 夜雨聆风
夜雨聆风





Agentic AI Day8:LangChain 基础|从"调 LLM API"到"搭Agent系统"
前 7 天,我们一直在裸调 LLM API。能跑,但每次都要自己管上下文、自己封装工具调用、流程编排全靠 if-else。LangChain 就是来解决这些痛苦的。
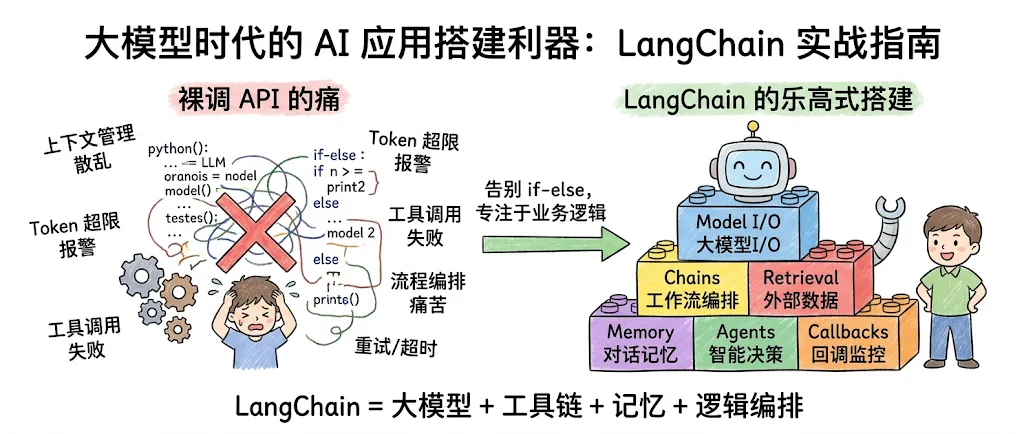
一、为什么必须学 LangChain?
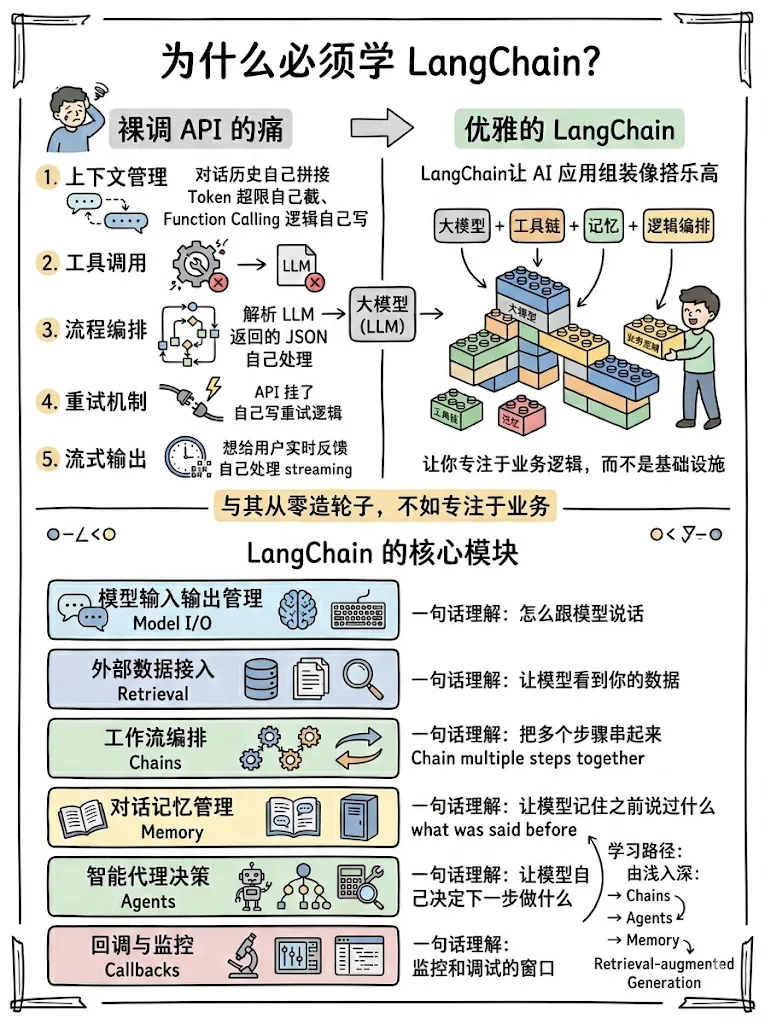
1.1 裸调 API 的痛
如果你自己写过 LLM 应用,大概率经历过这些:
-
上下文管理:对话历史自己拼接,Token 超限了自己截 -
工具调用:Function Calling 逻辑自己写,解析 LLM 返回的 JSON 自己处理 -
流程编排:多个步骤串联全靠 if-else 和嵌套调用 -
