 夜雨聆风
夜雨聆风





OpenClaw 到底是什么?它不是聊天工具,而是 AI Agent 的任务执行层
前言
用户在飞书里说“生成本周周报”,问答系统最多返回一段文本。OpenClaw 要继续读文档和 commit,整理进展、风险、阻塞,套模板,回读缺项,再把草稿发回飞书确认。
这就是它和问答系统的差别。问答系统交付回复,OpenClaw 推进任务状态。很多人第一次接触 OpenClaw,最容易看错对象:界面是对话式的,就以为它只是一个以对话式界面包装的问答系统;能调工具,就以为它是“问答系统加工具调用”。
OpenClaw 不是一个以对话式界面包装的问答系统。它更接近一个任务执行层:接任务、调工具、读结果、决定下一步。
第一章:先分清对象:它处理的是任务,不是问答
起源线索:从回答问题到推进任务
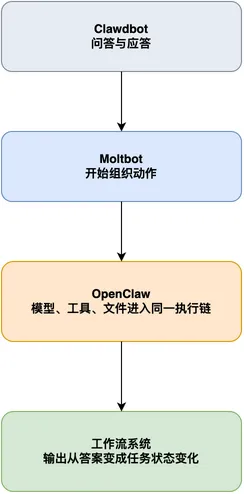
看 OpenClaw 的起源,不必把注意力放在产品名字上。更有价值的是 Clawdbot、Moltbot 和 OpenClaw 这条演进线:它一路从“回答问题”走向“推进任务”。
如果一个产品主要做的是“接收问题,再返回文本”,它再强,也还停留在问答范畴。只有当它开始围绕任务单元组织动作,把文件、工具、模型输出和回读结果放进同一条链路里,它才变成任务系统。
它当然要生成内容,但更重要的是把任务推到“已完成”。这个差异落到工程上很具体:前者看回答像不像样,后者看闭环有没有成立,文件状态有没有变,产物能不能被验收。
周报例子:任务链路必须走到验收

用户在飞书里说“生成本周周报”,OpenClaw 不能只回一句“这是周报”。它要读文档、commit 和任务记录,整理进展、风险、阻塞,再按模板生成草稿,最后检查格式、缺项和口径。不通过,就回到读取或重写阶段。
这才是任务系统和问答系统的差别。问答系统的终点是回复,任务系统的终点是产物状态变化:周报草稿是否生成,格式是否达标,用户能不能确认发送。
