 夜雨聆风
夜雨聆风





非技术PM的文档自救指南:从被怼到被夸

在做产品经理这么多年,带过很多刚入门的产品经理。
他们大多有很强的专业知识,很好的用户同理心,敏锐的客户思维。他们能写出让老板点头的商业分析,能做出让客户满意的方案汇报。
但一到了开发评审会,就原形毕露。
开发会追问一些你根本没想过的问题:
“这个功能涉及资金变动,如果用户重复点击怎么办?”
“批量导入支持多少条数据?超过上限怎么处理?”
“这个操作需要权限校验吗?不同角色的可见范围一样吗?”
“数据是物理删除还是逻辑删除?删除后能恢复吗?”
他们懂用户痛点、懂商业价值、懂交互体验,但没办法像开发或者测试一样,从他们的视角考虑得那么全面。
非技术出身的PM,有个天然的盲区:他们能写出流畅的主流程,但想不到各种异常分支。他们能设计出完美的界面,但考虑不到网络中断、数据为空、权限不足这些边缘场景。
这不是能力问题,是术业有专攻。产品经理当然也能把这些边界情况都想清楚,但需要消耗大量的精力去处理那些20%的极端场景。而开发、测试天天和这些边界打交道,他们的大脑已经形成了条件反射。
结果就是,开发拿到文档,发现到处都是模糊地带:
-
“这个场景没写,我先按最简单的方式做?” -
“这个异常没定义,我直接报错?” -
“这个限制没说明,我先不做上限?”
问产品经理,得到的回答往往是:”这个……我回头补充一下”。然后补丁越打越多,债务越积越重,没过几个月就不得不重构。
更可怕的是闭门造车——凭感觉写市场分析、拍脑袋定技术方案、想当然地假设用户行为。这些臆想出来的”事实”,在评审会上很容易被戳穿。
GPT时代的虚假繁荣

GPT刚出来的时候,很多产品经理天真地认为:产品经理的春天来了。
他们用的最多的就是和AI对话。通过提示词工程,渐进明细地梳理出相对完整的文档。AI会顺着你的思路补充细节,会肯定你的想法,会让你觉得这份文档越来越丰满、越来越无懈可击。
但对话式AI有个天然的问题:它会顺着你的思路往前走,不撞南墙不回头。
AI会不断强化你的既有观点,你说”用户需要这个功能”,它说”好的,我帮你补充细节”;你说”技术实现应该不难”,它说”是的,这个方案可行”。
你以为它在帮你完善文档,其实它在哄你开心。
在AI的不断吹捧下,你越写越high,觉得这篇文档完美无缺。主流程写得很顺,交互设计很精美,商业逻辑很自洽。
但你没发现,AI也可以帮你写异常处理、边界限制、数据校验,但它写出来的几乎都不可用——不是基于你这个项目进行的分析,中间夹杂着各种看不见的错漏。而且上下文的限制导致AI输出的内容顾尾不顾头。
最后拿到评审会上,在开发的追问下你才发现,自己写的只是一份理想状态下的美好幻想,而不是一份经得起现实考验的需求文档。
你以为是AI在帮你完善文档,其实是AI在陪你演一出自我感动的独角戏。
从”独角戏”到”评审会”
多智能体写作的概念出来后,我开始重新思考这个问题。