重试/超时:API 挂了怎么办?自己写重试逻辑 -
流式输出:想给用户实时反馈?自己处理 streaming
LangChain = 大模型 + 工具链 + 记忆 + 逻辑编排
它让你像搭乐高一样组装 AI 应用,而不是从零造轮子。一句话:让你专注于业务逻辑,而不是基础设施。
1.2 LangChain 的核心模块
LangChain 的架构可以概括为 6 个核心层:
|
|
|
|
|---|---|---|
| Model I/O |
|
|
| Retrieval |
|
|
| Chains |
|
|
| Memory |
|
|
| Agents |
|
|
| Callbacks |
|
|
学习路径:Chains → Agents → Memory → RAG,由浅入深。
二、Chains:把多个步骤串起来
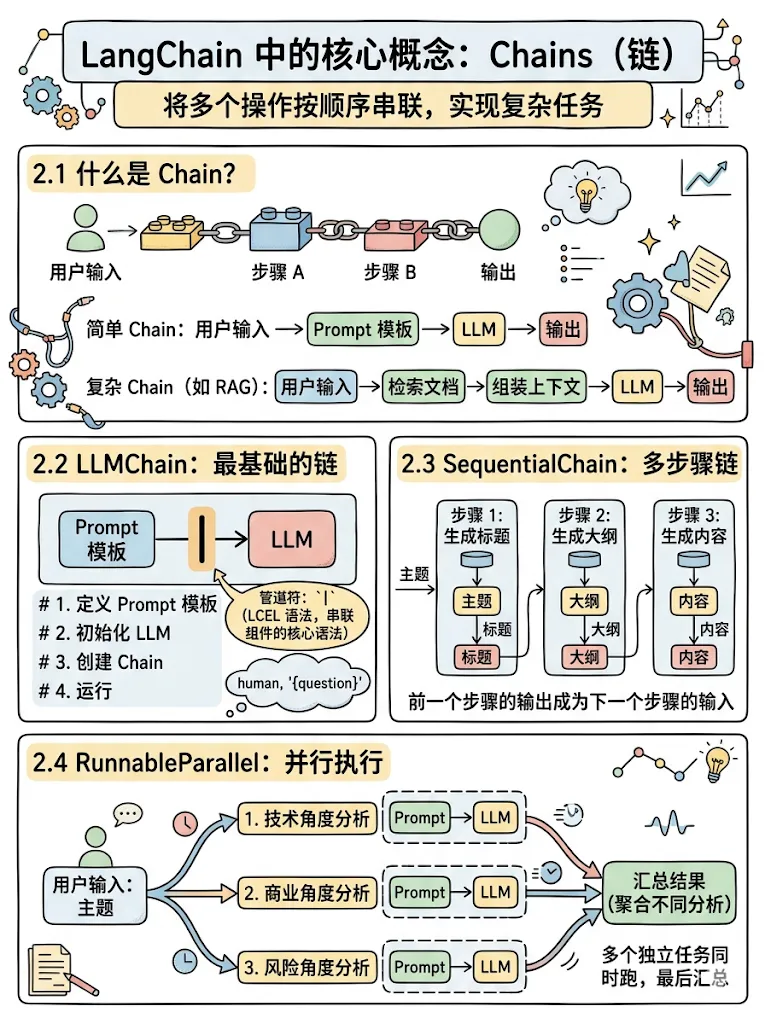
2.1 什么是 Chain?
