 夜雨聆风
夜雨聆风





50K Stars 的 AI 工具背后:这个「学习飞轮」是怎么设计的
50K Stars 的 AI 工具背后:这个「学习飞轮」是怎么设计的 静态配置是认知快照,进化系统是使用积累——两者长期差距是指数级的 |
今年二月,有人在 GitHub 的 Discussions 区贴了一个截图:他的 Claude Code 在帮他重构一个模块时,主动提出”根据你们项目的历史惯例,建议保留这个异常处理风格”。
他很困惑。他没有在任何地方写过这条规则。
答案藏在一个叫 ~/.claude/skills/ 的目录里。那里有一份自动生成的文件,记录着这个工具三个月来从他的工作模式里提炼出来的「直觉」:他偏好的错误处理方式、他不喜欢的变量命名风格、他在代码审查时反复纠正的同一类问题。
这不是魔法。这是一套有意为之的架构设计。
everything-claude-code(简称 ecc)是目前 GitHub 上增长最快的 AI 工具配置项目之一,从零到 50K stars 只用了不到半年。很多人以为它的核心是一堆精心编写的 prompt,或者一套漂亮的 slash command。但真正让它难以被复制的,是一个隐藏在这些表面功能之下的学习闭环——一个让工具随着使用者成长的「飞轮」。
01 静态配置的宿命
先说一个反面参照:手写 CLAUDE.md。
每个严肃使用 Claude Code 的人都在维护某种形式的配置文件。你告诉它你的代码风格,你的项目约定,你不想要它做什么。这套方式有用,但有一个根本性的限制:它不会成长。
你写下去的那些规则,来自你在某个特定时间点的认知。三个月后,你踩了新的坑,形成了新的判断,但配置文件还停在原地。维护它需要你主动记得去更新,而人类最不擅长的事情之一,就是在摸索期间把零散的认知及时整理成文档。
更深的问题在于,很多真正有价值的偏好是「前语言态」的——你在 code review 时立刻知道这段代码哪里别扭,但你说不清楚为什么。这种直觉无法手写进配置文件,因为你自己都还没把它提炼成语言。
|
静态配置的宿命,是永远落后于使用者的真实状态。 |
02 飞轮的四个齿轮
ecc 的设计者把解法拆成了四层,每一层的输出都是下一层的输入。
第一层:后台观察(Hook 机制)
工具在你正常工作的同时,通过 Hook 系统在后台静默记录。每次你接受或拒绝一个建议,每次你纠正了 AI 的输出,每次一个操作序列被成功执行——这些行为信号都被捕获。
这里有一个关键的设计决策:不记录内容,只记录模式。Hook 不关心你在写什么代码,它关心的是你「怎么反应」。你的接受率、你的修改方向、你重复做出同类纠正的频率——这些才是信号。
第二层:原子 Instinct 生成
每次捕获到足够强的信号,系统生成一条「Instinct」:一个原子化的、可读的偏好描述。比如”该用户倾向于在异步函数中显式声明错误类型,而非依赖 TypeScript 推断”。
原子化是关键。一条 Instinct 只描述一件事,不做组合,不做总结。这样的粒度让后续的聚类分析更准确,也让单条记录的可溯源性更强。
第三层:/evolve 命令触发聚类
当 Instincts 积累到一定数量,用户运行 /evolve 命令。这个命令做的事情,是对所有原子 Instinct 做聚类分析,识别出哪些是偶发行为,哪些是稳定模式,哪些已经有足够的证据可以被提升为 Skill——一套可以被持续加载、影响工具行为的结构化知识。
聚类的判断标准不只是频率。它还考虑信号的一致性(同类情境下是否总做同样选择)和跨时间的稳定性(这个偏好是三周前才出现的,还是从一开始就有)。
第四层:Skill 自动写入
通过聚类分析识别出的稳定模式,会被自动写入 ~/.claude/skills/ 目录下的对应文件。下次工具加载时,这些 Skill 就成为它的工作背景——不是作为规则被强制执行,而是作为「对这个用户习惯的理解」渗透进每一个建议里。
这就是飞轮完整转动一圈的过程:观察 → 原子化 → 聚类 → 自动写入。

03 没有账本的信任,走不远
光有飞轮还不够。飞轮产生的知识越来越多,一个新问题就会出现:你怎么知道这条 Skill 是从哪来的,它靠不靠得住?
