 夜雨聆风
夜雨聆风





大模型+图推理,让AI像侦探一样“看图说话”破谣言
划重点:当一条耸人听闻的新闻刷屏时,你还在纠结“这是真的吗?” 别急,AI侦探已经为你画好了“破案”路线图。
面对“日本核污水排海导致海盐致癌”这样的复杂谣言,传统AI可能只会甩给你一句“这是假的”,或者引用一两段不痛不痒的证据。
但今天要介绍的这位“AI侦探”不一样,它不仅能告诉你真假,还会像侦探办案一样,把谣言拆解成多个子命题,画出它们之间的逻辑关系图,然后为每个子命题找到正反两方的证据进行“辩论式”推理,最后生成一张清晰直观的“案情分析图”和总结性文字。
这就是来自吉林大学、香港浸会大学等机构的研究团队提出的 G-Defense 框架。它结合了大语言模型(LLM)的生成能力、检索增强生成(RAG)的证据获取能力,以及图神经网络(GNN)的结构化推理能力,在假新闻检测和解释生成两项任务上,都达到了最先进的性能。
更关键的是,它完全不需要依赖耗时费力的人工核实报告,仅凭网络上未经验证的众包信息,就能实现高效、可解释的检测。
01 痛点:假新闻泛滥,传统AI“说不清、道不明”
假新闻的危害无需赘言。从疫情初期的“口罩导致缺氧中毒”谣言,到层出不穷的各类社会恐慌信息,其传播速度和破坏力远超想象。
传统的自动化假新闻检测方法,往往存在两大硬伤:
- “说不清”:
早期方法通常只是从相关报告中高亮出几个关键词或句子作为“证据”。这种碎片化的解释缺乏连贯的逻辑推理过程,用户看了依然一头雾水,不知道模型到底是怎么得出“真假”结论的。 - “来不及”:
一些更先进的方法会尝试生成完整的解释文本,但它们严重依赖人工核实过的辟谣报告作为监督信号。问题是,针对突发新闻,权威机构的辟谣报告往往严重滞后,等报告出来,谣言早已泛滥成灾。
大语言模型(LLM)的出现带来了曙光。它强大的语言理解和生成能力,似乎天生就适合做“解释”这件事。然而,LLM本身存在“幻觉”(胡编乱造)问题,且其内部知识可能过时。
于是,检索增强生成(RAG) 成为主流方案:先为LLM检索外部证据,再让它基于证据进行推理。但这又引出了新问题:该信谁的?
如果只从维基百科等可信但更新慢的知识库检索,无法应对突发新闻。如果从社交媒体、新闻报道等更新快但未经验证的“野生”信息源检索,又可能被其中的错误或偏见信息带偏。

图1展示了一个典型谣言(“日本核污水排海导致海盐短缺和癌症风险”)的分析过程。左图可见,支持方(R1, R2, R4)的证据信息量少、可信度低;而反对方(R3)则提供了详细、可靠的证据。
研究团队从中洞察到一个关键规律:在围绕一个声明的正反两方“辩论”中,与事实真相一致的那一方,其证据往往具有更高的信息量和可靠性。 因此,比较双方证据的质量,而非单纯依赖某一方,成为判断真伪的更可靠途径。
02 破局:从“整体判断”到“庖丁解牛”
基于上述洞察,团队在早期工作 L-Defense 的基础上,进行了革命性升级,提出了 G-Defense。
L-Defense 已经引入了“防御式推理”(Debate-style Reasoning)的思想,即让LLM基于正反两方的证据分别生成解释,然后比较解释的质量来判定真假。但它仍将新闻声明作为一个整体来处理。
G-Defense 的核心突破在于“分解”与“构图”。 它认为,复杂的新闻声明(尤其是谣言)往往由多个相互关联的子命题构成。不对其进行拆解,就很容易遗漏关键细节,导致解释不完整。
如图1右图所示,对于“核污水导致海盐致癌”这个声明,G-Defense 会将其分解为:
-
c1: 核污染水正在被排放并广泛扩散。 -
c2: 排放的物质会在环境中持续存在。 -
c3: 海盐生产会受到影响。 -
c4: 海盐是唯一的食盐来源。 -
c5: 食用受污染的海盐会致癌。
传统的“独立”处理方法(Independent)会分别验证这5点,然后简单聚合结果。但这忽略了子声明之间内在的逻辑依赖关系,例如,要判断c3(海盐生产受影响),必须先确认c1(污水扩散)和c2(物质持久)。
G-Defense 则通过构建“以声明为中心的图”(Claim-centered Graph)来建模这些依赖关系(如图1右图Graph所示),使得推理过程更符合人类的逻辑思维。
03 核心方法:四步走,打造AI谣言“侦探”
G-Defense 的工作流程清晰分为四个模块,如同侦探破案的四个步骤:
第一步:构图——画出“案情”关系网给定一个新闻声明,首先请LLM将其分解成多个子声明。接着,再次请LLM分析这些子声明之间的逻辑依赖关系(如支持、反驳、前提条件等),并构建成一个有向图。图中的节点是子声明,边代表依赖关系。

