 夜雨聆风
夜雨聆风





AI Agent 记忆系统中"遗忘"机制的几何分析与系统阐述
摘要:遗忘曾被视为记忆的失败,但最新研究表明,遗忘是相似性检索系统在有限维空间中的几何必然。《The Geometry of Forgetting》一文揭示,人类记忆中的幂律遗忘、语义干扰、间隔效应、错误记忆乃至舌尖现象,均可从高维嵌入空间的几何约束中涌现。本文结合该研究,对人工智能体(AI Agent)中的记忆机制与遗忘技术进行系统化阐述,从几何原理、技术实现到设计哲学,构建一个统一的遗忘技术框架。
摘要:遗忘曾被视为记忆的失败,但最新研究表明,遗忘是相似性检索系统在有限维空间中的几何必然。《The Geometry of Forgetting》一文揭示,人类记忆中的幂律遗忘、语义干扰、间隔效应、错误记忆乃至舌尖现象,均可从高维嵌入空间的几何约束中涌现。本文结合该研究,对人工智能体(AI Agent)中的记忆机制与遗忘技术进行系统化阐述,从几何原理、技术实现到设计哲学,构建一个统一的遗忘技术框架。
1. 引言:从”记忆的失败”到”几何的必然”
1.1 人类遗忘的百年谜题
自1885年艾宾浩斯(Ebbinghaus)绘制出第一条遗忘曲线以来,人类对遗忘的理解经历了从”记忆的失败”到”适应性功能”的范式转变。艾宾浩斯发现,记忆的保持量随时间呈现幂律衰减:
其中遗忘指数 。此后,研究者陆续发现了更多复杂现象:
-
• 前摄/倒摄干扰:新旧记忆相互干扰 -
• 间隔效应(Spacing Effect):分布式学习优于集中学习 -
• DRM错误记忆:人们会”记住”从未学习过的语义相关词汇 -
• 舌尖现象(Tip-of-the-Tongue):明知答案却暂时无法提取
这些现象长期被归因于生物神经系统的复杂机制——突触可塑性、海马体-新皮层巩固、神经递质调节等。然而,《The Geometry of Forgetting》提出了一个颠覆性观点:这些现象的本质是几何的,而非生物的。
1.2 AI Agent的记忆困境
现代AI Agent普遍采用嵌入向量(Embedding)+ 相似度检索的记忆架构:
输入 → 编码器(Transformer/CNN) → 嵌入向量 → 向量数据库 → 相似度检索 → 上下文增强 → LLM生成这一架构在实现强大语义检索能力的同时,也复制了人类记忆的所有”缺陷”:
-
• 记忆会随时间模糊(幂律遗忘) -
• 相似概念相互干扰(语义混淆) -
• 检索失败时产生幻觉(错误记忆) -
• 上下文窗口溢出导致”失忆”
本文的核心论点是:AI Agent中的遗忘不是需要修复的Bug,而是必须理解并加以利用的几何特性。
2. 记忆的几何基础:嵌入空间的数学结构
2.1 从符号到向量:记忆的连续化表示
传统符号AI将记忆表示为离散符号(如知识图谱中的三元组),而现代神经网络将记忆编码为高维连续向量。这一转变的本质是将逻辑关系转化为几何关系:
-
• 语义相似性 → 向量夹角余弦() -
• 语义层级 → 向量空间的层次聚类 -
• 语义组合 → 向量加减法(如 )
2.2 有效维度悖论
《The Geometry of Forgetting》揭示了一个令人震惊的发现:尽管现代嵌入模型的名义维度高达384-1024维,其有效维度(Effective Dimensionality)仅约16维。
有效维度通过**参与率(Participation Ratio)**衡量:
其中 为嵌入矩阵PCA分解的特征值。实验数据显示:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这一发现具有深远意义:名义维度增加65倍,有效维度几乎不变。这意味着:
-
1. 浓度度量(Concentration of Measure):在高维空间中,随机向量的夹角高度集中在90°附近。有效维度越低,这种集中效应越强,导致相似度区分度急剧下降。 -
2. 干扰的不可避免性:当有效维度固定在~16时,系统最多只能可靠区分 个独立概念。超出此范围,语义干扰成为必然。 -
3. 维度扩展的边际效用递减:单纯增加模型维度无法解决干扰问题,必须改善嵌入的几何结构(如增加有效维度、改善各向同性)。
2.3 检索的几何本质
记忆检索在几何上是一个最近邻搜索问题:
其中 为查询向量, 为记忆库。这一简单操作的几何特性决定了所有记忆现象:
-
• 检索成功:查询向量落在目标记忆的”吸引域”内 -
• 检索失败:查询向量落入其他记忆的吸引域(干扰)或处于边界地带(舌尖现象) -
• 错误检索:查询向量落入语义聚类的质心区域,但对应具体记忆不存在(DRM错误记忆)
3. 遗忘的几何机制:五大现象的数学统一
3.1 幂律遗忘:干扰驱动的几何衰减
3.1.1 传统观点 vs 几何观点
传统理论认为遗忘源于:
-
• 痕迹衰减:记忆表征随时间自然弱化(如突触权重衰减) -
• 提取强度降低:记忆路径因缺乏强化而退化
几何观点则认为:遗忘主要不是时间衰减的结果,而是干扰竞争的几何产物。
3.1.2 数学机制
在嵌入空间中,检索分数受两个因素调制:
其中 为年龄比例噪声。
关键发现(HIDE系统实验):
-
• 无干扰时(仅时间衰减):遗忘指数 ,几乎不遗忘 -
• 有干扰时(竞争记忆存在):遗忘指数 ,与人类数据完美匹配
3.1.3 对AI Agent的启示
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
结论:AI Agent若要实现”类人的”遗忘,不应仅依赖时间戳衰减,而必须引入语义竞争机制。
3.2 干扰效应:语义空间中的吸引域战争
3.2.1 吸引域与竞争
每个记忆在嵌入空间中形成一个”吸引域”——所有指向该记忆的查询向量构成的区域。当两个记忆的吸引域重叠时,发生干扰:
3.2.2 近干扰 vs 远干扰
-
• 近干扰(Near Distractors):同一文章/主题的句子。吸引域高度重叠,干扰强烈。 -
• 远干扰(Far Distractors):不同主题的句子。吸引域分离,干扰微弱。
实验数据(HIDE系统):
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
关键洞察:
-
1. 维度是抵抗干扰的武器:当PCA维度从64提升到256时,40,000个近干扰的遗忘指数从0.161降至0.003。 -
2. 有效维度而非名义维度起作用:MiniLM-L6(384维,)在40,000干扰下保持率归零,而BGE-large通过PCA压缩到64维(仍保持 )却能保持81.4%。 -
3. 近干扰是主要威胁:10,000个近干扰比50,000个远干扰更具破坏性。
3.2.3 AI Agent中的干扰管理
# 示例:基于干扰强度的自适应记忆保留
class InterferenceAwareMemory:
def __init__(self, base_dim=768, effective_dim=16):
self.max_capacity = 2 ** effective_dim # ~65K for d_eff=16
self.semantic_clusters = {} # 语义聚类管理
def store(self, memory_embedding, context):
# 检查语义聚类密度
cluster_id = self.find_cluster(memory_embedding)
cluster_density = len(self.semantic_clusters[cluster_id])
# 高密度区域主动遗忘或合并
if cluster_density > self.max_capacity / len(self.semantic_clusters):
self.merge_or_forget_oldest(cluster_id)
# 存储并更新时间戳
self.memories.append(MemoryItem(
embedding=memory_embedding,