ecc 的 provenance 追踪系统是这个架构里最容易被忽视、也最不可或缺的部分。
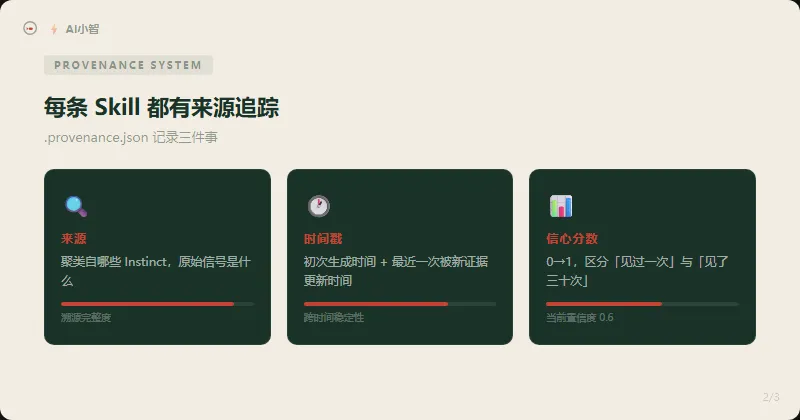
每一个自动生成的 Skill,都对应一个 .provenance.json 文件。这个文件记录三件事:
- 来源
:这条 Skill 是从哪些 Instinct 聚类而来的,原始信号是什么 - 时间戳
:最初生成时间,以及最近一次被新证据更新的时间 - 信心分数
:基于信号数量、一致性和时间跨度计算出的置信度,从 0 到 1
信心分数的存在,让系统能做出一件极其重要的事:区分「我只见过一次」和「我见了三十次」。
没有这个区分,一个偶发行为就可能被过度泛化成「规则」,然后在未来的工作中反复被错误地应用。这种过度拟合的失败模式,在没有 provenance 系统的机械学习工具里极其常见。
更重要的是,provenance 让 Skill 的演化有了依据。当你的偏好发生了变化,新的 Instinct 信号会逐渐推低旧 Skill 的信心分数,直到触发重新聚类。工具的「记忆」不是刻在石头上的,而是随着新证据的积累持续修正的。
|
没有 provenance,学习系统只是一个越用越乱的黑盒。有了 provenance,它才是一个可以被审计、被信任的知识体系。 |
04 分层存储:知识的生态位
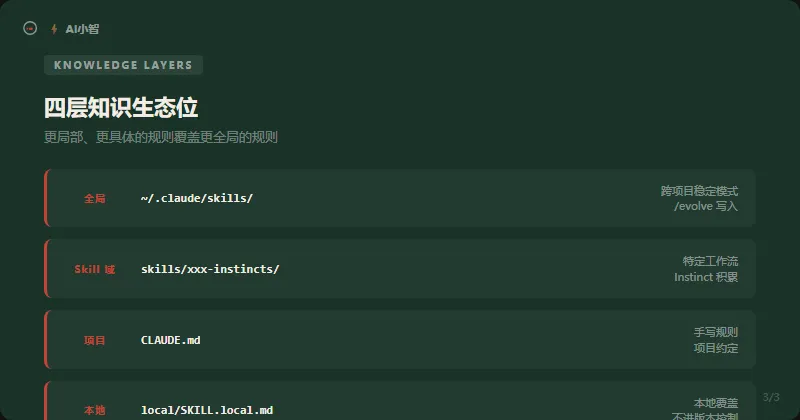
飞轮生成的知识,最终以四个不同层级存储,每一层有不同的来源和作用域。
| 存储层 | 来源 | 作用域 |
| ~/.claude/skills/ | 跨项目稳定模式,/evolve 聚类写入 | 全局,所有项目 |
| skills/xxx-instincts/ | 特定工作流的 Instinct 积累 | 特定 Skill 域 |
| 项目级 CLAUDE.md | 手写规则 + 项目特定约定 | 单个仓库 |
| local/SKILL.local.md | 用户本地覆盖,不进入版本控制 | 本地环境 |
这个分层设计解决了一个微妙的问题:不同来源的知识,应该有不同的权威性和生命周期。
你在个人 dotfiles 里记录的跨项目偏好,应该比某个特定仓库里的临时约定有更高的持久性。你在本地环境里的测试性配置,不应该污染你的全局行为。这四层之间有明确的优先级,当冲突发生时,更局部、更具体的规则覆盖更全局的规则。
这个设计在架构上并不复杂,但需要「想到它」。大多数竞品工具把所有配置都压进一个文件或一个目录,导致手写规则和自动学习的内容相互干扰,最终用户只能用原始覆盖来「纠正」被污染的行为。
结语
回到最开始的那个问题:为什么这个设计难以被简单复制?
不是因为技术门槛高。飞轮的每一个环节,用现有的工具都可以实现。难的是「想到这个设计的前提」:
你必须承认,一个静态配置文件和一个持续演化的知识系统,长期来看会产生指数级的差距。前者是你某个下午的认知快照,后者是你几百小时工作的提炼。
你还必须承认,自动学习如果没有可溯源性,就是一个不可信任的黑盒。provenance 系统不是可有可无的附加功能,它是整个学习闭环的信任基础。
ecc 涨到 50K stars,不是因为它的 prompt 写得有多精妙。而是因为它是少数几个真正把「工具应该随使用者成长」这个想法,落实成了一套可运转的工程架构的项目。
飞轮一旦转起来,就会越来越快。这才是它真正的护城河。
⚡🟡AI小智 · 全文完