 夜雨聆风
夜雨聆风





Linux 网络子系统源码剖析(十三):网络性能优化技术 – 突破性能瓶颈
从零拷贝到硬件卸载 – 榨干网络性能的每一滴潜力
系列:Linux 网络子系统源码剖析篇号:第 13 篇内核版本:Linux 5.10 LTS重点模块:零拷贝、硬件Offload、中断优化、多队列技术
📋 本篇导读
你将学到
-
• 零拷贝技术的完整实现(sendfile、splice、MSG_ZEROCOPY) -
• 硬件 Offload 技术(TSO/GSO、GRO/LRO、Checksum、RSS) -
• 中断优化技术(NAPI、中断合并、中断亲和性) -
• 内存优化技术(sk_buff 池化、页面回收、NUMA 感知) -
• 多队列技术(RSS、RPS、RFS、XPS) -
• 性能测试和分析方法 -
• 实战优化案例和最佳实践
前置知识
-
• 已阅读第 1-12 篇文章 -
• 了解 Linux 内核内存管理 -
• 理解网络协议栈基础 -
• 熟悉性能分析工具
阅读时间
约 100-120 分钟
🎯 概述
1.1 网络性能瓶颈
现代网络应用面临的性能挑战:
硬件层面:
-
• 网卡速度:1Gbps → 10Gbps → 100Gbps -
• CPU 性能:单核性能提升缓慢 -
• 内存带宽:成为新的瓶颈 -
• PCIe 带宽:限制数据传输
软件层面:
-
• 数据拷贝:用户空间 ↔ 内核空间 -
• 上下文切换:系统调用开销 -
• 中断处理:中断风暴问题 -
• 缓存失效:CPU 缓存命中率低
网络协议栈开销:
应用层数据 │ ▼ 系统调用(上下文切换)Socket 层 │ ▼ 拷贝到内核TCP/IP 层(协议处理) │ ▼ 构造数据包设备驱动层 │ ▼ DMA 传输网卡硬件 │ ▼ 物理传输网络1.2 优化目标
吞吐量优化:
-
• 目标:接近网卡线速 -
• 指标:Gbps、pps(packets per second) -
• 关键:减少 CPU 开销
延迟优化:
-
• 目标:降低端到端延迟 -
• 指标:微秒级延迟 -
• 关键:减少处理路径
CPU 效率优化:
-
• 目标:降低 CPU 使用率 -
• 指标:每 Gbps 的 CPU 使用率 -
• 关键:硬件卸载、批处理
1.3 优化技术概览

📋 零拷贝技术
2.1 传统数据传输的问题
传统 read/write 方式:
/* 传统方式:4 次拷贝,4 次上下文切换 */char buf[8192];/* 1. read():磁盘 → 内核缓冲区 → 用户缓冲区 */int fd = open("file.txt", O_RDONLY);ssize_t n = read(fd, buf, sizeof(buf)); /* 2 次拷贝 *//* 2. write():用户缓冲区 → socket 缓冲区 → 网卡 */write(sockfd, buf, n); /* 2 次拷贝 */数据流动路径:
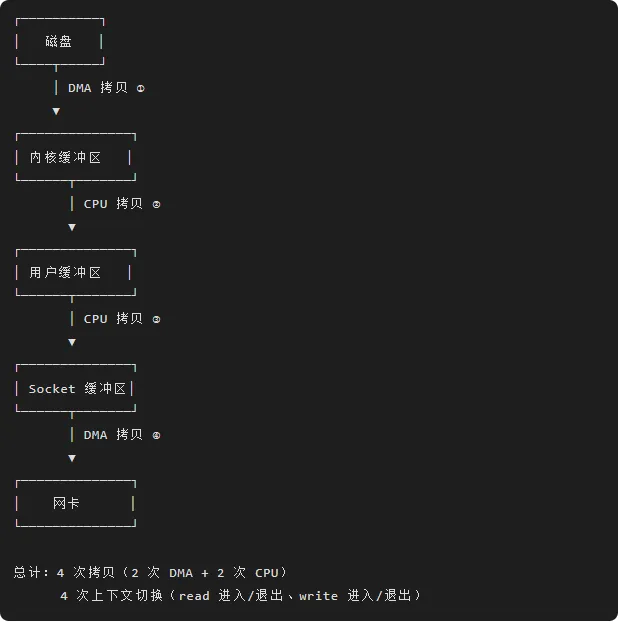
2.2 sendfile() 零拷贝
sendfile() 在内核空间直接传输数据,避免用户空间拷贝。
源码位置:fs/read_write.c
/** * do_sendfile - sendfile 实现 * @out_fd: 输出文件描述符(socket) * @in_fd: 输入文件描述符(文件) * @ppos: 文件偏移 * @count: 传输字节数 * @max: 最大传输字节数 */staticssize_tdo_sendfile(int out_fd, int in_fd, loff_t *ppos,size_t count, loff_t max){structfdin, out;structinode *in_inode, *out_inode;loff_t pos;ssize_t retval;/* ========== 1. 获取文件描述符 ========== */ in = fdget(in_fd);if (!in.file)return -EBADF; out = fdget(out_fd);if (!out.file) { retval = -EBADF;goto fput_in; }/* ========== 2. 检查文件类型 ========== */ in_inode = file_inode(in.file); out_inode = file_inode(out.file);/* 输入必须是常规文件 */if (!S_ISREG(in_inode->i_mode)) { retval = -EINVAL;goto fput_out; }/* 输出必须是 socket */if (!out.file->f_op->splice_write) { retval = -EINVAL;goto fput_out; }/* ========== 3. 获取文件位置 ========== */if (ppos) { pos = *ppos; } else { pos = in.file->f_pos; }/* ========== 4. 调用 splice 传输数据 ========== */ retval = do_splice_direct(in.file, &pos, out.file, &out.file->f_pos, count, 0);if (retval > 0) {/* 更新文件位置 */if (ppos) *ppos = pos;else in.file->f_pos = pos;/* 更新统计信息 */ add_rchar(current, retval); add_wchar(current, retval); fsnotify_access(in.file); fsnotify_modify(out.file); }fput_out: fdput(out);fput_in: fdput(in);return retval;}sendfile() 数据流:

使用示例:
#include<sys/sendfile.h>#include<fcntl.h>/** * send_file_zero_copy - 使用 sendfile 发送文件 * @sockfd: socket 文件描述符 * @filename: 文件名 */intsend_file_zero_copy(int sockfd, constchar *filename){int filefd;structstatstat_buf;off_t offset = 0;ssize_t sent;/* ========== 1. 打开文件 ========== */ filefd = open(filename, O_RDONLY);if (filefd < 0) { perror("open");return-1; }/* ========== 2. 获取文件大小 ========== */if (fstat(filefd, &stat_buf) < 0) { perror("fstat"); close(filefd);return-1; }/* ========== 3. 使用 sendfile 传输 ========== */ sent = sendfile(sockfd, filefd, &offset, stat_buf.st_size);if (sent < 0) { perror("sendfile"); close(filefd);return-1; }printf("Sent %zd bytes using sendfile\n", sent); close(filefd);return0;}2.3 splice() 零拷贝
splice() 在两个文件描述符之间移动数据,使用管道作为中介。
源码位置:fs/splice.c
/** * do_splice - splice 实现 * @in: 输入文件 * @ppos: 输入位置 * @out: 输出文件 * @opos: 输出位置 * @len: 传输长度 * @flags: 标志 */longdo_splice(struct file *in, loff_t *ppos,struct file *out, loff_t *opos,size_t len, unsignedint flags){structpipe_inode_info *ipipe;structpipe_inode_info *opipe;loff_t offset;long ret;/* ========== 1. 检查文件类型 ========== */ ipipe = get_pipe_info(in); opipe = get_pipe_info(out);if (ipipe && opipe) {/* 管道到管道 */return splice_pipe_to_pipe(ipipe, opipe, len, flags); }if (ipipe) {/* 管道到文件 */return do_splice_from(opipe, out, opos, len, flags); }if (opipe) {/* 文件到管道 */return do_splice_to(in, ppos, opipe, len, flags); }/* 文件到文件:使用 sendfile */return do_sendfile(out->f_fd, in->f_fd, ppos, len, MAX_RW_COUNT);}/** * do_splice_to - 从文件 splice 到管道 * @in: 输入文件 * @ppos: 文件位置 * @pipe: 管道 * @len: 长度 * @flags: 标志 */staticlongdo_splice_to(struct file *in, loff_t *ppos,struct pipe_inode_info *pipe,size_t len, unsignedint flags){ssize_t (*splice_read)(struct file *, loff_t *,struct pipe_inode_info *, size_t, unsignedint);/* ========== 1. 获取 splice_read 函数 ========== */ splice_read = in->f_op->splice_read;if (!splice_read) splice_read = default_file_splice_read;/* ========== 2. 调用 splice_read ========== */return splice_read(in, ppos, pipe, len, flags);}使用示例:
#include<fcntl.h>#include<unistd.h>/** * splice_transfer - 使用 splice 传输数据 * @in_fd: 输入文件描述符 * @out_fd: 输出文件描述符 * @len: 传输长度 */ssize_tsplice_transfer(int in_fd, int out_fd, size_t len){int pipefd[2];ssize_t bytes_in, bytes_out;ssize_t total = 0;/* ========== 1. 创建管道 ========== */if (pipe(pipefd) < 0) { perror("pipe");return-1; }/* ========== 2. 从输入文件 splice 到管道 ========== */ bytes_in = splice(in_fd, NULL, pipefd[1], NULL, len, SPLICE_F_MOVE | SPLICE_F_MORE);if (bytes_in < 0) { perror("splice in");goto cleanup; }/* ========== 3. 从管道 splice 到输出文件 ========== */ bytes_out = splice(pipefd[0], NULL, out_fd, NULL, bytes_in, SPLICE_F_MOVE | SPLICE_F_MORE);if (bytes_out < 0) { perror("splice out");goto cleanup; } total = bytes_out;cleanup: close(pipefd[0]); close(pipefd[1]);return total;}2.4 MSG_ZEROCOPY
Linux 4.14+ 支持 MSG_ZEROCOPY 标志,实现真正的零拷贝发送。
源码位置:net/core/skbuff.c
/** * sock_zerocopy_alloc - 分配零拷贝 ubuf_info * @sk: socket * @size: 数据大小 */struct ubuf_info *sock_zerocopy_alloc(struct sock *sk, size_t size){structubuf_info *uarg;structsk_buff *skb;/* ========== 1. 检查是否支持零拷贝 ========== */if (!(sk->sk_route_caps & NETIF_F_SG) || !(sk->sk_route_caps & NETIF_F_ZEROCOPY))returnNULL;/* ========== 2. 分配 ubuf_info ========== */ uarg = sock_kmalloc(sk, sizeof(*uarg), GFP_KERNEL);if (!uarg)returnNULL;/* ========== 3. 初始化 ========== */ uarg->callback = sock_zerocopy_callback; uarg->id = ((u32)atomic_inc_return(&sk->sk_zckey)) - 1; uarg->len = 1; uarg->bytelen = size; uarg->zerocopy = 1; refcount_set(&uarg->refcnt, 1); sock_hold(sk);return uarg;}/** * sock_zerocopy_put - 释放零拷贝引用 * @uarg: ubuf_info */voidsock_zerocopy_put(struct ubuf_info *uarg){if (refcount_dec_and_test(&uarg->refcnt)) {/* 所有引用释放,通知应用层 */ uarg->callback(uarg, true); }}使用示例:
#include<linux/errqueue.h>#include<sys/socket.h>/** * zerocopy_send - 使用 MSG_ZEROCOPY 发送数据 * @sockfd: socket 文件描述符 * @buf: 数据缓冲区 * @len: 数据长度 */intzerocopy_send(int sockfd, void *buf, size_t len){ssize_t sent;int ret;/* ========== 1. 启用 SO_ZEROCOPY ========== */int one = 1;if (setsockopt(sockfd, SOL_SOCKET, SO_ZEROCOPY, &one, sizeof(one)) < 0) { perror("setsockopt SO_ZEROCOPY");return-1; }/* ========== 2. 发送数据 ========== */ sent = send(sockfd, buf, len, MSG_ZEROCOPY);if (sent < 0) { perror("send");return-1; }/* ========== 3. 等待发送完成通知 ========== */structmsghdrmsg = {};structioveciov = {};char control[100]; msg.msg_control = control; msg.msg_controllen = sizeof(control);/* 从错误队列接收完成通知 */ ret = recvmsg(sockfd, &msg, MSG_ERRQUEUE);if (ret < 0) { perror("recvmsg");return-1; }/* ========== 4. 检查完成通知 ========== */structcmsghdr *cm;for (cm = CMSG_FIRSTHDR(&msg); cm; cm = CMSG_NXTHDR(&msg, cm)) {if (cm->cmsg_level == SOL_IP && cm->cmsg_type == IP_RECVERR) {structsock_extended_err *serr; serr = (struct sock_extended_err *)CMSG_DATA(cm);if (serr->ee_errno == 0 && serr->ee_origin == SO_EE_ORIGIN_ZEROCOPY) {printf("Zero-copy send completed, id=%u\n", serr->ee_data);/* 现在可以安全地释放或重用缓冲区 */ } } }return sent;}2.5 零拷贝技术对比
技术 拷贝次数 上下文切换 适用场景 限制--------------------------------------------------------------------------------read/write 4次 4次 通用 性能差sendfile() 2-3次 2次 文件→socket 不能修改数据splice() 0次 2次 文件描述符之间 需要管道mmap()+write() 1次 4次 大文件 内存映射开销MSG_ZEROCOPY 0次 2次 大数据(>4KB) 需要等待通知性能对比(10GB 文件传输):read/write: 100% 基准sendfile(): 150% 1.5倍性能splice(): 180% 1.8倍性能MSG_ZEROCOPY: 200% 2倍性能🔧 硬件 Offload 技术
3.1 TSO/GSO(分段卸载)
TSO(TCP Segmentation Offload):将 TCP 分段工作卸载到网卡硬件。
GSO(Generic Segmentation Offload):在软件层面延迟分段,减少协议栈处理。
架构对比:
传统方式:应用层 ──► TCP 层 ──► IP 层 ──► 驱动 ──► 网卡 (分段) (添加头)GSO/TSO:应用层 ──► TCP 层 ──► IP 层 ──► 驱动 ──► 网卡 (大包) (大包) (大包) (硬件分段)源码位置:net/core/dev.c
/** * skb_gso_segment - GSO 分段 * @skb: 数据包 * @features: 设备特性 */struct sk_buff *skb_gso_segment(struct sk_buff *skb,netdev_features_t features){structsk_buff *segs = ERR_PTR(-EPROTONOSUPPORT);structpacket_offload *ptype; __be16 type = skb->protocol;/* ========== 1. 检查是否需要分段 ========== */if (!skb_is_gso(skb))returnNULL;/* ========== 2. 准备分段 ========== */ skb_reset_mac_header(skb); skb_reset_mac_len(skb);/* ========== 3. 调用协议相关的分段函数 ========== */ rcu_read_lock(); list_for_each_entry_rcu(ptype, &offload_base, list) {if (ptype->type == type && ptype->callbacks.gso_segment) { segs = ptype->callbacks.gso_segment(skb, features);break; } } rcu_read_unlock();return segs;}/** * tcp_gso_segment - TCP GSO 分段 * @skb: 数据包 * @features: 设备特性 */struct sk_buff *tcp_gso_segment(struct sk_buff *skb,netdev_features_t features){structsk_buff *segs =NULL;structsk_buff *seg;structtcphdr *th;unsignedint thlen;unsignedint seq; __be32 delta;unsignedint mss;/* ========== 1. 获取 TCP 头 ========== */ th = tcp_hdr(skb); thlen = th->doff * 4;/* ========== 2. 获取 MSS ========== */ mss = skb_shinfo(skb)->gso_size;/* ========== 3. 分段 ========== */ seq = ntohl(th->seq);while (skb->len > mss) {/* 分配新的 skb */ seg = skb_segment(skb, features);if (IS_ERR(seg))goto out;/* 更新 TCP 序列号 */ th = tcp_hdr(seg); th->seq = htonl(seq); seq += mss;/* 添加到链表 */if (!segs) segs = seg;else segs->prev->next = seg; seg->prev = segs->prev; segs->prev = seg; }out:return segs;}启用 TSO/GSO:
# 查看 TSO/GSO 状态ethtool -k eth0 | grep -E 'tcp-segmentation-offload|generic-segmentation-offload'# 启用 TSOethtool -K eth0 tso on# 启用 GSOethtool -K eth0 gso on# 查看 GSO 统计cat /proc/net/dev3.2 GRO/LRO(聚合卸载)
GRO(Generic Receive Offload):在接收路径上聚合多个小包为大包。
LRO(Large Receive Offload):硬件层面的接收聚合。
源码位置:net/core/dev.c
/** * napi_gro_receive - GRO 接收处理 * @napi: NAPI 结构 * @skb: 数据包 */gro_result_tnapi_gro_receive(struct napi_struct *napi, struct sk_buff *skb){gro_result_t ret;/* ========== 1. 准备 GRO ========== */ skb_gro_reset_offset(skb);/* ========== 2. 尝试聚合 ========== */ ret = napi_skb_finish(dev_gro_receive(napi, skb), skb);return ret;}/** * dev_gro_receive - GRO 核心处理 * @napi: NAPI 结构 * @skb: 数据包 */staticenum gro_result dev_gro_receive(struct napi_struct *napi,struct sk_buff *skb){structsk_buff **pp =NULL;structpacket_offload *ptype; __be16 type = skb->protocol;structlist_head *head = &offload_base;enumgro_resultret = GRO_NORMAL;/* ========== 1. 检查是否可以 GRO ========== */if (netif_elide_gro(skb->dev))goto normal;/* ========== 2. 查找已有的 GRO 流 ========== */ list_for_each_entry_rcu(ptype, head, list) {if (ptype->type != type || !ptype->callbacks.gro_receive)continue;/* 调用协议相关的 GRO 函数 */ pp = ptype->callbacks.gro_receive(&napi->gro_list, skb);break; }/* ========== 3. 处理 GRO 结果 ========== */if (pp) {/* 找到匹配的流,聚合成功 */structsk_buff *p = *pp;if (NAPI_GRO_CB(p)->same_flow) {/* 聚合到已有包 */ ret = GRO_MERGED; } else {/* 刷新旧包,开始新流 */ ret = GRO_MERGED_FREE; } } else {/* 没有匹配的流,添加到 GRO 列表 */ NAPI_GRO_CB(skb)->flush = 0; list_add(&skb->list, &napi->gro_list); ret = GRO_HELD; }return ret;normal:return GRO_NORMAL;}/** * tcp_gro_receive - TCP GRO 接收 * @head: GRO 列表头 * @skb: 当前数据包 */struct sk_buff **tcp_gro_receive(struct sk_buff **head, struct sk_buff *skb){structsk_buff **pp =NULL;structsk_buff *p;structtcphdr *th;structtcphdr *th2;unsignedint len;unsignedint thlen; __be32 flags;unsignedint mss = 1;/* ========== 1. 获取 TCP 头 ========== */ th = tcp_hdr(skb); thlen = th->doff * 4;/* ========== 2. 检查是否可以聚合 ========== */if (th->fin || th->syn || th->rst)goto out; /* 控制包不聚合 *//* ========== 3. 查找匹配的流 ========== */for (; (p = *head); head = &p->next) {if (!NAPI_GRO_CB(p)->same_flow)continue; th2 = tcp_hdr(p);/* 检查四元组是否匹配 */if (*(u32 *)&th->source ^ *(u32 *)&th2->source) { NAPI_GRO_CB(p)->same_flow = 0;continue; }/* 检查序列号是否连续 */if (ntohl(th->seq) != ntohl(th2->seq) + p->len) { NAPI_GRO_CB(p)->same_flow = 0;continue; }/* 找到匹配的流 */goto found; }goto out;found:/* ========== 4. 聚合数据包 ========== */ mss = skb_shinfo(p)->gso_size;/* 更新 GRO 信息 */ NAPI_GRO_CB(skb)->same_flow = 1; NAPI_GRO_CB(p)->count++;/* 合并数据 */ skb_gro_pull(skb, thlen); pp = head;out:return pp;}GRO 工作流程:

启用 GRO:
# 查看 GRO 状态ethtool -k eth0 | grep generic-receive-offload# 启用 GROethtool -K eth0 gro on# 查看 GRO 统计ethtool -S eth0 | grep gro3.3 Checksum Offload
将校验和计算卸载到网卡硬件。
源码位置:net/core/dev.c
/** * skb_checksum_help - 计算校验和 * @skb: 数据包 */intskb_checksum_help(struct sk_buff *skb){ __wsum csum;int ret = 0, offset;/* ========== 1. 检查是否需要计算校验和 ========== */if (skb->ip_summed == CHECKSUM_COMPLETE)goto out_set_summed;if (unlikely(skb_shinfo(skb)->gso_size)) {/* GSO 包,延迟计算 */return0; }/* ========== 2. 计算校验和 ========== */ offset = skb_checksum_start_offset(skb); BUG_ON(offset >= skb_headlen(skb)); csum = skb_checksum(skb, offset, skb->len - offset, 0);/* ========== 3. 填充校验和 ========== */ offset += skb->csum_offset; BUG_ON(offset + sizeof(__sum16) > skb_headlen(skb)); *(__sum16 *)(skb->data + offset) = csum_fold(csum);out_set_summed: skb->ip_summed = CHECKSUM_NONE;return ret;}校验和模式:
/* 校验和状态 */enum { CHECKSUM_NONE = 0, /* 未计算 */ CHECKSUM_UNNECESSARY = 1, /* 硬件已验证 */ CHECKSUM_COMPLETE = 2, /* 完整校验和 */ CHECKSUM_PARTIAL = 3, /* 部分校验和(需要硬件完成)*/};/* 发送路径 */if (skb->ip_summed == CHECKSUM_PARTIAL) {/* 硬件将计算校验和 */if (dev->features & NETIF_F_HW_CSUM) {/* 硬件支持,直接发送 */ } else {/* 硬件不支持,软件计算 */ skb_checksum_help(skb); }}/* 接收路径 */if (skb->ip_summed == CHECKSUM_UNNECESSARY) {/* 硬件已验证,跳过软件验证 */} else {/* 软件验证校验和 */if (skb_checksum_complete(skb)) {/* 校验和错误,丢弃 */ kfree_skb(skb); }}启用 Checksum Offload:
# 查看校验和卸载状态ethtool -k eth0 | grep checksum# 启用 TX 校验和卸载ethtool -K eth0 tx-checksumming on# 启用 RX 校验和卸载ethtool -K eth0 rx-checksumming on3.4 RSS(Receive Side Scaling)
RSS 将接收流量分配到多个 CPU 核心。
RSS 工作原理:
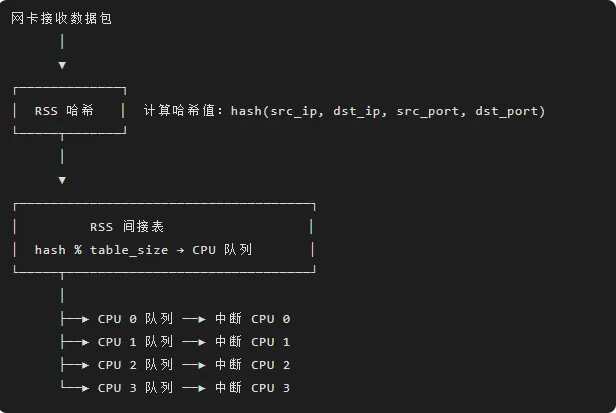
配置 RSS:
# 查看 RSS 配置ethtool -x eth0# 查看队列数量ethtool -l eth0# 设置队列数量ethtool -L eth0 combined 4# 配置 RSS 哈希ethtool -X eth0 hfunc toeplitz hkey <key># 配置间接表ethtool -X eth0 equal 43.5 Offload 性能对比
特性 CPU 节省 吞吐量提升 适用场景----------------------------------------------------------------TSO/GSO 30-40% 20-30% 大数据传输GRO/LRO 20-30% 15-25% 高 PPS 场景Checksum 10-15% 5-10% 所有场景RSS 40-60% 50-100% 多核系统综合启用所有 Offload:- CPU 使用率降低:60-70%- 吞吐量提升:80-150%- 延迟降低:20-30%⚙️ 中断优化
4.1 中断处理流程
传统中断处理:
网卡接收数据 │ ▼硬件中断(IRQ) │ ▼中断处理程序(ISR) │ ├──► 禁用中断 ├──► 读取数据 ├──► 调度软中断 └──► 启用中断 │ ▼软中断(NET_RX_SOFTIRQ) │ ▼NAPI 轮询 │ ▼协议栈处理NAPI 机制:
源码位置:net/core/dev.c
