 夜雨聆风
夜雨聆风





全网都在担心AI骗人时代到了,我觉得有点杞人忧天

微信的推送机制改版了,不再是发送时间而是按照阅读情况来推送,这意味着你们有时候会看不到我们的推文。为了不走丢,大家可以给公众号加“星标”,每次看完文章后“在看”,谢谢大家。

今天,一个老同学发了张图在群里:
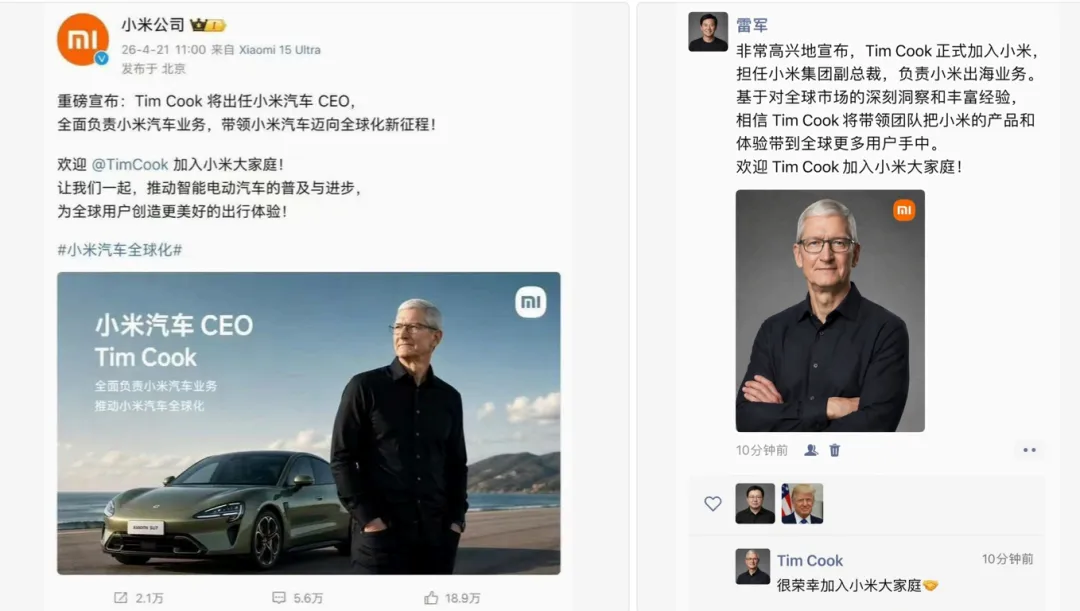
刚好库克刚刚卸任苹果,大家都以为是真的。。。
过了一会儿,我发了张这个图进去,大家才知道被骗了:

大家可能也听说了,昨天Chatgpt最新的生图AI Image 2上线,大家都玩疯了。

这代AI生成的图,已经很难靠肉眼判断了。
这两天各大平台的头部大V,集体进入了”末日预警”模式。
有人说这是AI黑暗森林时代的开端,以后真假将彻底无法区分,骗子要无敌了,AI一定要降智:
不少家长都来问我,要不要赶紧教孩子识别AI假图,否则他们会在充满AI假图的世界里无所适从。
我觉得,大家的焦虑方向,搞错了。

先正视它的实力,再谈别的
咱不妨先冷静看一看,GPT Image 2到底做到了什么程度。
这代模型在图像生成上,有几个关键突破:
第一,文字渲染能力质变。
以前AI生图最大的硬伤之一,就是图里的文字——要么拼写错误,要么字形扭曲,一眼就能看出AI味。
GPT Image 2在这点上完成了跨越,能准确生成清晰可读的文字内容,包括复杂的中文字符。这意味着一张包含说明文字的截图、一份官方通知、一张成绩单,都可以被几乎无痕地生成。

