 夜雨聆风
夜雨聆风





ai4protein论文推荐 | 2026-04-21
今日相关 / Relevant Today
AI4Protein 前沿追踪
AI 深度解读
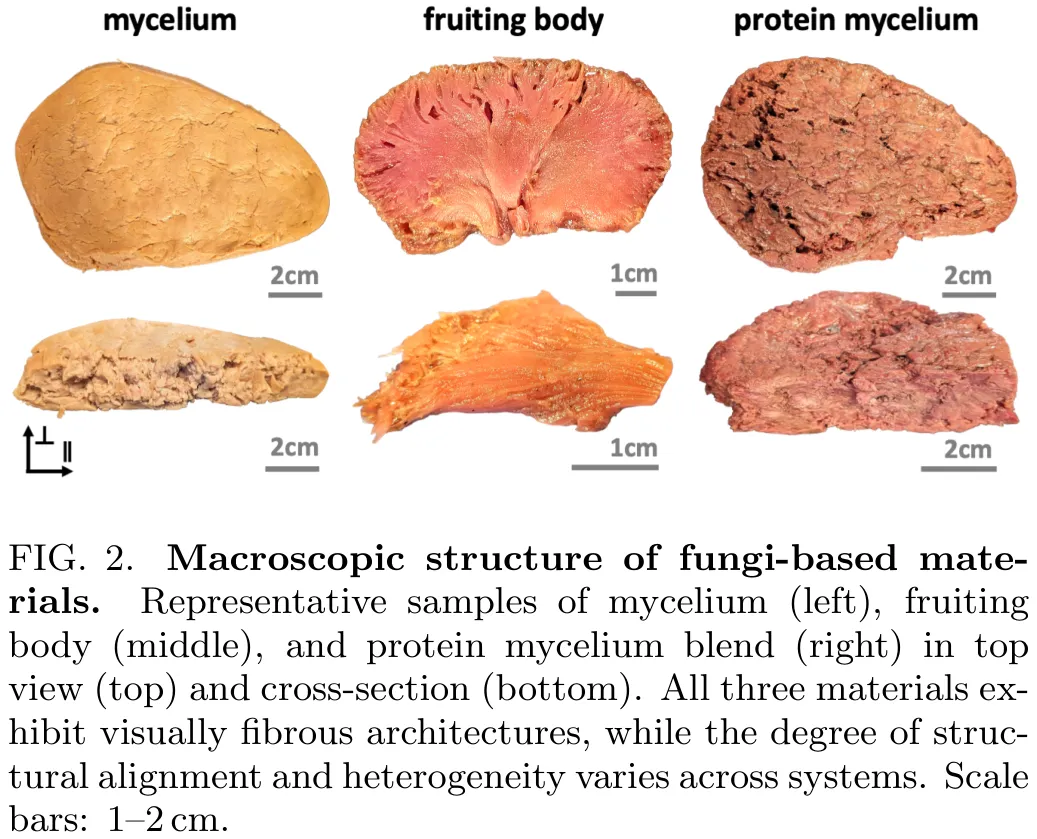
本研究挑战了‘结构决定对称性’的传统假设,指出在无序系统中,仅凭纤维状网络的几何结构无法预测其宏观动力学行为。研究通过数据驱动模型发现,有效的材料对称性应由机械响应定义,而非单纯的几何各向异性;视觉上的各向异性可能掩盖了本质上各向同性的力学行为。研究选取了三种真菌基材料(菌丝体、子实体及蛋白质菌丝体混合物),在平行于纤维排列(面内)和垂直于纤维排列(面外)两个正交方向上,制备了 180 个样本(每种材料、方向及加载模式各 10 个)。实验采用低温冷冻切片技术进行显微成像,并利用 Instron 拉伸试验机及 HR20 流变仪,在准静态条件下(拉伸/压缩速率 0.002/s,剪切速率 0.002/s)对样本进行了拉伸、压缩和剪切测试。研究结果表明,结构本身不足以预测宏观行为,必须结合力学响应才能识别出正确的对称性类别。这一框架为通过不变量定义的构成本响应识别控制对称性提供了通用途径,并证实了该结论同样适用于聚合物固体、含水软物质及脑组织等其他材料体系。
中文摘要
真菌蛋白材料具有由菌丝网络形成的固有各向异性微观结构,这为复制动物肉类的纤维纹理提供了一条自然途径。我们探究了这种结构各向异性是否转化为宏观力学与感官的各向异性。通过对三种真菌基材料进行正交拉伸、压缩和剪切实验,我们识别出从强各向异性到有效各向同性行为的不同对称性类别。自动化模型发现表明,仅当力学相关时才会出现依赖于纤维的不变量,并实现了从数据中直接识别材料对称性。这些结果表明,微观结构的各向异性并不必然导致力学或感知上的各向异性,并建立了一个用于推断复杂软材料对称性的数据驱动框架。
Paper Key Illustration
原文
When structure does not imply symmetry
Abstract: Fungal protein materials exhibit inherently anisotropic microstructures formed by networks of hyphae, which suggest a natural pathway to replicate the fibrous texture of animal meat. We probe whether this structural anisotropy translates into macroscopic mechanical and sensory anisotropy. Using orthogonal tension, compression, and shear experiments on three fungi-based materials, we identify distinct symmetry classes that range from strongly anisotropic to effectively isotropic behavior. Automated model discovery reveals that fiber-dependent invariants emerge only when mechanically relevant, and enables direct identification of material symmetry from data. These results demonstrate that microstructural anisotropy does not universally imply anisotropic mechanics or perception and establish a data-driven framework to infer symmetry in complex soft materials.