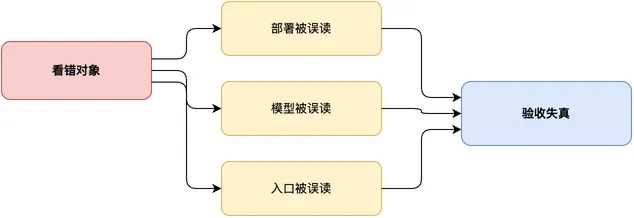
错误理解:把入口、模型和 Skill 都看偏
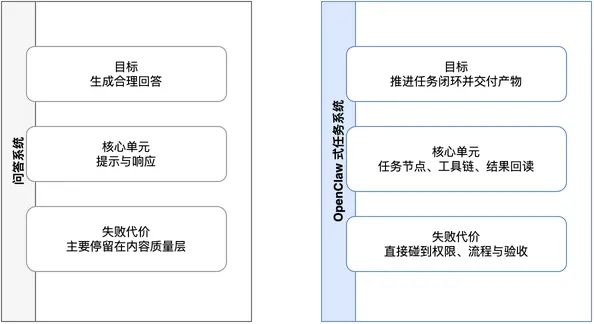
评价 OpenClaw,别只看它答得好不好,要看它有没有把任务往前推。
对象看错,能力都会被误读。部署会被理解成“装个客户端”,模型切换成“换回复风格”,IM 接入成“把聊天结果发到飞书”。但在周报例子里,IM 是入口,模型是推理资源,Skill 是周报做法的契约。
更麻烦的是,它会制造错误预期。用户会以为答得对就算成功;但系统一旦进入工作流,碰到的就是文件状态、任务约束、平台入口、失败回退和产物验收。答案再漂亮,如果任务没有推进,就还是失败。
第二章:再看结构:5 个支柱分别承担什么责任
总览:对象、运行、模型、入口、治理
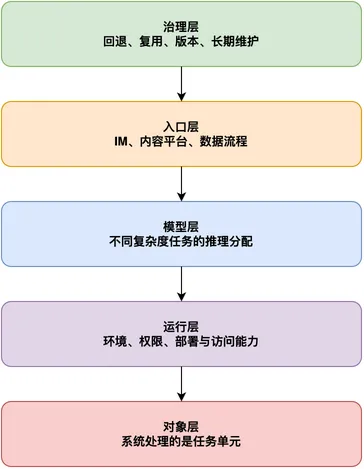
为了读懂这些能力,可以把 OpenClaw 拆成 5 个层面:对象、运行、模型、入口和治理。否则部署、模型切换、IM 接入、内容流水线、数据任务和 Skill 都只是散件。
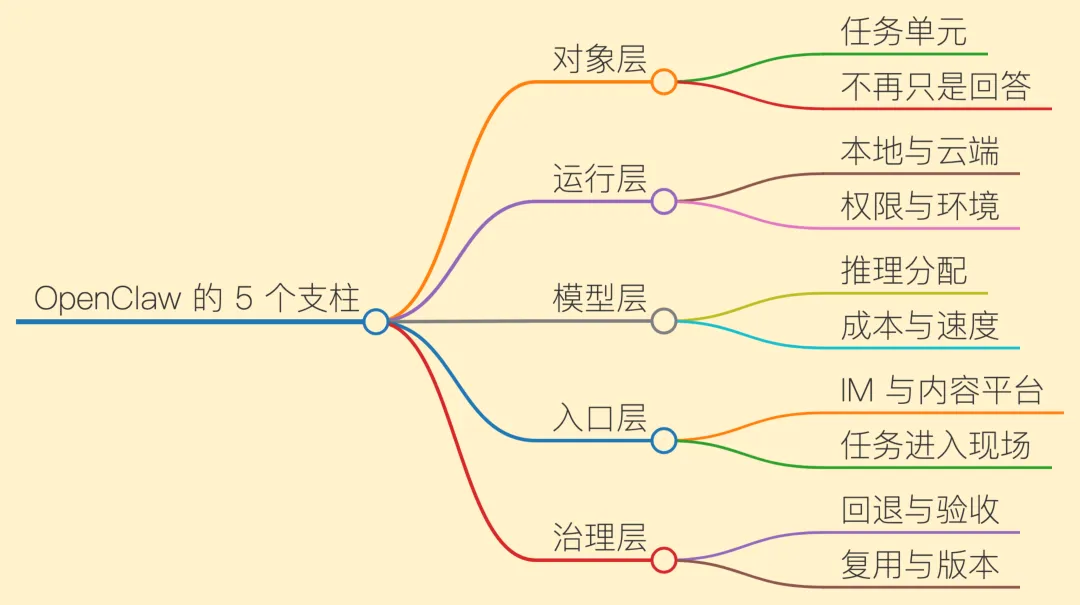
还是看周报例子。对象层定义“生成周报”这个任务;运行层决定能不能读文档、commit 和任务记录;模型层决定摘要、归因、风险提取用什么推理强度;入口层决定任务从飞书进入和确认;治理层决定缺项时回到哪一步、发送前是否必须人工确认。
这样拆,抽象词就落地了:对象处理什么,运行能碰到什么,模型怎么分配推理,入口从哪里进来,治理失败后怎么收回来。
运行和模型:决定任务能不能真实完成
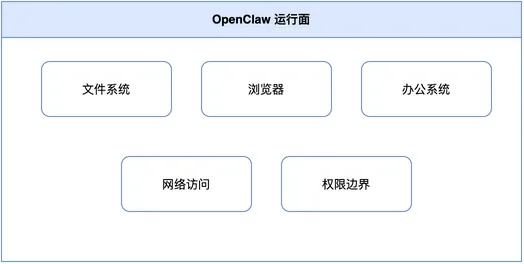
运行层不能含糊。周报链路要读文档、commit 和任务记录,就必须有文件访问、代码仓库访问、办公入口和权限边界;条件不具备,模型再强也只能凭空编。模型层也不是“选最强模型”:摘要可用快模型,风险归因用强推理,格式检查交给轻量模型。
