 夜雨聆风
夜雨聆风





Spring AI 文档处理进阶:Token 切分与智能摘要增强
Spring AI 文档处理进阶:Token 切分与智能摘要增强
上一期我们学会了用各种 Reader 读取文档,但读出来的“大块头”AI 根本消化不了。今天我们来搞定文档的“精加工”——切分与元数据增强。
在《Spring AI 文档处理全指南:从 PDF 到 Markdown,一文掌握所有 DocumentReader》中,我们掌握了如何用 JsonReader、TikaDocumentReader 等工具把 PDF、Word、HTML 读成 Document 对象。
但问题是:一个 50 页的 PDF 读完就是一个巨大的 Document。如果直接扔给大模型,会撑爆上下文窗口,检索精度也会惨不忍睹。
ETL 管道的第二个环节——Transformers(转换器),就是用来解决这个问题的。今天我们会重点学习三个核心组件:
|
|
|
|
|---|---|---|
TokenTextSplitter |
|
必选
|
KeywordMetadataEnricher |
|
|
SummaryMetadataEnricher |
|
|
TokenTextSplitter:给文档“分块”的艺术
1. 为什么需要切分?
大模型的上下文窗口有限(如 8K、32K Token)。如果把一整本书存成一个向量,当你问“第三章讲了什么?”时,AI 很难精准定位到那几页。
切分的核心目标:把长文档拆成一个个 语义相对完整的小块(Chunk),每个块独立向量化。检索时只召回最相关的几个块,既精准又省 Token。
2. TokenTextSplitter 核心参数
Spring AI 的 TokenTextSplitter 基于 OpenAI 的 CL100K_BASE 编码,能精确控制每个块的 Token 数量。通过 Builder 模式可以灵活配置:
@ComponentpublicclassMyTokenTextSplitter{/** * 使用 Builder 模式优雅配置 * @param documents * @return */public List<Document> splitWithBuilder(List<Document> documents){ TokenTextSplitter splitter = TokenTextSplitter.builder()// 每个文本块的目标最大 Token 数量。分割器会尽量使每个块的 Token 数接近但不超过此值。 .withChunkSize(1000)// 最小字符数阈值。如果一个块在达到 chunkSize 前字符数已小于此值,分割器会尝试与下一块合并,避免产生过小的碎片块。 .withMinChunkSizeChars(400)//最小有效块长度。若一个块在分割后长度小于此值,则会被直接丢弃,不纳入最终的 Document 列表。常用于过滤掉只有标点符号或空白字符的无意义块。 .withMinChunkLengthToEmbed(10)//单个输入文档最多允许生成的块数量。防止文档过大导致内存溢出。 .withMaxNumChunks(5000)// 是否在分割后的文本块中保留分隔符。true 表示将分隔符附加在前一个块的末尾;false 则丢弃分隔符。 .withKeepSeparator(true)// 自定义分隔符优先级列表。分割器会按顺序尝试用这些字符拆分文本:先用 "." 分,如果分出的块仍超过 chunkSize,则用 "?" 分,依此类推。这样可以尽量保证语义完整性(优先按句子分割)。 .withPunctuationMarks(List.of('.', '?', '!', '\n')) .build();return splitter.apply(documents); }}参数详解
|
|
|
|
|---|---|---|
chunkSize |
|
|
minChunkSizeChars |
|
|
minChunkLengthToEmbed |
|
|
maxNumChunks |
|
|
keepSeparator |
|
|