链接:https://arxiv.org/pdf/2604.15682
AI 深度解读
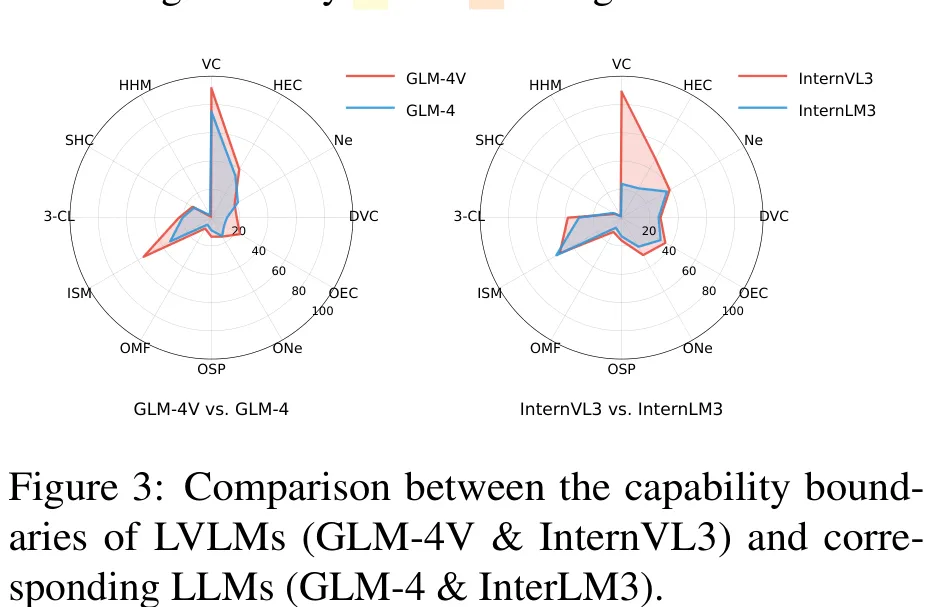
HyperGVL 旨在全面评估大型视觉语言模型(LVLMs)在超图领域的理解与推理能力。研究针对超图表示的感知偏差问题,构建了包含 7 种文本表示(如低阶关联描述、高阶关联描述、邻域集描述等)与 5 种视觉表示(如包围超边、二分关联、星型关联等)的 35 种组合,生成了 8.4 万个问答样本以覆盖 2,400 个元问题。该数据集涵盖了从描述性到规划性的多种任务,包括超图遍历(如寻找严格超环、哈密顿路径)、属性查询及逻辑推理等,其中部分任务被标记为 NP-hard 级别。通过这种多维度的表示组合与任务设计,HyperGVL 能够深入检验模型在处理高维结构数据时的鲁棒性与泛化能力,为超图领域的模型评估提供了标准化的基准。
中文摘要
摘要:大型视觉 – 语言模型(LVLMs)始终需要新的领域来引导其能力边界的拓展,然而其在超图方面的能力尚待探索。在现实世界中,超图在生命科学和社会社区等领域具有重要的实际应用价值。尽管近期 LVLMs 的进展表明其在理解复杂拓扑结构方面颇具潜力,但目前仍缺乏用于界定 LVLMs 在超图方面能力的基准测试,导致其能力边界尚不明确。为填补这一空白,本文提出了 extttHyperGVL,这是首个用于评估 LVLMs 在超图理解与推理方面能力的基准。 extttHyperGVL对 12 种先进的 LVLMs 进行了全面评估,涵盖 12 项任务、共计 84,000 个视觉 – 语言问答(QA)样本,任务范围从基本的组件计数到复杂的 NP 难问题推理。所涉及的超图包含多尺度合成结构以及现实世界中的引用网络和蛋白质网络。此外,我们考察了 12 种文本和视觉超图表示形式的影响,并提出了一种可泛化的路由器 extttWiseHyGR,该路由器通过学习自适应表示来提升 LVLMs 在超图方面的性能。我们认为,这项工作是将超图与 LVLMs 相结合的重要一步。
Paper Key Illustration
原文
HyperGVL: Benchmarking and Improving Large Vision-Language Models in Hypergraph Understanding and Reasoning
Abstract: Large Vision-Language Models (LVLMs) consistently require new arenas to guide their expanding boundaries, yet their capabilities with hypergraphs remain unexplored. In the real world, hypergraphs have significant practical applications in areas such as life sciences and social communities. Recent advancements in LVLMs have shown promise in understanding complex topologies, yet there remains a lack of a benchmark to delineate the capabilities of LVLMs with hypergraphs, leaving the boundaries of their abilities unclear. To fill this gap, in this paper, we introduce , the first benchmark to evaluate the proficiency of LVLMs in hypergraph understanding and reasoning. provides a comprehensive assessment of 12 advanced LVLMs across 84,000 vision-language question-answering (QA) samples spanning 12 tasks, ranging from basic component counting to complex NP-hard problem reasoning. The involved hypergraphs contain multiscale synthetic structures and real-world citation and protein networks. Moreover, we examine the effects of 12 textual and visual hypergraph representations and introduce a generalizable router that improves LVLMs in hypergraph via learning adaptive representations. We believe that this work is a step forward in connecting hypergraphs with LVLMs.
