 夜雨聆风
夜雨聆风





Claude-Mem:让AI编程助手拥有跨会话持久记忆
目录
-
[1. 概述] -
[2. 核心架构] -
[3. 三层搜索工作流] -
[4. 搜索参数详解] -
[5. 实战场景] -
[6. 进阶功能] -
[7. 安装与配置] -
[8. 总结] -
[参考文献]
1. 概述
Claude Code 是 Anthropic 官方的命令行 AI 编程助手,但它有一个明显的短板——每次会话结束后,上下文就消失了。你昨天修过的 bug、上周做的架构决策,新会话中 Claude 完全不记得。
claude-mem 正是为解决这个问题而生的开源插件(GitHub 46K+ Stars)。它通过自动捕获每次会话中的工具使用记录、代码变更和决策过程,用 AI 压缩成结构化摘要,然后在未来的会话中智能注入相关上下文,让 Claude 拥有真正的”持久记忆”。
核心价值:
-
跨会话保持项目知识连续性 -
自动记录,无需手动干预 -
Token 高效的渐进式检索策略 -
支持自然语言搜索历史工作记录
2. 核心架构
claude-mem 由 6 个核心组件构成,形成一个完整的数据采集→压缩→存储→检索闭环:
2.1 生命周期钩子
5 个生命周期钩子覆盖会话的全过程:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
数据采集与检索生命周期:
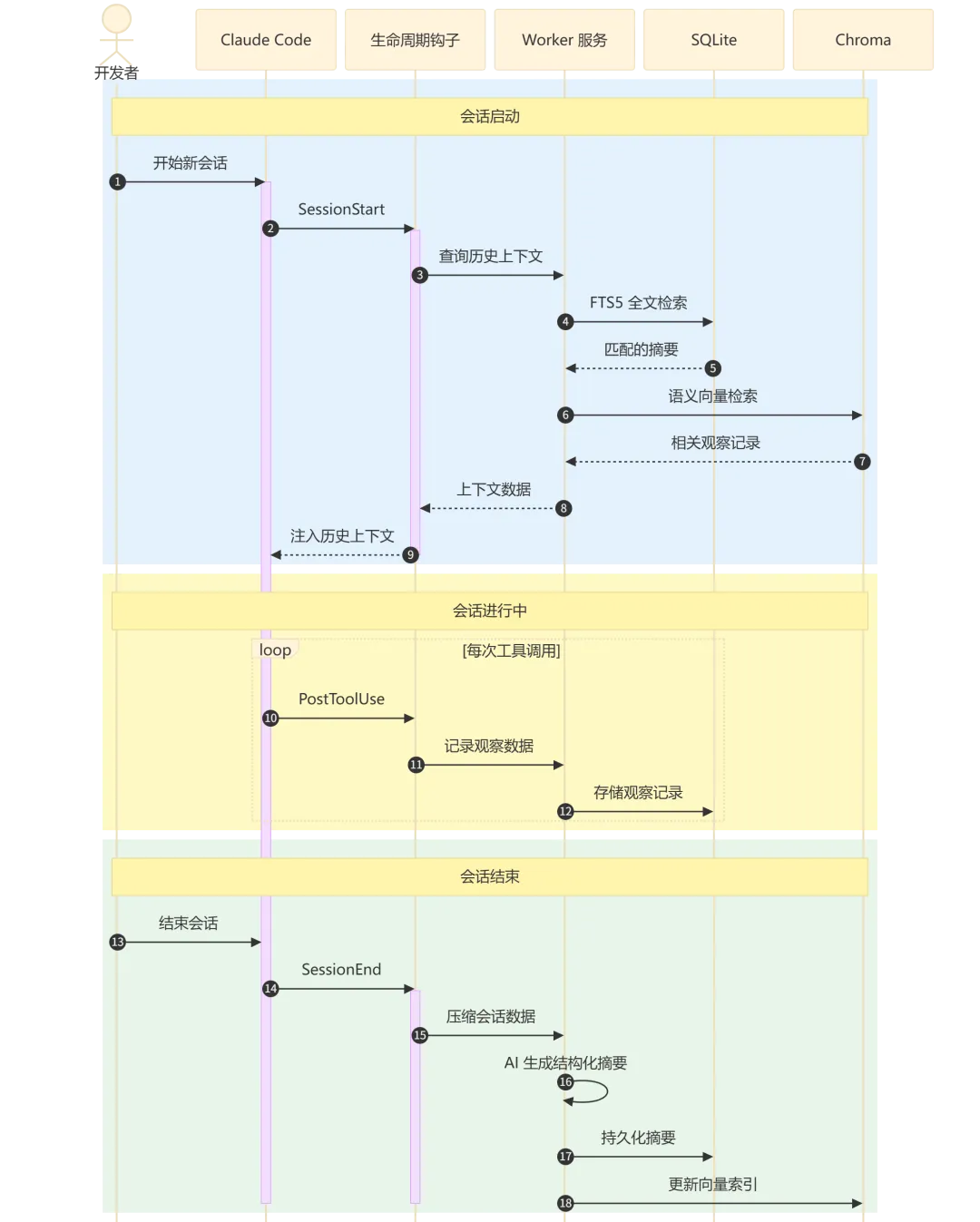
流程执行说明:
-
会话启动阶段(步骤 1-9):SessionStart 钩子触发,Worker 同时查询 SQLite(关键词检索)和 Chroma(语义检索),将历史上下文注入新会话。 -
会话进行阶段(步骤 10-13):每次工具调用后,PostToolUse 钩子自动捕获观察数据并存入 SQLite。 -
会话结束阶段(步骤 14-19):SessionEnd 钩子触发压缩流程,AI 生成结构化摘要,同时更新 SQLite 和 Chroma 向量索引。
2.2 存储层
-
SQLite 数据库:存储会话、观察记录、摘要,使用 FTS5 全文检索 -
Chroma 向量数据库:支持语义搜索 + 关键词搜索的混合检索
2.3 Worker 服务
运行在 localhost:37777 的 HTTP 服务,提供:
-
10 个搜索 API 端点 -
Web Viewer UI(可视化查看记忆流) -
Bun 进程管理
3. 三层搜索工作流
claude-mem 的搜索设计遵循”渐进式披露”原则——先看索引,再定范围,最后取详情。这个策略能带来 约 10 倍的 token 节省。
3.1 第一层:search(搜索索引)
目的:快速获取匹配结果的 ID 列表和标题摘要。
search(query="authentication bug", limit=20, project="my-app")返回格式:每条记录约 50-100 token,包含 ID、时间戳、类型图标、标题:
| ID | Time | T | Title | Read ||-------|----------|----|------------------------------|------|| 11131 | 3:48 PM | 🔴 | Fixed auth token expiration | ~75 || 10942 | 2:15 PM | 🟣 | Added JWT authentication | ~50 |
类型图标的含义:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.2 第二层:timeline(时间线上下文)
目的:查看某条记录前后的工作上下文,理解完整的做事脉络。
// 以某条记录为锚点,查看前后各 3 条timeline(anchor=11131, depth_before=3, depth_after=3)// 或者用关键词自动定位锚点timeline(query="authentication", depth_before=5, depth_after=5)
这个步骤非常关键——单独看一条 bugfix 记录可能只知道”修了什么”,但通过 timeline 你能看到:修 bug 前做了什么调研、修了之后又做了哪些测试。
3.3 第三层:get_observations(获取详情)
目的:只获取筛选后的关键记录的完整内容。
get_observations(ids=[11131, 10942])返回内容:每条约 500-1000 token,包含:
-
标题和副标题 -
叙事描述(发生了什么) -
关键事实列表 -
相关概念标签 -
涉及的文件列表
为什么必须批量获取? 一次请求获取多条记录,比逐条获取减少 N-1 次 HTTP 请求,在 token 和时间上都更高效。
3.4 工作流可视化
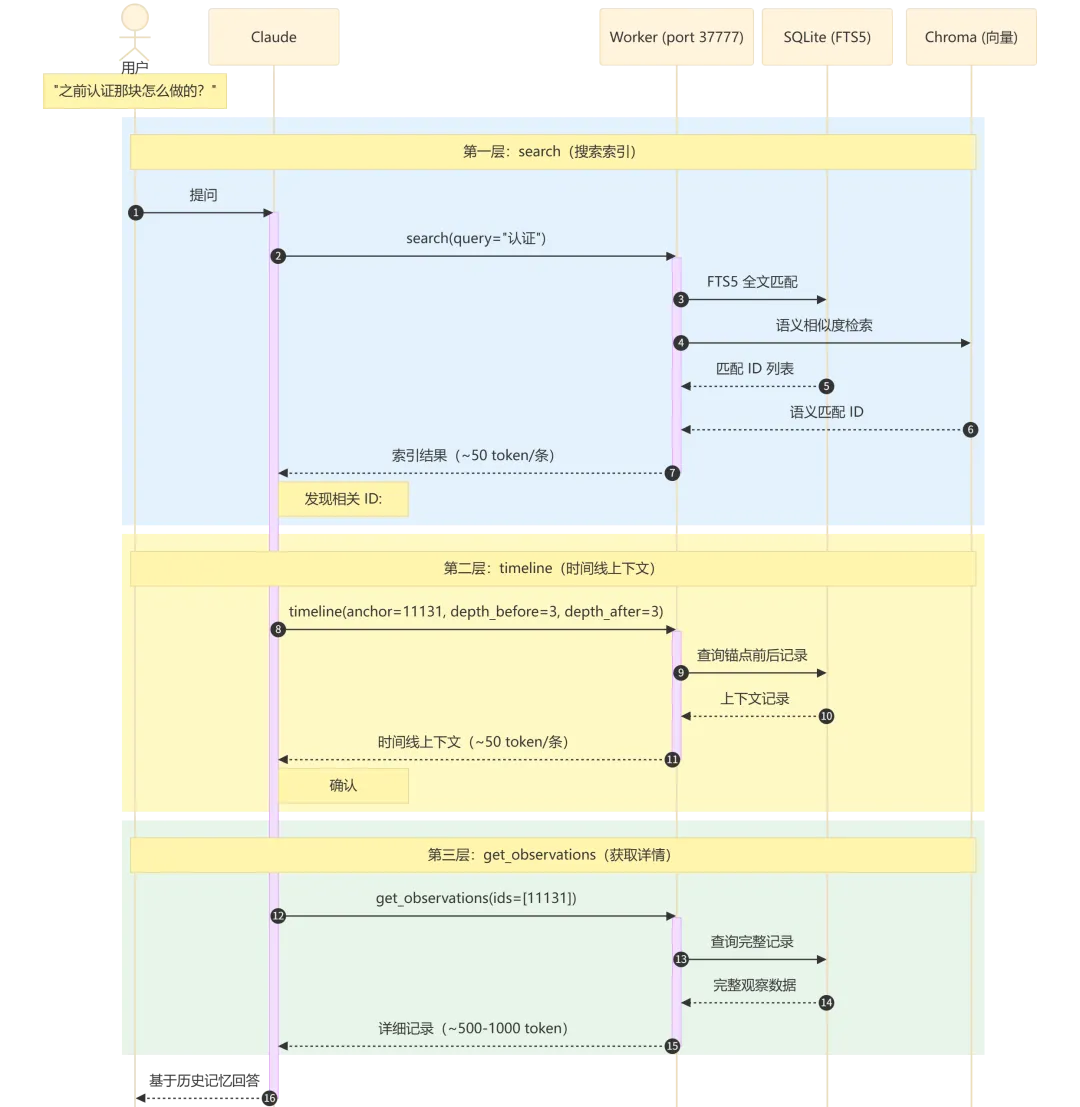
流程执行说明:
-
第一层 search(步骤 1-6):Claude 同时向 SQLite(关键词匹配)和 Chroma(语义检索)发起查询,返回索引列表。每条仅约 50 token,快速定位候选记录。 -
第二层 timeline(步骤 7-10):以候选记录 ID 为锚点,查询前后各 N 条上下文记录。帮助判断记录的相关性和完整性。 -
第三层 get_observations(步骤 11-14):仅对确认相关的记录 ID 批量获取完整详情。每条约 500-1000 token,精准投喂。
Token 节省关键:如果直接获取所有 20 条记录的完整内容,需要约 10,000-20,000 token。经过三层过滤后,通常只需获取 2-3 条,仅需 1,000-3,000 token——节省约 10 倍。
4. 搜索参数详解
4.1 search 参数
|
|
|
|
|
|---|---|---|---|
query |
|
|
|
limit |
|
|
|
project |
|
|
|
obs_type |
|
|
|
dateStart |
|
|
|
dateEnd |
|
|
|
offset |
|
|
|
