当前时间: 2026-04-28 17:07:18
更新时间: 2026-04-28
分类:软件教程
评论(0)
LLM Agent能自动完成软件分析吗?
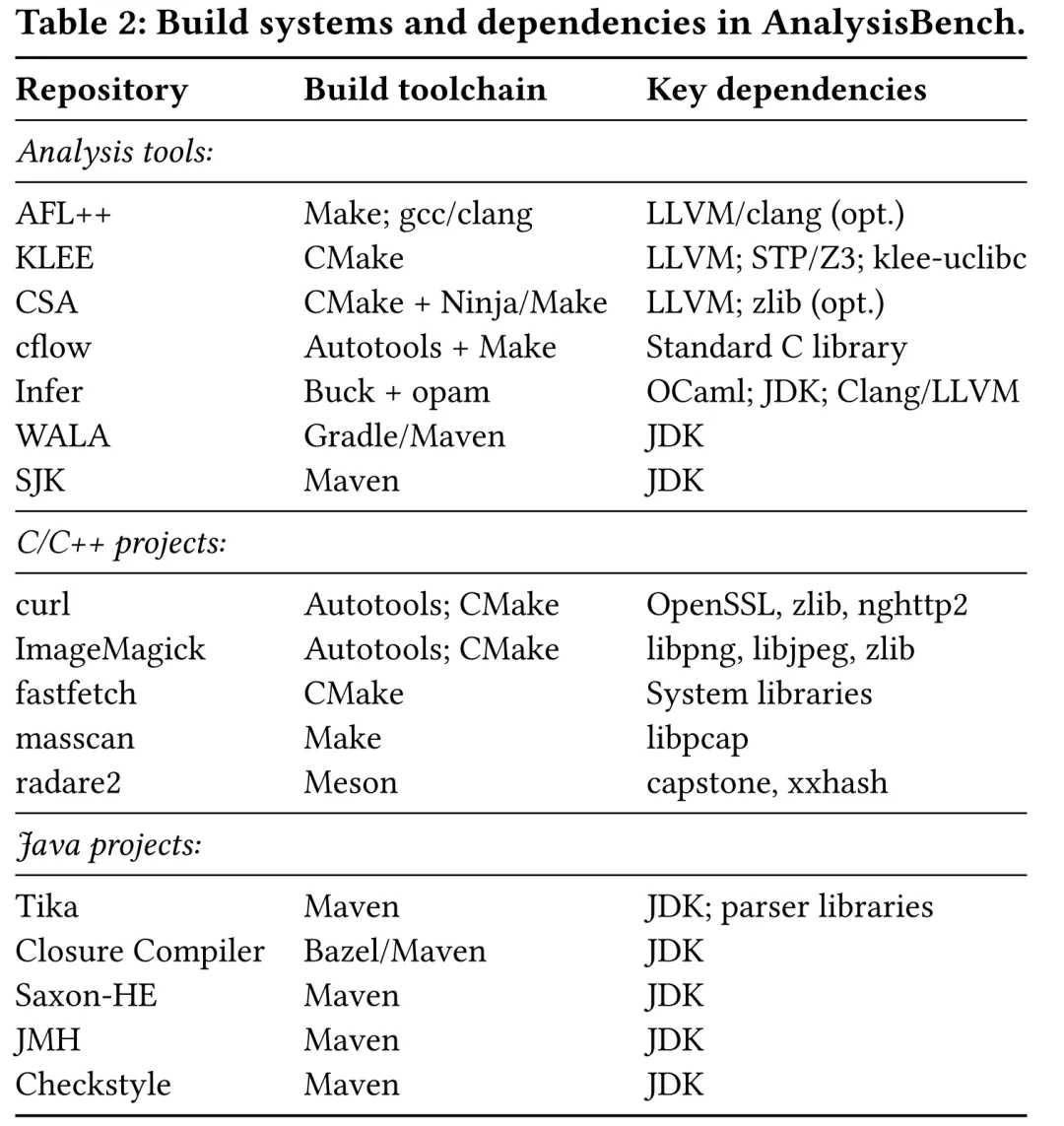
论文基本信息:Pradel, M., Cadar, C., & Bouzenia, I. (2026). Evaluating LLM Agents on Automated Software Analysis Tasks. arXiv preprint arXiv:2604.11270. 论文链接:https://arxiv.org/pdf/2604.11270 软件分析工具已经覆盖静态分析、符号执行、模糊测试、性能分析等多个方向,但是大模型是否能正确配置和使用这些工具?这篇最新工作调研了LLM agent借助已有分析工具进行软件项目自动分析的能力,作者来自德国CISPA的Michael Pradel团队和帝国理工学院。 1. 研究背景 软件工程师和研究者开发了大量的软件分析工具,但“把工具真正用到一个新项目上”仍然困难,这涉及为分析工具创建执行环境、目标项目依赖、编译器版本、构建系统、Docker 隔离环境,以及将目标项目调整为可分析状态(例如使用特定flag进行编译,生成LLVM bitcode…)。软件分析这一任务涉及多步流程、强环境信息,天然适配LLMagent: 它们可以执行 shell 命令、解释错误日志、迭代修改环境。然而,已有LLM agent在软件工程中的应用主要聚焦于issue solving、程序修复,或一般环境搭建这些通用任务。自动化软件分析比这些任务更复杂,因为它同时要求“安装独立分析工具”“构建目标项目”“生成工具专用输入”“验证项目级分析证据”。 因此,本文为自动软件分析任务构造的专用的基准数据集AnalysisBench,在benchmark上开展实证研究,并提出了一个用于软件分析任务的轻量级智能体AnalysisAgent。 