既然AI可以扮演各种角色,为什么不能模拟一个产品团队的专家会审?不是让一个AI陪你聊天,而是让多个负责不同领域的AI Agent一起,互相质疑,互相补充,共同产出一份经得起各方审视的文档。
核心思路:
产品经理还是那个产品经理——提出需求、理解客户、把控方向。但不再是独自面对空白文档发愁,而是有一群”专家”帮你填补不擅长的领域。
-
你负责提出需求和理解客户 -
技术专家负责追问技术细节 -
行业专家负责验证市场数据 -
UX专家负责明确交互规则 -
合规专家负责检查法律风险 -
……
你不再是那个什么都要懂、什么都写不全的”全能PM”,而是那个提出正确问题、整合各方意见、做出最终决策的”幕后推手”。
PM-Copilot
基于这个思路,我开始设计PM Copilot的框架。
第一步:定义专家角色
真实的研发团队有哪些角色?产品经理、架构师、开发、测试、运营、法务……每个角色都有自己的专业领域和审视角度。
我最终定义了16类专家,包括但不限于:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
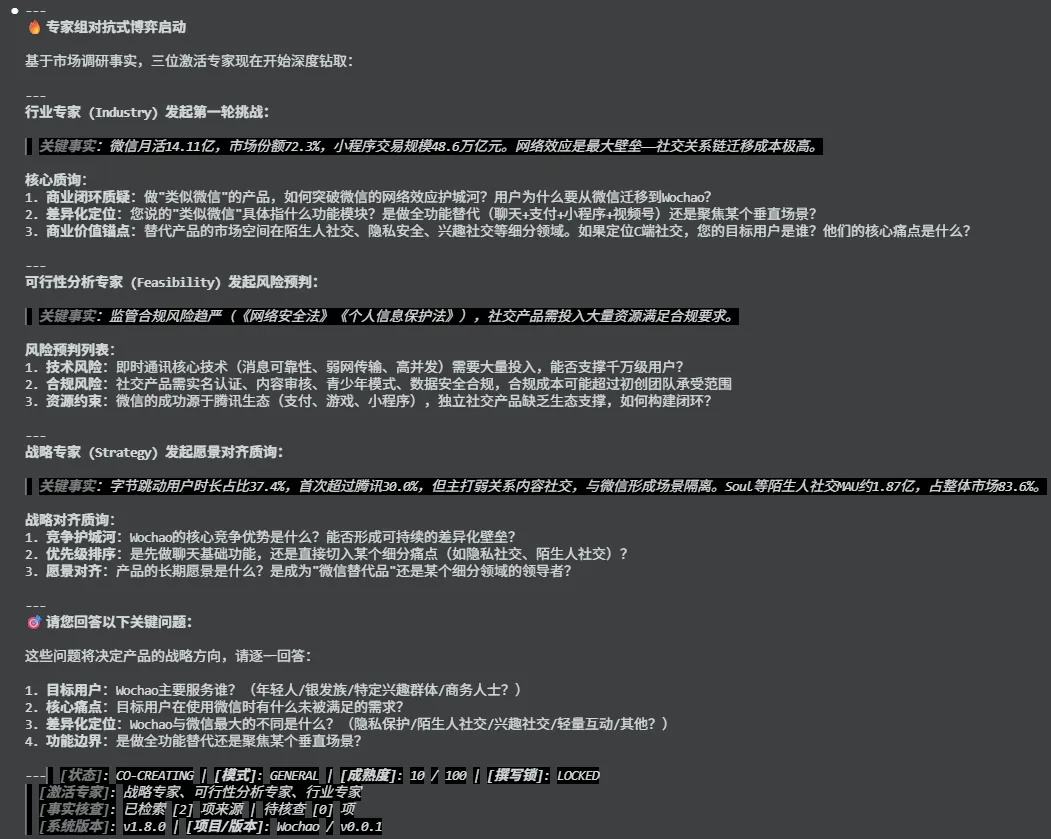
每个专家都有自己的博弈视角——不是无条件附和,而是会站在自己的专业角度提出质疑。
第二步:设计四阶段闭环
真实的评审会不是一言堂,是多轮讨论、反复打磨。
我设计了四阶段闭环:
第一阶段:初始化
-
系统识别你要写什么文档 -
自动组建对应的专家组 -
激活相关专家,准备开始博弈
第二阶段:对抗式共创(核心)
-
专家组进行≥3轮深度钻取 -
每轮每个专家都会基于自己的视角提问 -
你的回答会被追问,直到各方满意 - 成熟度达到80分,才解锁撰写阶段
第三阶段:分布式撰写
-
各专家独立撰写自己负责的部分 -
行业专家写业务规则 -
开发专家写技术逻辑 -
UX专家写交互流程 -
最后由一个”Creator”整合成完整文档
第四阶段:内部审计
-
各专家确认自己的意图被正确呈现 -
检查跨模块的一致性 -
发现问题,回退修正 -
审计通过,输出最终文档
第三步:解决”幻觉”问题
设计到这一步,我发现还有一个关键问题:AI会幻觉。
它可能会:
-
编造不存在的行业数据 -
假设技术方案可行但实际上有坑 -
臆想用户行为但不符合真实情况
如果让AI专家凭感觉说话,那和闭门造车没什么区别。
所以我引入了外部信息检索强制协议:
- 禁止臆想:专家不能凭感觉说”市场很大”、”用户需要”
- 必须检索:每个关键结论都必须基于可验证的外部信息
- 事实审计:审计阶段会检查每个数据是否有来源
不是基于事实的结论,成熟度打不到80分,进不了撰写阶段。
这套框架能做什么
1. 填补非技术PM的技术盲区
你不需要懂复杂的技术概念。系统里的”全栈开发专家”会主动追问那些你容易忽略的场景:
-
“如果用户同时操作,系统怎么处理?” -
“网络断了数据怎么办?” -
“这个字段为空的时候有默认值吗?”