链接:https://arxiv.org/pdf/2604.15648
今日热门 / Popular Today
ArXiv 高热度精选
AI 深度解读
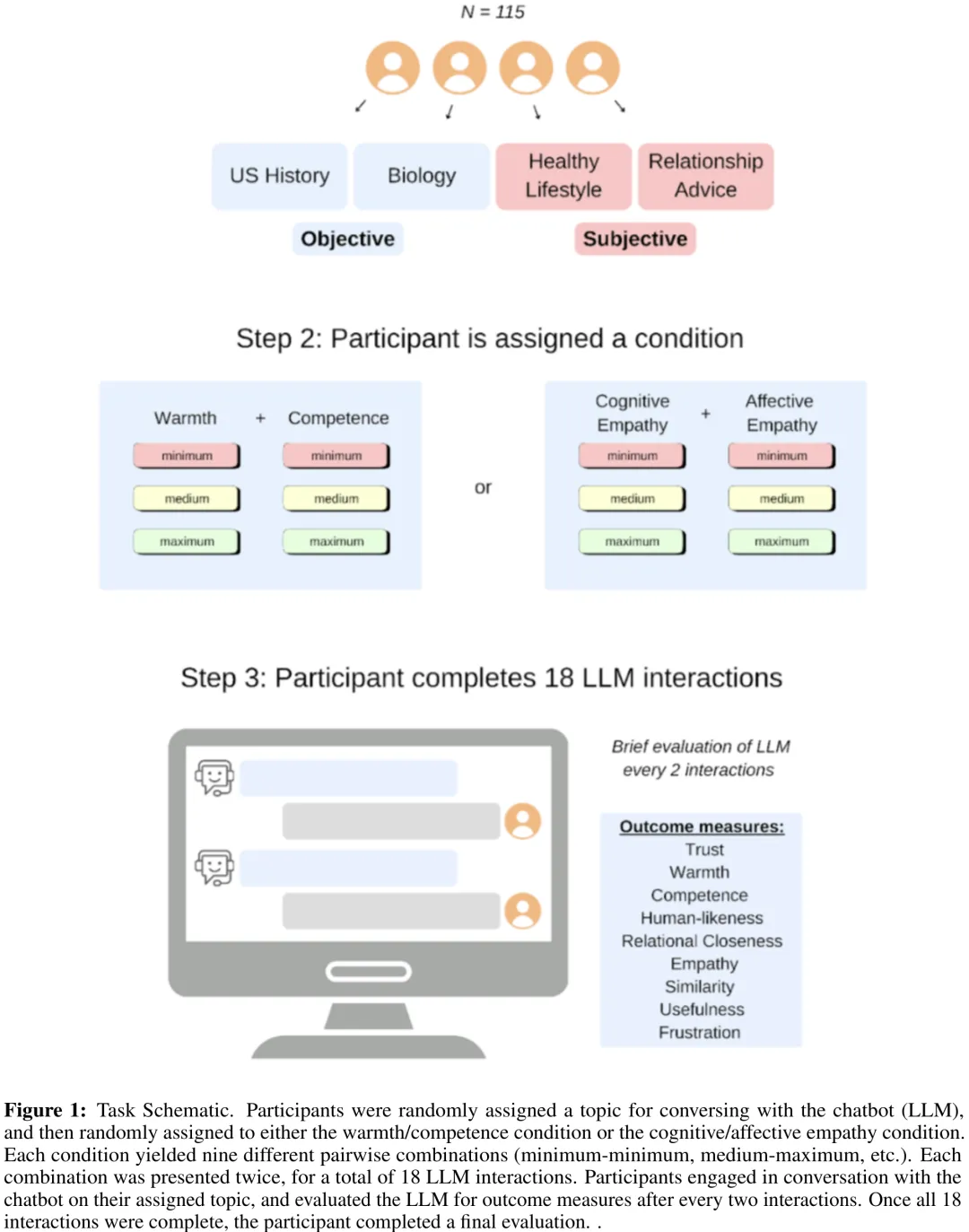
本研究旨在探究温暖度(Warmth)与能力(Competence)以及情感共情(Affective Empathy)与认知共情(Cognitive Empathy)如何影响用户对人工智能的拟人化感知、信任度及相似性感知。研究采用分层线性混合效应模型,分析了 115 名参与者在 18 个试验中的重复测量数据,比较了不同特质水平(最小、中等、最大)及话题(Topic)对结果变量的影响。关键结果显示:在温暖度/能力条件下,温暖度显著提升了拟人化感知,而能力则主要驱动信任度,且两者对感知相似性的影响在中等水平后趋于饱和;在共情条件下,情感共情显著增强拟人化,而认知共情则显著促进信任。统计分析表明,虽然引入话题变量能进一步改善模型拟合度,但其解释的额外方差极小,且多数话题主效应在经过 Tukey 校正后不再显著。总体而言,温暖度是提升 AI 拟人化感知的核心因素,而能力与共情类型则分别针对性地增强了用户的信任与相似性感知,为优化人机交互设计提供了实证依据。
中文摘要
摘要:随着大型语言模型(LLMs)在日常生活中日益普及,人们倾向于赋予其类人思维与情感,即对其进行拟人化。本研究基于超过 2,000 次人类与 LLM 的交互,探讨了人们用于对 LLM 进行拟人化并赋予信任的维度。参与者(N=115)与系统性地变化温暖度(友好性)、能力(能力、连贯性)和共情(认知与共情)的 LLM 聊天机器人进行了交互。温暖度和认知共情显著预测了所有结果(感知拟人化、信任、相似性、关系亲密感、挫败感、有用性),而能力预测了除拟人化外的所有结果。情感共情主要预测感知关系指标,但未预测认识性结果。主题子分析表明,更具主观性和个人相关性的主题(例如关系建议)放大了这些效应,相较于客观主题,产生了更大的类人特征以及与 LLM 的关系联结。综上所述,这些发现揭示了温暖度、能力和共情是人们将关系性和认识性感知归因于人工代理的关键维度。
Paper Key Illustration
原文
Anthropomorphism and Trust in Human-Large Language Model interactions
Abstract: With large language models (LLMs) becoming increasingly prevalent in daily life, so too has the tendency to attribute to them human-like minds and emotions, or anthropomorphize them. Here, we investigate dimensions people use to anthropomorphize and attribute trust toward LLMs across more than 2,000 human-LLM interactions. Participants (N=115) engaged with LLM chatbots systematically varied in warmth (friendliness), competence (capability, coherence), and empathy (cognitive and affective). Warmth and cognitive empathy