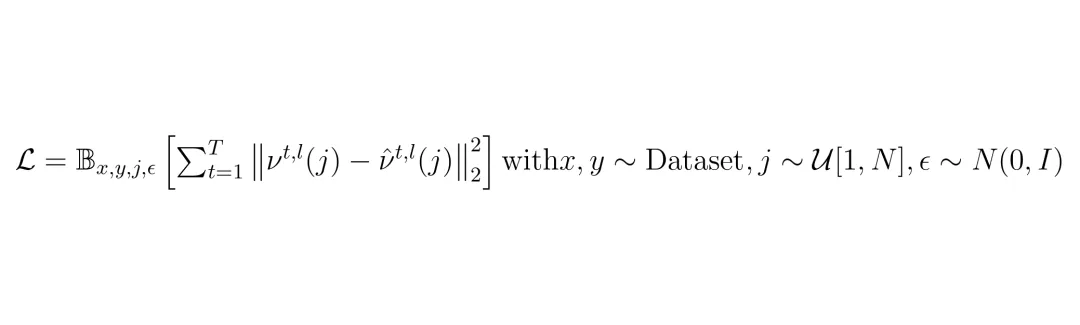一个AI架构搞定所有尺度?洛桑大学推出“万能”降水超分模型
🐉 龙哥读论文知识星球来了! 公众号每日8篇拆解不够看?星球 无上限更AI领域论文、资讯、招聘、招博、开源代码, 一站式干货,每日2分钟刷完即赚! 👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~
龙哥推荐理由:
原论文信息如下:
论文标题:
发表日期:
龙哥开讲!今天咱们来聊一篇让你看完直呼“妙啊”的论文。你有没有想过,给AI一张超模糊的卫星云图,让它不但能把空间分辨率拉高十倍,还能把帧率从一小时一帧脑补成十分钟一帧,而且还要保证降雨量守恒?听着就头大对吧?更离谱的是,如果现在要求你换一个放大倍数,比如从10倍变成25倍,那模型是不是得重新设计?大部分深度学习超分模型确实是这样的“钉子户”——钉死在一个放大倍数上,换一个就得重来。但今天这篇来自洛桑大学等机构的论文,偏偏要搞一个“万金油”架构,只用调几个旋钮就能应对不同尺度,而且效果还贼好。咱们一起看看他们是怎么做到的。
降水预测的尺度难题:一个架构能搞定所有吗? 先说说痛点。在地球科学尤其是水文气象领域,降水数据来自卫星、雷达、雨量计和再分析产品,空间分辨率从1公里到几十公里不等,时间频率从分钟级到小时级。如果我们想拿一个AI模型来做视频超分辨率(Video Super-Resolution, VSR) ×4的模型,想改成×8?不好意思,整个架构得重来。这在实际应用中简直要命——做气候影响评估的同学经常要处理不同来源的数据,每换一种分辨率就得重新造轮子。
更麻烦的是,降水数据本身极其“叛逆”:有很多零值区域(无降水),又偶尔出现极大值(极端暴雨),分布重尾且高度间歇。传统基于L2损失的确定性模型在这种数据上会倾向于预测模糊均值,极端值被严重低估。而生成模型如GAN又容易训练不稳定。近年扩散模型(Denoising Diffusion Probabilistic Models, DDPM,即去噪扩散概率模型)在图像生成上大放异彩,也自然被引入时空超分。但同样的问题——它们通常只为固定放大倍数设计。
本文的野心就是打破这个僵局。他们提出一个尺度自适应框架(Scale-Adaptive Framework)
分解任务:确定性预测 + 扩散模型 = 灵活超分
整个方法的设计哲学就是“分而治之”。他们把时空超分解耦成两步:
第一步:确定性均值预测 物质守恒变换(Mass Conservation, MC)
第二步:残差扩散采样 去噪扩散概率模型(DDPM)
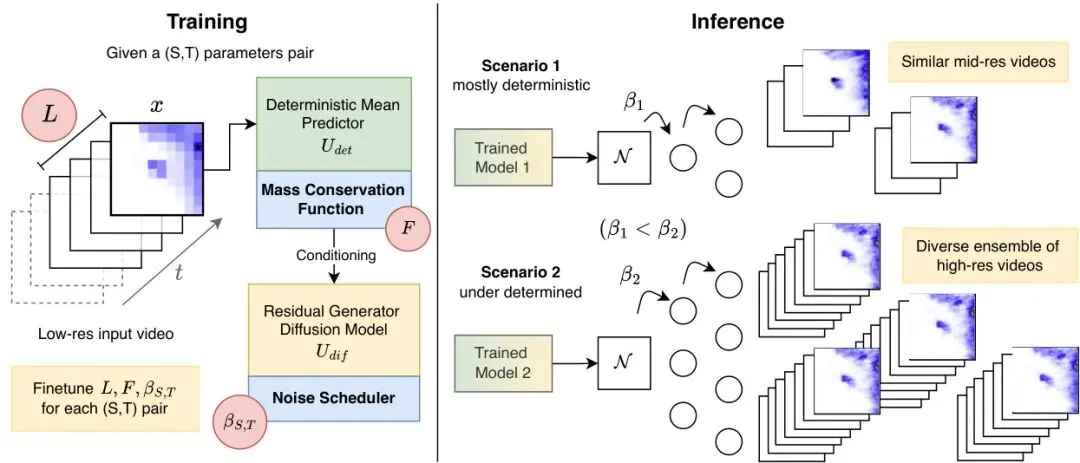
图1:尺度自适应时空视频超分:确定性U-Net预测粗粒度平均场,随后是可选的物质守恒变换和残差扩散头,后者生成以均值为条件的目标准确率视频。尺度自适应通过调整注意力范围L和噪声调度β(对于较大SR因子增加β以促进视频多样性)实现。
训练损失公式:L = E[ sum_{t=1}^T || v – v_hat ||^2 ],其中v是速度(噪声与残差的加权组合),v_hat是网络预测
这里v定义为:v = sqrt(ᾱ) * ε - sqrt(1-ᾱ) * r,其中r是真实残差,ε是高斯噪声,ᾱ是累积噪声系数。网络预测速度,再反推出噪声和残差。这种预测方式比直接预测噪声更稳定。
三个关键旋钮:让同一个模型适应不同的尺度
既然架构不变,那怎么适应不同的放大倍数呢?文章找到了三个可调节的超参数,它们直接关联到尺度变化带来的需求变化:
1. 时间上下文长度 L
2. 噪声调度振幅 β_max
3. 物质守恒函数 F
表2:根据超分辨率因子优化的超参数配置。颜色深浅表示值的大小:β_max和注意力时间随因子增大而增大,质量守恒函数趋于更平缓的增长,阈值也增大。
可以看到,随着空间因子S和时间因子T的增加,注意力时间A_T从12小时增加到18小时,β_max从0.01增加到0.035,质量守恒函数从开平方逐渐过渡到线性甚至恒等(但阈值提高)。这说明尺度越大,需要的上下文越长、噪声越大、对极端的抑制越强
视觉盛宴:AI如何脑补出暴雨的细节?
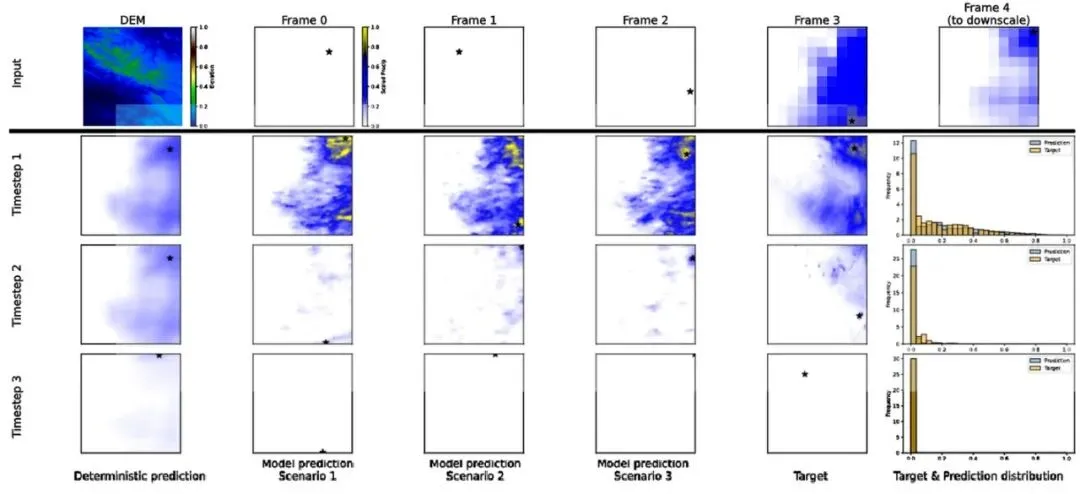
文字描述终究苍白,直接上图。下图是针对放大倍数(10, 3)的一个示例:第一行是模型输入——地形图和过去5帧的低分辨率降水场(每帧4×4像素),每一列代表一个输出。左起第一列是确定性U-Net的预测(平滑模糊),后三列是扩散模型生成的三个不同场景,最后一列是真值(Ground Truth)。每三行对应三个时间帧(T=3)。
图2:模型生成的时空降水超分定性示例。第一行为低分辨率输入序列和地形图。第一列对应确定性(平均)预测,随后每列显示扩散模型生成的一个高分辨率场景,展示了多种合理结果。颜色梯度在除地形外的所有帧中一致。
看到没有?确定性预测(第一列)完全是一团模糊,连降水中心都看不清楚。但扩散模型生成的三个场景不仅清晰地重建了降水区的形状和位置,还捕获了高强度的黄色区域(极端降水),而且三个场景之间各有差异——这正是我们想要的:同一个低分辨率输入,对应多个可能的高分辨率现实,而且每个都看起来真实。相比而言,双三次插值和最近邻插值这类传统方法会完全丢失细节,而EDSR(Enhanced Deep Residual Network,增强深度残差网络)这类纯确定性深度学习模型也会过于平滑。扩散模型带来的多样性,对于风险评估和概率预报至关重要。
定量比较:全面碾压,但仍有提升空间
光好看不够,还得看硬指标。下表对比了在(10, 3)放大倍数下,六种模型的八项指标。基线包括双三次插值、最近邻插值、EDSR;本文的模型分为三版:纯确定性模型、去掉注意力的生成模型、以及完整架构。
表1:在(10,3)因子对上的性能对比。三个基线(双三次、最近邻、EDSR)和三个本文提出的超分模型(蓝色部分)。使用八项互补指标评估像素精度、结构一致性和气候相关性。每项指标的最佳得分用绿色高亮显示。
看结果,直接惊呼:完整架构在MSE(均方误差)、MAE(平均绝对误差)、99th PE(99百分位误差)、LSD(局部标准差误差)、EMD(推土机距离)、PITD(概率积分变换偏差)、CRPS(连续排序概率分数)上全部大幅领先,通常比最好的基线(EDSR或确定性模型)好一个数量级!唯一的例外是SSIM(结构相似性指数)——双三次和确定性模型居然略高。但SSIM本身偏爱平滑图像,对于降水这种精细结构反而可能不敏感。所以这不算缺点。
另外,纯确定性模型(没有扩散)的性能其实也不错,尤其在计算资源有限时可以作为轻量选择。而去掉注意力模块的生成模型效果很差,说明时空注意力机制对于提取有效的上下文信息至关重要。
需要指出的是,本文目前仅在“完美模型”设定下验证,即低分辨率数据由高分辨率数据直接平均下采样得到,没有考虑观测噪声和偏差。实际场景中还有大量工程问题要解决,但至少从学术角度证明了这条路径的潜力。
龙迷三问
这篇论文解决什么问题?
残差扩散是什么意思?为什么用残差?
三个超参数是如何优化的?
