 夜雨聆风
夜雨聆风





AI 代码总是偏题返工?这个热门 GitHub 项目给了一套可落地解法

点击蓝字 关注我们

本文介绍一个最近比较火的 GitHub 项目:andrej-karpathy-skills。
项目链接: 🔗 https://github.com/forrestchang/andrej-karpathy-skills
目前项目已获得超过 7.9 万 Star,在 AI 编码协作规范类仓库里热度很高。
andrej-karpathy-skills 是一个围绕 AI 编码协作的开源规范项目。它不提供新模型,也不提供复杂框架,核心是用一份可读、可改、可版本化的规则文件,约束 AI 智能体在真实工程中的行为。
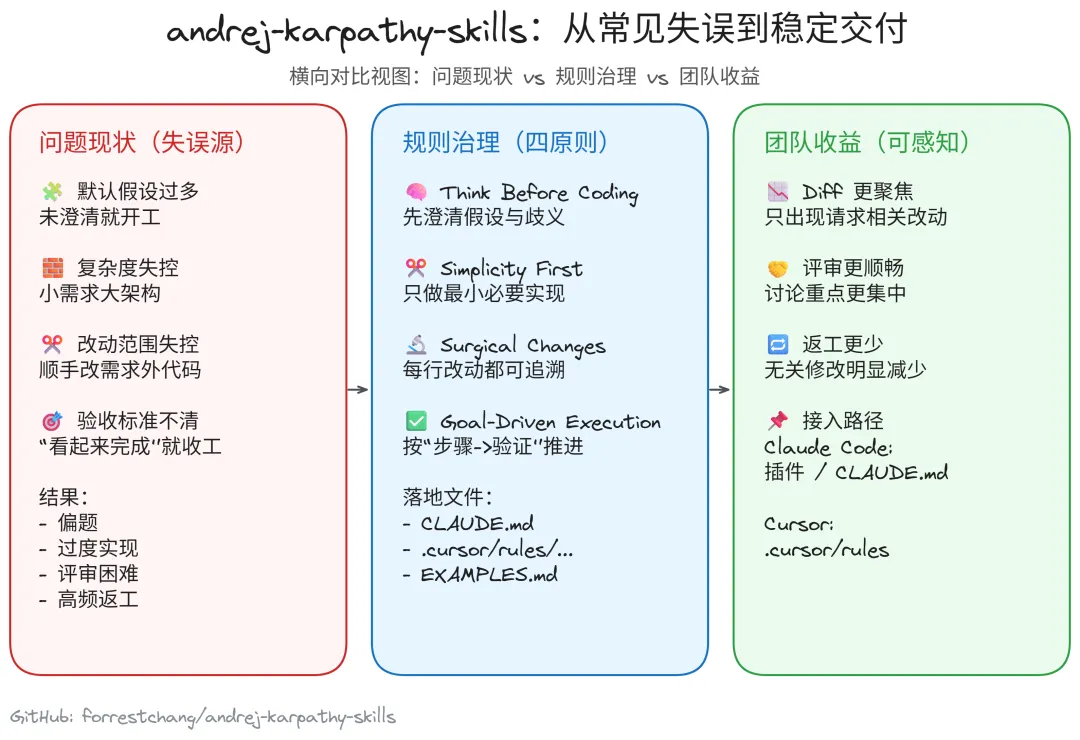
AI 编码能力快速增强后,团队普遍遇到同一类问题,任务能跑通,但实现常常偏题、过度、难评审。这个仓库的目标是把这些失误前置治理,而不是在 PR 阶段被动返工。
对从事 AI 编码的读者来说,这个仓库有很直接的实操价值:把规则文件导入自己的项目后,可以先建立统一的执行边界,让 AI 智能体在“先澄清再实现、减少无关改动、按可验证目标收口”这三件事上更稳定。通常会看到 diff 更聚焦、评审更顺畅、返工次数更少。
仓库里都有什么:不仅是 CLAUDE.md
很多人只看到这个项目有一个 CLAUDE.md,但仓库实际是“同一套原则,多入口复用”:
-
🧱 CLAUDE.md:核心行为规范正文,强调四条规则和谨慎优先的取舍。 -
🧭 .cursor/rules/karpathy-guidelines.mdc:Cursor 的项目规则版本,用于在 Cursor 内自动生效。 -
🧩 CURSOR.md:解释在 Cursor 中如何启用、迁移到其他仓库、与 Claude Code 的关系。 -
🧪 EXAMPLES.md:给出反例与正例对照,展示“常见错法”和“更稳妥改法”。 -
📘 README.md / README.zh.md:问题背景、安装方式、验收指标、可定制方式。
这个结构本身就很有学习价值:不是把经验写成一篇文章就结束,而是做成可被工具读取、可被团队继承的工程资产。
这个项目在解决什么问题
仓库把高频问题归纳得很清楚,核心是四类行为失控:
-
🧩 默认假设过多:不澄清就直接实现。 -
🧱 复杂度失控:小需求做成大架构。 -
✂️ 改动范围失控:顺手改了需求外代码。 -
🎯 验收标准失控:没有明确“做到什么算完成”。
很多团队把问题归因为“模型不够强”,但仓库强调,返工往往来自执行行为而不是能力上限。先把行为约束做好,通常比盲目换模型更稳定。
四条规则在工程里怎么用
-
🧠 Think Before Coding:要求显式说明假设、暴露歧义、必要时提出更简单方案。 -
✂️ Simplicity First:要求只写当前需求需要的最小代码,不提前设计未来复杂性。 -
🔬 Surgical Changes:要求每一行改动都能追溯到用户请求,避免“路过式重构”。 -