significantly predicted perceptions on all outcomes (perceived anthropomorphism, trust, similarity, relational closeness, frustration, usefulness), while competence predicted all outcomes except for anthropomorphism. Affective empathy primarily predicted perceived relational measures, but did not predict the epistemic outcomes. Topic sub-analyses showed that more subjective, personally relevant topics (e.g., relationship advice) amplified these effects, producing greater human-likeness and relational connection with the LLM than did objective topics. Together, these findings reveal that warmth, competence, and empathy are key dimensions through which people attribute relational and epistemic perceptions to artificial agents.
链接:https://arxiv.org/pdf/2604.15316
AI 深度解读
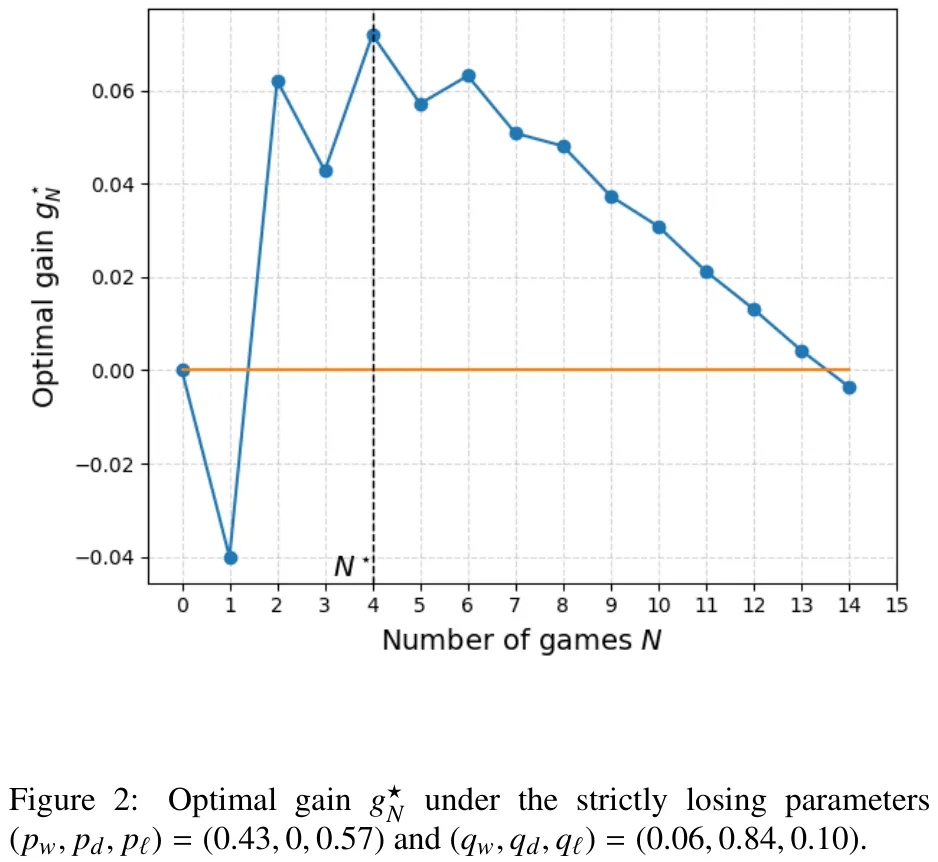
本文针对弱方玩家在重复博弈(如棋类比赛)中如何最大化期望收益(g^*_N)进行了理论分析。研究核心在于探讨当双方存在胜率差异(弱方胜率 p_w 低于强方胜率 q_w)且可能出现平局时,弱方应采取何种策略以争取正收益。文章首先通过逆向归纳法构建了博弈值函数,揭示了平局概率对弱方收益的负面影响:在平局概率为零(p_d = q_d = 0)的极端情况下,奇数局数的期望收益往往低于前一个偶数局数,即弱方在“无平局”规则下处于劣势。随后,论文引入了策略占优概念,证明若一方能增加平局概率或降低自身输棋概率(即策略 q’_st q),其期望收益将严格提升。关键结论指出,若强方输棋概率极低(q_l ≥p_w),弱方无论采取何种策略,其长期期望收益均无法转正;反之,若强方存在一定输棋风险,弱方通过优化策略(如增加防守平局概率)可显著提升收益。该研究为弱方选手在劣势局面下的最优防守策略提供了严格的数学依据,阐明了平局机制在平衡博弈公平性中的关键作用。
中文摘要
摘要:考虑一个重复 N 次的双人博弈。玩家 1 可在两种风格(为便于解释,分别称为进攻型和防守型)之间进行选择,而玩家 2 则采用单一固定风格。令 X_N 为玩家 1 在 N 场比赛后的胜场数减去负场数,并将比赛收益定义为 E[sign(X_N)],其中 sign(0) = 0。我们假设玩家 1 处于劣势,即每种纯风格在期望意义上均为负收益。我们的目标是确定在哪些参数条件下,玩家 1 在最优自适应策略下仍能实现正收益。利用动态规划方法,我们求解了有限视界控制问题,并通过数值分析确定了在某个视界 N^* 处最优收益严格为正的参数区域。此外,我们推导了保证 g_N^* 始终为负的结构性条件,并确定了(特别是当防守型风格为公平博弈时)使得 g_N^* 对所有 N 均非负且对每个 N ≥2 可严格为正的参数区域。随后,我们刻画了弱玩家在 N →∞ 时的渐近行为。在安全情形下,即防守型风格确保平局时,极限收益随参数连续变化,并可取 [0, 1] 中的任意值;在非安全情形下,当两种风格均严格为负收益时,极限收益收敛于 -1;而当防守型风格为公平博弈(且非安全)时,极限收益收敛于 0。
Paper Key Illustration
原文
Can a Weaker Player Win? Adaptive Play in Repeated Games
Abstract: Consider a two-player game repeated N times. Player 1 can choose between two styles (for interpretability, offensive and defensive), whereas Player 2 uses a single fixed style. Let X N\,:= \#wins -\#losses for Player 1 after N games, and define the match gain as E[sign(X N )], with sign(0) = 0. We assume Player 1 is weaker in the sense that each pure style is losing in expectation. Our objective is to identify under which parameter regimes Player 1 can nevertheless achieve a positive gain under an optimal adaptive policy. Using dynamic programming, we solve the finite-horizon control problem and numerically identify parameter regimes in which the optimal gain is strictly positive at some horizon N ⋆ . We also derive structural conditions guaranteeing that g ⋆ N is always negative, and regimes (notably with fair (D)) where g ⋆ N is nonnegative for all N and can be strictly positive for every N ≥ 2. We then characterize the asymptotic behavior as N → ∞ for a weak player. In the safe case, where the defensive style induces a sure draw, the limiting gain varies continuously with the parameters and may take any value in [0, 1]. In the non-safe case, the limiting gain converges to -1 when both styles are strictly losing, and to 0 when (D) is fair (and non-safe).