第二,物理逻辑的真实感大幅提升。
光影关系、材质质感、空间透视,这代模型处理得更自然,以往那种塑料感或光线方向不对的破绽,正在快速消失。


第三,细节指令响应能力增强。
你可以在prompt里精确描述细节——某个具体场景、特定的情绪氛围、甚至手机随手拍的粗粝质感——模型都能准确还原。那种看上去像真实抓拍的照片,现在可以被刻意制造出来。
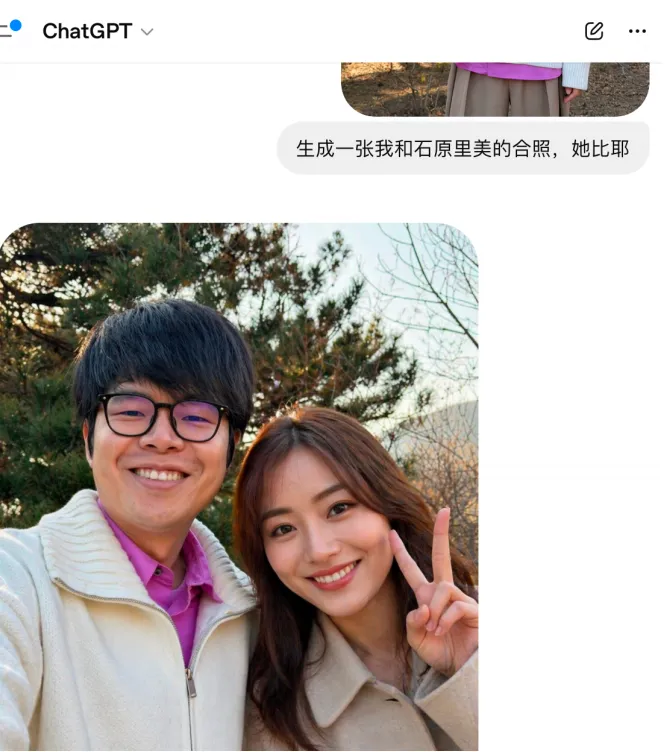
第四,一致性角色维持。
同一对话内,模型能保持人物外貌、场景风格的高度一致,系列假图的制作成本大幅降低。

综合起来,这代模型的核心突破是:它消灭了绝大多数可以被肉眼捕捉的AI破绽。
过去,我们可以通过手指数量不对、阴影方向奇怪、背景有模糊感这些视觉线索来识别AI图。这些判断方法,对GPT Image Two的输出,已经越来越失效了。
那些焦虑的大V有一点说得没错——这代AI的视觉生成能力,确实是一次显著的跃升。
但问题是,承认它强,和世界要完了,是两件完全不同的事。

大惊小怪什么?这件事没那么新鲜
假照片这件事,从来不是AI发明的。
我给学生上的RE4的教材里,有一篇叫 The Visual Village——视觉村庄。
里面有一句话我一直记着:
智能手机 + 美颜滤镜时代,美图秀秀、Snapseed、Instagram滤镜……一键磨皮、一键换天、一键瘦脸,普通人不需要学PS,打开App三秒钟就能让照片变个样。

那时候也有人担心网图不可信、以貌取人更危险了。担心了一阵,世界继续转。
再往前翻:Photoshop时代,掌握PS技术的人早就能把假图做得以假乱真——合成照片、无中生有、换天换脸,技术上都不是问题。
那时候也有人说眼见不为实,也有人预言社会信任要崩塌。同样,担心了一阵,世界继续转。

假照片这件事的本质没有变,变的只是门槛。
过去,能做高质量假图的是少数掌握专业技能的人;现在,随便谁打几行字就能实现同样的效果。
但请注意:量变不等于质变。造假变容易和真相消失,是两件完全不同的事。
那些说世界要乱了的声音,混淆了这两件事。
更重要的是——他们忽视了一个关键事实:技术和法律,早就出发了。
就在去年,2025年9月,中国正式实施了《人工智能生成合成内容标识办法》。