punctuationMarks |
.?!\n |
|
3. 中文场景的最佳实践
默认的英文标点(.?!\n)对中文文档不太友好。强烈建议自定义标点列表:
@ComponentclassMyInternationalTextSplitter{/** * 专门针对中文文本的分割器,使用中文标点符号作为分隔符 * @param documents * @return */public List<Document> splitChineseText(List<Document> documents){// Use Chinese punctuation marks TokenTextSplitter splitter = TokenTextSplitter.builder()// 目标块大小(Token数) .withChunkSize(800)// 最小字符数,防止碎片 .withMinChunkSizeChars(350)// 中文标点符号 .withPunctuationMarks(List.of('。', '?', '!', ';')) .build();return splitter.apply(documents); }}⚠️ 重要行为说明:
TokenTextSplitter仅在当前块的 Token 数量超过chunkSize时,才会尝试在标点处切分。如果一个段落本身的 Token 数没有超标,它会被完整保留,不会被强制切断。这避免了对小文本不必要的碎片化。
4. 完整示例
@SpringBootTestpublicclassChineseSplitTest{@Autowiredprivate MyInternationalTextSplitter textSplitter; // 注入我们自定义的分割器@TestpublicvoidtestChineseTextSplit(){// 准备一段较长的中文文本(模拟从文件读取的文档) String longChineseText = """ Spring AI 是一个基于 Spring 生态构建的 AI 应用开发框架。 它旨在简化将人工智能能力集成到企业级应用中的过程。 该框架提供了一套统一的抽象接口,开发者无需关注底层 AI 服务提供商的具体实现细节。 即可轻松接入包括 OpenAI、Azure OpenAI、Ollama 以及国内的阿里云通义千问、智谱 AI 等在内的多种主流大模型。 Spring AI 的核心组件包括 ChatClient、EmbeddingClient 和 VectorStore。 它们分别用于处理对话生成、文本向量化以及向量数据存储与检索。 借助 Spring AI,开发者可以快速实现智能客服、代码自动补全、文档语义搜索等高级功能。 同时还能利用 Spring Boot 的自动配置特性,仅需少量配置即可启动一个完整的 RAG(检索增强生成)应用。 此外,Spring AI 还内置了对 ETL(抽取、转换、加载)流程的支持。 通过 DocumentReader、DocumentTransformer 和 DocumentWriter 等组件,能够高效地将 PDF、Markdown、JSON 等非结构化数据转化为可供大模型理解的向量化知识库。 这极大地降低了 AI 应用开发的门槛,使传统 Java 开发者也能轻松驾驭 AI 技术。 """;// 创建文档对象,并附带元数据(可选) Document doc = new Document(longChineseText, Map.of("source", "spring-ai-intro.txt"));// 调用自定义的中文分割器进行切分 List<Document> chunks = textSplitter.splitChineseText(List.of(doc));// 打印切分结果 System.out.println("原始文档被切分为 " + chunks.size() + " 个块:");for (int i = 0; i < chunks.size(); i++) { Document chunk = chunks.get(i); System.out.println("\n========== 块 " + (i + 1) + " =========="); System.out.println("内容: " + chunk.getText()); System.out.println("元数据: " + chunk.getMetadata()); } }}KeywordMetadataEnricher:让 AI 自己打标签