你只需要回答业务场景,专家会帮你把这些边界情况都定义清楚,写出完整的技术实现方案。
2. 杜绝”我觉得”式的臆想
“我觉得用户需要这个功能”、”我觉得市场很大”
这种话在对抗阶段就会被challenge:
-
“用户调研样本量多少?” -
“市场数据从哪来?TAM/SAM/SOM分别是多少?”
每个结论都必须有数据来源。
3. 确保文档质量不依赖个人状态
今天状态好写得细,明天赶时间就写得糙——这种情况不会再有。
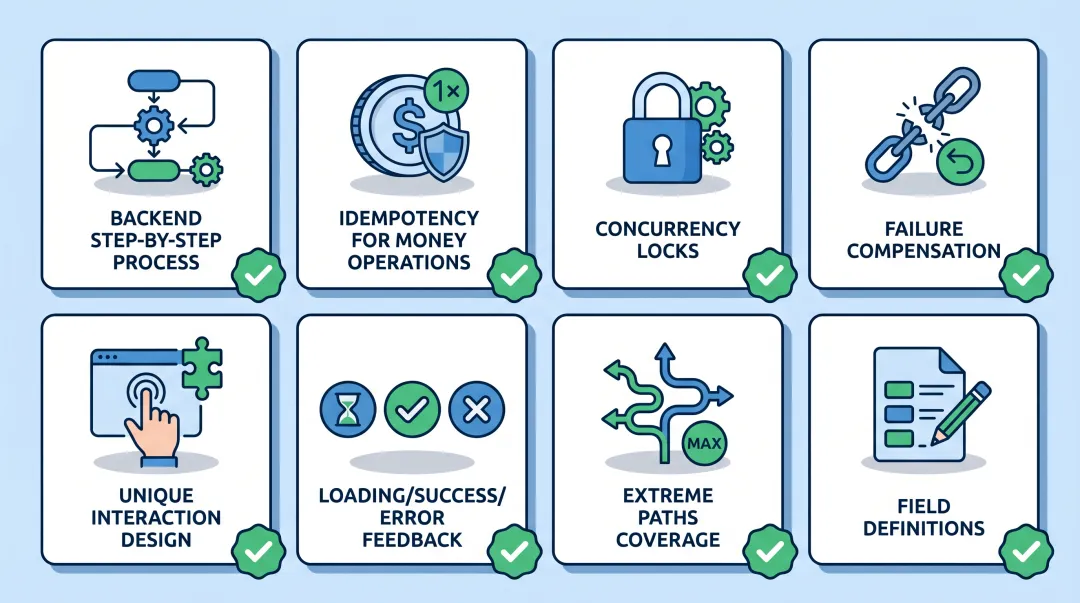
系统内置了硬核交付协议,强制要求8项标准必须达标:
-
后端处理流程必须Step-by-step描述 -
涉及资金操作必须有幂等性方案 -
并发场景必须有锁机制说明 -
失败必须有补偿和回滚流程 -
交互方案必须唯一确定 -
必须定义加载/成功/失败反馈样式 -
必须覆盖极端路径(无权限、断网、空数据) -
字段必须定义类型、长度、约束、缺省值
再加上外部信息检索强制协议,达不到标准,系统不会让你交付。
4. 自动检查跨文档一致性
产品迭代久了,PRD v1.0、v2.0、v3.0之间经常出现逻辑矛盾。审计阶段会检查:
-
战略对齐:当前需求是否偏离产品愿景? -
逻辑对齐:技术约束是否落实? -
术语对齐:同一个概念在不同文档里叫法一致吗? -
事实对齐:同一个数据在不同文档里是否一致? -
边界对齐:v1.0定义的约束在v2.0中是否被无意中打破?
