 夜雨聆风
夜雨聆风





RAG 检索设计:如何从海量文档中找到真正有用的那几段
在很多企业落地 RAG时,一个常见误区是:大家把注意力都放在“选哪个大模型”,却忽略了一个更关键的问题——你给模型喂的上下文,是否真的“对”。
本质上,RAG 检索系统要解决的不是“找更多信息”,而是找到最可能包含答案的证据片段(chunks)。
RAG知识库的流程可以阅读”从“胡说八道”到“有据可查”:一文讲透RAG知识库工程搭建“这篇文章。
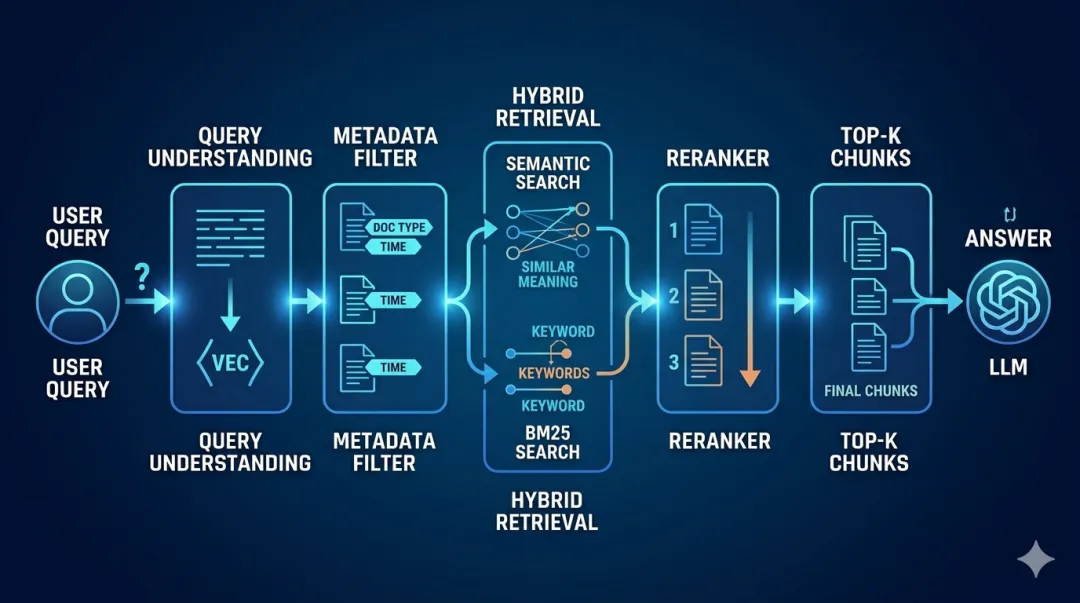
一、从“用户问题”到“候选证据”的路径
一个工程上相对成熟的检索流程,通常包括以下几个关键层:
1. Query 理解层用户问题先被 embedding 成向量,这是语义检索的基础。往往需要 Query Rewrite 或分类增强提升召回率。
2. Metadata 过滤通过 chunk 的metadata结构化信息(如文档类型、时间、业务线),可以先过滤掉明显不相关的数据。举个例子:用户问“理赔规则”,你完全没必要让“营销文档”参与检索。
3 & 4. 双路召回:语义 + 关键词
-
向量检索(Semantic Search):擅长理解“意思相近”
-
关键词检索(BM25):擅长匹配“字面命中”
两者本质是互补关系。只用向量,会漏掉精确术语;只用关键词,会听不懂“人话”。
通过这2种检索拿到top N chunks,比如top 50。
5. 多路融合(Fusion)把两路结果合并、去重。这一步的关键不是“拼起来”,而是如何平衡两种信号(比如加权、排序融合)。
6. Reranker 排序这是“从top 50条到top 5条”的关键一刀。Reranker 通常是一个更精细的模型(甚至是小型 cross-encoder),负责判断“这段内容和问题到底有多相关”。
7. LLM 生成最终只把 Top-K(比如5条)拼接进 Prompt,交给大模型生成答案。
二、工程实践中的几个关键点
-
Chunk 设计决定上限:切得太大,噪音多;太小,上下文断裂。很多系统效果不好,其实是 chunking 出了问题。
-
Metadata ≠ 可有可无:它本质是“低成本筛选器”,比你调 embedding 模型更划算。
-
Reranker 是性价比之王:相比一味扩大 Top-K,引入 Reranker 通常更有效。
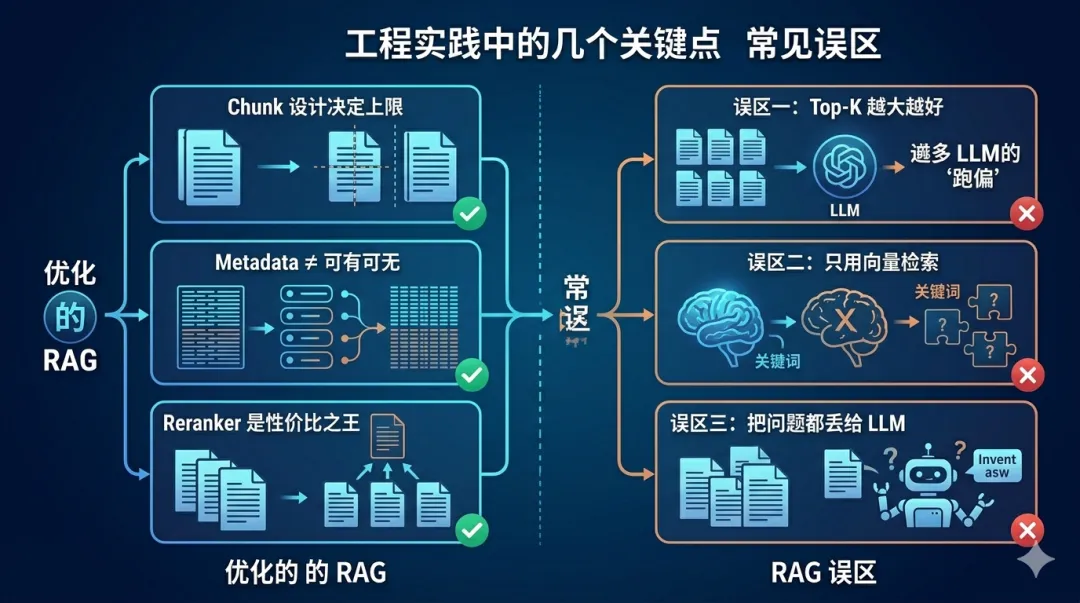
三、常见误区
-
误区一:Top-K 越大越好上下文越多,LLM 越容易“跑偏”,甚至增加 hallucination。
-
误区二:只用向量检索很多业务场景(如法务、医疗)对关键词极其敏感,不能丢。
-
误区三:把问题都丢给 LLM检索做不好,再强的模型也只能“胡编得更像真的”。
四、小结
RAG 的核心不是“接入大模型”,而是构建一套高质量的信息筛选机制。从 Query 到 Top-K,每一步都是在不断逼近“最有用的那几段内容”。
换句话说:LLM 决定你能说多好,检索系统决定你有没有东西可说。