 夜雨聆风
夜雨聆风





Can "AI" Be a Doctor? 大模型临床沟通能力深度评测
论文标题:Can “AI” Be a Doctor? 大模型临床沟通能力深度评测
作者:Mariano Barone, et al.
机构:那不勒斯费德里科二世大学 | 卡帕尼亚大学 | 西北大学
链接:https://arxiv.org/abs/2604.20791
📖 导语
作为一名长期关注AI医疗应用的学者,我经常被问到一个问题:”AI什么时候能取代医生?”这个问题本身就暴露了公众对AI能力的过度期待,以及对医疗本质的某种误解。
今天要解读的这篇论文,恰恰是一剂清醒剂。来自那不勒斯大学和西北大学的研究团队,通过大规模实证研究揭示了一个重要事实:即便强如GPT-5、Claude,当前大模型在临床沟通的关键维度上仍与人类医生存在系统性差距。更值得深思的是,AI最擅长的”情感表达”优化,恰恰可能以牺牲”专业准确性”为代价——这对医疗场景而言,可能是最危险的妥协。
我想从一个研究者的视角,结合自身对医疗AI的理解,与大家分享这项工作的核心发现与启示。
🔬 研究背景与技术挑战
大语言模型(LLM)正以前所未有的速度渗透医疗健康领域。据研究统计,全球已超过15万名临床医生在150余家医疗机构中依赖AI系统辅助患者沟通。这一趋势正在深刻改变临床沟通的实践形态。
然而,现有评估体系存在一个显著的盲点:绝大多数研究聚焦于LLM的”事实准确性”——即诊断正确与否、用药合理与否——却忽视了临床沟通中同样关键、甚至更为日常的三个维度:
• 语义忠实度:AI回复是否准确传递了医学专业判断?
• 可读性:内容是否对非专业背景的患者足够通俗易懂?
• 情感共鸣:回复是否在患者脆弱时刻提供了恰当的情绪支持?
当AI在急诊室里用冰冷的学术语言回复一位焦虑的癌症患者家属时,其危害或许不如诊断错误那样直接,但由此引发的信任侵蚀、焦虑放大,对治疗依从性和最终预后同样影响深远。
⚠️ 核心挑战
研究揭示了一个令人忧虑的系统性偏差:LLM生成的医疗回复在情感维度上显著偏离医生习惯——GPT-5和Claude的”非常负面”情感表达占比达43-45%,而真实医生仅37%。更关键的是,顶级模型的FKGL(语言难度指数)高达16-17,相当于学术论文的阅读难度,而医生回复的平均水平仅为11-12。这种”过度专业”和”过度负面”的双重偏差,构成了AI临床沟通的核心挑战。
🛠️ 核心创新与主要贡献
🔹 多维评估体系:超越”准确性”的全面审视
研究团队构建了包含47,457条医疗问答的大规模语料库,涵盖从TREC医疗问答数据集等权威来源。评估在三个核心维度展开:语义忠实度(对比AI回复与专家临床判断的匹配程度)、可读性(使用Flesch-Kincaid Grade Level等标准化指标)、情感共鸣(通过情感分析量化回复中的情绪表达)。评测对象包括GPT-5、Claude等通用大模型,以及专门针对医疗领域优化的领域模型。
🔹 提示工程实验:同理心导向策略的有效性边界
研究系统测试了多种提示策略:基础提示(直接要求回答)、同理心导向提示(如”请用温暖且易于理解的方式回复”)、以及协作改写模式(让AI改进医生原始回复而非独立生成)。结果揭示了一个重要但反直觉的发现:同理心提示可将GPT-5的复杂度降低6.87个FKGL点并减少极端负面情绪,但语义准确性的提升并不显著——”更温暖”与”更专业”之间存在权衡。
🔹 双重视角评估:医生与患者的价值错位
研究同时收集了医学专家和患者两大群体的评分。数据显示了一个有趣的”价值错位”:在认知标准(如专业准确性)上,所有模型均未能超越人类医生;但在清晰度和情感语调上,患者普遍更青睐经过AI改写的版本。这种错位揭示了LLM在医疗场景中的真实定位——它可能不是”更好的医生”,但可以是”更好的沟通者”。
📊 方法论与技术细节
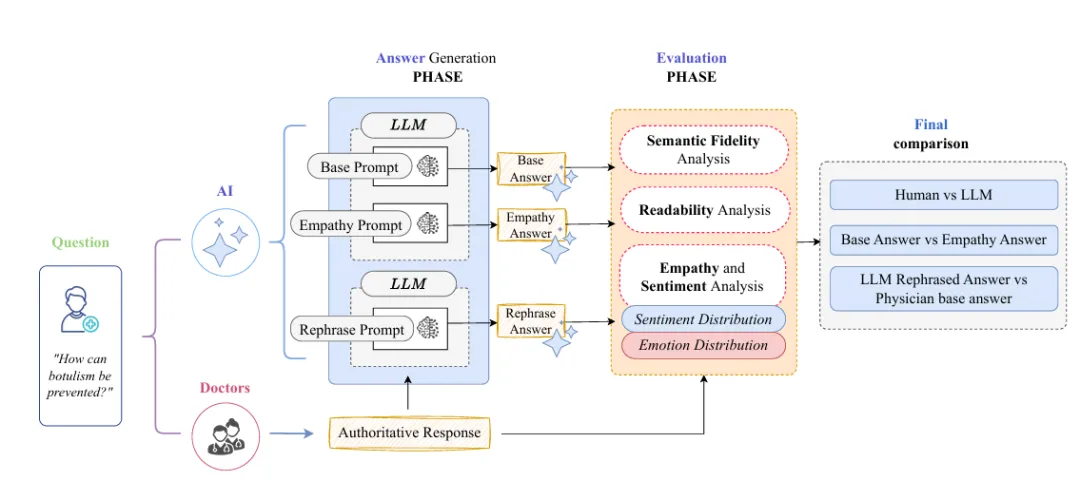
从方法论角度,这项研究有几个值得称道的设计:
• 数据来源:与以往依赖社交媒体或合成对话的研究不同,本文使用的是真实临床环境中的医生撰写内容,这保证了评估的生态有效性。
