 夜雨聆风
夜雨聆风





Obsidian+OpenClaw组合技!花9分钟重构你的AI知识管理体系
三周前,我决定将知识管理体系迁移到Claude Code+Obsidian,这个过程远比想象中复杂。在此之前,我的常用搭配是:所有信息通过微信转发到滴答清单,兼容度拉满——能转链接的优先用链接,群聊等多文本难复制的内容就截图保存,每条信息都会标注用途,比如是选题储备还是深入学习素材。

但这套模式有个无解的短板:我只是把知识点从“信息海洋”转移到了“信息湖泊”,过几天还是要手动将这些内容收录到飞书,做文本去重、视频文案提取,若要做内容输出,还得额外做排期,重复工作量极大。
想要实现无痛迁移,我必须先解决两个核心问题:
一是如何让各类信息顺畅流入Obsidian;
二是如何给Obsidian里的信息搭建合理结构,让我和AI都能清晰看懂、高效调用。
这篇文章的超高速打开方式是全篇丢给OpenClaw,把需要安装和配置的半自动搞定😎
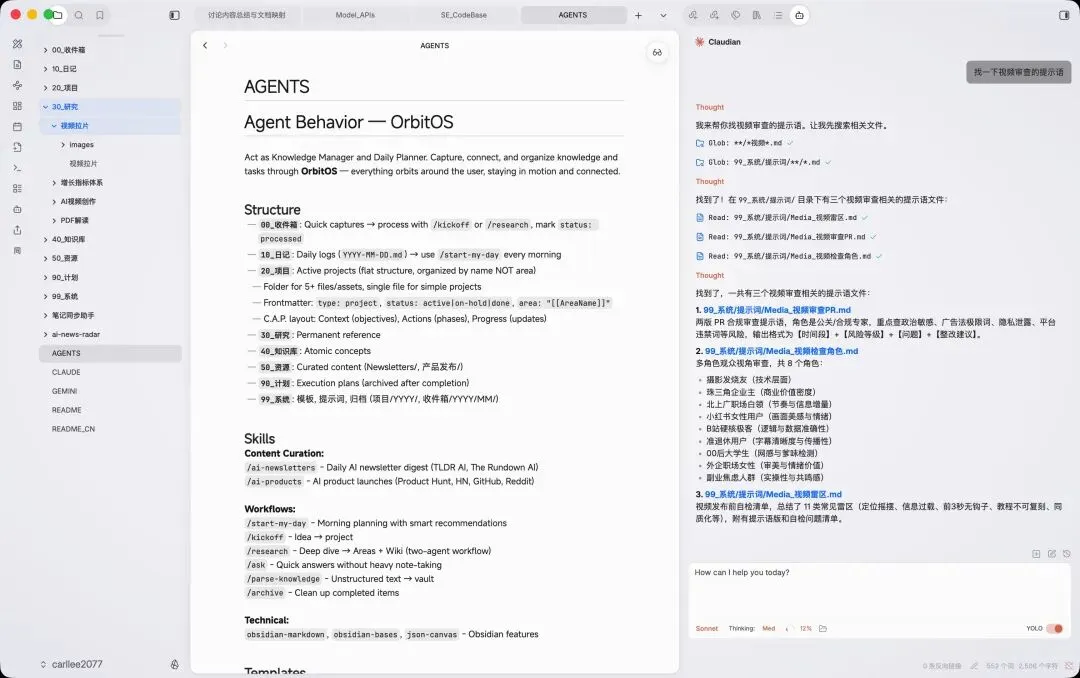