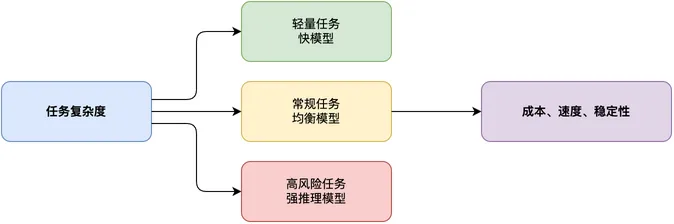
模型层按任务分配后,5 个支柱就不再是一张横向清单:对象定义任务,运行提供条件,模型负责推理,入口接进现场,治理兜住失败和复用。每一层都有自己的责任,不会混成“什么都能做”的宣传口号。
入口和治理:决定系统能不能长期跑
入口层很容易被低估。周报任务从飞书来,确认也要回到飞书;内容发布任务从公众号后台来,验收就要看草稿和封面。任务发生在哪里,OpenClaw 就得进到哪里。
最后是治理层。周报少了风险项,要回到材料读取;格式不合模板,要回到草稿生成;发送前没有确认,就不能自动发出。进入自动发布、定时任务、自定义 Skill 后,失败回退、能力沉淀、版本维护没人兜底,系统就只配做演示。
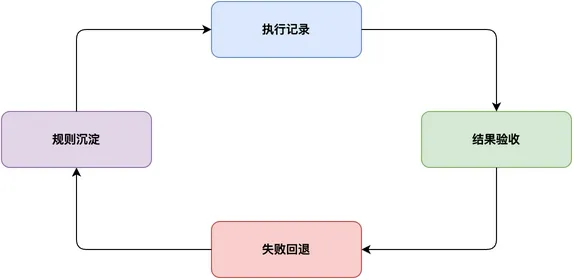
这 5 个支柱放在一起,OpenClaw 才不像一堆功能按钮,而像一套能跑任务的结构。
第三章:最后看边界:什么能交给它,什么不能
边界:有输入、有产物、有验收才适合
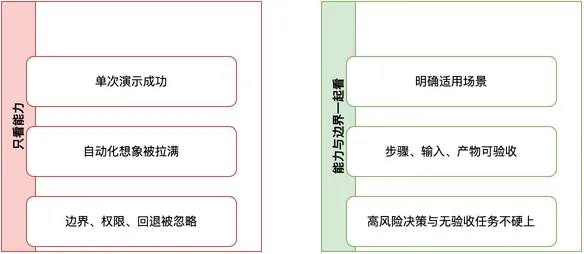
任务系统特别容易被高估。它跑通一次 demo,用户就会把“单次成功”外推成“长期稳定”。在问答系统里最多是答错一句话;进入内容发布、日报生成、办公入口和 Skill 运维后,错误代价会被放大。
所以 OpenClaw 的边界不能写成“补充说明”。它更像控制面:哪些任务可以交给它,哪些任务宁愿人工处理。没有明确输入、可验证产物、失败回退和权限约束的任务,交给 OpenClaw 往往不是自动化,而是在制造新风险。
适合交给 OpenClaw 的,是“整理本周项目风险,生成待确认草稿”这种有输入、有产物、有验收的任务。不适合直接交给它的,是“判断这个项目该不该砍掉”这种高风险决策。前者可以回读和修正,后者需要人承担责任。
