态任务(如视频-文本对齐、3D-语言对齐)。
目前作者已开源了代码和研究资料,感兴趣的同学可以直接上手复现、拓展——或许基于这个思路,你也能解锁更多跨模态对齐的新可能!
如果大家有要宣传的工作(paper、项目、rp、招聘等),欢迎后台留言
关注+星标不迷路~
CCF/SCI/SSCI论文辅导