本质上,Obsidian可以看作一个功能强大的Markdown文件阅读器,它拥有丰富的插件体系,还能内置Claude Code(也叫Claudian)。不过我后来将Claudian换成了Codex App,它的表现更稳定,对话管理也更便捷。
放弃Claudian的主要原因有两个:一是它限制同时打开的对话数量(最多3个),二是没有可视化的定时任务管理。如果你们也想从Claude Code迁移记忆到Codex App,方法很简单:把本地的Claude.md文件复制一份,重命名为Agent.md,放在同目录下即可,记忆内容会自动同步。

我们还是从安装开始,
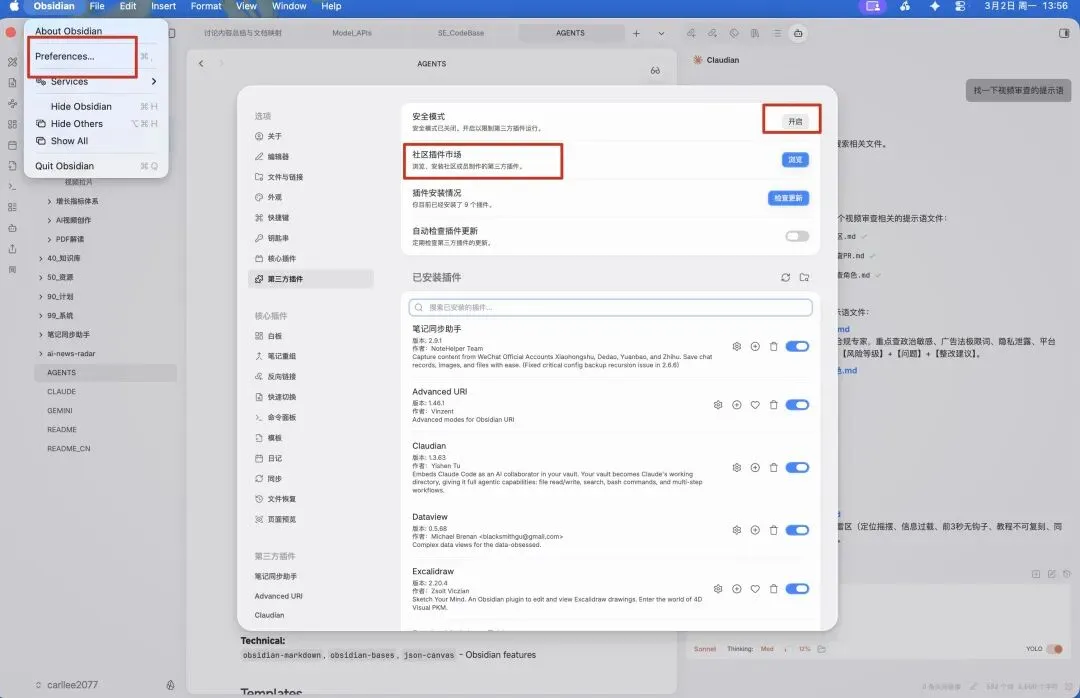
刚安装好的Obsidian就是一个纯素的阅读器,必须先安装几个核心社区插件,才能实现高效协同:
-
Claudian:将本地Claude Code内置到Obsidian侧边栏,调用更便捷;
-
笔记同步助手:核心插件,负责让Obsidian同步微信消息,解决信息流入难题;
-