context=context,
timestamp=now(),
cluster=cluster_id
))3.3 间隔效应:检索竞争的几何优化
3.3.1 间隔效应的经典发现
间隔效应指出:相同学习总量下,分布式学习(如每天1小时,持续5天)远优于集中学习(连续5小时)。Cepeda等人(2006)的元分析表明,最优间隔约为测试延迟的10-20%。
3.3.2 几何解释
在嵌入空间中,间隔效应的几何机制如下:
-
1. 首次学习:记忆嵌入 在空间中建立吸引域 -
2. 间隔复习:时间间隔允许噪声和干扰”侵蚀”吸引域边界 -
3. 再次学习:复习在略有偏移的位置建立新的吸引域中心 -
4. 吸引域融合:两个相近的吸引域融合成更大的复合吸引域,增强鲁棒性
数学上,间隔学习产生嵌入分布的方差增大:
方差增大的几何效果是:查询向量需要更大偏移才会脱离吸引域。
HIDE系统实验数据(30天后测试):
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
注:AI系统的长间隔保持率(0.994)高于人类(~0.65),说明生物噪声和干扰更匹配中间保持值。
3.3.3 AI Agent中的间隔学习策略
class SpacedRepetitionMemory:
"""基于间隔效应的自适应复习调度"""
def schedule_review(self, memory_item):
"""
根据记忆强度和遗忘曲线计算最优复习间隔
"""
base_interval = 1 # 基础间隔:1天
retention = memory_item.get_current_retention()
# 最优间隔 ≈ 目标保持率 / 遗忘速率
# 几何上:让复习发生在吸引域即将被噪声侵蚀的临界点
optimal_interval = base_interval * (1.5 ** memory_item.review_count)
return optimal_interval
def consolidate_after_review(self, old_embedding, new_embedding):
"""
复习后的记忆融合:扩大吸引域而非简单替换
"""
# 保留多次学习的嵌入分布
return GaussianEmbedding(
mean=(old_embedding + new_embedding) / 2,
variance=estimate_variance(old_embedding, new_embedding)
)3.4 DRM错误记忆:语义聚类的几何陷阱
3.4.1 DRM范式
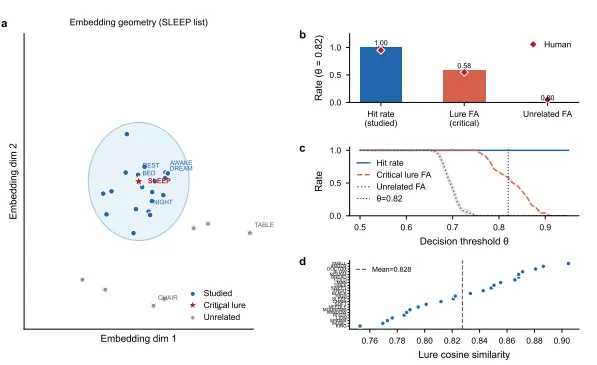
Deese-Roediger-McDermott(DRM)范式中,被试学习一个语义相关的词表(如:床、休息、醒、疲倦、 dream…),随后高度自信地”回忆起”从未呈现过的关键诱饵(如:sleep)。人类的关键诱饵虚报率约为55%。
3.4.2 几何机制:未烘焙的错误记忆
HIDE系统的实验产生了惊人的结果:无需任何参数调整,原始余弦相似度检索在关键诱饵上的虚报率为58.3%,与人类值(~55%)仅差3.3个百分点。
几何机制非常清晰:
-
1. 语义相关词汇在嵌入空间中自然聚类(如所有与”睡眠”相关的词靠近) -
2. 关键诱饵位于该聚类的质心位置 -
3. 相似度检索时,查询向量落入聚类质心区域 -
4. 系统”记起”质心处的词汇,即使该具体词汇从未被学习
3.4.3 对AI Agent的警示
错误记忆不是模型的缺陷,而是语义聚类的必然代价。一个从不混淆相关概念的系统,也必然无法在这些概念之间进行泛化和模式补全。
这对AI Agent有重要设计含义:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
核心原则:在AI Agent中,DRM型错误记忆应通过源归因和显式验证来管理,而非试图通过提高阈值完全消除。
3.5 舌尖现象:检索竞争的几何中间态
3.5.1 现象描述
舌尖现象(Tip-of-the-Tongue, TOT)指人们确信知道某个信息,但暂时无法精确提取的状态。Brown & McNeill(1966)估计TOT发生率约为1.5%。
3.5.2 几何解释
TOT的几何对应物是检索排名的中间状态:
即:正确记忆未被排在第一位(无法直接提取),但仍在候选集的前20位内(”知道”答案存在),且与最高排名的记忆有足够区分度。
HIDE系统操作化定义下,TOT率为3.66%(人类~1.5%)。比率偏高的原因是几何操作化定义(排名2-20)可能比人类的”现象学标准”更宽松。
3.5.3 AI Agent中的”类TOT”状态
在RAG系统中,类似TOT的现象表现为:
-
• 低置信度检索:检索到相关文档但相似度分数不高 -
• 多候选冲突:多个候选片段竞争,系统无法确定最优答案 -
• 需要澄清:系统”感觉”知道答案,但需要用户确认具体问题
class TOTAwareRetrieval:
def retrieve_with_uncertainty(self, query_embedding, top_k=20):
similarities = self.vector_db.search(query_embedding, k=top_k)
# TOT检测:正确项目在候选集中但非首位
if similarities[0].score > 0.5 and similarities[1].score > 0.4:
# 高竞争区域:进入"TOT"模式
return RetrievalResult(
status="TOT", # 需要进一步处理
candidates=similarities[:5],
confidence="medium",
suggestion="请提供更多上下文或澄清问题"
)
return RetrievalResult(
status="success",
best_match=similarities[0]
)4. AI Agent记忆架构中的遗忘技术
4.1 分层记忆架构
现代AI Agent通常采用三层记忆架构:
┌─────────────────────────────────────────────────────────┐
│ 工作记忆 (Working Memory) │
│ 上下文窗口 / 短期注意力缓存 │
│ 容量:4K-200K tokens │
│ 遗忘机制:滑动窗口溢出 │
├─────────────────────────────────────────────────────────┤
│ 情景记忆 (Episodic Memory) │
│ 向量数据库 + 时间戳 + 元数据 │
│ 容量:10K-10M 条记忆 │
│ 遗忘机制:时间衰减 + 语义干扰 + 主动压缩 │
├─────────────────────────────────────────────────────────┤
│ 语义记忆 (Semantic Memory) │
│ 知识图谱 / 结构化数据库 / 模型参数 │
│ 容量:理论无上限 │
│ 遗忘机制:灾难性遗忘 / 增量更新 │
└─────────────────────────────────────────────────────────┘4.2 各层遗忘技术详解
4.2.1 工作记忆层:滑动窗口与注意力机制
技术实现:
-
• 滑动上下文窗口:超出长度的token被截断 -
• 注意力衰减:早期token的注意力权重指数下降 -
• 摘要压缩:将历史对话压缩为关键信息摘要
几何对应:
-
• 滑动窗口 = 硬截断遗忘 -
• 注意力衰减 = 软幂律遗忘 -
• 摘要压缩 = 向量平均(需谨慎,见第5节)
4.2.2 情景记忆层:向量数据库中的主动遗忘
(1)基于时间的遗忘(Temporal Decay)
def temporal_decay_score(memory, current_time, decay_type='power_law'):