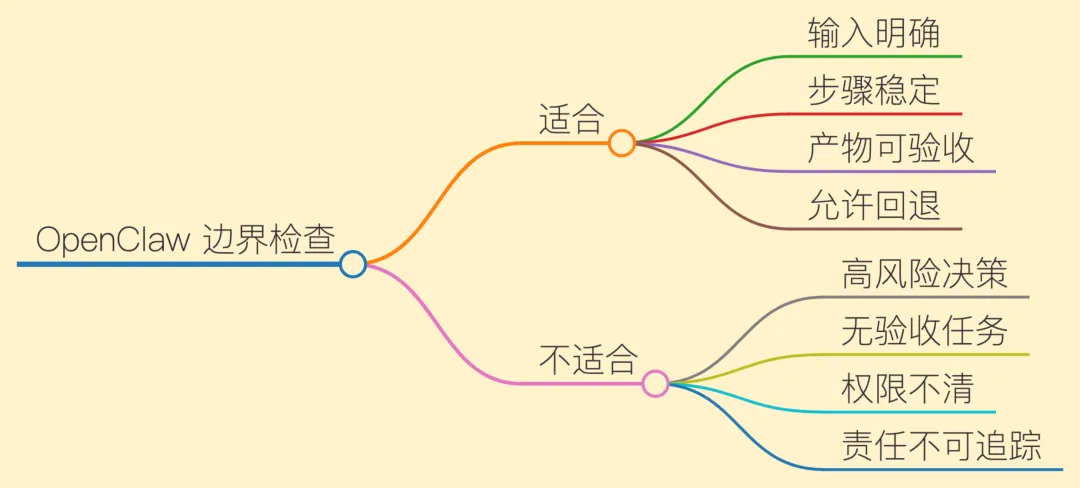
一个系统能不能进工作流,不能只看最亮眼的能力,还要看边界画得够不够清楚。
Skill:把重复做法写成执行契约
这也是 Skill 会出现的原因。只靠模型和工具调用,系统最多做到一次性执行;只有把步骤、约束、输入输出标准和失败处理沉淀下来,它才具备复用能力。Skill 不是高级玩法,只是把人反复做事的步骤写下来,让系统下次复用。
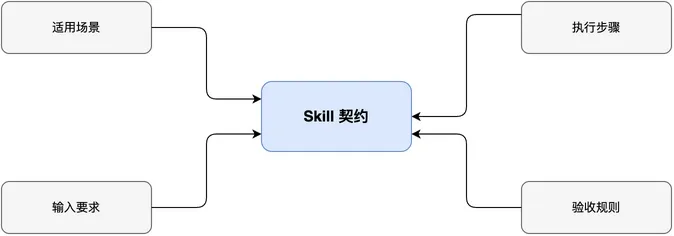
普通 prompt 通常只写一句临场要求,比如“帮我写一份周报,语气专业一点”。Skill 要写清适用场景、输入要求、材料读取顺序、输出模板、失败补救和验收规则。差别不在文字长短,而在它把一次性表达变成可复用的执行契约。
契约图解释 Skill 的静态结构:场景、输入、步骤、验收都要写清。下一张图看动态形成过程:任务系统跑久后,重复任务里的同一组约束会沉淀成 Skill。
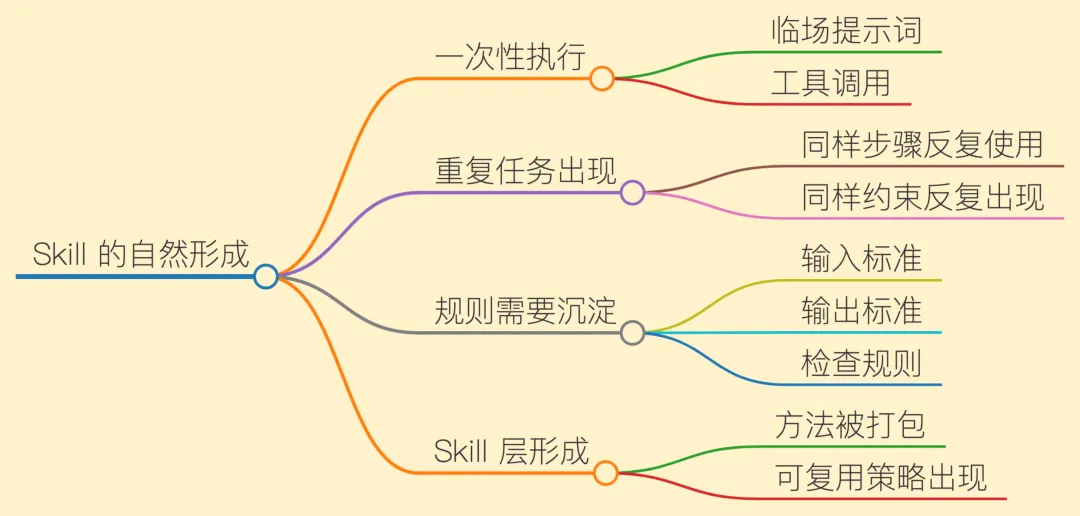
如果用“问答系统 + 工具调用”的眼光看 OpenClaw,就会觉得 Skill 像附加模块;但如果你接受它是任务系统,这一层就很合理。周报做一次,可以靠临场 prompt;每周都做,就要固定材料来源、字段顺序、缺项检查和发送确认。
这也是 OpenClaw 和很多短平快 Agent 产品的分界线。前者追求的不是“一次跑通”,而是“逐渐形成一套可维护的方法系统”。要接进工作流,几乎只能这么走。
结语
理解 OpenClaw,别先数它能接多少能力。只看一件事:它能不能把一句飞书消息变成可验收的周报草稿,并在失败时知道回到哪一步。做到这一点,它才不是问答系统。
把 OpenClaw 看成问答系统,会低估它;忽略边界和治理,又会高估它。更稳的读法,是把它看成一个围绕任务闭环组织动作、并且会逐步沉淀方法的执行层。