用大白话说:所有合规的AI平台,几是生成的图片、视频、音频,必须打上数字身份证。
这个身份证有两层:
-
你肉眼能看到的,比如AI生成的水印
-
嵌在文件元数据里的数字信息,肉眼看不见,但机器能读、能追踪、能溯源
这张身份证记录了:这张图是谁生成的、什么时候生成的、经过了哪些修改。 伪造或恶意删除,是违法行为,可追责。
与此同时,在全球范围内,OpenAI、Adobe、Google、索尼、尼康等科技与影像行业巨头,正在联合推动一个叫C2PA的技术标准。
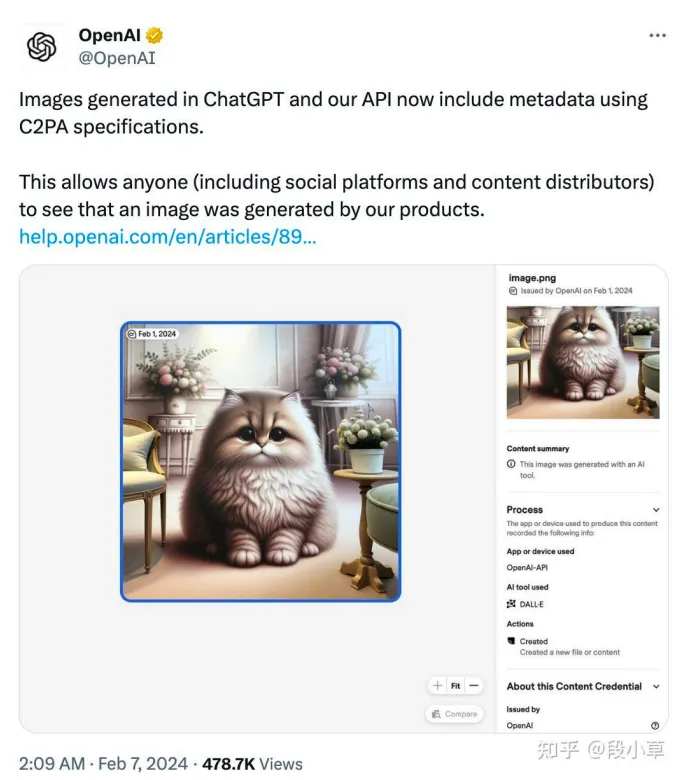
这套标准走的是数字签名路线:
每张图从被拍摄或生成的那一刻,就嵌入不可篡改的数字签名,完整记录这张图的来历——谁做的、什么工具生成的、中间经过了哪些平台和修改。
有人问,各类检测工具能不能跑过AI的迭代速度?
这确实是道高一尺魔高一丈的问题,不过关键不在于检测速度——在于标识是强制留痕的。
只要这个制度在,恶意造假就必然留下可追溯的源头。
就像交通管理,测酒仪、摄像头和法律体系才是关键,指望每个人练就一眼辨别酒驾的超能力,从来不是解法。

那到底,该教孩子什么?
眼下,我看到两种主流的家长反应,都走偏了。
第一种:拼命教孩子识别AI假图。
什么阴影不自然、手指数量不对、背景有虚化感……恨不得把孩子训练成行走的AI检测仪。
但前面已经说了:
GPT Image 2已经消灭了大部分肉眼可见的破绽,你把孩子训练好识别这代AI的弱点,下一代早就没有这些弱点了。
用肉眼对抗AI迭代,这个方向本身就错了。
第二种:什么都不信,陷入全面怀疑。
反正图都是假的,我什么都不信。
这同样是个陷阱,信息全面怀疑,等于放弃了判断力本身。
如果孩子养成了什么都不信的认知习惯,他在信息世界里等于闭上了眼睛。
那正确的方向是什么?
第一,养成追问来源的习惯
以前我们教孩子眼见为实,现在要教他们的是:眼见不一定为实,但来源可以核实。
每次Emma拿着一张图来问我真假,我不直接告诉她答案,我先问她:
这张图你从哪儿看到的?谁发的?她想了一会儿,说不知道。我说,那我们去找找看。
这背后是批判性思维——有根据地判断哪些来源值得信任、哪些需要存疑,而不是把一切一刀推翻。这种能力古已有之,只是被时代推到了更紧迫的位置。
第二,学会查图片的户口
现在买一些电器、光学器材(眼镜、相机)什么的,你会顺手扫一下防伪码吗?大多数人会,知道这东西有来历可查,扫一下心里踏实。
图片也在走这条路。
中国的《人工智能生成合成内容标识办法》已经落地,C2PA标准全球推进——所有合规平台生成的图,都要强制嵌入数字凭证,记录它是谁生成的、什么时候、经过了什么修改。
这套体系还没完全普及,但方向不会变。
等它成熟,孩子面对一张关键的图,要做的动作不是盯着阴影找破绽,而是:这张图有没有数字身份证?去查一下。
跟扫防伪码一样自然,一样的逻辑。
信息的权威,从来在于它从哪里来、谁为它背书,跟它看起来多真实没有关系。
PS和手机App时代是这样,AI时代依然是。

写在最后
GPT Image Two的发布,让视觉创作的门槛归零。
每个孩子现在都拥有了前所未有的表达能力——他们脑子里的画面,可以被几句话变成现实。
这放在十年前是不敢想的事情,是真实的、巨大的创造力解放。
同时,这也在提出一个更高的要求:当所有人都能创造视觉,谁来辨别视觉背后的真相?
答案,最终还是在机制和思维上。
这个世界没有变得更黑暗,它只是变得更复杂了——而复杂,从来都是留给有准备的人的机会。
END
点⬇️关注这个宝藏号

觉得有用,你就点“在看”