2. Benchmark构造 给定一个软件分析工具T和目标项目P,Agent 需要从基础环境出发,完成 Docker 容器配置、工具及其依赖安装、目标项目获取与构建、执行软件分析工具,并输出能够证明分析完成的结果。成功标准包括可复现环境(如Dockerfile) 、完整执行轨迹 、和工具分析产物(如分析日志、调用图) 。 本文作者使用35个工具-项目对否见了AnalysisBench。作者通过3个标准筛选软件分析工具:1)工具开源且免费,2)工具代表了一种特定的分析技术(模糊测试、符号执行、静态分析…),3)工具无法通过简单方式(直接安装一个软件包)安装。最终,作者筛选的工具包括 AFL++、KLEE、Clang Static Analyzer、cflow、Infer、WALA 和 SJK,分别代表模糊测试、符号执行、静态分析、结构分析与 JVM 分析等类型。目标项目则包含5个C/C++项目和5个Java项目。具体工具和项目列表如表2所示。 3. 自动化软件分析agent 作者使用3个agent作为baseline:RAG-Agent 代表“先检索再生成完整脚本”的范式;Mini-SWE-Agent 代表通用软件工程 Agent,通过命令执行与文件编辑进行迭代调试;ExecutionAgent (来自作者此前工作”You Name It, I Run It: An LLM Agent to Execute Tests of Arbitrary Projects”, ISSTA 2025)原本面向项目环境搭建和测试用例执行,作者将其改造用于软件分析任务。早期实验显示,三类baseline存在共同缺陷:第一,缺少过程结构 ,导致在工具未安装、项目未构建时提前运行分析;第二,长日志掩盖根因 ,使 Agent 陷入无目标试错;第三,针对任务成功的验证能力薄弱 ,常把 –help、版本号、toy example运行或项目构建成功误判为分析完成。 针对这些缺陷,作者提出 AnalysisAgent,遵循三个设计原则:
显式分阶段执行。Agent 被约束为四个线性阶段:Docker setup、Tool setup、Project setup、Analysis run。第一阶段只能写入和读取文件,避免无容器时执行无效 shell 命令;第二阶段安装分析工具并进行 smoke test;第三阶段构建目标项目并生成 bitcode、compilation database 等工具专用产物;第四阶段才允许对目标项目运行分析,并将结果放入指定目录。该结构直接缓解“阶段混合”问题。
单动作循环与日志压缩。AnalysisAgent 不让模型一次生成一长串脚本,而是在每轮中先让模型提出下一步,再由独立 LLM 调用抽取第一个具体动作并格式化为可执行命令;系统执行后返回 stdout、stderr、退出码和环境元数据。面对上千行构建日志,作者没有依赖 LLM 总结,而是用确定性规则提取命令开头、70 类人工整理的失败模式匹配行,以及日志末尾信息,从而保留关键诊断信号并降低错误定位成本。
证据驱动的验证。Agent 声称完成任务时,系统会构造结构化证据包,包括阶段摘要、近期分析阶段观察和输出文件位置,并交给独立的 LLM-as-judge。该判别器不能访问 Agent 的推理上下文,只检查分析是否针对指定项目、是否产生符合工具完成状态的产物,并与由工具官方文档综合出的参考样例比较。若验证失败,Agent 会收到拒绝理由并继续尝试;同时,论文明确指出 LLM-as-judge 只是运行时启发式机制,最终评价仍以人工验证为准。
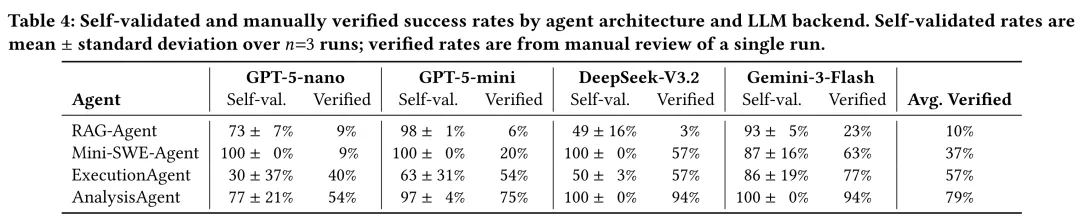
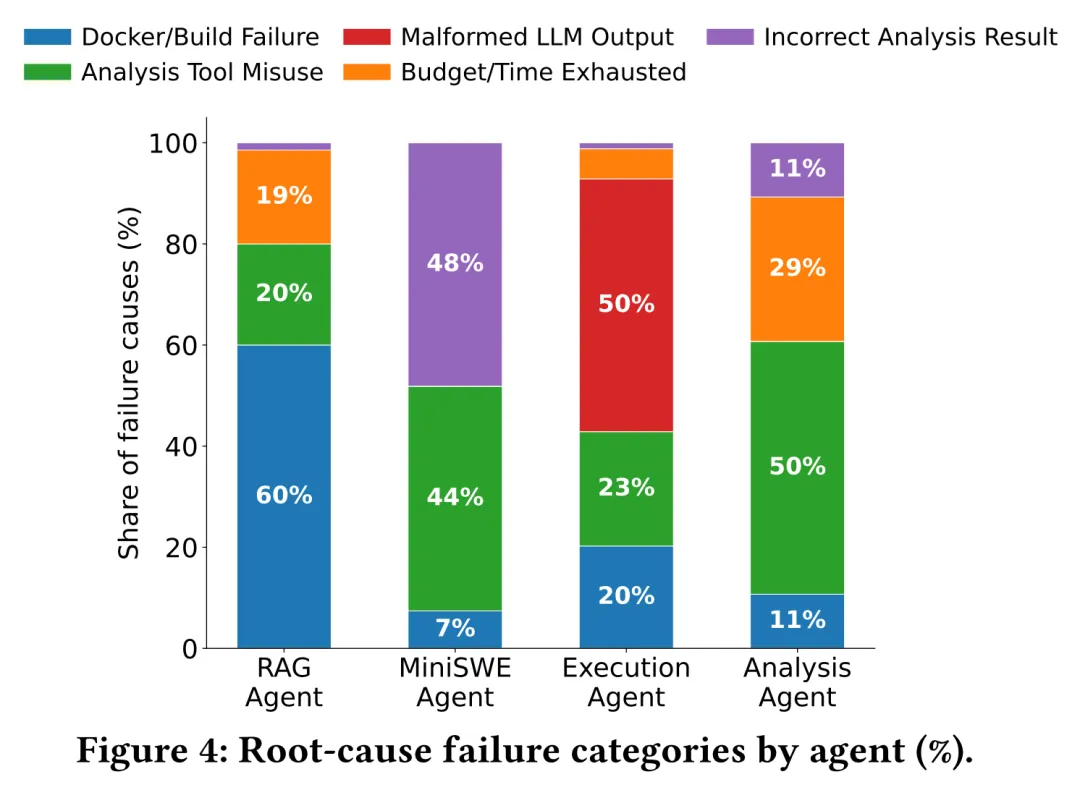
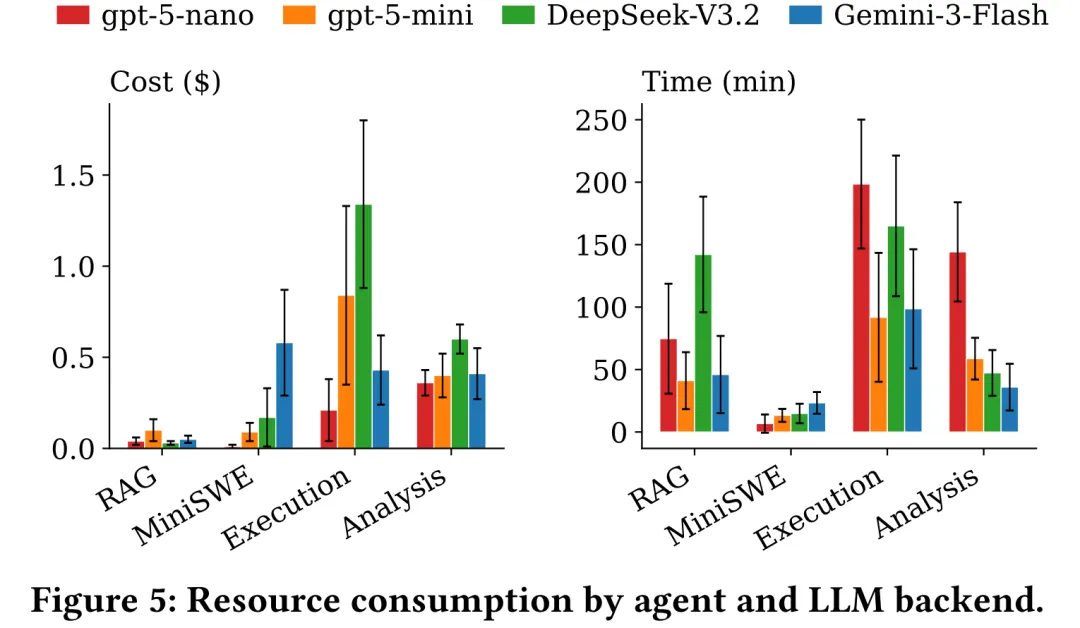