orderBy |
|
|
|
4.2 timeline 参数
|
|
|
|
|
|---|---|---|---|
anchor |
|
|
|
query |
|
|
|
depth_before |
|
|
|
depth_after |
|
|
|
project |
|
|
|
4.3 get_observations 参数
|
|
|
|
|
|---|---|---|---|
ids |
|
|
|
orderBy |
|
|
|
limit |
|
|
|
project |
|
|
|
5. 实战场景
5.1 搜索上周修过的 Bug
search(query="bug", obs_type="bugfix", dateStart="2026-04-14", limit=20)返回上周所有 bugfix 记录的索引,快速回顾修复历史。
5.2 追溯某个功能的完整实现过程
// Step 1: 搜索功能相关记录search(query="prompt extraction", limit=20)// Step 2: 找到关键记录后查看上下文timeline(anchor=2376, depth_before=5, depth_after=5)// Step 3: 获取关键节点详情get_observations(ids=[2376, 2377, 2380])
这样你能看到:调研→计划→实现→测试的完整链路。
5.3 查找架构决策的依据
search(query="architecture", obs_type="decision", limit=10)找出之前的架构决策记录,了解”为什么这样做”而不仅仅是”做了什么”。
5.4 日常回顾
search(dateStart="2026-04-20", limit=20)查看某一天的所有工作记录,适合做日报或周报回顾。
6. 进阶功能
6.1 知识库(Knowledge Corpus)
当观察记录积累到一定量后,可以构建知识库进行语义问答:
// 构建知识库build_corpus(name="auth-system", query="authentication", types="bugfix,feature")// 启用知识库prime_corpus(name="auth-system")// 向知识库提问query_corpus(name="auth-system", question="认证系统用过哪些方案?")
知识库将多条相关观察记录融合成一个可对话的 AI 会话,比逐条阅读记录更高效。
6.2 Smart Explore 工具
除了记忆搜索,claude-mem 还提供代码结构分析工具:
-
smart_search:基于 tree-sitter AST 的符号搜索,比文本搜索更精准 -
smart_outline:获取文件的结构大纲,展示所有函数/类/方法签名 -
smart_unfold:展开特定符号的完整实现代码
这些工具支持 24 种编程语言,包括 JS、TS、Python、Go、Rust、Java 等。
6.3 多语言支持
