Cursor 应用最佳实践:从 AI 编辑器到 Agent 开发操作系统
过去很多人用 Cursor,停留在一个很浅的层面:补全代码、写几个函数、顺手改个 bug。
于是他们很快得出一个结论:Cursor 很强,但也就那样,
今天的 Cursor,早已经不是一个“更聪明的代码补全器”了。
到 2026 年,Cursor 正在越来越明确地把自己定位成一个围绕 Agent 展开的软件开发工作空间:它能理解代码库、先做计划再编码、切换本地与云端 Agent、在隔离 worktree 中并行实验、控制浏览器做 UI 测试、通过 MCP 接外部系统、用 Bugbot 做 PR 审查,甚至把自动修复和持续自动化串进研发流程。
2026 年 4 月发布的 Cursor 3,更直接把这种方向写成了“统一的 agent 工作空间”。
所以,真正的问题不是“Cursor 好不好用”,而是你到底把 Cursor 当成了什么。
如果你把它当成“会写代码的助手”,它给你的价值,大概率只是提速 20%。
如果你把它当成“可被管理、可被约束、可被验证、可被接入工作流的编码 Agent”,它改变的就不是速度,而是你的整个开发方法。
这篇文章,想讲透的就是Cursor 的最佳实践,重建一套人机协作的软件开发流程。
一、先计划,再编码
很多人用 Cursor 最大的问题,不是模型不够强,而是输入过于模糊。
一句“帮我改一下登录模块”,对人类同事都不算清楚,对 Agent 更是灾难。
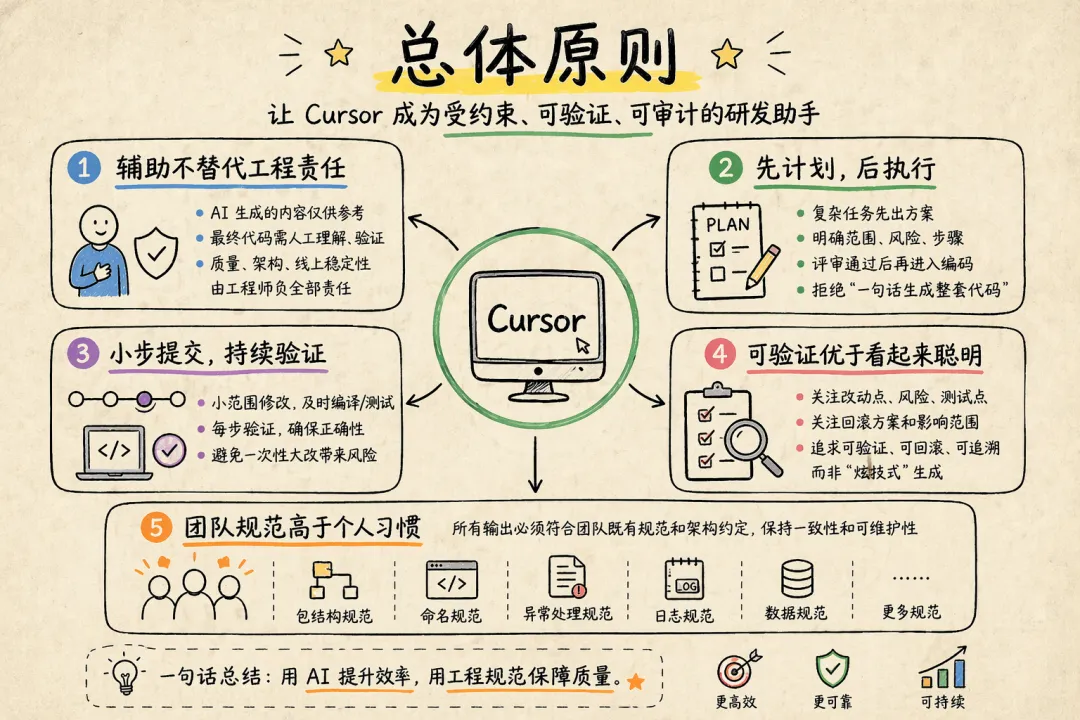
Cursor 官方在 2026 年 1 月发布的《Best practices for coding with agents》里,把最重要的一条经验放在最前面:先计划,再编码。
它明确建议优先使用Plan Mode,让 Agent 先研究代码库、提出澄清问题、生成可审阅的实现计划,再等你批准后动手。
官方甚至建议,把计划保存到.cursor/plans/,因为这样不仅方便中断后恢复,也能成为团队后续 Agent 的上下文。
这背后的本质非常重要:传统 IDE 时代,程序员的核心能力是“写代码”;
Agent 时代,程序员越来越重要的能力,变成了定义任务、约束边界、组织上下文、设计验证信号。
你不是在“指挥一个打字更快的自己”,你是在“管理一个执行速度极快、但理解仍然依赖上下文的代理人”。
二、最有效的起手式:Plan Mode 不是附加功能,而是主工作流入口
官方文档里,Plan Mode 的定义非常清楚:它会先研究代码库,询问需求中的不确定点,再输出带文件路径和代码引用的详细实现方案。
官方提供的快捷方式是Shift+Tab,CLI 里也有/plan命令。
但 Cursor 真正擅长的,不是你说一句、它吐一段,而是你先把任务分层,它再沿着结构化目标推进。
比如新增一个支付风控流程,可能会改 controller、service、repository、配置、测试、监控埋点。你直接让它写,容易漏边界;先出计划,才知道它是否真的理解系统。
比如包结构调整、接口收敛、DTO 统一、日志体系重写。这类任务最怕“改着改着失控”。
先让 Cursor 输出迁移路径、影响文件、回滚点,比直接开改稳得多。
Plan Mode 的价值,恰恰在于逼 Agent 先问问题。
一个会先问问题的 Agent,通常比一个急着给答案的 Agent 更可靠。
Plan Mode 不是为了显得更“专业”,而是为了把“含糊任务”变成“可执行任务”。
三、真正决定 Cursor 上限的,不是模型,而是上下文管理能力
Cursor 官方在同一篇最佳实践文章里说得很直接:
随着你越来越习惯 Agent 写代码,你的工作会越来越变成给 Agent 提供完成任务所需的上下文。
其实在真实项目里,模型差距当然存在,但更常见的瓶颈是:Agent 拿到的信息不完整、不稳定、不结构化。
于是,Cursor 的第二条最佳实践就出来了:把“临时口头说明”升级为“持久化上下文资产”。
Rules:持久化指令,可分为 Project、Team、User Rules,并支持AGENTS.md。
Skills:通过SKILL.md封装领域知识、脚本和命令,Agent 可按需动态发现和调用。
Subagents:创建面向特定任务的专用子代理,用于更好的任务分工与上下文管理。