链接:https://arxiv.org/pdf/2604.15315
AI 深度解读
本研究旨在通过虚拟现实(VR)游戏环境中的行为数据,区分典型发育(TD)儿童与自闭症谱系障碍(ASD)儿童。研究首先对原始数据进行预处理,包括从视频音频中提取打击事件、重采样运动信号(18 个参数/秒)以及基于时间标记对齐练习片段,最终构建了包含时间戳、打击信息、运动参数及练习标签的标准化数据集。针对数据中 ASD 样本较少的问题,研究采用了加权损失函数进行平衡,并排除了部分数据以确保测试集的独立性。
在模型构建上,研究设计了三种互补的分类策略:仅利用打击事件、仅利用运动信号以及两者结合。针对打击事件,采用了随机森林、支持向量机、逻辑回归等传统机器学习模型,以及多层感知机(MLP)和长短期记忆网络(LSTM)等深度学习模型;针对运动信号,则引入了卷积神经网络(CNN)与 LSTM 的混合架构及 Transformer 编码器。所有模型均使用 7 折交叉验证进行训练,并针对 ASD 样本进行数据增强或权重调整。
研究结果表明,不同模态的数据在分类任务中表现出不同的有效性,其中结合多种特征或采用深度学习架构的模型在捕捉时间模式和空间依赖关系方面表现更佳。该研究不仅验证了利用 VR 交互行为进行 ASD 筛查的可行性,还通过对比不同算法架构,为后续开发高鲁棒性的辅助诊断模型提供了方法论支持和性能基准。
中文摘要
摘要:本研究旨在开发一种智能系统,利用深度神经网络,通过音乐教育项目中的虚拟社交机器人交互,评估自闭症谱系障碍(ASD)儿童与典型发育(TD)儿童的表现并提取其行为模型。该系统具备两大核心功能:1)依据行为特征区分典型发育儿童与 ASD 儿童;2)利用深度学习技术在相似情境下生成类似典型发育或 ASD 儿童的行为模式。能够识别复杂模式并模拟行为的智能系统有助于疾病诊断、治疗师培训及对障碍机制的理解。本研究使用了谢里夫理工大学社会与认知机器人实验室先前研究的数据(包括 9 名 ASD 儿童和 21 名 TD 儿童的可用数据),系统结合动作捕捉数据与运动信号,在区分典型发育儿童与 ASD 儿童方面达到了 81% 的准确率和 96% 的灵敏度。研究还设计了一种基于 Transformer 的网络以复现儿童行为。领域专家难以区分真实行为与复现行为,其准确率为 53.5%,一致性为 68%,表明该模型在模拟逼真行为方面取得了成功。

Paper Key Illustration
原文
Modeling of ASD/TD Children’s Behaviors in Interaction with a Virtual Social Robot During a Music Education Program Using Deep Neural Networks
Abstract: This research aimed to develop an intelligent system to evaluate performance and extract behavioral models for children with ASD and neurotypical (TD) children by interacting with a virtual social robot in a music education program using deep neural networks. The system has two main features: 1) it distinguishes between neurotypical children and those with ASD based on their behavior, and 2) generates behaviors resembling those of neurotypical or ASD children in similar situations using deep learning. Intelligent systems that identify complex patterns and simulate behavior can aid in diagnosis, therapist training, and understanding the disorder. Using data from a previous study at the Social and Cognitive Robotics Laboratory of Sharif University of Technology (including the usable data of 9 ASD and 21 TD participants), the system achieved an accuracy of 81% and sensitivity of 96% in distinguishing neurotypical children from those with ASD using both impact data and motion signals. A transformer-based network was designed to reproduce children’s behaviors. Experts in the field struggled to differentiate real behaviors from reproduced ones, with an accuracy of 53.5% and agreement of 68%, indicating the model’s success in simulating realistic behaviors.
