 夜雨聆风
夜雨聆风





"AI只是工具,与其限制工具,不如直接追究提交者的责任." –「谁点提交,谁负责」:Linux内核给代码立规矩,释放三个信号
「谁点提交,谁负责」:Linux内核给AI代码立规矩,释放三个信号
“AI只是工具,与其限制工具,不如直接追究提交者的责任。”
——Linus Torvalds,2026年1月
2026年4月12日,Linux内核维护团队正式发布AI生成代码使用准则。这份准则的核心只有一句话:谁点提交,谁负责。
这不是一次普通的技术社区公告。它意味着,全球最核心的开源项目用正式规则回应了一个正在困扰整个科技行业的问题:当AI写的代码出了问题,谁来担责?
一场持续数月的”内战”
故事要从2026年1月说起。
Linux内核社区爆发了一场激烈争论。一方是英特尔工程师Dave Hansen,他主张严格限制AI编程工具的使用;另一方是甲骨文员工Lorenzo Stoakes,他认为限制AI没有意义。
争论的本质不是”能不能用AI”,而是”出了问题怎么办”。
这场”内战”最终惊动了Linus Torvalds本人。他的表态干脆利落:全面禁止AI只是毫无意义的作秀。在他看来,与其争辩工具的好坏,不如直接锁定责任主体。
“谁签字,谁负责”变成了”谁点提交,谁负责”
Linux的新准则并非无底线放开。
它要求所有开发者必须声明代码是否由AI生成。这不是一道选择题,而是强制披露。
表面看,这是一个代码管理的细节规定。但它的实质是:Linux把AI辅助编程纳入了正式的工作流,同时把责任链条清晰地绑在了提交者身上。
换句话说,GitHub Copilot可以帮你写代码,但Bug和安全漏洞的账,要从你口袋里扣。
三个信号,CEO必须读懂
信号一:AI代码治理,从”封堵”转向”疏导”
在新规出台前,开源社区对AI工具的态度截然分化。
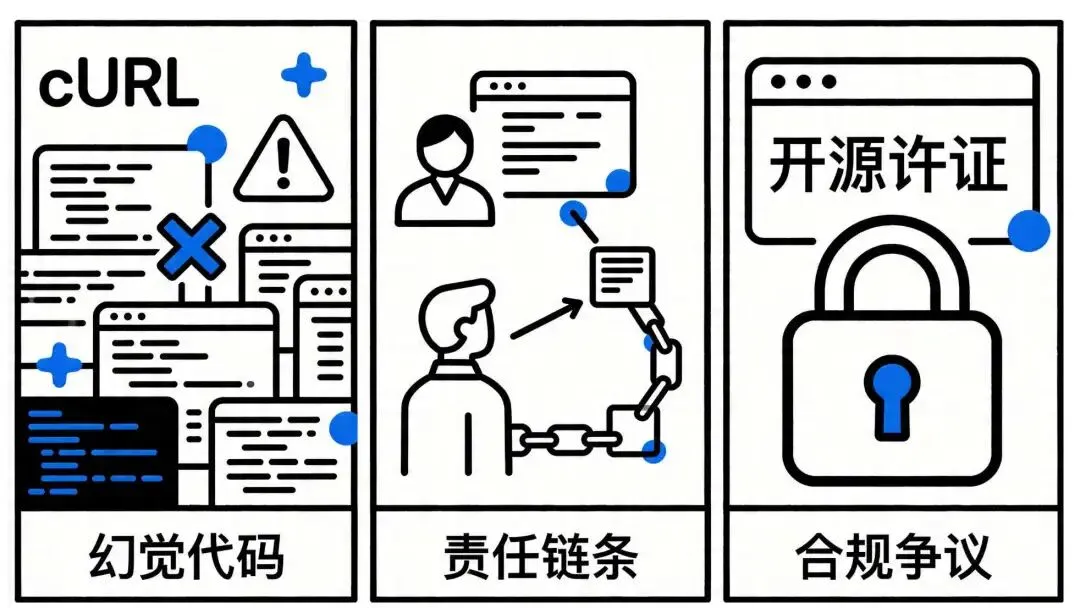
NetBSD和Gentoo选择了直接禁止。Gentoo的理由尤其值得玩味:**他们认为大模型生成的内容在法律上属于”污染”**,因为训练数据的版权来源本身就不明确。
但Linux选择了另一条路:与其把AI挡在门外,不如建好”交通规则”让它有序运行。
这透露出的信号很清楚:封堵的成本越来越高,疏导才是主流方向。对于正在推进AI工具应用的企业来说,这意味着监管压力会从”能不能用”转向”怎么用才对”。

信号二:责任边界,正在成为AI落地的核心矛盾
Linux准则里有一个细节容易被忽视:原创声明(DCO)的争议。
DCO要求开发者确保提交的代码拥有明确的所有权。但AI大模型的训练数据里,大量代码受GPL等许可证约束。当AI”借鉴”了这些代码,开发者根本无法完全保证来源的合法性。
这个问题不只存在于开源社区。
想象一下:企业用AI开发了一款产品,其中某个模块出现了专利侵权纠纷。谁来负责?AI供应商?开发者?还是企业自身?
AI生成内容的法律归属和责任划分,正在从技术问题变成商业风险。 这个问题越早布局,越主动。
信号三:开源社区,成了AI治理的”试验场”
有意思的是,最先认真对待AI代码治理问题的,不是政府监管机构,也不是大型科技公司,而是一群开源社区的开发者。
因为他们最直接地感受到了AI代码带来的冲击。
cURL被大量幻觉代码淹没,被迫关闭漏洞奖赏计划。
Node.js和OCaml收到上万行AI补丁,引发内部争议。
Sasha Levin曾未披露AI使用情况提交补丁,代码能跑但性能极差,连Torvalds都承认评审不充分。
开源社区的”应急反应”,正在为更大范围的AI治理提供样本。当这些经验成熟后,它们很可能会以某种形式进入企业级规范,甚至成为行业标准。
给CEO的行动建议
-
**盘点你家的”AI代码责任链”**:如果团队在用AI编程工具,必须明确:代码审查谁负责?Bug谁担责?合规风险谁兜底?
-
建立AI工具使用的披露机制:参考Linux准则,要求使用AI辅助编程的开发者主动声明。这是防御风险的第一步。
-
关注开源社区的治理实践:Linux的做法可能成为行业范本。持续跟踪这些实践,能让你在监管正式出台前做好准备。
-
法务团队要提前介入AI合规:GPL等开源许可证的合规问题,加上AI生成内容的版权归属,是一个需要专业介入的复杂领域。
当工具进化得越来越快,规则必须跟上。
Linux内核用一句”谁点提交,谁负责”,给所有AI应用者提了一个醒:AI可以是帮手,但不会是担责的主体。 这个主体,只能是人。
你所在的企业,AI代码的责任边界是怎么划定的?欢迎在评论区分享。
如果觉得这篇文章对你有启发,欢迎转发给需要的朋友。