 夜雨聆风
夜雨聆风





OpenClaw + Ollama:本地模型能做什么、怎么配才不崩
OpenClaw + Ollama:本地模型能做什么、怎么配才不崩
lean mode × 混合路由 × Ollama 提效指南
用 大模型 API 跑 OpenClaw,效果好是好,就是贵。
Ollama 本地跑模型,零 API 费用,听起来很美。装上之后发现:要么 context overflow(上下文溢出),要么 AI 说着说着突然失忆忘掉前半段对话,要么直接超时挂起。
问题不在 Ollama,在于 OpenClaw 默认的配置是给 GPT-4、通义千问这种大 context window 模型用的。本地模型参数小、context 短,直接跑就是拿着小水管接大水塔。解决方案不是换模型,是换模式。
一、为什么本地模型在 OpenClaw 里总出问题
OpenClaw 的核心机制是,把你的对话历史、系统 prompt、工具描述全部塞进模型 context 里。一个完整的 OpenClaw prompt,在标准模式下是 约 20K tokens 起步。
主流 Ollama 模型呢?
context window 8K
context window 32K,但 embedding 效率低
context window 8K
用小 context 硬撑大 prompt,结果就是溢出。
AI 吃到 context 上限,强行压缩历史对话,压缩算法又不完美,于是出现”失忆”——说到一半突然忘了之前说的什么。有些人以为是模型质量问题,其实是 context 超了之后 prompt 被截断。
二、lean mode:把 20K 压缩到 5K 的关键
OpenClaw 有一个专门为本地小模型设计的工作模式:localModelMode: "lean"。
agents:
defaults:
localModelMode: "lean"标准模式塞进了 browser(浏览器控制)、cron(定时任务)、message(消息收发)这些重型工具的完整描述。这些工具在云端大模型看来只是几行文字,但在本地小模型 context 里,占比相当可观。
lean 模式把这些工具从默认 prompt 里移除,只保留核心能力:文件操作、代码执行、网页获取。Prompt 体积从约 20K tokens 降到约 5K。
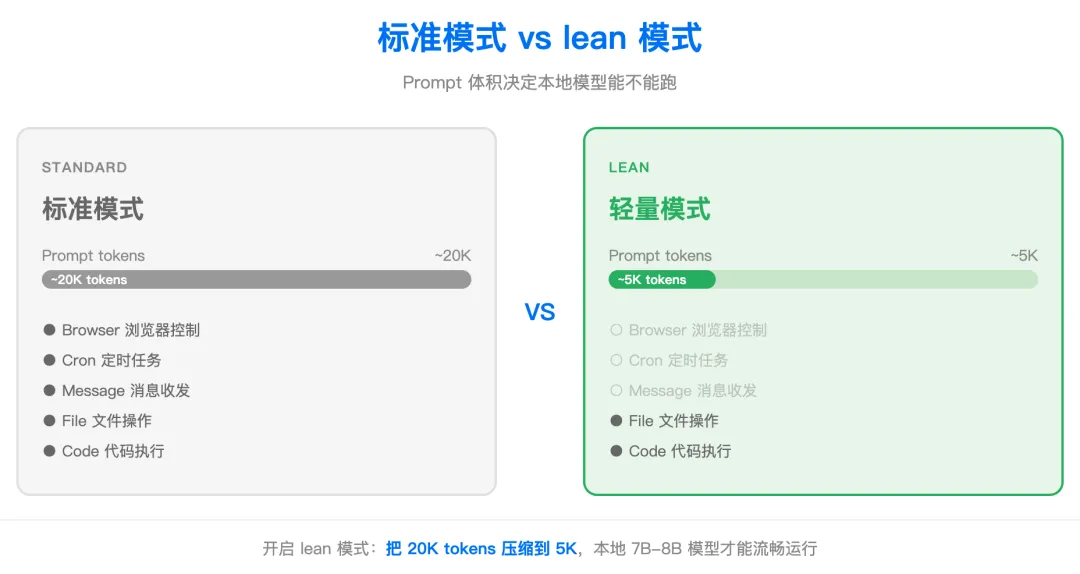
图:标准模式 vs lean 模式,prompt 体积从 20K 压缩到 5K
5K tokens,Ollama 7B-8B 的模型完全能 handle。
三、Ollama 配置三件套:跑得稳、测得准、不失忆
lean mode 是核心,但还有三个配置必须一起调。
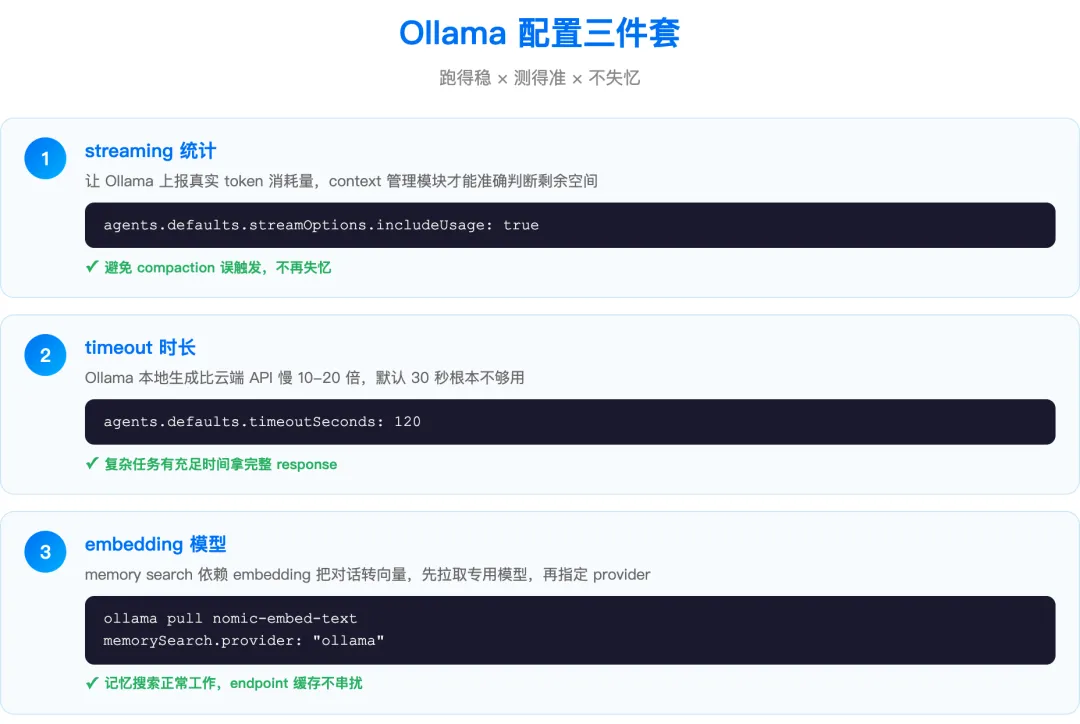
图:streaming 统计、timeout、embedding,缺一不可
第一,streaming 统计。
Ollama 默认不上报 token 使用量,OpenClaw 的 context 管理模块收不到 usage 数据,会误判 context 剩余空间,提前或延后触发 compaction(上下文压缩)。导致:要么压缩太早、AI 记忆断片;要么压缩太晚、直接 overflow 崩溃。