Chain 的本质很简单:把多个操作按顺序串联。
最简单的 Chain:
用户输入 → Prompt Template → LLM → 输出复杂 Chain(比如 RAG):
用户输入 → 检索文档 → 组装上下文 → LLM → 输出2.2 LLMChain:最基础的链
from langchain_openai import ChatOpenAIfrom langchain_core.prompts import ChatPromptTemplate# 1. 定义 Prompt 模板prompt = ChatPromptTemplate.from_messages([ ("system", "你是一个专业的程序员助手。"), ("human", "{question}")])# 2. 初始化 LLMllm = ChatOpenAI(model="gpt-4o", temperature=0.7)# 3. 创建 Chain(使用 LCEL 语法)chain = prompt | llm# 4. 运行result = chain.invoke({"question": "什么是递归?"})print(result.content)关键语法:| 管道符。这是 LangChain 的 LCEL(LangChain Expression Language),像 Unix 管道一样组合组件。
2.3 SequentialChain:多步骤链
一个步骤的输出作为下一个步骤的输入——内容创作、代码生成的常见模式。
from langchain_core.output_parsers import StrOutputParser# 步骤 1:生成标题title_chain = ( ChatPromptTemplate.from_template("根据以下主题生成一个吸引人的标题:{topic}") | llm | StrOutputParser())# 步骤 2:根据标题生成大纲outline_chain = ( ChatPromptTemplate.from_template("根据以下标题生成文章大纲:{title}") | llm | StrOutputParser())# 步骤 3:根据大纲生成内容content_chain = ( ChatPromptTemplate.from_template("根据以下大纲生成文章内容:{outline}") | llm | StrOutputParser())# 组装:前一个的输出自动成为下一个的输入full_chain = title_chain | outline_chain | content_chain# 运行result = full_chain.invoke({"topic": "Agentic AI 的未来"})2.4 RunnableParallel:并行执行
多个独立任务同时跑,最后汇总:
from langchain_core.runnables import RunnableParallel# 同时生成三个不同角度的分析parallel_chain = RunnableParallel({"technical": ChatPromptTemplate.from_template("从技术角度分析:{topic}") | llm | StrOutputParser(),"business": ChatPromptTemplate.from_template("从商业角度分析:{topic}") | llm | StrOutputParser(),"risk": ChatPromptTemplate.from_template("从风险角度分析:{topic}") | llm | StrOutputParser(),})result = parallel_chain.invoke({"topic": "LangChain 在企业的落地"})# result = {"technical": "...", "business": "...", "risk": "..."}三、Agents:让 LLM 自己决定怎么做