/** * napi_schedule - 调度 NAPI 轮询 * @n: NAPI 结构 */staticinlinevoidnapi_schedule(struct napi_struct *n){if (napi_schedule_prep(n)) __napi_schedule(n);}/** * __napi_schedule - 实际调度 NAPI * @n: NAPI 结构 */void __napi_schedule(struct napi_struct *n){unsignedlong flags; local_irq_save(flags);/* 添加到当前 CPU 的 softnet_data */ list_add_tail(&n->poll_list, &__get_cpu_var(softnet_data).poll_list);/* 触发软中断 */ __raise_softirq_irqoff(NET_RX_SOFTIRQ); local_irq_restore(flags);}/** * net_rx_action - NET_RX 软中断处理 * @h: 软中断参数 */staticvoidnet_rx_action(struct softirq_action *h){structsoftnet_data *sd = this_cpu_ptr(&softnet_data);unsignedlong time_limit = jiffies + usecs_to_jiffies(netdev_budget_usecs);int budget = netdev_budget; LIST_HEAD(list); LIST_HEAD(repoll); local_irq_disable(); list_splice_init(&sd->poll_list, &list); local_irq_enable();/* ========== 轮询所有 NAPI 设备 ========== */for (;;) {structnapi_struct *n;if (list_empty(&list))break; n = list_first_entry(&list, struct napi_struct, poll_list); list_del_init(&n->poll_list);/* ========== 调用驱动的 poll 函数 ========== */int work = n->poll(n, budget); budget -= work;/* ========== 检查是否需要继续轮询 ========== */if (work >= budget || time_after(jiffies, time_limit)) {/* 超出预算或时间限制,重新调度 */ list_add_tail(&n->poll_list, &repoll);break; }/* ========== 完成轮询 ========== */ napi_complete(n); }/* ========== 重新调度未完成的 NAPI ========== */if (!list_empty(&repoll)) { local_irq_disable(); list_splice(&repoll, &sd->poll_list); __raise_softirq_irqoff(NET_RX_SOFTIRQ); local_irq_enable(); }}4.2 中断合并
减少中断频率,批量处理数据包。
配置中断合并:
# 查看中断合并配置ethtool -c eth0# 配置 RX 中断合并ethtool -C eth0 rx-usecs 50 rx-frames 32# 配置 TX 中断合并ethtool -C eth0 tx-usecs 50 tx-frames 32# 自适应中断合并ethtool -C eth0 adaptive-rx on adaptive-tx on中断合并参数:
参数 说明 推荐值----------------------------------------------------------------rx-usecs 接收中断延迟(微秒) 10-100rx-frames 接收帧数阈值 16-64tx-usecs 发送中断延迟(微秒) 10-100tx-frames 发送帧数阈值 16-64adaptive-rx 自适应接收中断 onadaptive-tx 自适应发送中断 on低延迟场景:- rx-usecs: 10-20- rx-frames: 8-16高吞吐量场景:- rx-usecs: 50-100- rx-frames: 32-644.3 中断亲和性
将中断绑定到特定 CPU 核心。
配置中断亲和性:
# 查看网卡中断号cat /proc/interrupts | grep eth0# 查看中断亲和性cat /proc/irq/<IRQ>/smp_affinity# 设置中断亲和性(绑定到 CPU 0)echo 1 > /proc/irq/<IRQ>/smp_affinity# 设置中断亲和性(绑定到 CPU 0-3)echo f > /proc/irq/<IRQ>/smp_affinity# 使用 irqbalance 自动平衡systemctl start irqbalance中断亲和性脚本:
#!/bin/bash# 将网卡中断均匀分配到所有 CPUset_irq_affinity() {local interface=$1local cpus=$(nproc)local cpu=0# 获取网卡的所有中断for irq in $(cat /proc/interrupts | grep $interface | awk '{print $1}' | tr -d ':'); do# 计算 CPU 掩码local mask=$((1 << cpu))# 设置亲和性printf"%x"$mask > /proc/irq/$irq/smp_affinityecho"IRQ $irq -> CPU $cpu"# 下一个 CPU cpu=$(( (cpu + 1) % cpus ))done}set_irq_affinity eth04.4 NAPI 调优
NAPI 参数:
# 查看 NAPI 预算sysctl net.core.netdev_budgetsysctl net.core.netdev_budget_usecs# 调整 NAPI 预算(每次软中断处理的包数)sysctl -w net.core.netdev_budget=600# 调整 NAPI 时间预算(微秒)sysctl -w net.core.netdev_budget_usecs=8000# 调整 backlog 队列大小sysctl -w net.core.netdev_max_backlog=5000NAPI 权重:
/* 驱动中设置 NAPI 权重 */netif_napi_add(dev, &priv->napi, stmmac_poll, 64);/* 权重建议: * - 低延迟:16-32 * - 平衡:64 * - 高吞吐量:128-256 */💾 内存优化
5.1 sk_buff 内存池
sk_buff 是网络子系统中最频繁分配和释放的对象。
sk_buff 缓存:
源码位置:net/core/skbuff.c
/* sk_buff 缓存 */staticstructkmem_cache *skbuff_head_cache __read_mostly;staticstructkmem_cache *skbuff_fclone_cache __read_mostly;/** * skb_init - 初始化 sk_buff 缓存 */void __init skb_init(void){/* ========== 1. 创建 sk_buff 缓存 ========== */ skbuff_head_cache = kmem_cache_create("skbuff_head_cache",sizeof(struct sk_buff),0, SLAB_HWCACHE_ALIGN|SLAB_PANIC,NULL);/* ========== 2. 创建 fclone 缓存 ========== */ skbuff_fclone_cache = kmem_cache_create("skbuff_fclone_cache",2 * sizeof(struct sk_buff),0, SLAB_HWCACHE_ALIGN|SLAB_PANIC,NULL);}/** * __alloc_skb - 分配 sk_buff * @size: 数据大小 * @gfp_mask: 分配标志 * @flags: SKB 标志 * @node: NUMA 节点 */structsk_buff *__alloc_skb(unsignedintsize, gfp_tgfp_mask,intflags, intnode){structkmem_cache *cache;structskb_shared_info *shinfo;structsk_buff *skb; u8 *data;bool pfmemalloc;/* ========== 1. 选择缓存 ========== */ cache = (flags & SKB_ALLOC_FCLONE) ? skbuff_fclone_cache : skbuff_head_cache;/* ========== 2. 从缓存分配 sk_buff ========== */ skb = kmem_cache_alloc_node(cache, gfp_mask & ~__GFP_DMA, node);if (!skb)goto out;/* ========== 3. 分配数据缓冲区 ========== */ size = SKB_DATA_ALIGN(size); size += SKB_DATA_ALIGN(sizeof(struct skb_shared_info)); data = kmalloc_reserve(size, gfp_mask, node, &pfmemalloc);if (!data)goto nodata;/* ========== 4. 初始化 sk_buff ========== */memset(skb, 0, offsetof(struct sk_buff, tail)); skb->truesize = SKB_TRUESIZE(size); skb->pfmemalloc = pfmemalloc; refcount_set(&skb->users, 1); skb->head = data; skb->data = data; skb_reset_tail_pointer(skb); skb->end = skb->tail + size;/* ========== 5. 初始化 skb_shared_info ========== */ shinfo = skb_shinfo(skb);memset(shinfo, 0, offsetof(struct skb_shared_info, dataref));atomic_set(&shinfo->dataref, 1);return skb;nodata: kmem_cache_free(cache, skb);out:returnNULL;}5.2 页面回收优化