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~
龙哥点评 论文创新性分数: ★★★★☆
实验合理度: ★★★★★
基线选择恰当(传统+简单深度学习+消融),评估指标全面(8项,涵盖像素、结构、分布),四组放大倍数验证,结果清晰可信。
学术研究价值: ★★★★☆
为尺度可迁移的生成式超分提供了清晰的方法论,尤其在气候科学领域有重要参考意义。但仅测试了理想下采样场景,尚未验证真实噪声输入下的鲁棒性。
稳定性: ★★★☆☆
扩散模型生成结果多样性好,但个别极端场景可能出现离群值。物质守恒变换在较大尺度时需要精细调参,否则可能放大噪声。整体可用但需谨慎。
适应性以及泛化能力: ★★★★☆
架构可迁移到不同放大倍数,但需要针对每对因子独立训练,且超参数需重新优化。迁移到新区域或新数据集尚未验证,理论上存在过拟合风险。
硬件需求及成本: ★★★☆☆
训练每个因子对需要约1天(A100 GPU),推理相对快(几分钟处理一批)。但每个因子独立训练,多因子场景下总成本线性增加。扩散模型推理比纯确定性慢。
复现难度: ★★★★★
代码和数据均已开源(GitHub和数据链接),且超参数调优方法描述清晰,可复现性极强。
产品化成熟度: ★★☆☆☆
目前仅在理想设置下表现良好,距离实际降雨预报产品仍差一个“偏置校正+观测噪声”环节。但作为后端模型,可直接用于集合预报系统的降尺度模块,有一定产品化基础。
可能的问题: 论文假设条件均值结构随尺度不变,但实际中极端事件可能改变大尺度形态;超参数调优依赖PITD,需要生成大量场景才能准确估计,增加调优成本。另外,未与其他通用视频超分模型(如BasicVSR)对比,稍显不足。
[1] Liu H, Ruan Z, Zhao P, et al. Video super-resolution based on deep learning: a comprehensive survey. Artificial Intelligence Review, 2022, 55(8): 5981-6035. [2] Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models. NeurIPS, 2020. [3] Salimans T, Ho J. Progressive distillation for fast sampling of diffusion models. ICLR, 2022. [4] Defez M, Quarenghi F, Vrac M, et al. A Scale-Adaptive Framework for Joint Spatiotemporal Super-Resolution with Diffusion Models. arXiv:2604.21903, 2026.
*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的 “阅读原文”, 查看更多原论文细节哦!
欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群 :kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 图像处理+上海+清华+龙哥) ,根据格式备注,可更快被通过且邀请进群。
『龙哥读论文』微信群目前包含:图像处理、大模型及智能体、自动驾驶及机器人、AI医疗及AI金融5个群
 夜雨聆风
夜雨聆风