MCP:把外部工具和数据源接进 Cursor,让 Agent 不只看代码,也能访问你真实的研发环境。
这里面最容易犯的错误,是把所有要求都塞进一个超长的全局规则里。
官方其实明确提醒:先从简单开始,只在发现 Agent 重复犯同样错误时,才逐步增加规则;只有当一个工作流已经稳定重复时,再把它做成 command。不要过早过度优化。
四、Rules、Skills、Subagents,到底该怎么分工
因为它本质上是在告诉 Agent:无论你做什么,都别越过这些边界。
官方对 Skills 的描述很明确:它们用SKILL.md定义,可以包含自定义命令、前后置 hooks、以及特定领域的知识和脚本。
-
“新增一个 Spring Boot API” 的标准脚手架流程
-
-
“给 React 页面做无障碍检查并修正” 的固定方法
-
“生成 Flink CEP 规则测试样例” 的内部套路
Rules 管“不要犯错”,Skills 管“遇到这类任务时该怎么做”。
Subagents 的定位是把复杂任务拆给更专门的代理去做。
官方文档把它定义为面向特定工作流与上下文管理的专用代理。
这样做的价值,不只是并行,而是避免一个 Agent 在一个超长会话里同时背着太多任务负担。
五、MCP 才是 Cursor 从“写代码”走向“做工程”的关键跳板
如果说 Rules 和 Skills 解决的是“Agent 怎么做”,那么 MCP 解决的是“Agent 能接触到什么”。
官方文档把 MCP 定义为:通过 Model Context Protocol,把外部工具和数据源接入 Cursor。Marketplace 里的很多插件,本质上也是 MCP、skills、commands 的组合。
你还要看接口文档、跑 Postman、查日志、看监控、读 Issue、翻 Slack、查 GitLab/GitHub PR、拉 Sentry 报错、调云资源。
这就是为什么 Cursor Marketplace 的真正价值,不在于多几个小插件,而在于把研发链路中的上下游系统纳入同一个 Agent 工作流。
后端工程师,优先接 API、日志、监控、代码托管系统;
前端工程师,优先接设计稿、浏览器测试、埋点、错误追踪;
AI Agent 开发者,优先接搜索、评测、追踪、向量库或模型平台。
六、本地 Agent 与 Cloud Agent,最好的关系不是二选一,而是分层协作
Cursor 官方明确支持本地与云端 Agent 切换。
Cloud Agents 可以从网页、编辑器或手机发起,在远程沙箱中运行,其标准工作流包括克隆仓库、创建分支、自主工作、完成后开 PR,并通过 Slack、邮件或 Web 通知你。
不要问“我该用本地还是云端”,而要问“这类任务应该在哪一层执行”。
本地 Agent 更像“坐在你旁边的搭子”,Cloud Agent 更像“领了任务去独立施工的外包队”。
真正成熟的工作流,不是所有活都自己盯着,而是:小任务在本地高频交互,大任务扔给云端异步推进。
而且,2026 年 3 月 Cursor 还推出了 self-hosted cloud agents,支持把代码和工具执行保留在你自己的网络里。
七、最容易被低估的能力:隔离实验,而不是直接污染主工作树
很多人让 Agent 直接在当前分支上大改,改坏了再回滚。
Cursor 的 Worktrees 文档明确支持通过/worktree和/best-of-n,在隔离的 Git worktree 中运行本地 Agent 工作。
让 Agent 在隔离空间试错,而不是在你的主工作区里试错。
/best-of-n这种思路,本质上是在多个方案里选最优,不再把单次生成当成唯一答案。
比如“重构这个模块,给我两个实现路线”,这种任务如果都在主分支上做,成本会迅速上升。
八、浏览器工具不是锦上添花,它决定 Cursor 能不能真正碰前端和端到端验证
Cursor 的 Browser 工具文档写得很直接:Agent 可以控制浏览器去测试应用、可视化编辑布局和样式、做无障碍审计、把设计转换成代码。
因为软件开发里最贵的错误,往往不是代码语法错,而是:
如果 Agent 只能写,不能看,它就只能停在“猜”,一旦它能控制浏览器,它就开始具备“验证”。
所以,对前端、全栈、测试甚至增长产品团队来说,最佳实践不是只让 Cursor 产代码,而是让它参与端到端验证。
九、验证信号越强,Cursor 的表现越稳定