Image auto upload:可选择性上传图片,通过PicGo将笔记图片同步到GitHub,降低本地存储压力;
-
ObShare:将Obsidian文件上传同步到飞书,方便和团队分享素材。
无需手动安装,直接在Claude Code或Codex App中输入插件名称,就能自动完成配置。

文件同步方面,我直接将Obsidian的文件目录放在iCloud上,无需手动设置定时同步,自动实现多端同步。至于Claude Code本身的安装,大家可以参考我之前的教程(篇幅有限,不展开),也可以直接用Codex App,全程无需额外配置,上手门槛低到小学二年级,有豆包辅助就能搞定。
内容迁移到这一步,我遇到了一个大难题:GitHub上能搜到5000多个适配Obsidian+Claude Code的文件系统项目,而且很容易陷入一个误区——认为文件目录必须和Claude Code严格匹配,否则AI记不住内容。
其实大错特错!我的实际体验是:只要在批量移动、修改文件时,让模型将相关信息录入自身memory,或者把重要的文件路径、每次启动需要读取的记忆内容,写入Claude.md文件即可——Claude Code新开对话时,会默认读取这份文件,完全不用担心记不住。

我的文件目录,是在GitHub项目MarsWang42/OrbitOS的基础上,融合了heyitsnoah/claudesidian的metadata目录(专门存放提示语和工作流模板),同时我还做了一个优化:每次对话结束后,主动更新相关知识,确保AI记忆的时效性。
这里给大家一个小建议:不用过度担心AI记不住内容,可以限制AI读取文件目录的深度(我设置的是3层子目录),如果发现AI忘记某个文件,只需把该文件的路径和用途,重新写入记忆文件即可。
另外,Claude Code在侧边栏的优势很明显,各种形式的数据(zip压缩包、图片、链接、PDF)都能先放到Obsidian收件箱,再让AI生成整理计划,批量处理更高效。
把信息收录到Obsidian的方式就分为三大类,
插件,微信和OpenClaw(专门啃难解析链接和视频)
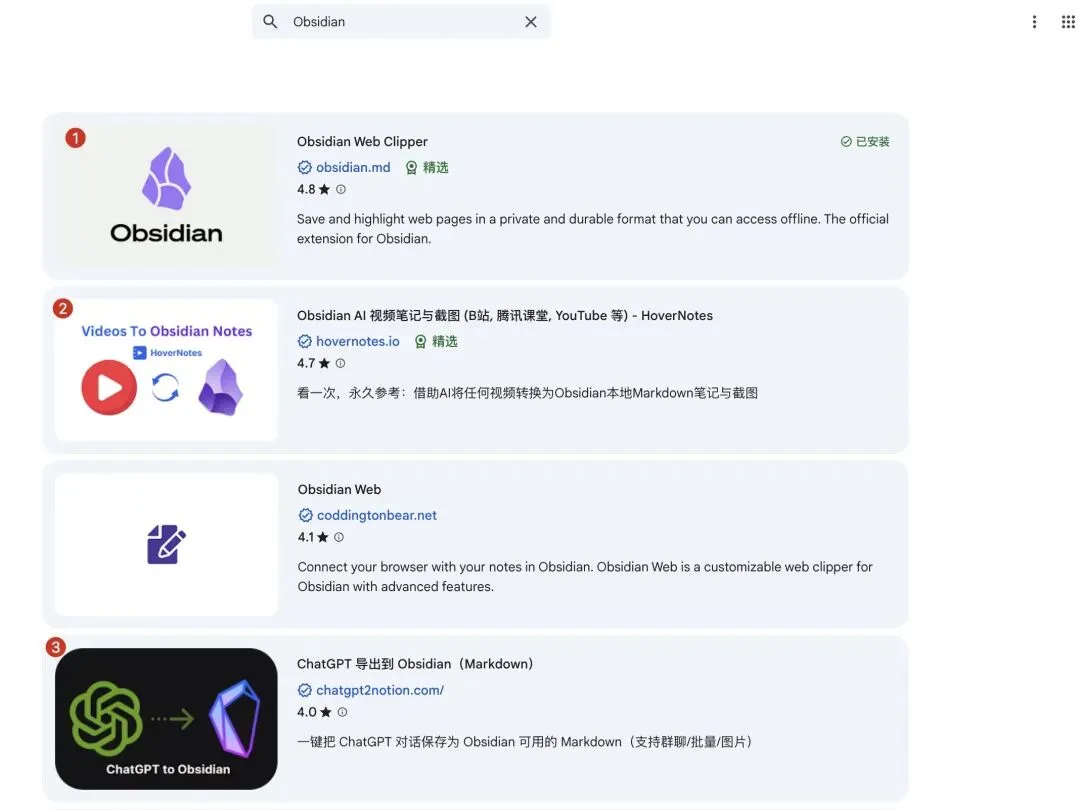