切分完成后,每个块都是孤立的文本。如果能在元数据中补充关键词,后续检索时就可以通过 filterExpression 进行精确过滤,大幅提升召回精度。
KeywordMetadataEnricher 会调用大模型,为每个 Document 自动提取关键词,并存入 excerpt_keywords 字段。
1. 基础用法
@ComponentpublicclassMyKeywordEnricher{privatefinal ChatModel chatModel; MyKeywordEnricher(ChatModel chatModel) {this.chatModel = chatModel; }public List<Document> enrichDocuments(List<Document> documents){ KeywordMetadataEnricher enricher = KeywordMetadataEnricher.builder(chatModel) .keywordCount(5) // 提取 5 个关键词 .build();return enricher.apply(documents); }}2. 自定义提示词(中文输出)
默认模板生成的关键词是英文的。如果希望输出中文关键词,可以自定义模板:
public List<Document> customTemplateEnrich(List<Document> documents){ String chineseTemplate = """ 请阅读以下文本内容,提取最能概括其核心主题的5个关键词。 要求: 1. 关键词必须使用中文。 2. 关键词之间用英文逗号分隔。 3. 只返回关键词列表,不要包含任何其他解释或符号。 文本内容: {context_str} """; PromptTemplate promptTemplate = new PromptTemplate(chineseTemplate); KeywordMetadataEnricher enricher = KeywordMetadataEnricher.builder(chatModel) .keywordsTemplate(promptTemplate) .build();return enricher.apply(documents);}3. 测试结果
String testString = """ Spring AI 是一个基于 Spring 生态构建的 AI 应用开发框架, 它旨在简化将人工智能能力集成到企业级应用中的过程。 该框架提供了一套统一的抽象接口,开发者无需关注底层 AI 服务提供商的具体实现细节, 即可轻松接入包括 OpenAI、Azure OpenAI、Ollama 以及国内的阿里云通义千问、 智谱 AI 等在内的多种主流大模型。Spring AI 的核心组件包括 ChatClient、EmbeddingClient 和 VectorStore,它们分别用于处理对话生成、文本向量化以及向量数据存储与检索。 借助 Spring AI,开发者可以快速实现智能客服、代码自动补全、文档语义搜索等高级功能, 同时还能利用 Spring Boot 的自动配置特性,仅需少量配置即可启动一个完整的 RAG(检索增强生成)应用。 此外,Spring AI 还内置了对 ETL(抽取、转换、加载)流程的支持, 通过 DocumentReader、DocumentTransformer 和 DocumentWriter 等组件, 能够高效地将 PDF、Markdown、JSON 等非结构化数据转化为可供大模型理解的向量化知识库。 """;@Autowired MyKeywordEnricher myKeywordEnricher;@TestpublicvoidtestTokenTextSplitter(){ Document doc = new Document(testString, Map.of("source", testString)); List<Document> documents = myKeywordEnricher.enrichDocuments(List.of(doc)); System.out.println("结果:"+documents); List<Document> documents1 = myKeywordEnricher.customTemplateEnrichDocuments(List.of(doc)); System.out.println("结果1:"+documents1); }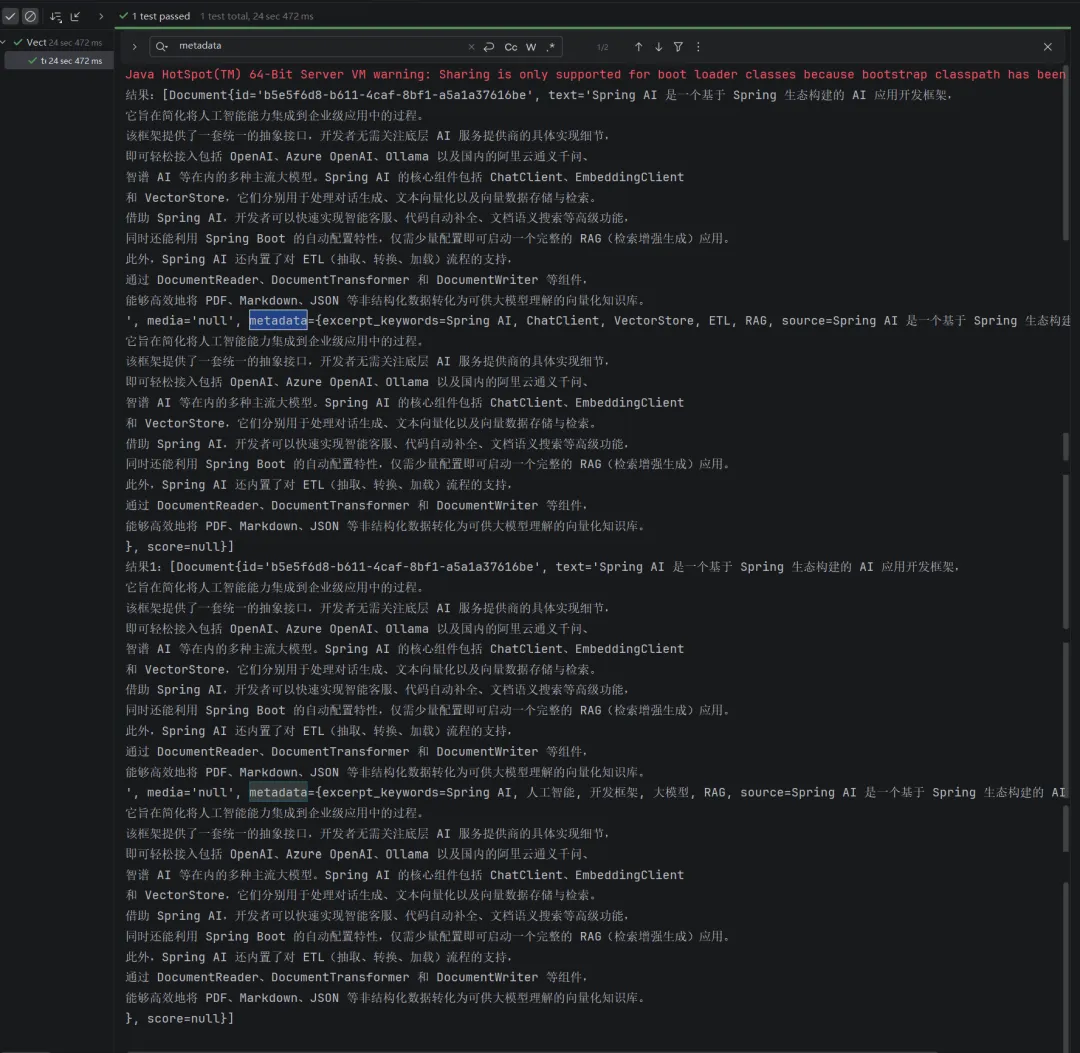
4. 注意事项
-
KeywordMetadataEnricher需要一个可用的ChatModel(如 Ollama、OpenAI)。 -
提取的关键词以逗号分隔的字符串形式存入元数据,键名为 excerpt_keywords。 -
如果同时指定了 keywordCount和keywordsTemplate,自定义模板优先。
SummaryMetadataEnricher:让片段拥有“上下文记忆”
对于按顺序排列的文档(如书籍的章节、长文的段落),单个片段可能丢失上下文信息。SummaryMetadataEnricher 可以为每个片段生成当前、前一个、后一个三个摘要,并存入元数据。这样,即使检索只命中中间的一个片段,AI 也能通过摘要了解前后文。
1. 工作原理
-
遍历文档列表,按顺序处理。 -
为每个文档生成当前片段摘要,存入 section_summary。 -
如果请求了相邻摘要,会基于相邻文档内容生成 prev_section_summary或next_section_summary。 -
所有摘要均通过大模型生成,并注入元数据。
2. 基础配置
@ConfigurationpublicclassEnricherConfig{@Beanpublic SummaryMetadataEnricher summaryMetadata(ChatModel chatModel){// 生成当前、前一个、后一个摘要returnnew SummaryMetadataEnricher(chatModel, List.of( SummaryMetadataEnricher.SummaryType.PREVIOUS, SummaryMetadataEnricher.SummaryType.CURRENT, SummaryMetadataEnricher.SummaryType.NEXT ) ); }}3. 中文摘要自定义模板
与关键词增强器一样,默认输出是英文。我们需要自定义中文模板,并指定 MetadataMode:
@Beanpublic SummaryMetadataEnricher summaryMetadata(ChatModel chatModel){ String CHINESE_SUMMARY_TEMPLATE = """ 以下是章节内容: {context_str} 请用中文简要总结本章节的核心主题和关键实体,严格依据以上内容进行概括,不要添加任何额外信息。 摘要: """;@Beanpublic SummaryMetadataEnricher summaryMetadata(ChatModel aiClient){// 生成当前、前一个、后一个摘要returnnew SummaryMetadataEnricher(aiClient, List.of(SummaryMetadataEnricher.SummaryType.PREVIOUS, SummaryMetadataEnricher.SummaryType.CURRENT, SummaryMetadataEnricher.SummaryType.NEXT), CHINESE_SUMMARY_TEMPLATE, MetadataMode.EMBED ); }}4. MetadataMode 是什么?