✅ Goal-Driven Execution:要求把任务改写为可验证目标,按“步骤 -> 检查”推进。
这四条不是抽象理念,而是可直接转成评审语句。例如“这次改动里哪些行不对应需求”“这次任务的验证条件是什么”,都能落到具体检查动作。
EXAMPLES 给出的实战信号
EXAMPLES.md 的价值在于“反例-正例”对照,读完能立刻发现 AI 智能体常犯的三类错误:
-
🧪 遇到模糊需求时直接假设:比如“导出用户数据”就默认导出全部字段和文件格式。 -
🧱 为简单需求套复杂模式:比如一个简单计算函数先上策略模式、配置对象、扩展接口。 -
✂️ 修 bug 时顺便重写风格:比如加日志时同时改注释、改格式、改类型声明。
先问清范围,再做最小实现;先修核心问题,再谈结构升级;先保留原风格,再做必要改动。这些方法在任何技术栈都通用。
经验可以沉淀进版本库
很多团队已经有提示词经验,但效果不稳定,主要问题是经验只留在个人脑中。这个仓库的做法是把经验写进版本库,形成三层收益:
-
🧭 协作一致性更高:同一仓库里的 AI 智能体行为更可预测。 -
🔍 评审成本更低:diff 更聚焦,评审更容易判断是否偏题。 -
🔁 复用效率更好:新成员可直接继承规则,不需要从零摸索。
这也是它最值得学习的地方:把“上下文工程”从个人技巧提升为团队基础设施。
Claude Code 和 Cursor 的接入差异
仓库明确给了两条接入方式:
-
🚀 Claude Code 路径:可以通过插件市场安装,也可以按项目引入 CLAUDE.md。 -
🧩 Cursor 路径:优先使用 .cursor/rules 下的规则文件,Cursor 默认不读取 .claude-plugin 或 CLAUDE.md。
这里的差异很实用。很多人把 CLAUDE.md 放进仓库后以为 Cursor 会自动生效,实际上要走 Cursor 规则入口。
使用时最容易忽略的边界
仓库本身也强调了取舍:这套规则偏“谨慎优先”,不是“速度优先”。落地时建议注意三点:
-
⚖️ 简单任务不必过度流程化:一行修复不需要完整重流程。 -
🧩 规则要和项目约束合并:例如测试规范、错误处理规范、语言规范。 -
📏 验收要定量:观察无关改动比例、返工次数、澄清提问时机等指标。
这样可以避免“规则写了很多,但团队体感没变化”。
建议的上手顺序
-
📖 第一步,先读 README 和 CLAUDE.md,理解四条规则各自约束什么问题。 -
🧪 第二步,通读 EXAMPLES.md,把反例映射到自己的历史问题。 -
🛠️ 第三步,在一个真实仓库小范围试点,先跑两周再评估。 -
📝 第四步,把项目特有规则并入同一文件,形成团队版本。
这条路径的重点是“先小范围验证,再规模化推广”,而不是一次性全量切换。
写在最后
andrej-karpathy-skills 的真正价值,不在于提出了新概念,而在于把很多团队已经感受到的问题,整理成可执行、可检查、可复用的规则体系。
对 AI 编码来说,这类项目比“再多一个技巧”更重要,因为它直接影响长期协作质量。
欢迎关注,点赞!