第二步:取证与辩论——为每个“疑点”寻找正反证据对于图中的每一个子声明节点,系统会利用RAG技术,从外部信息源(如新闻网站、社交媒体)检索与之相关的报告。然后,关键的一步来了:系统会引导LLM扮演“控方”和“辩方”,基于检索到的证据,分别生成支持该子声明为真和支持该子声明为假的两段竞争性解释。
第三步:图推理——在关系网中进行“防御式”审判此时,原始的声明图已经“升级”为一个“解释增强的声明图”——每个节点都附上了正反两方的解释。接下来,一个基于图的推理模块(这里使用了图神经网络GNN)会对整个图进行信息聚合与推理。它不仅要看每个节点上正反解释的质量对比,还要考虑节点之间的依赖关系是如何传递和影响最终判断的。这个过程模拟了法庭上基于证据链和逻辑关系的综合审判。
第四步:生成报告——输出“判决书”和“案情图解”最后,根据第三步的推理结果,系统已经得出了整个声明的真实性判断,以及每个子声明的可能真伪。此时,再请LLM出马,生成一段简洁、连贯的总结性文字解释,告诉用户为什么这个声明是真/假的。同时,系统可以自动从“解释增强图”中,剔除掉与最终判定不符的那些解释分支,生成一个最终的、清晰的解释图,直观展示推理路径。
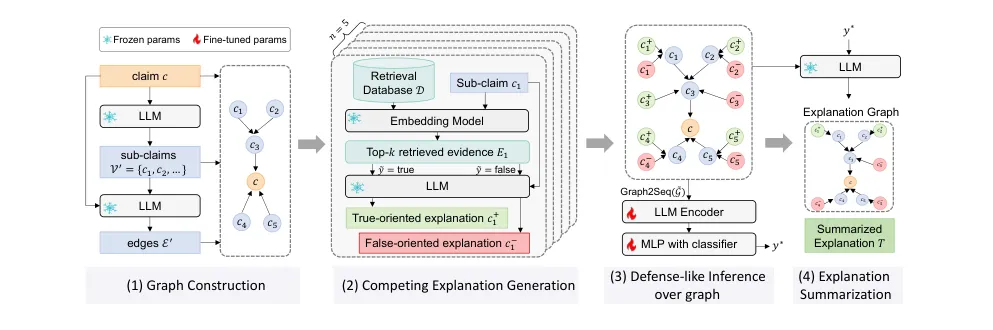
图2完整展示了G-Defense框架的四大模块,清晰勾勒出从声明输入到解释图输出的全过程。
04 实验结果:不仅判得准,而且讲得明
研究团队在Snopes和PolitiFact两个权威假新闻检测基准数据集上进行了全面测试。
-
检测性能SOTA:G-Defense在声明真实性检测的准确率(Accuracy)和宏平均F1值(Macro-F1)上,均显著超过了所有基线模型,包括其前身L-Defense以及一系列基于LLM+RAG的先进方法。这证明了“分解+构图+防御推理”这一套组合拳的有效性。
-
解释质量领先:研究者从信息量(是否包含关键事实)、可信度(是否基于可靠证据)、流畅性和相关性等多个维度,对模型生成的解释文本进行了人工评估。结果显示,G-Defense生成的解释在各项指标上均优于或与其他最佳模型持平,并且与人类专家撰写的解释质量最为接近。
-
消融实验验证:通过移除“图结构”或“防御式推理”等组件构造模型变体,实验证实了这两个核心设计缺一不可。图结构能有效捕捉子声明间的依赖,提升复杂声明的推理能力;而防御式推理通过比较竞争解释,显著提升了对未验证证据源的鲁棒性。
05 意义与影响:重塑信息验证的范式
G-Defense 的研究,其价值远不止于一项性能优异的算法。
-
学术上:它成功地将符号逻辑(图结构) 与亚符号计算(LLM的分布式表示与生成) 相结合,为可解释AI(XAI)领域,特别是复杂推理任务的可解释性,提供了一个强有力的框架范式。它证明了“分解问题、构建结构、竞争推理”这条路径的可行性。
-
产业应用上:
- 社交媒体平台:
可以集成此类系统,对热门、可疑的帖文进行实时分析和标记,为用户提供“事实核查”提示,而不仅仅是简单的“删除”或“限流”。 - 新闻编辑室:
记者和编辑可以利用它作为辅助工具,快速核查信源复杂的报道,理清事件脉络。 - 教育领域:
可以开发成教学工具,帮助学生可视化地理解逻辑谬误、识别谣言结构,提升媒介素养。 -
范式创新:这项研究最重要的启示在于,它为利用“未经验证的众包智慧”进行事实核查开辟了新路。它不再试图从嘈杂的网络信息中寻找唯一的“黄金答案”,而是转向比较和评估不同观点(智慧)的质量。这更接近人类在信息不完备情况下做决策的方式——我们常常通过比较不同来源的说法,看哪一方更合理、证据更扎实,来判断真伪。
06 结语
在信息爆炸且真伪难辨的时代,我们需要的不仅仅是一个能给出“是/否”答案的AI裁判,更需要一个能展示完整推理过程、帮助我们理解复杂世界的AI助手。
G-Defense 正是朝着这个方向迈出的坚实一步。它将大模型的生成能力、检索技术的信息获取能力与图结构的结构化思维相结合,像一位训练有素的侦探,不仅告诉我们结论,更向我们展示了“案情分析图”和“侦破报告”。
尽管在计算成本、对LLM提示工程的依赖等方面仍有优化空间,但G-Defense 所代表的“可解释、细粒度、基于未验证信息源”的假新闻检测新范式,无疑为未来构建更透明、更健壮、更及时的网络信息防火墙点亮了一盏明灯。
下一次再看到令人震惊的消息时,或许我们可以期待,AI能先我们一步,画出那张厘清真相的“思维导图”。
论文原文地址:https://arxiv.org/abs/2604.06666v1