4. 实验评估 本文提出3个研究问题,分别关注有效性、成功与失败模式、以及效率和成本。 RQ1: 有效性 实验结果显示,AnalysisAgent 的平均人工验证成功率 为 79%,显著高于 RAG-Agent 的 10%、Mini-SWE-Agent 的 37% 和 ExecutionAgent 的 57%。作者发现自验证成功率普遍被高估 。某些baseline(如Mini-SWE-Agent)几乎总会声称完成任务,但人工验证后发现大量结果只是部分完成(如项目成功build,但分析工具没有使用)、玩具输入或无效输出。 RQ2: 定性分析 成功的 AnalysisAgent 运行通常具备三个特征:较早收敛到可用容器、按阶段递进并针对性修复错误、每个阶段都生成并验证证据。在成功运行中,WALA 可生成中位数 3.9 万节点、430 万边的调用图,Infer 可报告线程安全、资源泄漏和空指针等问题;但 AFL++ 和 KLEE 等动态工具在短预算下输出较浅(这些工具需要长时间运行),例如 AFL++ 中位覆盖率仅 0.44%,KLEE 中位生成 2 个测试用例。 在失败轨迹方面,主要的失败原因包括Docker/buil失败、分析工具误用、LLM 输出格式错误、预算/时间耗尽和分析结果不正确,其分布如图4所示。AnalysisAgent 基本缓解了环境搭建问题,其失败更多集中在工具调用层面。 RQ3: 效率和成本 成本分析说明,低价模型未必更省钱。GPT-5-nano 虽然 token 单价低,但平均调用次数和执行时间最高。Java 任务比C/C++更耗资源,因为其工具链依赖更重、常需完整构建目标项目,并涉及 JVM 后台进程与 profiler attach 等运行时协调。 5. 总结 本文提出了一个独特的问题:利用大模型调用复杂的软件分析工具,这一问题在此前关于通用软件工程agent以及环境配置agent的工作中很少被考虑。本文系统分析了已有agent在这一任务上的不足,并提出了一个针对该任务的agent结构。
上一篇报名 | 企业数智化训练营(AI+财务专场)
 夜雨聆风
夜雨聆风