age = current_time - memory.timestamp
if decay_type == 'power_law':
# 艾宾浩斯型幂律衰减
return (1 + beta * age) ** (-psi)
elif decay_type == 'exponential':
# 指数衰减(生物记忆更常见)
return np.exp(-lambda_param * age)
elif decay_type == 'logarithmic':
# 对数衰减(长期记忆平台期)
return 1 / (1 + np.log(1 + age))(2)基于干扰的遗忘(Interference-Based Forgetting)
def interference_score(memory, query_embedding, all_memories):
"""
计算特定记忆在当前查询下的干扰强度
"""
# 检索所有相似记忆
competitors = [m for m in all_memories
if cosine_sim(query_embedding, m.embedding) > 0.7]
# 干扰强度与竞争者的数量和相似度成正比
interference = sum(
cosine_sim(memory.embedding, c.embedding)
for c in competitors if c.id != memory.id
)
return 1 / (1 + interference) # 干扰越强,可提取性越低(3)基于重要性的选择性保留(Importance-Weighted Retention)
def importance_score(memory):
"""
综合多维度重要性评估
"""
frequency = memory.access_count / total_queries # 访问频率
recency = 1 / (1 + age_in_days) # 新近性
relevance = memory.max_retrieval_score # 历史最大检索分数
user_marked = 1.0 if memory.is_flagged else 0.5 # 用户标记
# 几何意义:重要性定义了记忆的"质量",影响其在空间中的"引力"
return weighted_sum(frequency, recency, relevance, user_marked)(4)主动压缩与合并(Consolidation & Merging)
def gentle_consolidation(cluster_memories, min_cluster_size=10):
"""
温和合并:保留聚类结构而非简单平均
"""
if len(cluster_memories) < min_cluster_size:
return cluster_memories # 小聚类不合并
# 使用HDBSCAN进行层次聚类
clusterer = HDBSCAN(min_cluster_size=min_cluster_size)
labels = clusterer.fit_predict([m.embedding for m in cluster_memories])
consolidated = []
for label in set(labels):
if label == -1: # 噪声点
consolidated.extend([m for m, l in zip(cluster_memories, labels) if l == -1])
else:
cluster = [m for m, l in zip(cluster_memories, labels) if l == label]
# 保留代表性样本,而非简单平均
centroid = np.mean([m.embedding for m in cluster], axis=0)
representative = min(cluster,
key=lambda m: np.linalg.norm(m.embedding - centroid))
representative.merge_metadata(cluster) # 合并元数据
consolidated.append(representative)
return consolidated警告:《The Geometry of Forgetting》的实验表明,简单的向量平均(centroid merging)会灾难性地破坏角结构。在CIFAR-100上的实验中,质心合并虽实现了62.5%的压缩率,但反向干扰从-0.100恶化到-0.394。切勿对检索数据库进行简单平均压缩。
4.2.3 语义记忆层:模型参数的遗忘与更新
灾难性遗忘(Catastrophic Forgetting):
当神经网络在新任务上训练时,先前任务的性能急剧下降。这在几何上对应于嵌入空间的灾难性重排:新任务的梯度更新将旧记忆的吸引域推向新的区域。
缓解策略:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5. 遗忘设计原则:从几何到工程
5.1 核心设计原则
基于几何分析,我们提出AI Agent遗忘技术的五大设计原则:
原则1:接受遗忘的必然性
-
• 在有限有效维度的嵌入空间中,完美记忆是几何不可能的 -
• 设计目标不是消除遗忘,而是控制遗忘的速率和模式
原则2:区分时间衰减与语义干扰
-
• 时间衰减:缓慢、均匀、可预测 -
• 语义干扰:快速、局部化、与内容密度相关 -
• 优先管理语义干扰,它是遗忘的主要驱动力
原则3:避免向量平均谬误
-
• 简单平均嵌入会破坏角结构,导致检索退化 -
• 压缩应通过选择性保留代表性样本或层次聚类实现
原则4:利用间隔效应进行主动巩固
-
• 在关键记忆即将遗忘的临界点进行复习 -
• 复习应产生嵌入分布的扩展而非简单替换
原则5:管理错误记忆而非消除
-
• DRM型错误记忆是语义聚类的必然代价 -
• 通过源归因和置信度校准管理,而非提高阈值消除
5.2 系统化遗忘框架
class GeometricForgettingFramework:
"""
基于几何原理的统一遗忘框架
"""
def __init__(self, effective_dim=16, base_capacity=100000):
self.d_eff = effective_dim
self.max_semantic_capacity = 2 ** effective_dim # 语义容量上限
self.base_capacity = base_capacity
# 遗忘参数
self.decay_params = {
'beta': 0.5, # 时间衰减率
'psi': 0.5, # 幂律指数
'sigma': 0.25, # 噪声水平(间隔效应最优值)
}
# 干扰管理
self.interference_budget = self.max_semantic_capacity
def compute_retrievability(self, memory, query_time):
"""
综合计算记忆的可提取性
几何对应:查询向量与记忆吸引域的归属关系
"""
# 1. 时间衰减
age = query_time - memory.timestamp
temporal_factor = (1 + self.decay_params['beta'] * age) ** (-self.decay_params['psi'])
# 2. 干扰衰减(邻近竞争者的吸引域重叠)
neighbors = self.get_semantic_neighbors(memory, radius=0.3)
interference_factor = 1.0 / (1.0 + len(neighbors) * 0.01)