agents:
defaults:
localModelMode: "lean"
streamOptions:
includeUsage: true开启 includeUsage,让 Ollama 每次 response 都报告实际 token 消耗,OpenClaw 的 context 管理才能准确工作。
第二,timeout。
Ollama 生成速度比云端 API 慢得多——云端 100 tokens/秒,本地可能只有 5-10 tokens/秒。默认 timeout 是 30 秒,很多复杂任务 30 秒根本拿不到完整 response 就被强制中断。
agents:
defaults:
timeoutSeconds: 120第三,embedding 模型。
OpenClaw 的 memory search(记忆搜索)依赖 embedding 把你的对话片段转成向量,在本地 ollama 模式下跑,需要指定 embedding provider。
ollama pull nomic-embed-textmemorySearch:
provider: "ollama"
endpoint: "http://localhost:11434"Ollama v0.1.41+ 对 embedding 缓存做了 endpoint-aware 处理,不同的本地实例不会互相串扰。
四、本地模型能做什么、不能做什么
清楚边界比配置更重要。
频繁调用
隐私数据
开发调试
最新知识任务
高并发场景
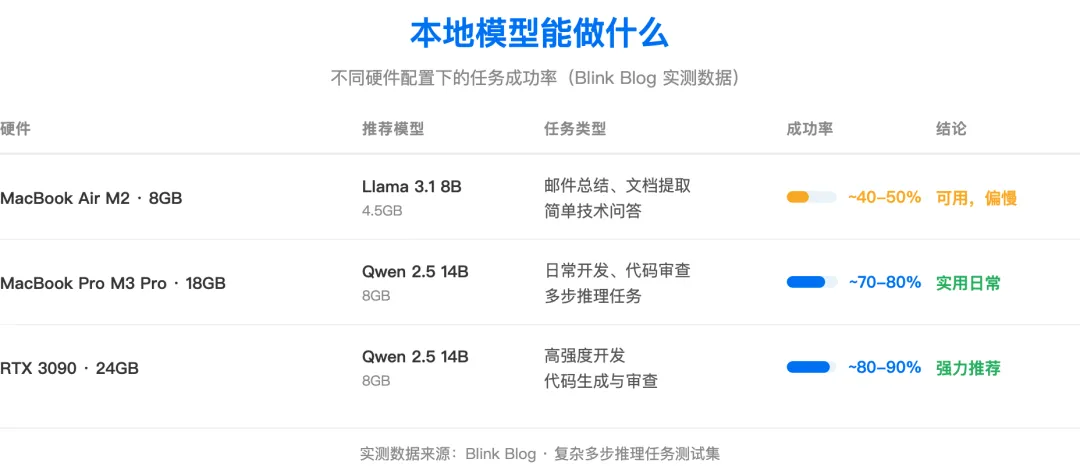
图:不同硬件配置下的任务成功率,数据来源 Blink Blog
Llama 3.1 8B 在复杂任务里成功率只有四成——邮件总结这种简单任务够用,代码审查多步推理就不行。
五、最优解:混合路由
大多数人的实际需求不是”全本地”或”全云端”,而是什么任务用什么模型。

图:混合路由策略,按任务复杂度自动分发
OpenClaw 支持在不同的 task 类型里指定不同的 provider。简单任务走 Ollama 省 API 费用,复杂任务切到通义千问——不需要手动切换,OpenClaw 的 routing 逻辑可以按任务复杂度自动分发。
agents:
defaults:
localModelMode: "lean"
routing:
simpleTasks:
provider: "ollama"
model: "qwen2.5:7b"
complexTasks:
provider: "qwen"
model: "qwen-max"隐私数据走本地,简单重复任务走本地,大模型推理走云端——这是目前最实用的架构。
Ollama 不是一个”更差的替代品”,它是一个”更合适的工具”。
用 Ollama 跑 OpenClaw,核心就三条:开 lean 模式、调 streaming 统计、按场景选模型。
不是所有任务都需要通义千问 Max,有些事本地模型干得又快又省钱,还不留痕迹。
GitHub:github.com/openclaw/openclaw