• 评估粒度:从粗粒度的准确率到细粒度的语义相似度(μ=0.93的极高相关性),研究建立了多层次的评估体系。
• 双盲对比:通过固定基线vs候选回复的配对比较设计,将主观评估转化为相对偏好,降低了评分方差。
• 提示策略覆盖:从基础到高级的多种提示配置,为实践者提供了可操作的落地路径。
然而,研究也存在局限性:主要聚焦于问答形式的医疗咨询场景,对于更具挑战性的诊断对话、手术知情同意等高风险交互的覆盖尚不充分。
📈 实验结果与分析
基础模型性能:系统性差距的存在
实验结果揭示了LLM与医生之间的多维度差距:
• 情感偏差:基础模型的负面情感表达占比(43-45%)显著高于医生(37%),GPT-5和Claude均存在这一倾向
• 语言复杂度:FKGL指数显示模型回复(16-17)难度相当于学术论文,医生回复(11-12)相当于通俗杂志
• 语义准确:Rephrase配置可达0.93的语义相似度,但这是通过改写医生内容而非独立生成实现的
提示工程效果:有限的改善与隐藏的代价
同理心提示确实带来了可测量的改善:GPT-5复杂度降低6.87个FKGL点,极端负面情感减少。然而,这种”更温暖”的代价是语义准确性的隐性下降——研究者在原文中的表述相当克制:”does not significantly increase semantic fidelity”(未显著提升语义忠实度)。
人机协作:最优的临床AI使用范式
研究的最重要发现或许是”协作改写”范式的有效性——让AI作为医生的辅助而非替代。在这一模式下,语义相似度达0.93的同时,清晰度显著提升,情感表达更加平衡。这与当前医疗AI”追求独立诊断能力”的主流叙事形成了微妙但重要的对话。
💡 核心结论
当前最强LLM在语义准确性、情感适当性和语言可读性上均与专业医生存在显著差距。同理心提示能改善情感表达但牺牲专业性;协作改写模式实现最佳平衡——AI作为医生的”沟通增强器”。医疗AI的落地路径,应是”AI辅助医生”而非”AI替代医生”。
🔮 总结与未来展望
这项研究的价值,不仅在于揭示了当前LLM与人类医生之间的差距,更在于它提出了一个更根本的问题:我们究竟需要什么样的医疗AI?
追求”AI替代医生”不仅是技术上的冒进,更可能是对医疗本质的误解。医疗从来不只是信息的传递,而是信任的建立、焦虑的安抚、以及两个灵魂之间的人文对话。AI或许可以学会模仿情感表达的表层形式,但那种在至暗时刻给予希望的力量,目前仍属于人类。
从技术演进的角度,这项研究为后续工作指明了几个重要方向:如何在保持语义准确性的前提下提升可读性?如何设计更有效的情感对齐训练策略?如何构建能够真正辅助而非干扰临床决策的人机协作范式?
对于医疗AI的实践者,研究结论同样提供了务实的指引:与其追求”全科医生”式的通用AI,不如专注于特定场景下的”沟通增强器”——帮助医生更高效地传递专业判断,同时让患者感受到被理解与被关怀。
🎯 研究者观察
🔸 一个反直觉的发现
研究中有个细节值得关注:同理心提示虽然改善了情感表达,但并未提升语义准确性。这其实反映了大模型的一个基本限制——RLHF对齐训练主要优化”人类偏好”(温暖、有帮助),而非”专业标准”(准确、可验证)。当两者冲突时,模型倾向于选择前者,这对医疗场景而言是危险的。
🔸 协作改写的启示
“协作改写”范式的成功揭示了一个被低估的价值:AI最擅长的是”优化表达”而非”独立判断”。这或许意味着,医疗AI的第一波落地红利不在诊断,而在沟通——帮助医生把专业判断翻译成患者能理解、会产生信任的语言。
🔸 对从业者的建议
对于正在考虑引入AI的医疗机构,研究提供了明确的指引:不要期望AI能独立完成诊疗全流程,而应将其定位为”沟通增强工具”——辅助医生在有限时间内提供更清晰、更有温度的患者教育材料。
💬 互动引导
作为医疗从业者或AI研究者,您如何看待LLM在临床沟通中的角色?
• 您认为”协作改写”模式能否成为医疗AI的主流落地路径?
• 在您看来,AI的情感表达能力是否应以牺牲准确性为代价?
欢迎在评论区分享您的观点!如果您对医疗AI的其他研究方向感兴趣,也可以留言告诉我们。