它建议使用类型系统、配置 linters、编写测试,因为 Agent 无法修复它自己不知道的问题。
这句话几乎可以当成 Cursor 最重要的工程原则。
很多人抱怨 AI 编码不靠谱,本质上是因为他们把一个“需要闭环信号的执行体”,丢进了一个“几乎没有反馈机制的环境”。
所以,Cursor 的最佳实践,并不只发生在 Cursor 里。
某种意义上,Cursor 用得越深,越会把团队推向“可验证的软件工程”。
十、Hooks 的价值,不在自动化,而在“把团队纪律嵌入执行流”
Cursor Docs 把 Hooks 描述为内置钩子机制,用来在 Agent 动作前后执行脚本;
而官方关于 Skills 的介绍,也明确提到 hooks 可以作为 skills 的一部分。
因为它让“我们团队通常会这样做”不再停留在口头习惯,而是变成真正会被执行的流程节点。
-
-
改 SQL 后自动跑 explain 或风格检查;
-
-
最佳实践不是把所有事都交给模型记住,而是让模型负责创造性工作,让 Hooks 守住机械性纪律。
十一、Bugbot 不是“自动挑刺”,而是把 code review 从人工经验变成系统闭环
Cursor 的 Bugbot 文档说明,它可以审查 PR,识别 bug、安全问题和代码质量问题;
其 Autofix 还能在发现问题后自动拉起 Cloud Agent 进行修复,并把结果回写到原 PR。
Autofix 支持新建分支或直接提交到现有分支,且官方推荐新建分支模式。
更重要的是,2026 年 4 月,Cursor 让 Bugbot 支持从实时代码审查反馈中学习,形成 learned rules;
官方披露,自 beta 推出以来,已有超过 11 万个仓库启用 learning,生成超过 4.4 万条 learned rules。
意味着 review 开始从“每次重新看一遍”转向“把过去踩过的坑沉淀成机器可复用的规则”。
所以,对团队来说,最佳实践不是把 Bugbot 当成一个自动 reviewer,而是把它放进整个研发闭环里:
Agent 可以提速,但真正放大组织效率的,是规则化的复利。
十二、自动化不是让 Cursor 替你上班,而是让它接管“适合持续执行的重复工作”
2026 年 3 月,Cursor 推出了 Automations,用云端 Agent 在定时或事件触发下自动运行任务。
官方给出的愿景非常明确:构建一个持续监控并改进代码库的“软件工厂”。
先把那些规则清楚、验证明确、重复发生的工作交给它。
也就是说,自动化的正确打开方式不是“完全无人值守”,而是:
成熟团队和不成熟团队的区别,不是有没有用 Agent,
而是有没有把 Agent 放进一个可审计、可回滚、可复盘的自动化框架里。
十三、CLI 的真正价值:让 Cursor 进入你的终端工作流,而不是只存在于 GUI
Cursor 官方 CLI 文档写明,CLI 支持在终端中使用 Agent,并且集成 MCP、rules、commands;slash commands 里也包括/plan、/sandbox、/mcp list、/rules、/commands、/compress等能力。
如果 Cursor 只在编辑器里强,它的上限仍然有限。
一旦它进入 CLI,它就更像一个真正的开发代理,而不是一个 UI 里的聊天框。
把那些本来就在终端里做的高频动作,逐步迁到可被 Agent 协助的模式里。
这样你不是在“多一个工具”,而是在“统一开发界面”。
十四、软件开发的“Agent 化重构”
它不是“哪句 prompt 更好”,也不是“哪个模型更强”。
-
-
-
-
-
这些东西叠起来,才构成了真正的 Cursor 方法论。
所以,Cursor 为什么让很多人觉得“忽然变强了”?
而是因为它正从一个 AI IDE,演进成一个软件开发的 Agent 操作系统。
2026 年 4 月的 Cursor 3,把这种方向进一步明确为“统一工作空间”,并强调多仓库布局、本地与云端 Agent 的无缝切换。
现在,越来越变成“人定义目标、约束和验收,Agent 负责推进执行”。
未来更有竞争力的开发者,不一定是敲代码最快的人,而更可能是:
这才是 Cursor 应用最佳实践真正值得深度理解的地方。
它不是教你如何“更快写代码”,它是在逼你回答一个更大的问题:
 夜雨聆风
夜雨聆风