确保文档迭代过程中不出现隐性矛盾。
怎么用
第一步:准备环境
首先需要安装Claude Code CLI,然后克隆这个仓库。
# 安装Claude Code CLI :https://claude.ai/code # 克隆仓库: git clone https://github.com/ccforever123/pm-copilot.git第二步:开始协作
在Claude Code中打开项目目录,系统会自动识别并加载配置。在和AI对话过程中,项目结构会自动创建,不需要手动创建目录。
举例:新产品立项
我对AI说:我要做一个类似微信的产品。,它会先为这个产品构建一个独立的项目文档,然后开始判断,需要从什么内容开始撰写。
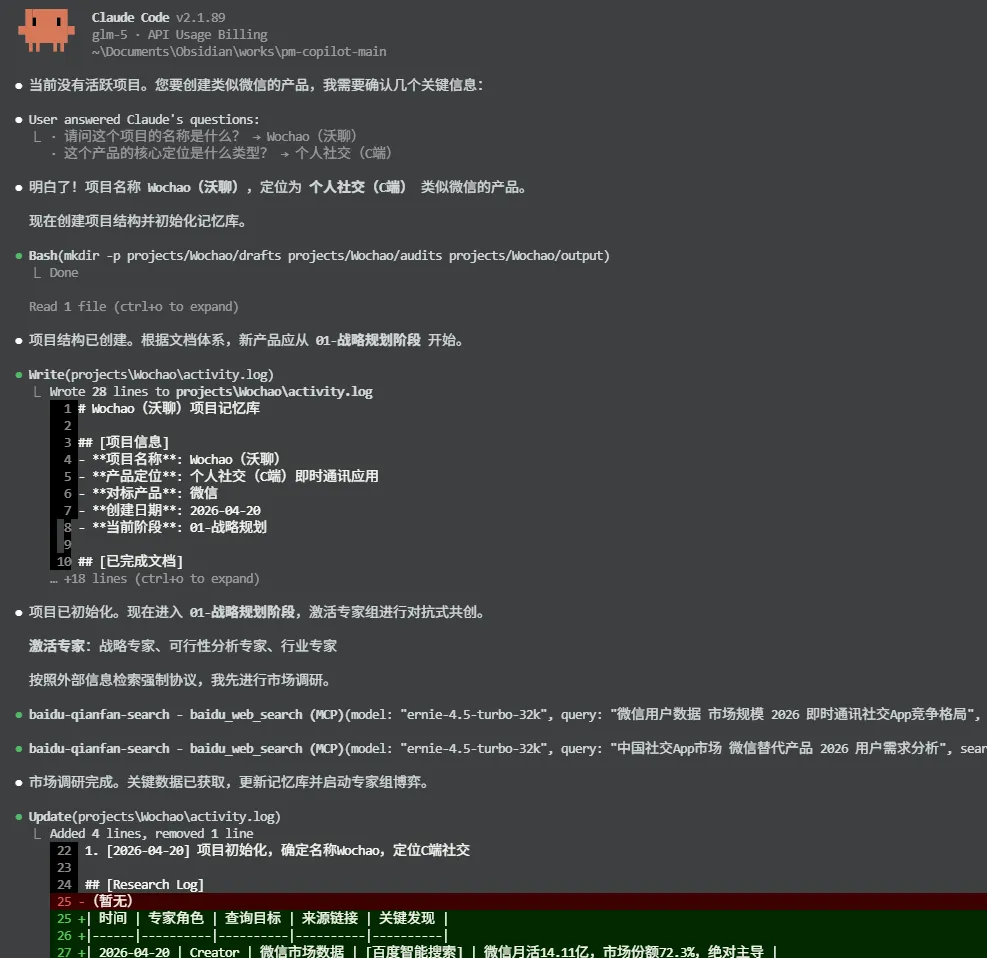
你回答问题,专家追问,每个结论都必须有数据来源。成熟度逐渐提升。
第三步:获取交付物
审计通过后,在projects/my-project/output/目录下获取最终的Word文档。
每份文档都附带:
-
完整的需求描述 -
技术实现细节 - 所有关键事实的数据来源引用
- 边界场景和极端情况的处理方案
- 跨版本一致性检查报告
开发拿到这份文档,不再需要反复问你”如果……怎么办”,因为所有的边界情况都已经被专家考虑过、定义清楚了。
适合谁用
- 非技术出身的产品经理
:不用再硬啃技术概念,让”开发专家”帮你基于技术文档写技术部分 - 刚入门的产品经理
:学习完整的PRD标准,养成基于事实做决策的习惯 - 中级产品经理
:提效,把重复性的格式工作交给AI,自己专注产品思考 - 高级产品经理
:建立团队文档标准,杜绝闭门造车
写在最后
这套框架的目标不是替代产品经理,而是把PM从繁琐的格式、跨领域知识缺口和臆想陷阱中解放出来。
你依然需要提出好问题、理解客户需求、判断专家博弈的质量、做最终决策、对结果负责。
但你可以专注于你擅长的事——理解用户、定义需求、把控方向。而不是纠结”这个字段要不要加约束”,更不用担心”这个数据是不是我臆想出来的”。
毕竟,好的PRD不是一个人写出来的,是一群专家基于事实博弈出来的。
而你,是那个提出正确问题、整合各方意见、做出最终决策的幕后推手。
GitHub: https://github.com/ccforever123/pm-copilot
欢迎Star、Fork、提Issue。
/ 作者:松鼠
/ 公众号:松鼠的AI笔记