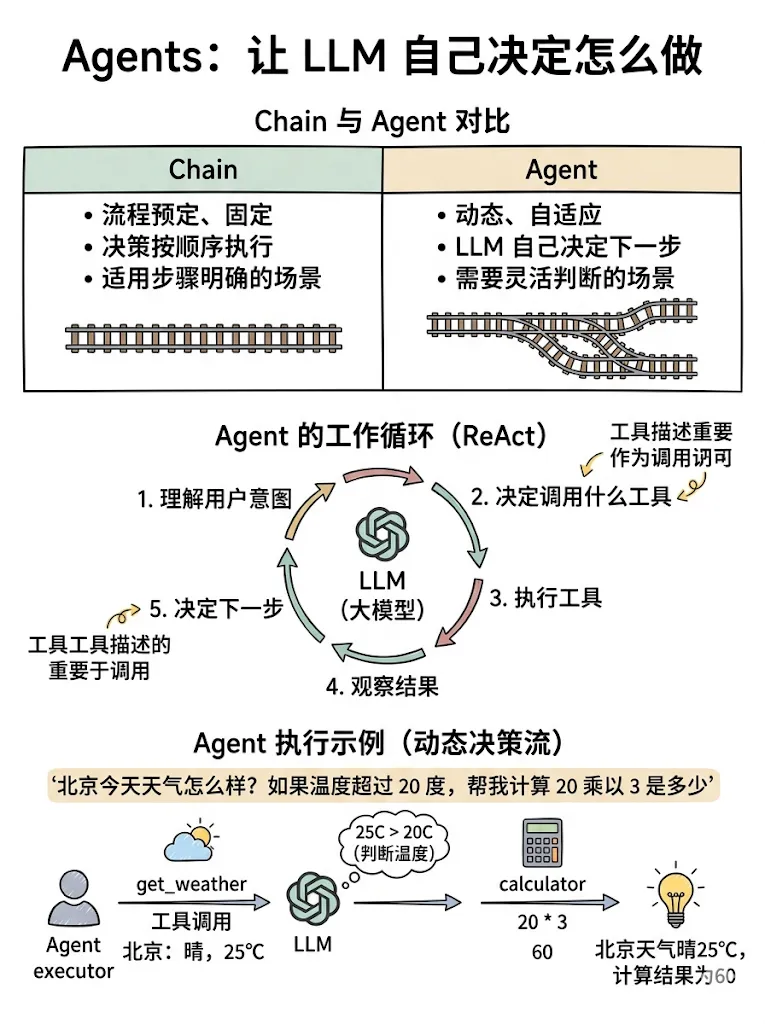
3.1 Chain vs Agent
|
|
|
|
|---|---|---|
| 流程 |
|
|
| 决策 |
|
|
| 适用 |
|
|
Agent 的工作循环(ReAct):
1. 理解用户意图2. 决定调用什么工具3. 执行工具4. 观察结果5. 决定下一步(重复直到完成)3.2 定义工具
from langchain_core.tools import tool# 工具 1:计算器@tooldefcalculator(expression: str) -> str:"""计算数学表达式,输入如 '2+3*4' 或 '10/2'"""try:return str(eval(expression))except Exception as e:returnf"计算错误:{str(e)}"# 工具 2:天气查询@tooldefget_weather(city: str) -> str:"""查询指定城市的天气情况""" weather_data = {"北京": "晴,25°C","上海": "多云,22°C","深圳": "小雨,28°C" }return weather_data.get(city, f"{city}:暂无天气数据")tools = [calculator, get_weather]⚠️ 工具描述很重要:LLM 根据 description 决定是否调用这个工具,描述写得越准确,调用越精准。
3.3 创建 Agent
from langchain.agents import create_tool_calling_agent, AgentExecutorfrom langchain_core.prompts import MessagesPlaceholder# 定义 Agent 的 Promptprompt = MessagesPlaceholder([ ("system", "你是一个智能助手,可以调用工具帮助用户解决问题。"), ("human", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"),])# 创建 Agentagent = create_tool_calling_agent( llm=llm, tools=tools, prompt=prompt,)# 用 AgentExecutor 执行executor = AgentExecutor( agent=agent, tools=tools, verbose=True, # 打印执行过程 handle_parsing_errors=True,)# 运行result = executor.invoke({"input": "北京今天天气怎么样?如果温度超过 20 度,帮我计算 20 乘以 3 是多少"})Agent 会自动:
-
判断需要调用 get_weather工具 -
执行后看到”25°C > 20°C” -
判断需要调用 calculator工具 -
返回最终答案
四、Memory:让 Agent 有”记忆”
4.1 为什么需要 Memory?