claude-mem 支持多种工作模式语言,在 ~/.claude-mem/settings.json 中配置:
{"CLAUDE_MEM_MODE":"code--zh"}
可用模式:code(英文默认)、code--zh(简体中文)、code--ja(日语)等。
6.4 Web Viewer
访问 http://localhost:37777 可以打开 Web Viewer UI,实时查看记忆流,支持可视化浏览所有观察记录。
6.5 隐私控制
使用 <private> 标签包裹敏感内容,claude-mem 会自动跳过这些内容的存储:
<private>API_KEY=sk-xxx</private>
7. 安装与配置
7.1 快速安装
一行命令安装:
npx claude-mem install或在 Claude Code 中通过插件市场安装:
/plugin marketplace add thedotmack/claude-mem/plugin install claude-mem
安装后重启 Claude Code 即可生效。
7.2 系统要求
-
Node.js >= 18.0.0 -
Claude Code 最新版本(需支持插件) -
Bun(自动安装) -
uv Python 包管理器(自动安装,用于向量搜索) -
SQLite 3(内建)
7.3 手动调用方式
在 Claude Code 中使用 /claude-mem:mem-search 技能触发搜索,或直接让 Claude 使用 MCP 工具进行搜索。Claude 会自动按三层工作流执行搜索、过滤、获取详情的步骤。
8. 总结
claude-mem 的 mem-search 功能解决了 AI 编程助手最痛的一个问题——记忆断层。它的设计理念值得借鉴:
-
渐进式披露:先索引后详情,用最小 token 成本定位目标 -
三层过滤:search → timeline → get_observations,层层递进 -
批量获取:合并 HTTP 请求,减少网络开销 -
多维度检索:关键词、类型、日期、项目名、语义向量多种过滤维度 -
自动采集:通过生命周期钩子无感记录,开发者零负担
对于长期维护项目的开发者来说,claude-mem 不只是一个搜索工具,更是一个项目知识管理系统的雏形——自动记录”做了什么””为什么这么做””当时发现了什么”,让每一次会话的知识都不会丢失。
参考文献
[1] claude-mem GitHub 仓库:https://github.com/thedotmack/claude-mem[2] claude-mem 搜索工具官方文档:https://mintlify.wiki/thedotmack/claude-mem/usage/search-tools[3] claude-mem 插件评测 2026:https://trigidigital.com/blog/claude-mem-plugin-review-2026/[4] Claude Code 插件、MCP 和工具完整列表:https://codelove.tw/@tony/post/ayYEMa