比如GPT导出到Obsidian,只需让Claude Code快速生成一个USER.md文件,就能让AI记住你的使用习惯,后续OpenClaw也能复用这份配置;Obsidian Web Clipper和HoverNotes则针对网页端,公众号文章、视频笔记都能直接剪藏到Obsidian,即便偶尔出现图片未完全获取的情况,笔记也会保留原链接,整体效果比我之前手动复制到滴答清单好太多,甚至能抓取网页评论区内容。
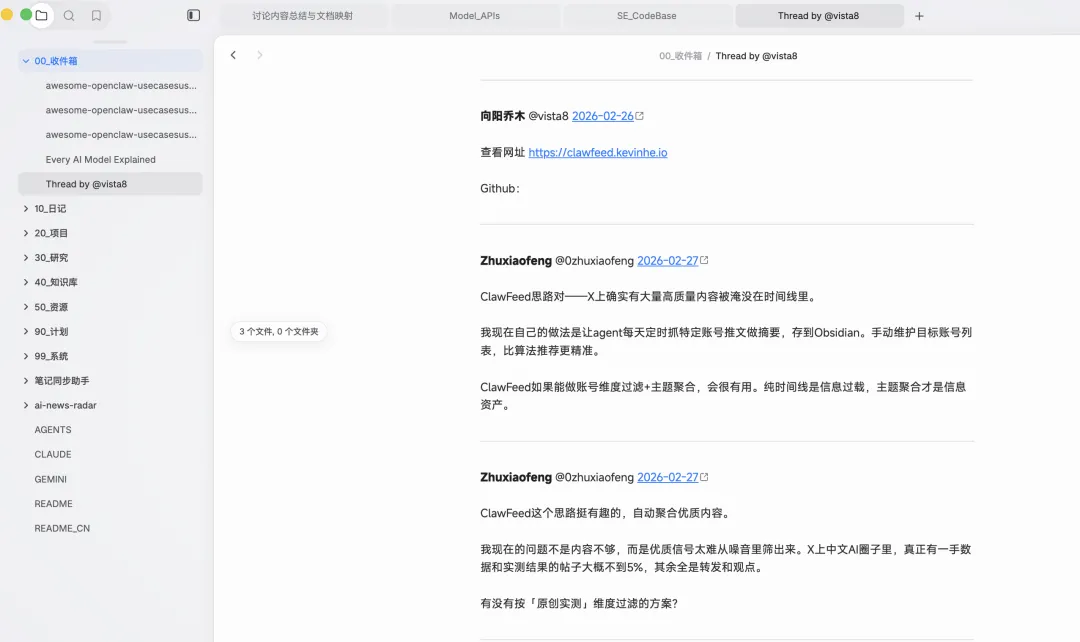
手机端我曾用Codex App做了一个快捷指令,能根据信息收录时间,自动分流到不同文件夹,但共享表单接收并非所有场景都生效。这时候我一度犹豫,是不是要回到“微信+滴答”的老路,先把信息收录到一个软件,再手动转移到Obsidian。
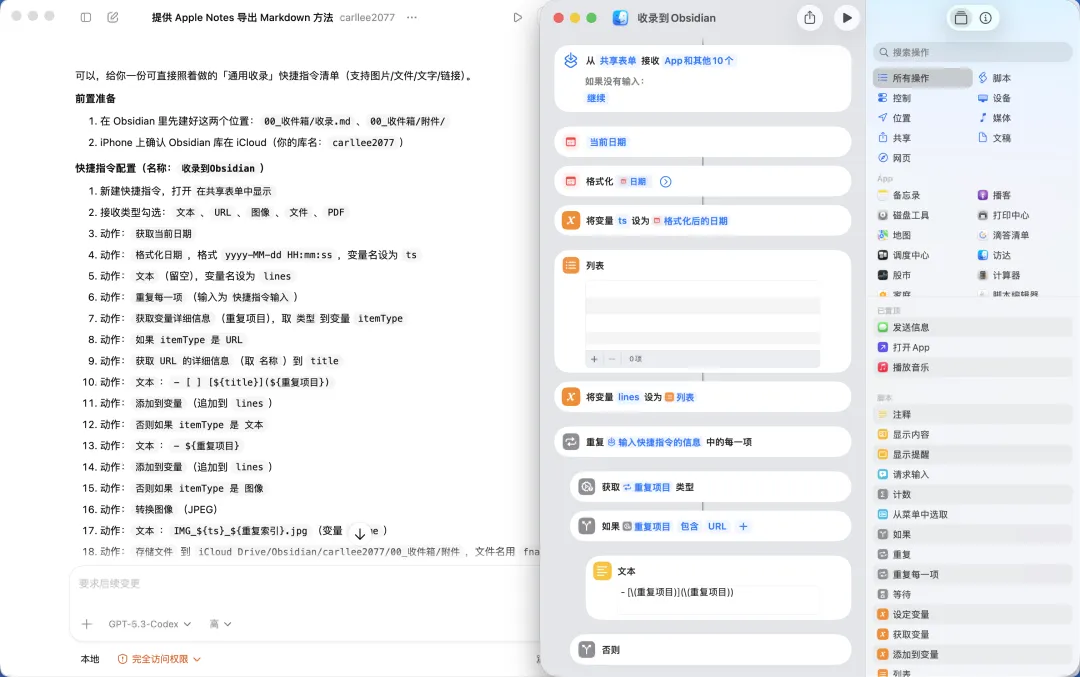