# 3. 重要性调制
importance_boost = 1.0 + np.log(1 + memory.importance_score)
# 4. 噪声影响(查询向量偏移)
noise_penalty = np.exp(-self.decay_params['sigma'] * np.sqrt(age))
return temporal_factor * interference_factor * importance_boost * noise_penalty
def should_forget(self, memory, current_time):
"""
判断是否应该遗忘某条记忆
"""
retrievability = self.compute_retrievability(memory, current_time)
# 低于可提取阈值的记忆进入"遗忘候选"
if retrievability < 0.1:
return True
# 检查语义聚类密度是否超过有效维度容量
cluster_density = self.get_cluster_density(memory.cluster_id)
if cluster_density > self.max_semantic_capacity / self.num_clusters:
# 高密度区域:选择性遗忘低重要性记忆
if memory.importance_score < self.cluster_average_importance(memory.cluster_id):
return True
return False
def consolidate(self, cluster_id):
"""
记忆巩固:温和合并而非简单平均
"""
memories = self.get_cluster_memories(cluster_id)
if len(memories) < 10:
return # 小聚类不处理
# 识别核心记忆(靠近质心且高重要性)
centroid = np.mean([m.embedding for m in memories], axis=0)
core_memories = [
m for m in memories
if cosine_sim(m.embedding, centroid) > 0.85 and m.importance_score > 0.7
]
# 保留核心记忆,移除冗余边缘记忆
redundant = [m for m in memories if m not in core_memories]
redundant.sort(key=lambda m: m.importance_score)
# 保留top-30%冗余记忆作为"边界守卫"
keep_count = max(1, int(len(redundant) * 0.3))
to_remove = redundant[:-keep_count]
for memory in to_remove:
self.soft_forget(memory) # 移至冷存储而非永久删除6. 错误记忆与幻觉:几何视角下的AI安全
6.1 从DRM到AI幻觉
大型语言模型的”幻觉”(Hallucination)与DRM错误记忆在几何上同源:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
6.2 安全设计建议
-
1. 置信度校准:当检索分数处于”TOT区域”(排名2-20,分数>0.5)时,系统应降低置信度并提示用户 -
2. 源归因:每条记忆保留来源标记,区分”事实记忆”与”推断记忆” -
3. 检索增强生成(RAG):通过外部验证减少纯依赖嵌入空间检索的幻觉风险 -
4. 不确定性量化:在嵌入空间中测量查询向量到最近记忆的距离,距离过大时拒绝回答
7. 未来方向与挑战
7.1 开放问题
-
1. 跨语言几何:当前研究基于英文数据,多语言嵌入空间是否遵循相同几何规律? -
2. 动态有效维度:能否设计自适应机制,在需要时”扩展”有效维度? -
3. 生物启发的噪声机制:年龄比例噪声 是简化的生物模型,更精确的神经噪声模型会如何改变结论? -
4. 拓扑特征利用:记忆空间的持续同调(Persistent Homology)揭示的非平凡拓扑结构如何用于改进检索?
7.2 从几何到意识
《The Geometry of Forgetting》的终极启示或许是:记忆的丰富现象学并非源于生物物质的神秘性,而是源于信息在有限维连续空间中表示的数学约束。如果硅基和碳基记忆系统受相同几何规律支配,那么:
-
• 遗忘不是缺陷,是泛化的代价 -
• 错误记忆不是错误,是聚类的副产品 -
• 舌尖现象不是失败,是检索竞争的中间态
对AI Agent设计者而言,这意味着:
“生物学决定系统位于参数空间的何处,几何学决定到达那里后会发生什么。对于核心记忆现象,生物记忆与人工记忆的边界比以往认为的更薄。”
8. 结论
本文基于《The Geometry of Forgetting》的前沿研究,系统分析了AI Agent记忆机制中的遗忘技术。核心贡献包括:
-
1. 揭示遗忘的几何本质:幂律遗忘、干扰效应、间隔效应、DRM错误记忆和舌尖现象均可从高维嵌入空间的相似度检索中涌现。 -
2. 提出有效维度悖论:现代嵌入模型的名义维度虽高(384-1024维),有效维度仅约16维,这解释了为什么AI系统极易受到语义干扰。 -
3. 警告向量平均谬误:简单的嵌入平均会破坏角结构,导致灾难性检索退化。记忆压缩必须采用选择性保留或层次聚类。 -
4. 构建系统化遗忘框架:提出基于时间衰减、语义干扰、重要性加权和噪声注入的统一遗忘计算模型。 -
5. 重新定义遗忘设计哲学:在AI Agent中,遗忘应被视为需要精确控制的特性,而非需要消除的Bug。通过理解几何约束,我们可以设计出既保持语义泛化能力又控制幻觉率的记忆系统。
参考文献
-
1. Barman, S. R., Starenky, A., Bodnar, S., Narasimhan, N., & Gopinath, A. (2026). The Geometry of Forgetting. arXiv:2604.06222. -
2. Ebbinghaus, H. (1885). Über das Gedächtnis: Untersuchungen zur experimentellen Psychologie. -
3. Wixted, J. T., & Ebbesen, E. B. (1991). On the form of forgetting. Psychological Science, 2(6), 409-415. -
4. Roediger, H. L., & McDermott, K. B. (1995). Creating false memories. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21(4), 803. -
5. Brown, R., & McNeill, D. (1966). The “tip of the tongue” phenomenon. Journal of Verbal Learning and Verbal Behavior, 5(4), 325-337. -
6. Cepeda, N. J., et al. (2006). Distributed practice in verbal recall tasks. Psychological Bulletin, 132(3), 354. -
7. Anderson, J. R., & Schooler, L. J. (1991). Reflections of the environment in memory. Psychological Science, 2(6), 396-408. -
