 夜雨聆风
夜雨聆风





OpenAI Image2 核心团队成员爆料:历时4个月,断崖反超谷歌 Nano Banana!几乎所有图像生成团队都上了!业内都在深扒Image2技术路径!
您想知道的人工智能干货,第一时间送达






下面这个例子,很好的体现了这一过程,在不同画面中保持人物、物体和风格的一致性。
OpenAI 表示,这将使生成漫画页面、社交媒体视觉内容系列,或整套家居设计方案变得更加容易。
以前,如果你让图像模型去研究一个主题,它其实并不具备足够的世界知识,也缺乏各个领域的专业能力。
现在,它已经可以执行完整任务:先做研究,查看图片,找出它们之间的共性,还能生成多个相互一致的输出,把它们组织成一个完整的故事。

生成前进行推理、结构规划,并结合网络信息完成复杂图像任务
它会主动思考这些内容:哪些信息需要放进去、以什么顺序呈现、最终输出什么结构图片。

在团队成员演示过程中,曾提到了两处模型的自主思考点:
第一处,模型会自主决定文字的位置,保证整个图片设计布局的高完成度;
第二处,则是模型会在最终输出前检查自身生成的结果,以确保多张图片之间的一致性。
小编认为,虽然 OpenAI 短期不会公开背后的技术细节,但对于人才辈出的今天,很快就会有人“逆向”出来。
另一个值得关注的点是,Image 2 成功攻克了“多语言”文字显示的问题。
这可以说是无数创作者以前“心中最大的伤疤”之一了。
过去的图像模型常将文字视为“贴入画面的元素”,导致中文、日语等语言笔画变形或乱码,而新模型实现了“语言融入设计”——不仅保证字形准确,还能匹配字体选择、排版节奏与书写习惯,例如中文海报的留白和日文漫画的分镜逻辑。
官方测试案例显示,该模型能稳定处理密集文本场景:
在中文连环漫画中,连底部超小字号的注释“(此处为极小字号测试)无锡是作者的故乡”都清晰可辨;
在印度书店场景中,同时渲染印地语、孟加拉语等九种印度语言的书封文字,且语句通顺连贯。
Boyuan 还演示了自己让 Image 2 渲染成一篇论文的过程,这种高度密集的中英文混合小字排版,也被 OpenAI 成功接住了!
据悉,Image 2 之所以能够突破这个痛点,是源于模型对非拉丁语系语言的底层训练优化,而非简单的字符映射——它能理解文字的语义和排版规则,例如中文从左到右的阅读顺序、日语竖排文字的行距要求。


目前公开的信息里,Image 2 支持非常灵活的输出尺寸调整,几乎覆盖了所有主流平台的图片尺寸。此外 API 端甚至支持高达 2K 分辨率输出,最大边长像素为 3840 px,总像素达 829 万。
要知道过去版本的模型,也只够支持固定的竖版、横版或者正方形。API 端最高仅支持 1K 分辨率。
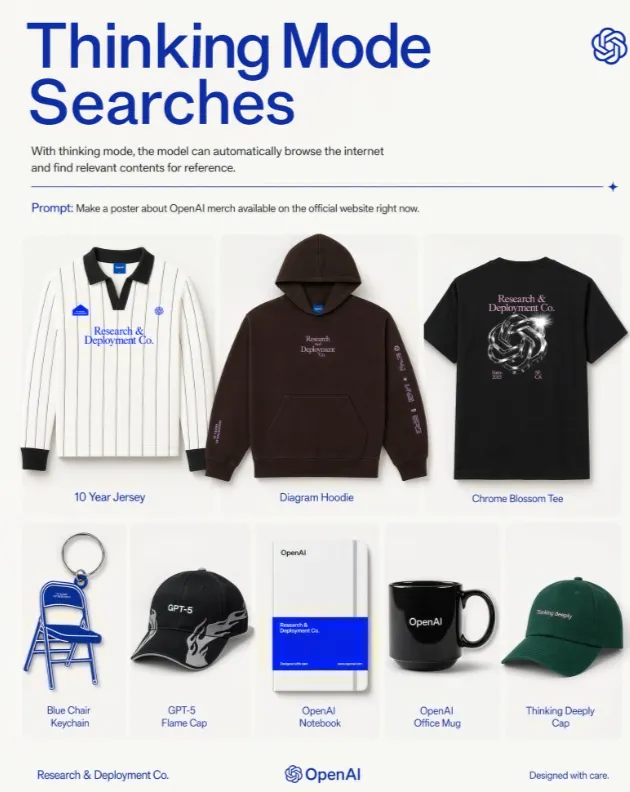
小编整理了一张核心能力特点,如下:


prompt:用超广角手法拍摄春天里的上海外滩

稻米上的小黑字清晰可见
不过,根据官方披露的信息,当前 Images 2.0 的高分辨率输出仍处于beta阶段,2K以上分辨率结果可能不稳定;同时对于折纸步骤图、倾斜面细节等需要完整物理世界模型的复杂场景,细节处理仍存在局限。
那么,如此灵活多变的尺寸,技术上如何实现的呢?
很明显,OpenAI 不会这么快就公开出来。 不过,结合当前图像生成领域的通用技术路径,Images 2.0 的可变像素输出大概率通过以下三种方式实现:
- 基于扩散模型的弹性输入输出架构
采用可变尺寸的latent扩散架构,支持不同长宽比的 latent 张量输入,无需固定尺寸输入即可生成对应尺寸图像,这是当前主流文生图模型实现可变尺寸的通用方案。 - 位置编码适配
通过可学习的旋转位置编码或正弦位置编码,适配不同尺寸的空间位置信息,保证不同比例下生成内容的结构合理性,这也解释了为什么它能重新组织构图而不是简单裁切。 - 训练数据覆盖多尺寸场景
训练阶段引入不同比例、不同分辨率的训练数据,让模型学习到不同尺寸下的合理构图逻辑,所以针对不同平台尺寸都能输出适配结果。
如果OpenAI后续公布更多技术细节,小编也会及时为大家跟踪解读。

Boyuan Chen 可以说,属于新一代“多模态基础研究者”的典型代表。他现任 OpenAI 研究科学家,参与了 GPT 图像生成等核心项目。

Boyuan Chen 博士毕业于 MIT(EECS,辅修哲学),本科就读于 UC Berkeley。
他的研究聚焦于“世界模型”、具身智能与强化学习,核心目标是让 AI 不只生成内容,而是理解环境、预测变化并与现实世界交互。
而另一位演示的东方面孔:Yuguang Yang。 同样也是 OpenAI 图像生成团队的研究员,参与了 ChatGPT Images 2.0 等核心项目的研发。

他这次的工作和演示重点集中在将复杂信息转化为高质量视觉内容,例如生成信息图、将 PDF 转换为幻灯片或海报等,推动图像模型从“生成图片”向“表达结构化信息”演进。

可以看出,Yuguang 更接近“应用与研究的交叉层”,既理解模型能力边界,又负责将其转化为可用工具。这个方向正成为 AI 产品化落地的重要推动力量。
用笑声链接时代,用作品温暖人心
The Power of Joy:沈腾如何重新定义喜剧,并成为文化符号

大家看下,这种地步的封面设计,你会打几分呢?
有了它,谁还会再去找图片模版去一点点复制粘贴素材呢?
https://www.youtube.com/watch?v=B4r4t9eIwNI
https://x.com/OpenAI/status/2046670977145372771
https://x.com/BoyuanChen0/status/2046678444042596581


文章精选:
1.强化学习之父、图灵奖得主 Sutton 隔空回应 图灵奖得主Hinton:目前的 AI “理解不足,调参有余”