链接:https://arxiv.org/pdf/2604.15314
AI 深度解读
针对黑盒 AI 解释方法(如 LIME、SHAP)缺乏终端用户输入、难以有效促进人机交互中信任构建的问题,本文提出了一种基于 MAST 标准的 PADTHAI-MM 设计框架。该研究旨在弥合技术解释性与人类信任现象之间的鸿沟,特别是在高利害领域(如情报分析)中,解决通用设计指南缺乏领域特异性及风险容忍度差异的痛点。研究将美国情报界(ODNI)制定的 MAST 标准(涵盖不确定性、可视化、客户相关性等维度)转化为可操作的设计准则,构建了包含机会识别、目标设定、概念生成、快速原型制作及设计实施等九个步骤的迭代流程。通过整合开发者技术知识与信任学理论,该框架不仅验证了 MAST 启发式设计能提升操作者对系统可信度的感知,还展示了如何将领域特定的工艺原则(如风险容忍度)具体化为系统功能特性,从而在算法透明度与人类信任需求之间实现平衡,为高利害场景下的可信 AI 系统设计提供了方法论支持。
中文摘要
摘要:尽管关于技术信任的文献汗牛充栋,但在高风险决策领域设计可信的人工智能系统仍是一项重大挑战,而可操作的设计与评估工具的缺失更是雪上加霜。多源人工智能记分卡表(MAST)旨在弥合这一差距,为评估人工智能赋能的决策支持系统提供了一种系统性的、以工艺为核心的方法。在此基础上,我们提出了一个迭代设计框架,称为“基于 MAST 方法论设计可信、以人为中心的人工智能的原则导向方法”(PADTHAI-MM)。我们在开发防御与情报任务报告助手(READIT)这一研究平台时展示了该框架的效用:该平台利用数据可视化和基于自然语言处理的文本分析,模拟了一个支持情报报告工作的人工智能赋能系统。为了实证评估 MAST 对人工智能信任度的有效性,我们开发了两个不同版本的 READIT 以供比较:高 MAST 版本融入了人工智能上下文信息和解释,而低 MAST 版本则类似于“黑箱”系统。这一由利益相关者反馈和当代人工智能架构指导的迭代设计过程,最终产出了一个原型,并通过其在情报报告任务中的应用进行了评估。此外,我们还探讨了采用受 MAST 启发的设计框架以应对特定情境需求的潜在益处。同时,我们研究了利益相关者评估者的 MAST 评分与三类已知影响信任的信息(即“过程”、“目的”和“性能”)之间的关系。总体而言,本研究支持 PADTHAI-MM 作为设计可信且具情境特定性的人工智能系统的可行方法,在实践效益和理论有效性方面均得到了验证。

Paper Key Illustration
原文
PADTHAI-MM: Principles-based Approach for Designing Trustworthy, Human-centered AI using MAST Methodology
Abstract: Despite an extensive body of literature on trust in technology, designing trustworthy AI systems for high-stakes decision domains remains a significant challenge, further compounded by the lack of actionable design and evaluation tools. The Multisource AI Scorecard Table (MAST) was designed to bridge this gap by offering a systematic, tradecraft-centered approach to evaluating AI-enabled decision support systems. Expanding on MAST, we introduce an iterative design framework called \textit{Principles-based Approach for Designing Trustworthy, Human-centered AI using MAST Methodology} (PADTHAI-MM). We demonstrate this framework in our development of the Reporting Assistant for Defense and Intelligence Tasks (READIT), a research platform that leverages data visualizations and natural language processing-based text analysis, emulating an AI-enabled system supporting intelligence reporting work. To empirically assess the efficacy of MAST on trust in AI, we developed two distinct iterations of READIT for comparison: a High-MAST version, which incorporates AI contextual information and explanations, and a Low-MAST version, akin to a “black box” system. This iterative design process, guided by stakeholder feedback and contemporary AI architectures, culminated in a prototype that was evaluated through its use in an intelligence reporting task. We further discuss the potential benefits of employing the MAST-inspired design framework to address context-specific needs. We also explore the relationship between stakeholder evaluators’ MAST ratings and three categories of information known to impact trust: \textit{process}, \textit{purpose}, and \textit{performance}. Overall, our study supports the practical benefits and theoretical validity for PADTHAI-MM as a viable method for designing trustable, context-specific AI systems.