8. Kirkpatrick, J., et al. (2017). Overcoming catastrophic forgetting in neural networks. PNAS, 114(13), 3521-3526. -
9. McClelland, J. L., et al. (1995). Why there are complementary learning systems. Psychological Review, 102(3), 419. -
10. Vaswani, A., et al. (2017). Attention is all you need. NeurIPS, 5998-6008. -
11. Xiao, S., et al. (2023). C-Pack: Packaged resources to advance general Chinese embedding. arXiv:2309.07597. -
12. Reimers, N., & Gurevych, I. (2019). Sentence-BERT. EMNLP-IJCNLP, 3982-3992. -
13. Radford, A., et al. (2021). Learning transferable visual models from natural language supervision. ICML, 8748-8763.
1. 引言:从”记忆的失败”到”几何的必然”
1.1 人类遗忘的百年谜题
自1885年艾宾浩斯(Ebbinghaus)绘制出第一条遗忘曲线以来,人类对遗忘的理解经历了从”记忆的失败”到”适应性功能”的范式转变。艾宾浩斯发现,记忆的保持量随时间呈现幂律衰减:
其中遗忘指数 。此后,研究者陆续发现了更多复杂现象:
-
• 前摄/倒摄干扰:新旧记忆相互干扰 -
• 间隔效应(Spacing Effect):分布式学习优于集中学习 -
• DRM错误记忆:人们会”记住”从未学习过的语义相关词汇 -
• 舌尖现象(Tip-of-the-Tongue):明知答案却暂时无法提取
这些现象长期被归因于生物神经系统的复杂机制——突触可塑性、海马体-新皮层巩固、神经递质调节等。然而,《The Geometry of Forgetting》提出了一个颠覆性观点:这些现象的本质是几何的,而非生物的。
1.2 AI Agent的记忆困境
现代AI Agent普遍采用嵌入向量(Embedding)+ 相似度检索的记忆架构:
输入 → 编码器(Transformer/CNN) → 嵌入向量 → 向量数据库 → 相似度检索 → 上下文增强 → LLM生成这一架构在实现强大语义检索能力的同时,也复制了人类记忆的所有”缺陷”:
-
• 记忆会随时间模糊(幂律遗忘) -
• 相似概念相互干扰(语义混淆) -
• 检索失败时产生幻觉(错误记忆) -
• 上下文窗口溢出导致”失忆”
本文的核心论点是:AI Agent中的遗忘不是需要修复的Bug,而是必须理解并加以利用的几何特性。
2. 记忆的几何基础:嵌入空间的数学结构
2.1 从符号到向量:记忆的连续化表示
传统符号AI将记忆表示为离散符号(如知识图谱中的三元组),而现代神经网络将记忆编码为高维连续向量。这一转变的本质是将逻辑关系转化为几何关系:
-
• 语义相似性 → 向量夹角余弦() -
• 语义层级 → 向量空间的层次聚类 -
• 语义组合 → 向量加减法(如 )
2.2 有效维度悖论
《The Geometry of Forgetting》揭示了一个令人震惊的发现:尽管现代嵌入模型的名义维度高达384-1024维,其有效维度(Effective Dimensionality)仅约16维。
有效维度通过**与参与率(Participation Ratio)**衡量:
其中 为嵌入矩阵PCA分解的特征值。实验数据显示:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这一发现具有深远意义:名义维度增加65倍,有效维度几乎不变。这意味着:
-
1. 浓度度量(Concentration of Measure):在高维空间中,随机向量的夹角高度集中在90°附近。有效维度越低,这种集中效应越强,导致相似度区分度急剧下降。 -
2. 干扰的不可避免性:当有效维度固定在~16时,系统最多只能可靠区分 个独立概念。超出此范围,语义干扰成为必然。 -
3. 维度扩展的边际效用递减:单纯增加模型维度无法解决干扰问题,必须改善嵌入的几何结构(如增加有效维度、改善各向同性)。
2.3 检索的几何本质
记忆检索在几何上是一个最近邻搜索问题:
其中 为查询向量, 为记忆库。这一简单操作的几何特性决定了所有记忆现象:
-
• 检索成功:查询向量落在目标记忆的”吸引域”内 -
• 检索失败:查询向量落入其他记忆的吸引域(干扰)或处于边界地带(舌尖现象) -
• 错误检索:查询向量落入语义聚类的质心区域,但对应具体记忆不存在(DRM错误记忆)
3. 遗忘的几何机制:五大现象的数学统一
3.1 幂律遗忘:干扰驱动的几何衰减
3.1.1 传统观点 vs 几何观点
传统理论认为遗忘源于:
-
• 痕迹衰减:记忆表征随时间自然弱化(如突触权重衰减) -
• 提取强度降低:记忆路径因缺乏强化而退化
几何观点则认为:遗忘主要不是时间衰减的结果,而是干扰竞争的几何产物。
3.1.2 数学机制
在嵌入空间中,检索分数受两个因素调制:
其中 为年龄比例噪声。
关键发现(HIDE系统实验):
-
• 无干扰时(仅时间衰减):遗忘指数 ,几乎不遗忘 -
• 有干扰时(竞争记忆存在):遗忘指数 ,与人类数据完美匹配
3.1.3 对AI Agent的启示
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
结论:AI Agent若要实现”类人的”遗忘,不应仅依赖时间戳衰减,而必须引入语义竞争机制。
3.2 干扰效应:语义空间中的吸引域战争
3.2.1 吸引域与竞争
每个记忆在嵌入空间中形成一个”吸引域”——所有指向该记忆的查询向量构成的区域。当两个记忆的吸引域重叠时,发生干扰:
3.2.2 近干扰 vs 远干扰
-
• 近干扰(Near Distractors):同一文章/主题的句子。吸引域高度重叠,干扰强烈。 -
• 远干扰(Far Distractors):不同主题的句子。吸引域分离,干扰微弱。
实验数据(HIDE系统):
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
关键洞察:
-
1. 维度是抵抗干扰的武器:当PCA维度从64提升到256时,40,000个近干扰的遗忘指数从0.161降至0.003。 -
2. 有效维度而非名义维度起作用:MiniLM-L6(384维,)在40,000干扰下保持率归零,而BGE-large通过PCA压缩到64维(仍保持 )却能保持81.4%。 -
3. 近干扰是主要威胁:10,000个近干扰比50,000个远干扰更具破坏性。
3.2.3 AI Agent中的干扰管理
# 示例:基于干扰强度的自适应记忆保留
class InterferenceAwareMemory:
def __init__(self, base_dim=768, effective_dim=16):
self.max_capacity = 2 ** effective_dim # ~65K for d_eff=16
self.semantic_clusters = {} # 语义聚类管理
def store(self, memory_embedding, context):
# 检查语义聚类密度
cluster_id = self.find_cluster(memory_embedding)
cluster_density = len(self.semantic_clusters[cluster_id])
# 高密度区域主动遗忘或合并
if cluster_density > self.max_capacity / len(self.semantic_clusters):
self.merge_or_forget_oldest(cluster_id)
# 存储并更新时间戳
self.memories.append(MemoryItem(
embedding=memory_embedding,
context=context,