默认情况下,LLM 是”无状态”的:
-
每次调用都是独立的 -
不知道之前的对话内容 -
无法保持上下文
Memory 解决了这个问题。
4.2 四种 Memory 类型
from langchain_core.chat_history import InMemoryChatMessageHistoryfrom langchain_core.prompts import MessagesPlaceholder# 方式 1:完整记忆(适合短对话)history = InMemoryChatMessageHistory()history.add_user_message("你好,我叫张三")history.add_ai_message("你好张三!")history.add_user_message("我叫什么名字?")# AI 能回答"张三"# 方式 2:滑动窗口(适合长对话,只保留最近 k 轮)from langchain.memory import ConversationBufferWindowMemorywindow_memory = ConversationBufferWindowMemory(k=3, return_messages=True)# 只保留最近 3 轮对话,控制 Token 消耗# 方式 3:摘要记忆(超长对话,Token 紧张)from langchain.memory import ConversationSummaryMemorysummary_memory = ConversationSummaryMemory(llm=llm, memory_key="summary")# LLM 自动总结历史对话,只保留摘要# 方式 4:向量检索记忆(需要检索历史相关内容的场景)from langchain.memory import VectorStoreRetrieverMemoryvector_memory = VectorStoreRetrieverMemory(retriever=vectorstore.as_retriever())# 基于语义相似度检索历史对话4.3 在 Chain 中使用 Memory
from langchain.chains import ConversationChainconversation = ConversationChain( llm=llm, memory=ConversationBufferWindowMemory(k=3), verbose=True)# 多轮对话print(conversation.invoke({"input": "你好,我叫张三"}))print(conversation.invoke({"input": "我叫什么名字?"})) # 能记住!print(conversation.invoke({"input": "我喜欢 Python 编程"}))print(conversation.invoke({"input": "你知道我喜欢什么吗?"})) # 能记住!4.4 Memory 选型指南
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
五、文档问答 Chain:RAG 的 LangChain 实现
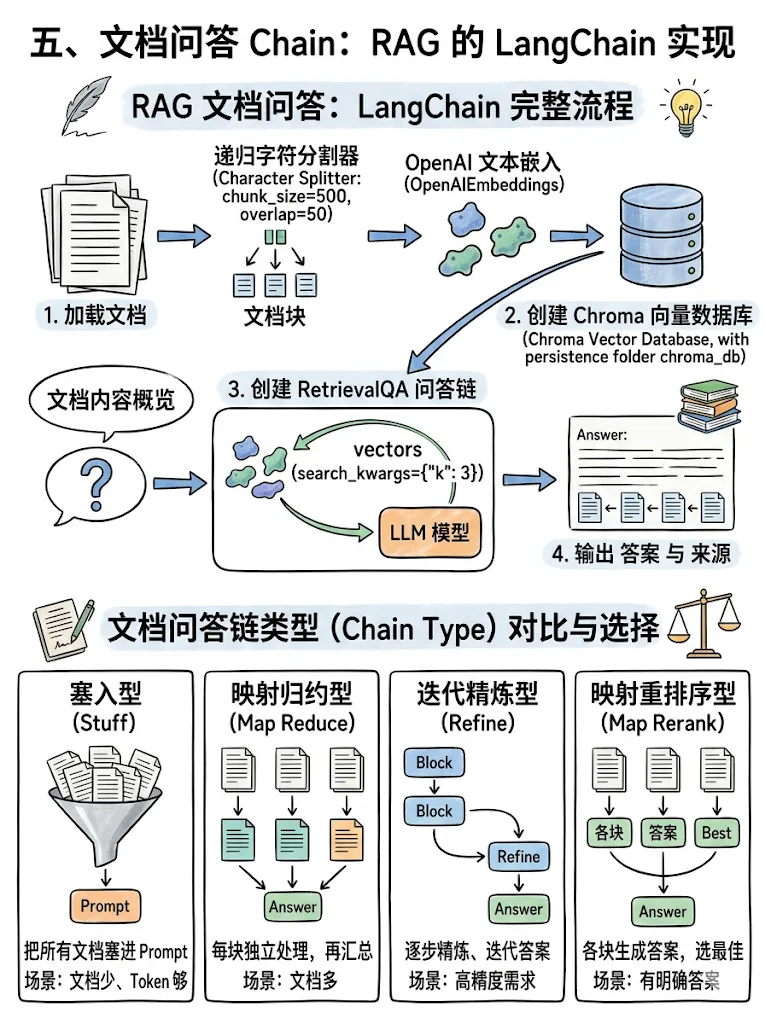
5.1 完整流程
from langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_community.vectorstores import Chromafrom langchain_openai import OpenAIEmbeddingsfrom langchain.chains import RetrievalQA# 1. 加载并分割文档with open("document.txt") as f: text = f.read()text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, chunk_overlap=50,)chunks = text_splitter.split_text(text)# 2. 创建向量存储embeddings = OpenAIEmbeddings(model="text-embedding-3-small")vectorstore = Chroma.from_texts( chunks, embeddings, persist_directory="./chroma_db")# 3. 创建 QA Chainqa_chain = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever(search_kwargs={"k": 3}), return_source_documents=True)# 4. 提问result = qa_chain.invoke({"query": "文档的主要内容是什么?"})print(f"答案:{result['result']}")print(f"来源:{result['source_documents']}")5.2 Chain Type 对比
|
|
|
|
|---|---|---|
stuff |
|
|
map_reduce |
|
|
refine |
|
|
map_rerank |
|
|
六、踩坑实录 💣
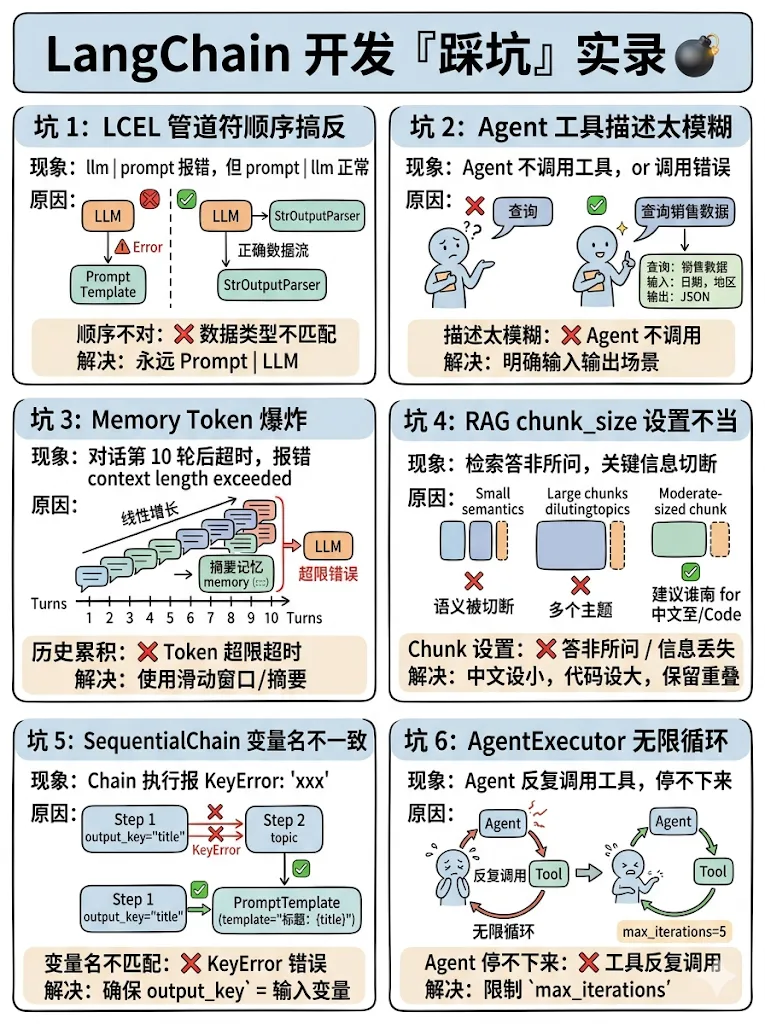
坑 1:LCEL 管道符顺序搞反
现象:llm | prompt 报错,但 prompt | llm 正常。
原因:LCEL 管道符 | 的顺序是数据流向——先 Prompt(组装输入),再 LLM(处理)。反过来数据格式不匹配。
解决:永远 prompt | llm | parser,不要反。
# ✅ 正确chain = prompt | llm | StrOutputParser()# ❌ 错误chain = llm | prompt # 数据类型不匹配坑 2:Agent 工具描述太模糊
现象:Agent 不调用工具,或者调用了错误的工具。
原因:LLM 完全依赖工具的 description 来决定是否调用。描述太模糊(如”查询工具”)会导致决策错误。
解决:工具描述要具体到输入输出格式和适用场景。
# ❌ 模糊@tooldefquery_data(query: str) -> str:"""查询数据"""# ✅ 具体@tooldefquery_sales_data(date: str, region: str) -> str:"""查询指定日期和地区的销售数据。 Args: date: 格式 YYYY-MM-DD region: 地区名称,如"北京"、"上海" Returns: JSON 格式的销售数据 """坑 3:Memory Token 爆炸
现象:对话进行到第 10 轮后,API 调用超时或报错 “context length exceeded”。
原因:ConversationBufferMemory 保存完整对话历史,每轮都累加,Token 数线性增长。
解决:
# 方案 1:滑动窗口(推荐)window_memory = ConversationBufferWindowMemory(k=5, return_messages=True)# 方案 2:摘要记忆summary_memory = ConversationSummaryMemory( llm=llm, max_token_limit=1000# 超过 1000 token 自动压缩)# 方案 3:手动监控print(f"当前记忆 Token 数:{len(buffer_memory.buffer.split())}")坑 4:RAG chunk_size 设置不当
现象:检索到的文档片段答非所问,或者关键信息被切断了。