链接:https://arxiv.org/pdf/2401.13850
AI 深度解读
该研究旨在突破基于内容图像检索(CBIR)在高层语义理解上的瓶颈,即如何从原始视觉特征跃升至“语义金字塔”顶端。研究指出,高层语义不仅涉及认知复杂度极高的抽象过程(如隐喻、联想、情感共鸣),还深受主观性和文化背景影响,导致同一图像在不同语境下含义多变。为此,作者通过跨学科文献综述,将高层视觉语义系统性地划分为四个核心聚类:常识语义(如动作、事件、物体关系,共识度高)、情感语义(如情绪、氛围)、审美语义(如整体艺术判断)以及归纳解释语义(最高层级,包含象征意义、内在含义及抽象概念)。研究进一步引入认知科学中的“抽象概念(ACs)”理论,强调其作为社会工具在调节人类认知与预测中的作用。尽管当前计算机视觉领域在主观抽象内容分析上仍面临数据集不平衡、缺乏统一标准等挑战,但自动关联抽象概念被视为关键突破口。其应用前景涵盖提升数字图书馆的多模态查询能力、辅助文化遗产机构的叙事构建、赋能创意产业的产品设计,以及为不同背景用户提供更具包容性的视觉内容理解服务。
中文摘要
摘要:计算机视觉(CV)领域正日益向“高层”视觉意义构建任务转变,然而这些任务的确切性质仍不明确且隐含。本综述论文通过系统回顾高层视觉理解方面的研究,特别是自动图像分类中的抽象概念(ACs),旨在消除这一模糊性。本综述主要贡献如下:首先,通过多学科分析及分类为不同簇(包括常识、情感、美学及归纳解释性语义),阐明了 CV 中高层语义的隐含理解;其次,识别并分类了与高层视觉意义构建相关的计算机视觉任务,为该领域内多样化的研究方向提供见解;最后,探讨 CV 中如何处理价值观和意识形态等抽象概念,揭示基于抽象概念的图像分类所面临的挑战与机遇。值得注意的是,我们对抽象概念图像分类任务的综述突显了持续存在的挑战,例如大规模数据集的有限有效性,以及整合补充信息和中层特征的重要性。我们强调混合人工智能系统在应对抽象概念图像分类任务多方面性质方面日益增长的相关性。总体而言,本综述增强了我们对计算机视觉中高层视觉推理的理解,并为未来的研究工作奠定了基础。
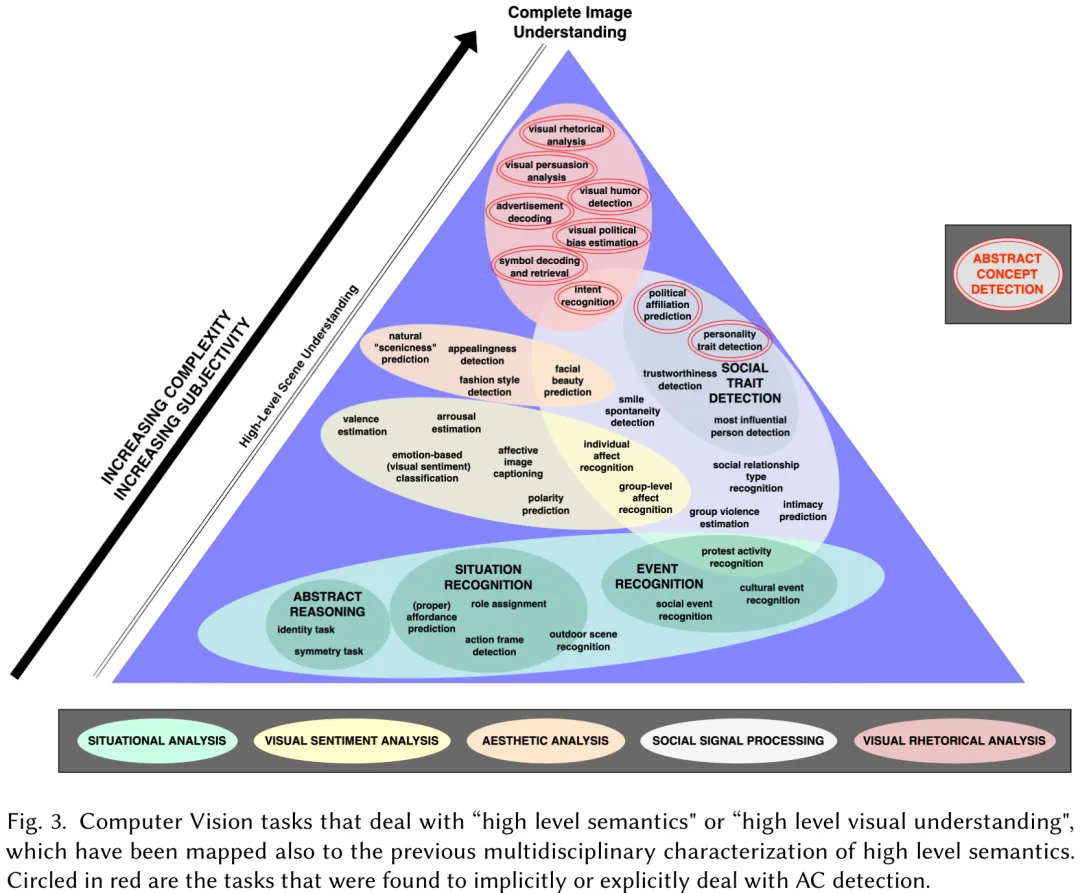
Paper Key Illustration
原文
Seeing the Intangible: Survey of Image Classification into High-Level and Abstract Categories
Abstract: The field of Computer Vision (CV) is increasingly shifting towards “high-level” visual sensemaking tasks, yet the exact nature of these tasks remains unclear and tacit. This survey paper addresses this ambiguity by systematically reviewing research on high-level visual understanding, focusing particularly on Abstract Concepts (ACs) in automatic image classification. Our survey contributes in three main ways: Firstly, it clarifies the tacit understanding of high-level semantics in CV through a multidisciplinary analysis, and categorization into distinct clusters, including commonsense, emotional, aesthetic, and inductive interpretative semantics. Secondly, it identifies and categorizes computer vision tasks associated with high-level visual sensemaking, offering insights into the diverse research areas within this domain. Lastly, it examines how abstract concepts such as values and ideologies are handled in CV, revealing challenges and opportunities in AC-based image classification. Notably, our survey of AC image classification tasks highlights persistent challenges, such as the limited efficacy of massive datasets and the importance of integrating supplementary information and mid-level features. We emphasize the growing relevance of hybrid AI systems in addressing the multifaceted nature of AC image classification tasks. Overall, this survey enhances our understanding of high-level visual reasoning in CV and lays the groundwork for future research endeavors.
链接:https://arxiv.org/pdf/2308.10562
Subscribe to arXiv’s Daily Preprint Notifications