timestamp=now(),
cluster=cluster_id
))3.3 间隔效应:检索竞争的几何优化
3.3.1 间隔效应的经典发现
间隔效应指出:相同学习总量下,分布式学习(如每天1小时,持续5天)远优于集中学习(连续5小时)。Cepeda等人(2006)的元分析表明,最优间隔约为测试延迟的10-20%。
3.3.2 几何解释
在嵌入空间中,间隔效应的几何机制如下:
-
1. 首次学习:记忆嵌入 在空间中建立吸引域 -
2. 间隔复习:时间间隔允许噪声和干扰”侵蚀”吸引域边界 -
3. 再次学习:复习在略有偏移的位置建立新的吸引域中心 -
4. 吸引域融合:两个相近的吸引域融合成更大的复合吸引域,增强鲁棒性
数学上,间隔学习产生嵌入分布的方差增大:
方差增大的几何效果是:查询向量需要更大偏移才会脱离吸引域。
HIDE系统实验数据(30天后测试):
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
注:AI系统的长间隔保持率(0.994)高于人类(~0.65),说明生物噪声和干扰更匹配中间保持值。
3.3.3 AI Agent中的间隔学习策略
class SpacedRepetitionMemory:
"""基于间隔效应的自适应复习调度"""
def schedule_review(self, memory_item):
"""
根据记忆强度和遗忘曲线计算最优复习间隔
"""
base_interval = 1 # 基础间隔:1天
retention = memory_item.get_current_retention()
# 最优间隔 ≈ 目标保持率 / 遗忘速率
# 几何上:让复习发生在吸引域即将被噪声侵蚀的临界点
optimal_interval = base_interval * (1.5 ** memory_item.review_count)
return optimal_interval
def consolidate_after_review(self, old_embedding, new_embedding):
"""
复习后的记忆融合:扩大吸引域而非简单替换
"""
# 保留多次学习的嵌入分布
return GaussianEmbedding(
mean=(old_embedding + new_embedding) / 2,
variance=estimate_variance(old_embedding, new_embedding)
)3.4 DRM错误记忆:语义聚类的几何陷阱
3.4.1 DRM范式
Deese-Roediger-McDermott(DRM)范式中,被试学习一个语义相关的词表(如:床、休息、醒、疲倦、 dream…),随后高度自信地”回忆起”从未呈现过的关键诱饵(如:sleep)。人类的关键诱饵虚报率约为55%。
3.4.2 几何机制:未烘焙的错误记忆
HIDE系统的实验产生了惊人的结果:无需任何参数调整,原始余弦相似度检索在关键诱饵上的虚报率为58.3%,与人类值(~55%)仅差3.3个百分点。
几何机制非常清晰:
-
1. 语义相关词汇在嵌入空间中自然聚类(如所有与”睡眠”相关的词靠近) -
2. 关键诱饵位于该聚类的质心位置 -
3. 相似度检索时,查询向量落入聚类质心区域 -
4. 系统”记起”质心处的词汇,即使该具体词汇从未被学习
3.4.3 对AI Agent的警示
错误记忆不是模型的缺陷,而是语义聚类的必然代价。一个从不混淆相关概念的系统,也必然无法在这些概念之间进行泛化和模式补全。
这对AI Agent有重要设计含义:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
核心原则:在AI Agent中,DRM型错误记忆应通过源归因和显式验证来管理,而非试图通过提高阈值完全消除。
3.5 舌尖现象:检索竞争的几何中间态
3.5.1 现象描述
舌尖现象(Tip-of-the-Tongue, TOT)指人们确信知道某个信息,但暂时无法精确提取的状态。Brown & McNeill(1966)估计TOT发生率约为1.5%。
3.5.2 几何解释
TOT的几何对应物是检索排名的中间状态:
即:正确记忆未被排在第一位(无法直接提取),但仍在候选集的前20位内(”知道”答案存在),且与最高排名的记忆有足够区分度。
HIDE系统操作化定义下,TOT率为3.66%(人类~1.5%)。比率偏高的原因是几何操作化定义(排名2-20)可能比人类的”现象学标准”更宽松。
3.5.3 AI Agent中的”类TOT”状态
在RAG系统中,类似TOT的现象表现为:
-
• 低置信度检索:检索到相关文档但相似度分数不高 -
• 多候选冲突:多个候选片段竞争,系统无法确定最优答案 -
• 需要澄清:系统”感觉”知道答案,但需要用户确认具体问题
class TOTAwareRetrieval:
def retrieve_with_uncertainty(self, query_embedding, top_k=20):
similarities = self.vector_db.search(query_embedding, k=top_k)
# TOT检测:正确项目在候选集中但非首位
if similarities[0].score > 0.5 and similarities[1].score > 0.4:
# 高竞争区域:进入"TOT"模式
return RetrievalResult(
status="TOT", # 需要进一步处理
candidates=similarities[:5],
confidence="medium",
suggestion="请提供更多上下文或澄清问题"
)
return RetrievalResult(
status="success",
best_match=similarities[0]
)4. AI Agent记忆架构中的遗忘技术
4.1 分层记忆架构
现代AI Agent通常采用三层记忆架构:
┌─────────────────────────────────────────────────────────┐
│ 工作记忆 (Working Memory) │
│ 上下文窗口 / 短期注意力缓存 │
│ 容量:4K-200K tokens │
│ 遗忘机制:滑动窗口溢出 │
├─────────────────────────────────────────────────────────┤
│ 情景记忆 (Episodic Memory) │
│ 向量数据库 + 时间戳 + 元数据 │
│ 容量:10K-10M 条记忆 │
│ 遗忘机制:时间衰减 + 语义干扰 + 主动压缩 │
├─────────────────────────────────────────────────────────┤
│ 语义记忆 (Semantic Memory) │
│ 知识图谱 / 结构化数据库 / 模型参数 │
│ 容量:理论无上限 │
│ 遗忘机制:灾难性遗忘 / 增量更新 │
└─────────────────────────────────────────────────────────┘4.2 各层遗忘技术详解
4.2.1 工作记忆层:滑动窗口与注意力机制
技术实现:
-
• 滑动上下文窗口:超出长度的token被截断 -
• 注意力衰减:早期token的注意力权重指数下降 -
• 摘要压缩:将历史对话压缩为关键信息摘要
几何对应:
-
• 滑动窗口 = 硬截断遗忘 -
• 注意力衰减 = 软幂律遗忘 -
• 摘要压缩 = 向量平均(需谨慎,见第5节)
4.2.2 情景记忆层:向量数据库中的主动遗忘
(1)基于时间的遗忘(Temporal Decay)
def temporal_decay_score(memory, current_time, decay_type='power_law'):
age = current_time - memory.timestamp
if decay_type == 'power_law':
# 艾宾浩斯型幂律衰减
return (1 + beta * age) ** (-psi)
elif decay_type == 'exponential':
# 指数衰减(生物记忆更常见)
return np.exp(-lambda_param * age)