好在Deep Research功能足够强大,我尝试了Gemini、Grok和OpenAI的Deep Research后,在微信上找到了一个小众的笔记同步助手——它支持OneNote、Obsidian和Notion的跨平台同步,还能将小红书视频直接转换成图文笔记,这波绝对是意外之喜!
最后就是把OpenClaw跟Obsidian链接起来了,
其实OpenClaw是可以把上面信息录入和信息整理两步当作一步执行的,
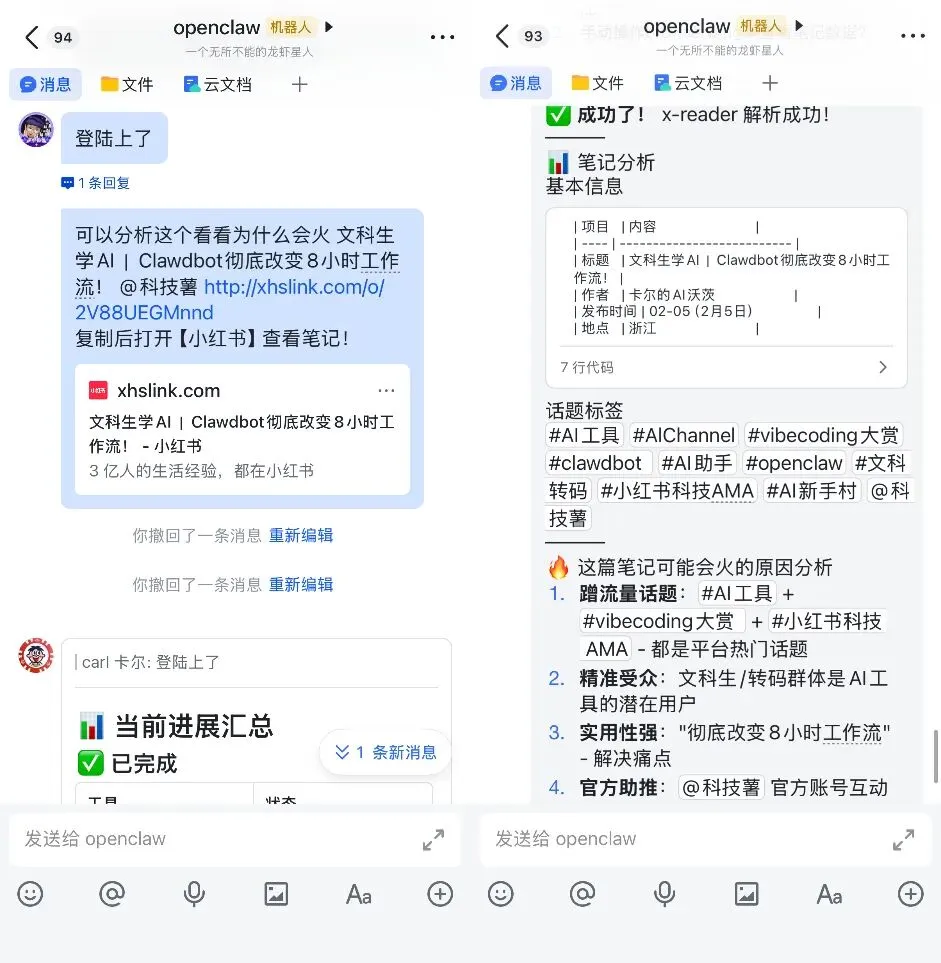
OpenClaw从零开始配置的教程我也写过了,
Clawdbot超级小白入门指南,不靠MacMini和云,安全用上满血版
这个时候就可以让OpenClaw给自己升级了。

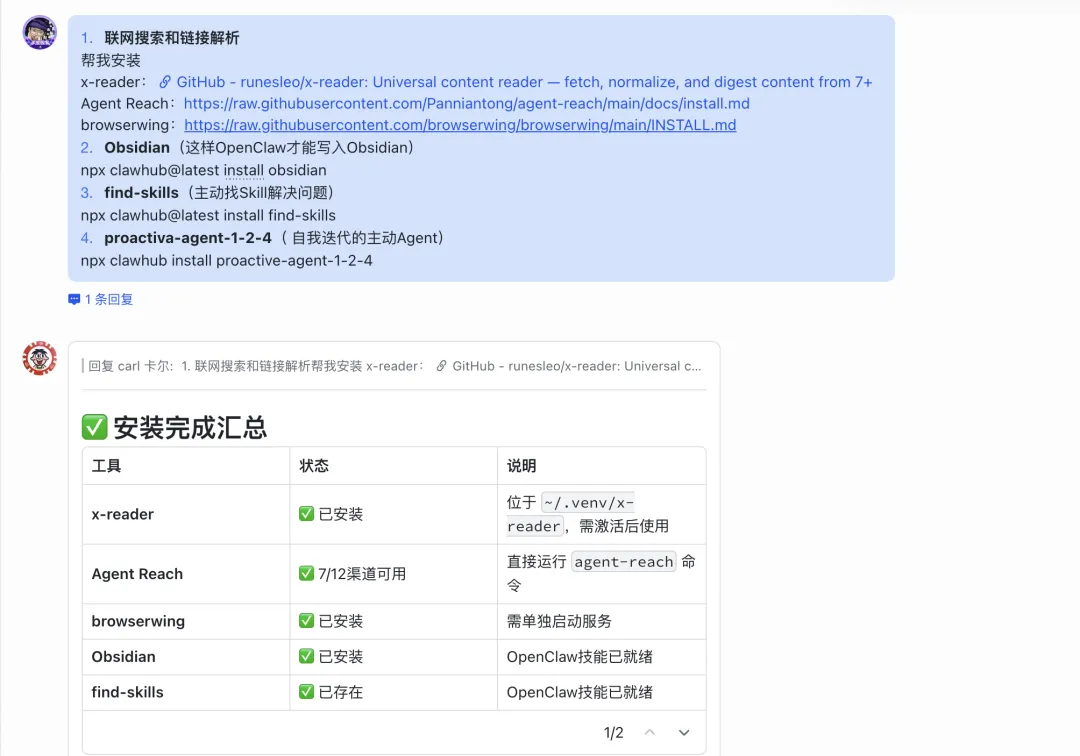
最后的最后

这样龙虾的核心配置文件就会出现在Obsidian的本地目录里,这样我们就可以在Obsidian里编写SOUL.md,OpenClaw会立刻生效。
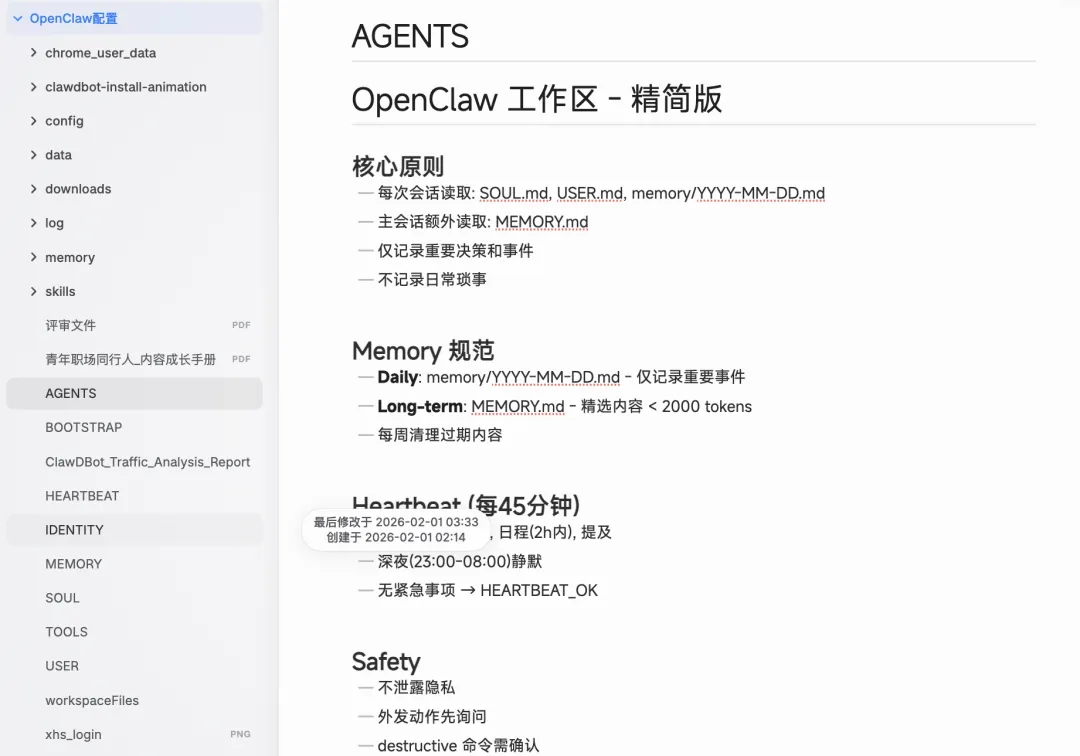
到这里,我已经完成了全流程的信息获取与自动整理,同时打通了Codex、Claude Code、OpenClaw和Obsidian四大工具。后续我会单独出一篇OpenClaw的Obsidian专题,因为现在好用的Skills越来越多,多群组+多个OpenClaw实例的使用场景也越来越普遍,而Obsidian作为本地知识管理的载体,绝对是当下最优选择之一。
折腾信息管理这么久,我最大的感悟是:不用太心疼信息损耗,能存到本地的,尽量做好备份——图床会失效,链接会过期,最简单的文字记录,反而能保存最久。

用久了会发现,同一份数据,OpenClaw会自动总结沉淀,将合适的知识点拆分到不同地方储存。刚开始我不理解它的逻辑,但用下来才发现,这正是AI协同的优势:我不需要时刻记住信息的来源,只管用就好,来源自有AI帮我记忆。
这大概就是和AI共用知识体系的独特体验:在一次次对话中,我在编写它的技能和记忆,它也在主动记录我的喜好,我们都在双向成长,无限进步。
Obsidian资料给大家整理好了,有需要的小伙伴按以下步骤获取领取方式
1、点赞+红心推荐
2、后台回复:学习