原因:
-
chunk_size 太大 → 一个片段包含多个主题,检索不够精准 -
chunk_size 太小 → 完整语义被切断,LLM 理解不了
解决:
# 中文文档推荐text_splitter = RecursiveCharacterTextSplitter( chunk_size=400-600, # 中文建议小一点 chunk_overlap=50-100, # 重叠保留上下文 separators=["\n\n", "\n", "。", "!", "?", " ", ""])# 代码文档推荐text_splitter = RecursiveCharacterTextSplitter( chunk_size=800, chunk_overlap=100, separators=["\nclass ", "\ndef ", "\n\n", "\n"])坑 5:SequentialChain 变量名不一致
现象:Chain 执行时报 “KeyError: ‘xxx'”。
原因:前一个 Chain 的 output_key 和后一个 Chain 的输入变量名不匹配。
解决:
# ✅ 确保变量名一致chain1 = LLMChain(llm=llm, prompt=prompt1, output_key="title")chain2 = LLMChain(llm=llm, prompt=prompt2, input_keys=["title"], output_key="outline")# prompt2 中必须使用 {title} 变量prompt2 = ChatPromptTemplate.from_template("根据标题生成大纲:{title}")坑 6:AgentExecutor 无限循环
现象:Agent 反复调用同一个工具,停不下来。
原因:工具返回的结果无法让 Agent 得出结论,它不断重试。
解决:
executor = AgentExecutor( agent=agent, tools=tools, max_iterations=5, # 限制最大迭代次数 early_stopping_method="generate", # 超时后让 LLM 生成最终回答 handle_parsing_errors=True,)七、总结:LangChain 核心概念速查
|
|
|
|
|---|---|---|
| LCEL |
|
prompt | llm | parser |
| Chains |
|
RunnableParallel
SequentialChain |
| Agents |
|
create_tool_calling_agent |
| Memory |
|
WindowMemory
SummaryMemory |
| Tools |
|
@tool
|
| RetrievalQA |
|
RetrievalQA.from_chain_type |
学习建议:
-
先掌握 LCEL 管道语法,这是 LangChain 1.x 的基础 -
从简单 Chain 开始,再学 Agent -
Memory 和 RAG 是生产环境必学 -
工具描述要写清楚,这是 Agent 效果的关键
Agentic AI Day 9 预告::
LangChain Agent 开发|Agent 类型、Tool 定义、AgentExecutor
Day 8 学会了 LangChain 基础:
-
能搭 Chain -
能跑 Agent -
能加 Memory -
能做文档问答
但有几个问题没搞明白:
-
Agent 到底有几种类型?怎么选? -
Tool 怎么定义才规范? -
AgentExecutor 是干啥的? -
自定义 Agent 怎么做?
Day 9 把这些问题讲透。
关注我,获取更多大模型训练/部署、AI Infra的硬核技术干货,带你从原理到实战,玩转大模型!