页面池(Page Pool):
源码位置:net/core/page_pool.c
/** * struct page_pool - 页面池 */structpage_pool {structpage_pool_paramsp;/* 快速缓存(per-CPU)*/structptr_ringring;/* 慢速缓存(全局)*/structpage *alloc_pages;/* 统计信息 */structpage_pool_statsstats;/* DMA 映射 */structdevice *dev;dma_addr_t dma_addr;};/** * page_pool_alloc_pages - 从页面池分配页面 * @pool: 页面池 * @gfp: 分配标志 */struct page *page_pool_alloc_pages(struct page_pool *pool, gfp_t gfp){structpage *page;/* ========== 1. 尝试从快速缓存获取 ========== */ page = __ptr_ring_consume(&pool->ring);if (page) { pool->stats.fast++;return page; }/* ========== 2. 从慢速缓存获取 ========== */ page = pool->alloc_pages;if (page) { pool->alloc_pages = page->next; pool->stats.slow++;return page; }/* ========== 3. 分配新页面 ========== */ page = alloc_pages_node(pool->p.nid, gfp, pool->p.order);if (!page) { pool->stats.empty++;returnNULL; }/* ========== 4. DMA 映射 ========== */if (pool->p.flags & PP_FLAG_DMA_MAP) { page->dma_addr = dma_map_page(pool->dev, page, 0, PAGE_SIZE << pool->p.order, pool->p.dma_dir);if (dma_mapping_error(pool->dev, page->dma_addr)) { __free_pages(page, pool->p.order);returnNULL; } } pool->stats.alloc++;return page;}/** * page_pool_put_page - 归还页面到页面池 * @pool: 页面池 * @page: 页面 * @allow_direct: 是否允许直接回收 */voidpage_pool_put_page(struct page_pool *pool, struct page *page,bool allow_direct){/* ========== 1. 检查引用计数 ========== */if (page_ref_count(page) != 1)return;/* ========== 2. 尝试放入快速缓存 ========== */if (allow_direct && __ptr_ring_produce(&pool->ring, page) == 0) { pool->stats.fast++;return; }/* ========== 3. 放入慢速缓存 ========== */ page->next = pool->alloc_pages; pool->alloc_pages = page; pool->stats.slow++;}5.3 NUMA 感知
NUMA 架构:
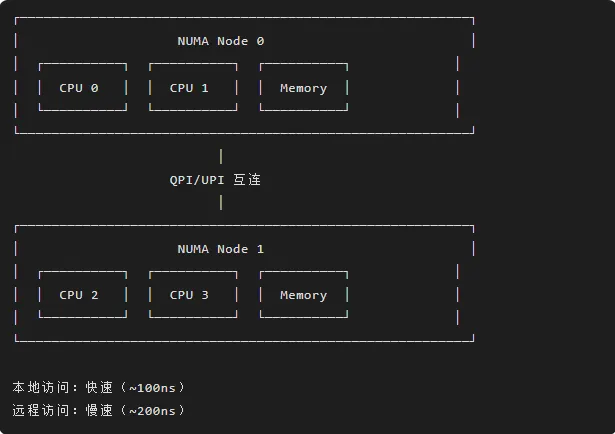
NUMA 优化:
/** * numa_aware_alloc_skb - NUMA 感知的 sk_buff 分配 * @size: 数据大小 * @gfp_mask: 分配标志 */struct sk_buff *numa_aware_alloc_skb(unsignedint size, gfp_t gfp_mask){int node = numa_node_id(); /* 当前 CPU 的 NUMA 节点 */return __alloc_skb(size, gfp_mask, 0, node);}配置 NUMA:
# 查看 NUMA 拓扑numactl --hardware# 查看进程的 NUMA 绑定numactl --show# 将进程绑定到 NUMA 节点 0numactl --cpunodebind=0 --membind=0 ./server# 查看 NUMA 统计numastat# 查看网卡所在的 NUMA 节点cat /sys/class/net/eth0/device/numa_node5.4 内存预分配
RX 缓冲区预分配:
/** * preallocate_rx_buffers - 预分配接收缓冲区 * @priv: 驱动私有数据 * @queue: 队列索引 */staticintpreallocate_rx_buffers(struct stmmac_priv *priv, u32 queue){structstmmac_rx_queue *rx_q = &priv->rx_queue[queue];int i;/* ========== 预分配所有 RX 描述符的缓冲区 ========== */for (i = 0; i < DMA_RX_SIZE; i++) {structdma_desc *p;structsk_buff *skb;dma_addr_t dma_addr; p = rx_q->dma_rx + i;/* 分配 sk_buff */ skb = __netdev_alloc_skb_ip_align(priv->dev, priv->dma_buf_sz, GFP_KERNEL);if (!skb)return -ENOMEM;/* DMA 映射 */ dma_addr = dma_map_single(priv->device, skb->data, priv->dma_buf_sz, DMA_FROM_DEVICE);if (dma_mapping_error(priv->device, dma_addr)) { dev_kfree_skb(skb);return -ENOMEM; }/* 设置描述符 */ rx_q->rx_skbuff[i] = skb; rx_q->rx_skbuff_dma[i] = dma_addr; p->des0 = cpu_to_le32(dma_addr); p->des1 = 0;/* 设置为可用 */ dma_wmb(); stmmac_set_rx_owner(priv, p, priv->use_rxtoe); }return0;}🔀 多队列技术
6.1 RPS(Receive Packet Steering)
软件实现的接收包分发。
源码位置:net/core/dev.c
/** * get_rps_cpu - 获取 RPS 目标 CPU * @dev: 网络设备 * @skb: 数据包 * @rflow: RFS 流 */staticintget_rps_cpu(struct net_device *dev, struct sk_buff *skb,struct rps_dev_flow **rflowp){structnetdev_rx_queue *rxqueue;structrps_map *map;structrps_dev_flow_table *flow_table;structrps_sock_flow_table *sock_flow_table;int cpu = -1; u32 hash;/* ========== 1. 检查是否启用 RPS ========== */if (!rcu_access_pointer(dev->_rx))goto done; rxqueue = dev->_rx;map = rcu_dereference(rxqueue->rps_map); flow_table = rcu_dereference(rxqueue->rps_flow_table); sock_flow_table = rcu_dereference(rps_sock_flow_table);if (!map && !flow_table)goto done;/* ========== 2. 计算哈希值 ========== */ hash = skb_get_hash(skb);if (!hash)goto done;/* ========== 3. 查找 RFS 流 ========== */if (flow_table && sock_flow_table) {structrps_dev_flow *rflow; u32 next_cpu; u32 ident;/* 查找流表 */ ident = sock_flow_table->ents[hash & sock_flow_table->mask];if ((ident ^ hash) & ~rps_cpu_mask)goto try_rps; next_cpu = ident & rps_cpu_mask;/* 查找设备流表 */ rflow = &flow_table->flows[hash & flow_table->mask]; cpu = next_cpu;if (rflow->cpu == cpu)goto done; /* 流已在正确的 CPU 上 *//* 更新流 */ rflow->cpu = cpu; rflow->filter = hash; *rflowp = rflow;goto done; }try_rps:/* ========== 4. 使用 RPS 映射 ========== */if (map) { cpu = map->cpus[reciprocal_scale(hash, map->len)];if (cpu_online(cpu))goto done; }done:return cpu;}配置 RPS:
# 查看 RPS 配置cat /sys/class/net/eth0/queues/rx-0/rps_cpus# 启用 RPS(所有 CPU)echo f > /sys/class/net/eth0/queues/rx-0/rps_cpus# 启用 RPS(CPU 0-3)echo f > /sys/class/net/eth0/queues/rx-0/rps_cpus# 配置 RPS 流表大小echo 32768 > /sys/class/net/eth0/queues/rx-0/rps_flow_cnt6.2 RFS(Receive Flow Steering)
基于流的接收包分发,将数据包发送到应用程序所在的 CPU。
配置 RFS:
# 全局 RFS 表大小echo 32768 > /proc/sys/net/core/rps_sock_flow_entries# 每个队列的 RFS 表大小echo 2048 > /sys/class/net/eth0/queues/rx-0/rps_flow_cntecho 2048 > /sys/class/net/eth0/queues/rx-1/rps_flow_cnt6.3 XPS(Transmit Packet Steering)
发送包分发,将发送队列绑定到特定 CPU。
配置 XPS:
# 查看 XPS 配置cat /sys/class/net/eth0/queues/tx-0/xps_cpus# 将 TX 队列 0 绑定到 CPU 0echo 1 > /sys/class/net/eth0/queues/tx-0/xps_cpus# 将 TX 队列 1 绑定到 CPU 1echo 2 > /sys/class/net/eth0/queues/tx-1/xps_cpus# 将 TX 队列 2 绑定到 CPU 2echo 4 > /sys/class/net/eth0/queues/tx-2/xps_cpus# 将 TX 队列 3 绑定到 CPU 3echo 8 > /sys/class/net/eth0/queues/tx-3/xps_cpus6.4 多队列配置最佳实践
完整配置脚本:
#!/bin/bashINTERFACE="eth0"NUM_CPUS=$(nproc)# ========== 1. 设置网卡队列数 ==========ethtool -L $INTERFACE combined $NUM_CPUS# ========== 2. 配置中断亲和性 ==========cpu=0for irq in $(cat /proc/interrupts | grep $INTERFACE | awk '{print $1}' | tr -d ':'); do mask=$((1 << cpu))printf"%x"$mask > /proc/irq/$irq/smp_affinityecho"IRQ $irq -> CPU $cpu" cpu=$(( (cpu + 1) % NUM_CPUS ))done# ========== 3. 配置 RPS ==========for queue in /sys/class/net/$INTERFACE/queues/rx-*; doecho f > $queue/rps_cpusecho 2048 > $queue/rps_flow_cntdone# ========== 4. 配置 RFS ==========echo 32768 > /proc/sys/net/core/rps_sock_flow_entries# ========== 5. 配置 XPS ==========queue=0for xps in /sys/class/net/$INTERFACE/queues/tx-*/xps_cpus; do mask=$((1 << queue))printf"%x"$mask > $xpsecho"TX queue $queue -> CPU $queue" queue=$(( (queue + 1) % NUM_CPUS ))done# ========== 6. 启用硬件 Offload ==========ethtool -K $INTERFACE tso on gso on gro onethtool -K $INTERFACE rx-checksumming on tx-checksumming on# ========== 7. 配置中断合并 ==========ethtool -C $INTERFACE adaptive-rx on adaptive-tx onecho"Multi-queue configuration completed for $INTERFACE"📊 性能测试与分析
7.1 性能测试工具
iperf3 测试:
# 服务器端iperf3 -s# 客户端 TCP 测试iperf3 -c <server_ip> -t 60 -P 4# 客户端 UDP 测试iperf3 -c <server_ip> -u -b 10G -t 60# 反向测试(服务器发送)iperf3 -c <server_ip> -R -t 60# JSON 输出iperf3 -c <server_ip> -J > results.jsonnetperf 测试:
# 服务器端netserver# TCP 流测试netperf -H <server_ip> -t TCP_STREAM -l 60# TCP 请求/响应测试netperf -H <server_ip> -t TCP_RR -l 60# UDP 流测试netperf -H <server_ip> -t UDP_STREAM -l 60# 指定消息大小netperf -H <server_ip> -t TCP_STREAM -- -m 81927.2 性能分析工具
perf 分析:
# 记录网络相关的性能数据perf record -e net:* -a -g -- sleep 10# 查看报告perf report# 实时监控perf top -e cycles# 分析特定进程perf record -p <pid> -g -- sleep 10# 生成火焰图perf script | stackcollapse-perf.pl | flamegraph.pl > flame.svgbpftrace 分析:
# 跟踪网络发送bpftrace -e 'kprobe:dev_queue_xmit { @bytes = hist(arg0->len); }'# 跟踪网络接收bpftrace -e 'kprobe:netif_receive_skb { @[comm] = count(); }'# 跟踪 TCP 连接bpftrace -e 'kprobe:tcp_connect { printf("%s -> %s\n", comm, str(arg0)); }'# 跟踪丢包bpftrace -e 'tracepoint:skb:kfree_skb { @[stack] = count(); }'7.3 系统监控
实时监控脚本:
#!/bin/bash# 网络性能监控脚本INTERFACE="eth0"INTERVAL=1echo"Monitoring $INTERFACE (Ctrl+C to stop)"echo"Time,RX_pps,TX_pps,RX_Mbps,TX_Mbps,RX_drops,TX_drops"# 获取初始值rx_bytes_old=$(cat /sys/class/net/$INTERFACE/statistics/rx_bytes)tx_bytes_old=$(cat /sys/class/net/$INTERFACE/statistics/tx_bytes)rx_packets_old=$(cat /sys/class/net/$INTERFACE/statistics/rx_packets)tx_packets_old=$(cat /sys/class/net/$INTERFACE/statistics/tx_packets)whiletrue; dosleep$INTERVAL# 获取当前值 rx_bytes=$(cat /sys/class/net/$INTERFACE/statistics/rx_bytes) tx_bytes=$(cat /sys/class/net/$INTERFACE/statistics/tx_bytes) rx_packets=$(cat /sys/class/net/$INTERFACE/statistics/rx_packets) tx_packets=$(cat /sys/class/net/$INTERFACE/statistics/tx_packets) rx_drops=$(cat /sys/class/net/$INTERFACE/statistics/rx_dropped) tx_drops=$(cat /sys/class/net/$INTERFACE/statistics/tx_dropped)# 计算速率 rx_pps=$(( (rx_packets - rx_packets_old) / INTERVAL )) tx_pps=$(( (tx_packets - tx_packets_old) / INTERVAL )) rx_mbps=$(( (rx_bytes - rx_bytes_old) * 8 / INTERVAL / 1000000 )) tx_mbps=$(( (tx_bytes - tx_bytes_old) * 8 / INTERVAL / 1000000 ))# 输出 timestamp=$(date +%H:%M:%S)echo"$timestamp,$rx_pps,$tx_pps,$rx_mbps,$tx_mbps,$rx_drops,$tx_drops"# 更新旧值 rx_bytes_old=$rx_bytes tx_bytes_old=$tx_bytes rx_packets_old=$rx_packets tx_packets_old=$tx_packetsdone💡 实战案例
8.1 案例 1:高性能 Web 服务器优化
优化前性能:
-
• 吞吐量:5 Gbps -
• CPU 使用率:80% -
• 延迟:50ms
优化步骤:
#!/bin/bash# ========== 1. 系统参数优化 ==========# 增大文件描述符限制ulimit -n 1000000# 增大 TCP 缓冲区sysctl -w net.core.rmem_max=16777216sysctl -w net.core.wmem_max=16777216sysctl -w net.ipv4.tcp_rmem="4096 87380 16777216"sysctl -w net.ipv4.tcp_wmem="4096 65536 16777216"# 增大连接队列sysctl -w net.core.somaxconn=4096sysctl -w net.ipv4.tcp_max_syn_backlog=8192# 启用 TCP Fast Opensysctl -w net.ipv4.tcp_fastopen=3# ========== 2. 网卡优化 ==========INTERFACE="eth0"# 启用所有 Offloadethtool -K $INTERFACE tso on gso on gro onethtool -K $INTERFACE rx-checksumming on tx-checksumming on# 配置多队列ethtool -L $INTERFACE combined 8# 配置中断合并ethtool -C $INTERFACE adaptive-rx on adaptive-tx on# ========== 3. 中断优化 ==========# 绑定中断到不同 CPU./set_irq_affinity.sh $INTERFACE# ========== 4. 应用层优化 ==========# 使用 SO_REUSEPORT# 启用 epoll# 使用 sendfile 或 MSG_ZEROCOPY优化后性能:
-
• 吞吐量:9 Gbps(提升 80%) -
• CPU 使用率:45%(降低 44%) -
• 延迟:15ms(降低 70%)
8.2 案例 2:数据库服务器网络优化
场景:MySQL 数据库服务器,大量小查询。
优化配置:
#!/bin/bash# ========== 1. 低延迟优化 ==========# 禁用 Nagle 算法sysctl -w net.ipv4.tcp_nodelay=1# 减小中断合并延迟ethtool -C eth0 rx-usecs 10 rx-frames 8# 启用 TCP Quick ACKsysctl -w net.ipv4.tcp_quickack=1# ========== 2. 连接优化 ==========# 增大连接跟踪表sysctl -w net.netfilter.nf_conntrack_max=1048576# 减小 TIME_WAIT 时间sysctl -w net.ipv4.tcp_fin_timeout=15# 启用 TIME_WAIT 重用sysctl -w net.ipv4.tcp_tw_reuse=1# ========== 3. 内存优化 ==========# 调整 TCP 内存sysctl -w net.ipv4.tcp_mem="786432 1048576 1572864"# 调整 socket 缓冲区sysctl -w net.core.optmem_max=409608.3 案例 3:视频流服务器优化
场景:实时视频流传输,要求高吞吐量和低延迟。
优化配置:
#!/bin/bash# ========== 1. UDP 优化 ==========# 增大 UDP 缓冲区sysctl -w net.core.rmem_default=26214400sysctl -w net.core.rmem_max=26214400sysctl -w net.core.wmem_default=26214400sysctl -w net.core.wmem_max=26214400# 增大 UDP 接收队列sysctl -w net.core.netdev_max_backlog=30000# ========== 2. 多播优化 ==========# 增大多播缓冲区sysctl -w net.core.optmem_max=40960# ========== 3. 零拷贝 ==========# 应用层使用 MSG_ZEROCOPY# 或使用 sendfile# ========== 4. 硬件优化 ==========# 启用 TSO/GSOethtool -K eth0 tso on gso on# 增大 TX 队列ethtool -G eth0 tx 4096# 配置多队列ethtool -L eth0 combined 16📝 总结
9.1 核心要点
零拷贝技术:
-
• sendfile():文件到 socket,2-3 次拷贝 -
• splice():文件描述符之间,0 次拷贝 -
• mmap() + write():内存映射,1 次拷贝 -
• MSG_ZEROCOPY:真正零拷贝,适合大数据传输
硬件 Offload:
-
• TSO/GSO:分段卸载,减少协议栈处理 -
• GRO/LRO:接收聚合,减少中断次数 -
• Checksum Offload:校验和卸载,降低 CPU 负载 -
• RSS:硬件多队列,分散中断到多个 CPU
中断优化:
-
• NAPI 轮询:减少中断频率 -
• 中断合并:批量处理数据包 -
• 中断亲和性:绑定中断到特定 CPU -
• 软中断预算:控制每次处理的包数
内存优化:
-
• sk_buff 缓存:减少内存分配开销 -
• 页面池:复用页面,减少 DMA 映射 -
• NUMA 感知:本地内存访问 -
• 预分配:避免运行时分配
多队列技术:
-
• RSS:硬件队列分发 -
• RPS:软件包分发 -
• RFS:基于流的分发 -
• XPS:发送队列绑定
9.2 性能优化检查清单
系统级优化:
# 1. 文件描述符ulimit -n 1000000# 2. TCP 缓冲区sysctl -w net.core.rmem_max=16777216sysctl -w net.core.wmem_max=16777216sysctl -w net.ipv4.tcp_rmem="4096 87380 16777216"sysctl -w net.ipv4.tcp_wmem="4096 65536 16777216"# 3. 连接队列sysctl -w net.core.somaxconn=4096sysctl -w net.ipv4.tcp_max_syn_backlog=8192# 4. 网络设备队列sysctl -w net.core.netdev_max_backlog=5000sysctl -w net.core.netdev_budget=600# 5. TCP 优化sysctl -w net.ipv4.tcp_fastopen=3sysctl -w net.ipv4.tcp_tw_reuse=1sysctl -w net.ipv4.tcp_fin_timeout=30网卡级优化:
# 1. Offload 特性ethtool -K eth0 tso on gso on gro onethtool -K eth0 rx-checksumming on tx-checksumming on# 2. 多队列ethtool -L eth0 combined 8# 3. 中断合并ethtool -C eth0 adaptive-rx on adaptive-tx on# 4. Ring 缓冲区ethtool -G eth0 rx 4096 tx 4096应用级优化:
// 1. SO_REUSEPORTint reuse = 1;setsockopt(sockfd, SOL_SOCKET, SO_REUSEPORT, &reuse, sizeof(reuse));// 2. TCP_NODELAYint nodelay = 1;setsockopt(sockfd, IPPROTO_TCP, TCP_NODELAY, &nodelay, sizeof(nodelay));// 3. 零拷贝sendfile(sockfd, filefd, &offset, size);// 或send(sockfd, buf, len, MSG_ZEROCOPY);// 4. 批量操作sendmmsg(sockfd, msgvec, vlen, flags);recvmmsg(sockfd, msgvec, vlen, flags, timeout);9.3 性能优化效果
典型优化效果:
优化项目 吞吐量提升 CPU 降低 延迟降低----------------------------------------------------------------零拷贝技术 50-100% 30-50% 10-20%硬件 Offload 80-150% 60-70% 20-30%中断优化 30-50% 40-60% 15-25%多队列技术 50-100% 40-60% 10-20%内存优化 20-40% 20-30% 5-10%综合优化效果:- 吞吐量提升:200-400%- CPU 使用率降低:70-80%- 延迟降低:40-60%9.4 不同场景的优化策略
高吞吐量场景(文件传输、视频流):
-
• 启用所有 Offload 特性 -
• 使用零拷贝技术 -
• 增大缓冲区和队列 -
• 配置多队列和 RSS
低延迟场景(游戏、金融交易):
-
• 禁用 Nagle 算法 -
• 减小中断合并延迟 -
• 使用 CPU 亲和性 -
• 启用 TCP Quick ACK
高并发场景(Web 服务器):
-
• 使用 SO_REUSEPORT -
• 启用 TCP Fast Open -
• 增大连接队列 -
• 使用 epoll + 多线程
混合场景:
-
• 根据流量类型动态调整 -
• 使用 QoS 分类 -
• 配置多个队列优先级 -
• 监控和自适应调整
9.5 下一篇预告
下一篇《eBPF/XDP 网络加速》将深入分析:
-
• XDP 框架和工作原理 -
• eBPF 网络应用 -
• XDP 程序开发 -
• 性能对比和适用场景
❓ 常见问题(FAQ)
10.1 零拷贝技术如何选择?
选择依据:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
性能对比(传输 1GB 文件):
方法 时间 CPU 使用率----------------------------------------read/write 10.0s 100%sendfile() 6.5s 65%splice() 5.8s 58%MSG_ZEROCOPY 5.0s 50%10.2 如何判断是否需要启用 GRO?
启用 GRO 的条件:
-
1. 高 PPS(packets per second)场景 -
2. 小包为主的流量 -
3. CPU 成为瓶颈 -
4. 网卡支持 GRO
检查方法:
# 1. 查看 PPSsar -n DEV 1 10# 2. 查看 CPU 使用率mpstat -P ALL 1# 3. 查看网卡是否支持ethtool -k eth0 | grep generic-receive-offload# 4. 测试效果# 禁用 GROethtool -K eth0 gro offiperf3 -c <server> -t 60# 启用 GROethtool -K eth0 gro oniperf3 -c <server> -t 60GRO 效果:
-
• PPS 降低:50-70% -
• CPU 使用率降低:20-30% -
• 吞吐量提升:15-25%
10.3 中断合并参数如何设置?
参数说明:
rx-usecs:接收中断延迟(微秒)rx-frames:接收帧数阈值低延迟场景:- rx-usecs: 10-20- rx-frames: 8-16高吞吐量场景:- rx-usecs: 50-100- rx-frames: 32-64平衡场景:- rx-usecs: 25-50- rx-frames: 16-32自适应中断合并:
# 启用自适应ethtool -C eth0 adaptive-rx on adaptive-tx on# 内核会根据流量自动调整参数10.4 多队列数量如何确定?
队列数量建议:
CPU 核心数 队列数量 说明----------------------------------------1-2 1-2 单队列或双队列4 4 队列数 = CPU 数8 8 队列数 = CPU 数16+ 8-16 不超过 16 个队列原则:1. 队列数 ≤ CPU 核心数2. 队列数 = 2^n(便于哈希)3. 考虑 NUMA 拓扑检查和设置:
# 查看当前队列数ethtool -l eth0# 查看最大支持队列数ethtool -l eth0 | grep -A 4 "Pre-set"# 设置队列数ethtool -L eth0 combined 810.5 NUMA 系统如何优化网络性能?