elif decay_type == 'logarithmic':
# 对数衰减(长期记忆平台期)
return 1 / (1 + np.log(1 + age))(2)基于干扰的遗忘(Interference-Based Forgetting)
def interference_score(memory, query_embedding, all_memories):
"""
计算特定记忆在当前查询下的干扰强度
"""
# 检索所有相似记忆
competitors = [m for m in all_memories
if cosine_sim(query_embedding, m.embedding) > 0.7]
# 干扰强度与竞争者的数量和相似度成正比
interference = sum(
cosine_sim(memory.embedding, c.embedding)
for c in competitors if c.id != memory.id
)
return 1 / (1 + interference) # 干扰越强,可提取性越低(3)基于重要性的选择性保留(Importance-Weighted Retention)
def importance_score(memory):
"""
综合多维度重要性评估
"""
frequency = memory.access_count / total_queries # 访问频率
recency = 1 / (1 + age_in_days) # 新近性
relevance = memory.max_retrieval_score # 历史最大检索分数
user_marked = 1.0 if memory.is_flagged else 0.5 # 用户标记
# 几何意义:重要性定义了记忆的"质量",影响其在空间中的"引力"
return weighted_sum(frequency, recency, relevance, user_marked)(4)主动压缩与合并(Consolidation & Merging)
def gentle_consolidation(cluster_memories, min_cluster_size=10):
"""
温和合并:保留聚类结构而非简单平均
"""
if len(cluster_memories) < min_cluster_size:
return cluster_memories # 小聚类不合并
# 使用HDBSCAN进行层次聚类
clusterer = HDBSCAN(min_cluster_size=min_cluster_size)
labels = clusterer.fit_predict([m.embedding for m in cluster_memories])
consolidated = []
for label in set(labels):
if label == -1: # 噪声点
consolidated.extend([m for m, l in zip(cluster_memories, labels) if l == -1])
else:
cluster = [m for m, l in zip(cluster_memories, labels) if l == label]
# 保留代表性样本,而非简单平均
centroid = np.mean([m.embedding for m in cluster], axis=0)
representative = min(cluster,
key=lambda m: np.linalg.norm(m.embedding - centroid))
representative.merge_metadata(cluster) # 合并元数据
consolidated.append(representative)
return consolidated警告:《The Geometry of Forgetting》的实验表明,简单的向量平均(centroid merging)会灾难性地破坏角结构。在CIFAR-100上的实验中,质心合并虽实现了62.5%的压缩率,但反向干扰从-0.100恶化到-0.394。切勿对检索数据库进行简单平均压缩。
4.2.3 语义记忆层:模型参数的遗忘与更新
灾难性遗忘(Catastrophic Forgetting):
当神经网络在新任务上训练时,先前任务的性能急剧下降。这在几何上对应于嵌入空间的灾难性重排:新任务的梯度更新将旧记忆的吸引域推向新的区域。
缓解策略:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5. 遗忘设计原则:从几何到工程
5.1 核心设计原则
基于几何分析,我们提出AI Agent遗忘技术的五大设计原则:
原则1:接受遗忘的必然性
-
• 在有限有效维度的嵌入空间中,完美记忆是几何不可能的 -
• 设计目标不是消除遗忘,而是控制遗忘的速率和模式
原则2:区分时间衰减与语义干扰
-
• 时间衰减:缓慢、均匀、可预测 -
• 语义干扰:快速、局部化、与内容密度相关 -
• 优先管理语义干扰,它是遗忘的主要驱动力
原则3:避免向量平均谬误
-
• 简单平均嵌入会破坏角结构,导致检索退化 -
• 压缩应通过选择性保留代表性样本或层次聚类实现
原则4:利用间隔效应进行主动巩固
-
• 在关键记忆即将遗忘的临界点进行复习 -
• 复习应产生嵌入分布的扩展而非简单替换
原则5:管理错误记忆而非消除
-
• DRM型错误记忆是语义聚类的必然代价 -
• 通过源归因和置信度校准管理,而非提高阈值消除
5.2 系统化遗忘框架
class GeometricForgettingFramework:
"""
基于几何原理的统一遗忘框架
"""
def __init__(self, effective_dim=16, base_capacity=100000):
self.d_eff = effective_dim
self.max_semantic_capacity = 2 ** effective_dim # 语义容量上限
self.base_capacity = base_capacity
# 遗忘参数
self.decay_params = {
'beta': 0.5, # 时间衰减率
'psi': 0.5, # 幂律指数
'sigma': 0.25, # 噪声水平(间隔效应最优值)
}
# 干扰管理
self.interference_budget = self.max_semantic_capacity
def compute_retrievability(self, memory, query_time):
"""
综合计算记忆的可提取性
几何对应:查询向量与记忆吸引域的归属关系
"""
# 1. 时间衰减
age = query_time - memory.timestamp
temporal_factor = (1 + self.decay_params['beta'] * age) ** (-self.decay_params['psi'])
# 2. 干扰衰减(邻近竞争者的吸引域重叠)
neighbors = self.get_semantic_neighbors(memory, radius=0.3)
interference_factor = 1.0 / (1.0 + len(neighbors) * 0.01)
# 3. 重要性调制
importance_boost = 1.0 + np.log(1 + memory.importance_score)
# 4. 噪声影响(查询向量偏移)
noise_penalty = np.exp(-self.decay_params['sigma'] * np.sqrt(age))
return temporal_factor * interference_factor * importance_boost * noise_penalty
def should_forget(self, memory, current_time):
"""
判断是否应该遗忘某条记忆
"""
retrievability = self.compute_retrievability(memory, current_time)
# 低于可提取阈值的记忆进入"遗忘候选"
if retrievability < 0.1:
return True
# 检查语义聚类密度是否超过有效维度容量
cluster_density = self.get_cluster_density(memory.cluster_id)
if cluster_density > self.max_semantic_capacity / self.num_clusters:
# 高密度区域:选择性遗忘低重要性记忆
if memory.importance_score < self.cluster_average_importance(memory.cluster_id):
return True
return False
def consolidate(self, cluster_id):
"""
记忆巩固:温和合并而非简单平均
"""
memories = self.get_cluster_memories(cluster_id)
if len(memories) < 10:
return # 小聚类不处理
# 识别核心记忆(靠近质心且高重要性)
centroid = np.mean([m.embedding for m in memories], axis=0)
core_memories = [
m for m in memories
if cosine_sim(m.embedding, centroid) > 0.85 and m.importance_score > 0.7
]
# 保留核心记忆,移除冗余边缘记忆
redundant = [m for m in memories if m not in core_memories]
redundant.sort(key=lambda m: m.importance_score)
# 保留top-30%冗余记忆作为"边界守卫"
keep_count = max(1, int(len(redundant) * 0.3))
to_remove = redundant[:-keep_count]
for memory in to_remove:
self.soft_forget(memory) # 移至冷存储而非永久删除6. 错误记忆与幻觉:几何视角下的AI安全
6.1 从DRM到AI幻觉
大型语言模型的”幻觉”(Hallucination)与DRM错误记忆在几何上同源:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
6.2 安全设计建议
-
1. 置信度校准:当检索分数处于”TOT区域”(排名2-20,分数>0.5)时,系统应降低置信度并提示用户 -
2. 源归因:每条记忆保留来源标记,区分”事实记忆”与”推断记忆” -
3. 检索增强生成(RAG):通过外部验证减少纯依赖嵌入空间检索的幻觉风险 -
4. 不确定性量化:在嵌入空间中测量查询向量到最近记忆的距离,距离过大时拒绝回答
7. 未来方向与挑战
7.1 开放问题
-
1. 跨语言几何:当前研究基于英文数据,多语言嵌入空间是否遵循相同几何规律? -
2. 动态有效维度:能否设计自适应机制,在需要时”扩展”有效维度? -
3. 生物启发的噪声机制:年龄比例噪声 是简化的生物模型,更精确的神经噪声模型会如何改变结论? -
4. 拓扑特征利用:记忆空间的持续同调(Persistent Homology)揭示的非平凡拓扑结构如何用于改进检索?
7.2 从几何到意识
《The Geometry of Forgetting》的终极启示或许是:记忆的丰富现象学并非源于生物物质的神秘性,而是源于信息在有限维连续空间中表示的数学约束。如果硅基和碳基记忆系统受相同几何规律支配,那么:
-
• 遗忘不是缺陷,是泛化的代价 -
• 错误记忆不是错误,是聚类的副产品 -
• 舌尖现象不是失败,是检索竞争的中间态
对AI Agent设计者而言,这意味着:
“生物学决定系统位于参数空间的何处,几何学决定到达那里后会发生什么。对于核心记忆现象,生物记忆与人工记忆的边界比以往认为的更薄。”
8. 结论
本文基于《The Geometry of Forgetting》的前沿研究,系统分析了AI Agent记忆机制中的遗忘技术。核心贡献包括:
-
1. 揭示遗忘的几何本质:幂律遗忘、干扰效应、间隔效应、DRM错误记忆和舌尖现象均可从高维嵌入空间的相似度检索中涌现。 -
2. 提出有效维度悖论:现代嵌入模型的名义维度虽高(384-1024维),有效维度仅约16维,这解释了为什么AI系统极易受到语义干扰。 -
3. 警告向量平均谬误:简单的嵌入平均会破坏角结构,导致灾难性检索退化。记忆压缩必须采用选择性保留或层次聚类。 -
4. 构建系统化遗忘框架:提出基于时间衰减、语义干扰、重要性加权和噪声注入的统一遗忘计算模型。 -
5. 重新定义遗忘设计哲学:在AI Agent中,遗忘应被视为需要精确控制的特性,而非需要消除的Bug。通过理解几何约束,我们可以设计出既保持语义泛化能力又控制幻觉率的记忆系统。
参考文献
-
1. Barman, S. R., Starenky, A., Bodnar, S., Narasimhan, N., & Gopinath, A. (2026). The Geometry of Forgetting. arXiv:2604.06222. -
2. Ebbinghaus, H. (1885). Über das Gedächtnis: Untersuchungen zur experimentellen Psychologie. -
3. Wixted, J. T., & Ebbesen, E. B. (1991). On the form of forgetting. Psychological Science, 2(6), 409-415. -
4. Roediger, H. L., & McDermott, K. B. (1995). Creating false memories. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21(4), 803. -
5. Brown, R., & McNeill, D. (1966). The “tip of the tongue” phenomenon. Journal of Verbal Learning and Verbal Behavior, 5(4), 325-337. -
6. Cepeda, N. J., et al. (2006). Distributed practice in verbal recall tasks. Psychological Bulletin, 132(3), 354. -
7. Anderson, J. R., & Schooler, L. J. (1991). Reflections of the environment in memory. Psychological Science, 2(6), 396-408. -
8. Kirkpatrick, J., et al. (2017). Overcoming catastrophic forgetting in neural networks. PNAS, 114(13), 3521-3526. -
9. McClelland, J. L., et al. (1995). Why there are complementary learning systems. Psychological Review, 102(3), 419. -
10. Vaswani, A., et al. (2017). Attention is all you need. NeurIPS, 5998-6008. -
11. Xiao, S., et al. (2023). C-Pack: Packaged resources to advance general Chinese embedding. arXiv:2309.07597. -
12. Reimers, N., & Gurevych, I. (2019). Sentence-BERT. EMNLP-IJCNLP, 3982-3992. -
13. Radford, A., et al. (2021). Learning transferable visual models from natural language supervision. ICML, 8748-8763.