MetadataMode 决定了在调用大模型生成摘要时,文档原有的元数据(如 source、author)是否以及如何与文本内容一起提供给模型。
|
|
|
|
|---|---|---|
NONE |
|
|
ALL |
|
|
EMBED |
[key: value] 格式嵌入文本前 |
|
INFERENCE |
ALL |
|
默认模式为 ALL。如果你希望摘要完全基于文本内容,不受元数据干扰,可以设为 NONE。
5. 测试效果
@Autowired SummaryMetadataEnricher summaryMetadataEnricher;@TestvoidtestSummaryMetadataEnricher(){ PagePdfDocumentReader pdfReader = new PagePdfDocumentReader(// 指定类路径下的 PDF 文件"classpath:/ETL 管道.pdf",// 构建配置对象 PdfDocumentReaderConfig.builder()// 设置页面顶部边距裁剪 .withPageTopMargin(0) .withPageExtractedTextFormatter( ExtractedTextFormatter.builder()// 删除提取文本的前 N 行 .withNumberOfTopTextLinesToDelete(0) .build() )// 每个 Document 包含的 PDF 页数 .withPagesPerDocument(1) .build() ); List<Document> documents = pdfReader.read(); List<Document> enriched = summaryMetadataEnricher.apply(documents);for (Document doc : enriched) { System.out.println("当前摘要: " + doc.getMetadata().get("section_summary")); System.out.println("前一个摘要: " + doc.getMetadata().get("prev_section_summary")); System.out.println("后一个摘要: " + doc.getMetadata().get("next_section_summary")); System.out.println("---"); } }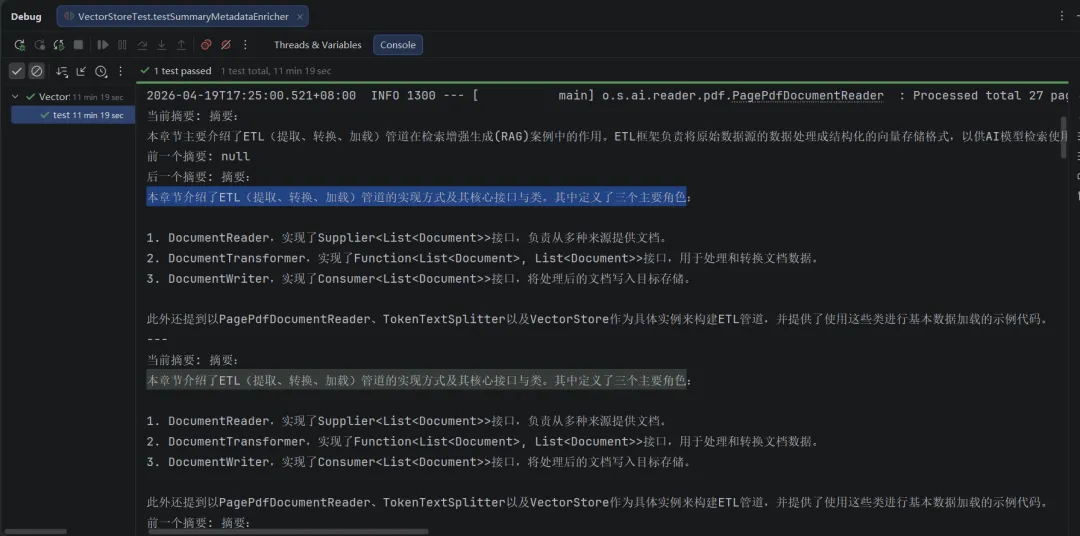
完整 ETL 管道串联示例
将 Reader、Splitter、Enricher 串起来,就是一个完整的文档预处理流程:
@ComponentpublicclassDocumentETLService{@Autowiredprivate VectorStore vectorStore;@Autowiredprivate ChatModel chatModel;publicvoidprocessFile(Resource file){// 1. Extract:读取文件 TikaDocumentReader reader = new TikaDocumentReader(file); List<Document> rawDocs = reader.read();// 2. Transform:切分 TokenTextSplitter splitter = TokenTextSplitter.builder() .withChunkSize(1000) .withPunctuationMarks(List.of('。', '?', '!', '\n')) .build(); List<Document> chunks = splitter.apply(rawDocs);// 3. Transform:关键词增强(可选) KeywordMetadataEnricher keywordEnricher = KeywordMetadataEnricher.builder(chatModel) .keywordCount(5) .build(); List<Document> withKeywords = keywordEnricher.apply(chunks);// 4. Load:存入向量库 vectorStore.add(withKeywords); }}总结
今天我们深入 Spring AI 的 DocumentTransformer 模块,掌握了三个核心技能:
-
** TokenTextSplitter**:按 Token 精准切分,是 RAG 的必选动作。 -
** KeywordMetadataEnricher**:自动提取关键词,提升检索精度。 -
** SummaryMetadataEnricher**:为片段添加上下文摘要,让 AI 理解前后文。
参数调优速查表
|
|
|
|
|---|---|---|
TokenTextSplitter |
chunkSize
punctuationMarks |
chunkSize
。?!; |
KeywordMetadataEnricher |
keywordCount
|
|
SummaryMetadataEnricher |
SummaryType
MetadataMode |
MetadataMode 用 NONE 或 EMBED |
如果觉得文章有帮助,欢迎 点赞、在看、转发 支持!我们下期见。