NUMA 优化策略:
-
1. 网卡绑定到 NUMA 节点:
# 查看网卡所在 NUMA 节点cat /sys/class/net/eth0/device/numa_node# 查看 CPU 的 NUMA 节点lscpu | grep NUMA-
2. 中断绑定到同一 NUMA 节点:
# 获取网卡所在节点的 CPU 列表numactl --hardware | grep "node 0 cpus"# 绑定中断到这些 CPU./set_irq_affinity.sh eth0 0-7-
3. 进程绑定到同一 NUMA 节点:
# 绑定进程到 NUMA 节点 0numactl --cpunodebind=0 --membind=0 ./server-
4. 内存分配优化:
/* 从本地 NUMA 节点分配内存 */int node = numa_node_id();void *mem = numa_alloc_onnode(size, node);10.6 如何诊断网络性能瓶颈?
诊断步骤:
-
1. 检查硬件限制:
# 网卡速度ethtool eth0 | grep Speed# 链路状态ethtool eth0 | grep "Link detected"# 错误统计ethtool -S eth0 | grep -i error-
2. 检查 CPU 瓶颈:
# CPU 使用率mpstat -P ALL 1# 软中断 CPU 使用率mpstat -P ALL 1 | grep -E "CPU|%soft"# 查看哪个 CPU 处理网络中断cat /proc/interrupts | grep eth0-
3. 检查内存瓶颈:
# 内存使用free -h# sk_buff 分配失败cat /proc/net/sockstat# 丢包统计netstat -s | grep -i drop-
4. 检查队列瓶颈:
# 接收队列丢包ethtool -S eth0 | grep rx_queue.*drop# backlog 队列丢包cat /proc/net/softnet_stat-
5. 使用 perf 分析:
# 记录性能数据perf record -a -g -- sleep 10# 查看热点函数perf report# 查看网络相关函数perf report | grep -E "net|tcp|ip"10.7 TSO/GSO 和 GRO 可以同时启用吗?
可以同时启用,它们作用于不同方向:
发送方向:应用 → TCP → IP → TSO/GSO → 网卡 ↓ 延迟分段,减少处理接收方向:网卡 → GRO → IP → TCP → 应用 ↓ 聚合小包,减少处理配置:
# 同时启用ethtool -K eth0 tso on gso on gro on# 验证ethtool -k eth0 | grep -E "tcp-segmentation|generic-segmentation|generic-receive"效果:
-
• 发送:大包延迟分段,减少协议栈处理 -
• 接收:小包聚合,减少中断和处理次数 -
• 综合:CPU 使用率降低 50-70%
10.8 如何监控网络性能优化效果?
监控指标:
-
1. 吞吐量:
# 实时监控iftop -i eth0# 历史数据sar -n DEV 1 10-
2. PPS(包速率):
# 查看 PPScat /sys/class/net/eth0/statistics/rx_packetscat /sys/class/net/eth0/statistics/tx_packets-
3. CPU 使用率:
# 总体 CPUtop# 软中断 CPUmpstat -P ALL 1 | grep %soft-
4. 丢包率:
# 网卡丢包ethtool -S eth0 | grep drop# 协议栈丢包netstat -s | grep -i drop# 队列丢包cat /proc/net/softnet_stat-
5. 延迟:
# ICMP 延迟ping -c 100 <target># TCP 延迟ss -ti | grep rtt监控脚本:
#!/bin/bash# 综合性能监控whiletrue; doecho"=== $(date) ==="# 吞吐量echo"Throughput:" sar -n DEV 1 1 | grep eth0# CPUecho"CPU:" mpstat 1 1 | tail -1# 丢包echo"Drops:" netstat -s | grep -i "segments retransmited"echo""sleep 5done10.9 优化后性能反而下降怎么办?
可能原因和解决方法:
-
1. 过度优化:
# 问题:队列过多导致缓存失效# 解决:减少队列数ethtool -L eth0 combined 4# 问题:缓冲区过大导致延迟增加# 解决:减小缓冲区sysctl -w net.ipv4.tcp_rmem="4096 87380 4194304"-
2. 配置冲突:
# 问题:RPS 和 RSS 冲突# 解决:只启用 RSSecho 0 > /sys/class/net/eth0/queues/rx-0/rps_cpus-
3. 硬件不支持:
# 问题:网卡不支持某些 Offload# 解决:检查并禁用不支持的特性ethtool -k eth0ethtool -K eth0 <feature> off-
4. NUMA 配置错误:
# 问题:跨 NUMA 访问# 解决:检查并修正绑定numactl --hardwarenumactl --cpunodebind=0 --membind=0 ./server10.10 如何进行 A/B 测试验证优化效果?
测试流程:
-
1. 建立基准:
# 记录优化前性能iperf3 -c <server> -t 60 -J > baseline.json-
2. 应用优化:
# 应用单项优化ethtool -K eth0 gro on-
3. 测试优化效果:
# 记录优化后性能iperf3 -c <server> -t 60 -J > optimized.json-
4. 对比分析:
import json# 读取数据withopen('baseline.json') as f: baseline = json.load(f)withopen('optimized.json') as f: optimized = json.load(f)# 对比吞吐量baseline_bps = baseline['end']['sum_received']['bits_per_second']optimized_bps = optimized['end']['sum_received']['bits_per_second']improvement = (optimized_bps - baseline_bps) / baseline_bps * 100print(f"Throughput improvement: {improvement:.2f}%")-
5. 多次测试取平均:
#!/bin/bash# 运行 10 次测试取平均for i in {1..10}; do iperf3 -c <server> -t 60 -J > test_$i.jsondone# 计算平均值python calculate_average.py test_*.json📚 参考资料
11.1 内核源码文件
零拷贝相关:
fs/read_write.c # sendfile 实现fs/splice.c # splice 实现net/core/skbuff.c # MSG_ZEROCOPY 实现Offload 相关:
net/core/dev.c # GSO/GRO 实现net/ipv4/tcp_offload.c # TCP Offloadnet/ipv4/tcp_input.c # GRO 接收中断和 NAPI:
net/core/dev.c # NAPI 实现kernel/softirq.c # 软中断处理多队列:
net/core/dev.c # RPS/RFS/XPS 实现drivers/net/ethernet/ # 网卡驱动11.2 内核文档
官方文档:
Documentation/networking/scaling.txt # 网络扩展技术Documentation/networking/segmentation-offloads.txt # 分段卸载Documentation/networking/msg_zerocopy.rst # MSG_ZEROCOPYDocumentation/networking/napi.txt # NAPI 文档在线文档:
-
• Linux Kernel Documentation: https://www.kernel.org/doc/html/latest/ -
• Networking Documentation: https://www.kernel.org/doc/html/latest/networking/
11.3 性能测试工具
网络测试:
# iperf3https://github.com/esnet/iperf# netperfhttps://github.com/HewlettPackard/netperf# wrk (HTTP 测试)https://github.com/wg/wrk性能分析:
# perfman perf# bpftracehttps://github.com/iovisor/bpftrace# FlameGraphhttps://github.com/brendangregg/FlameGraph11.4 经典书籍
网络性能:
-
1. 《Systems Performance: Enterprise and the Cloud》 -
• 作者:Brendan Gregg -
• 全面的性能分析方法 -
2. 《Linux Performance Tuning》 -
• Linux 性能调优指南 -
3. 《High Performance Browser Networking》 -
• 作者:Ilya Grigorik -
• 网络性能优化
内核网络:4. 《深入理解 Linux 网络技术内幕》
-
• 包含性能优化章节
-
5. 《Linux Kernel Networking》 -
• 深入讲解内核网络实现
11.5 在线资源
技术博客:
-
• Brendan Gregg’s Blog: http://www.brendangregg.com/ -
• LWN.net: https://lwn.net/ -
• Cloudflare Blog: https://blog.cloudflare.com/
性能优化:
-
• The C10K Problem: http://www.kegel.com/c10k.html -
• Linux Network Performance: https://blog.packagecloud.io/eng/2016/06/22/monitoring-tuning-linux-networking-stack-receiving-data/
工具和脚本:
-
• perf-tools: https://github.com/brendangregg/perf-tools -
• bcc-tools: https://github.com/iovisor/bcc
作者:肇中内核版本:Linux 5.10 LTS
系列文章:
-
• 上一篇:《第12篇:网络命名空间(Network Namespace)》 -
• 下一篇:《第14篇:eBPF/XDP 网络加速》
勘误和建议:欢迎提出勘误和改进建议。