 夜雨聆风
夜雨聆风





"一个搭房子,一个画房子:AI 设计工具走上两条路"
事情是这样的。
上周有个朋友给我发了张图,一个 AI 生成的运营数据看板,做得有模有样的,表格、折线图、饼图一应俱全。我问他哪个 AI 画的,他说“Claude Design”。
我当时就愣住了。
Claude 不是做聊天机器人的吗?什么时候开始搞设计了?
还没等我缓过神来,OpenAI 那边又放了个大招,GPT Image 2.0 上线,据说是 AI 生图领域的“断层领先”。B 站上有个叫 Xuan_酱的 UP 主,三天爆肝总结了 GPT Image 2 的玩法,视频播放量 7.2 万。另一个 UP 主带你吃火锅儿,花三天测了 32 个分类,对比 GPT-Image2 和 nano-banana 2,播放量 1.3 万。
两个工具前后脚出来,一个做设计原型,一个做图像生成,都是 AI 在设计领域的大动作。
我花了一整个周末,把两个工具都翻了个底朝天。

Claude Design:搭房子的人
先说 Claude Design。
这玩意跟我想象中完全不一样。
我本来以为它跟 Midjourney 一样,输入一段描述然后吐出一张图。结果不是。Claude Design 生成的是 HTML,是活的组件,是你可以直接改的文字和按钮。
打个比方,如果 Midjourney 是给你画了一张房子的照片,那 Claude Design 是直接给你搭了个房子出来。你可以推门进去,可以挪家具,可以换墙纸。
我的第一反应是,这也太猛了吧。
我试着让它帮我做一个运营数据分析仪表盘。输入了一段需求,大概就是“帮我设计一个电商运营数据看板,包含 GMV、订单量、转化率这些核心指标”。大约两分钟,它就给了我一个完整的看板页面。
七个数据表格,四个核心指标展示,折线图饼图柱状图都有,排版层次清晰得让人头皮发麻。
说真的,这东西如果放在两年前,得是专业数据可视化团队干两三天的活。
我当时就兴奋了,觉得发现了新大陆。
然后我试了一个稍微不同的需求,让它做一张新书上市的海报。
这次它没直接出结果,而是先问了我三个问题,书的卖点是什么,目标读者是谁,海报风格调性有什么偏好。
回答完之后它给了四个不同方向的方案,但都用占位图代替了实际封面。版面看着还行,就是不像成品,更像设计过程中的概念稿。
这就很有意思了。
Claude Design 在信息密度要求高的场景里简直如鱼得水,数据看板、后台管理界面、表单设计这些它特别在行。但到了纯视觉呈现的场景,比如海报、杂志封面这类“好看就行”的需求,它就不那么能打了。
为什么呢?
因为 Claude Design 生成的是结构,不是画面。它背后是 HTML 和组件,擅长的是信息组织和逻辑排版,不是视觉冲击力。
就像一个特别会搭积木的工程师,你让他搭个功能性很强的东西他分分钟搞定,但你让他画一幅油画,他可能得挠头。
GPT Image 2.0:画房子的人
然后是 GPT Image 2.0。
这个的思路完全不一样。
GPT Image 2.0 生成的是图片,真正的图片。 它的核心能力是把文字描述变成视觉作品。
我也试了三个场景。
第一个,杂志封面。
输入了一段描述之后,大约 30 秒出图。排版整齐,字体清晰,甚至能选择不同宽高比适配不同版式。这种标准化的视觉物料是它最擅长的领域之一。
说实话,如果不说这是 AI 生成的,很多人可能看不出区别。
第二个,产品海报。
我给了它一张汽车的照片,让它做一张产品宣传海报。它居然主动联网搜索了这辆车的品牌信息和智驾方案提供商,然后在海报里把这些信息都融合进去了。
这个“主动补信息”的能力让我有点惊讶。
不过这里得提醒一句,它能识别品牌信息不代表你就有权使用。商业场景下的版权问题还是要自己把关的。
第三个场景我想试试它的极限,让它画一组多格漫画。
这个就翻车了。
主角骑的车在不同分镜里变了三次。 第一格骑的自行车,第三格变成摩托车了,到第五格又变成了一辆不知道什么型号的电动车。它画每一格都挺好看的,但放在一起就串戏了。
这也暴露了 GPT Image 2.0 的一个短板,角色和物体的一致性在多帧场景里还不稳定。
但是,但是。
我得说一个让我印象特别深的事。
GPT Image 2.0 的中文渲染终于能看了。
用过 AI 生图的朋友都知道,以前不管 Midjourney 还是 DALL-E,一到中文就变成了鬼画符。要么是乱码,要么是错别字,反正就是没法看。
GPT Image 2.0 在中文、日文、韩文这些非拉丁文字的渲染上有了质的提升。能直接生成排版合理、文字融入画面的设计。
这一条对中文用户来说太重要了。
不是竞品,是两个物种
说到这里,我其实已经能感受到这两个工具的本质区别了。
GPT Image 2.0 生成的是“图”,本质是图像。Claude Design 生成的是“原型”,背后是 HTML 和组件结构。
这不是谁比谁强的问题,是两个完全不同的物种。
就像你问“菜刀和剪刀哪个更好用”,答案是看你要干什么。
我做了个不太严谨但很直观的对比。同一个任务给两个工具,看看各自的输出。
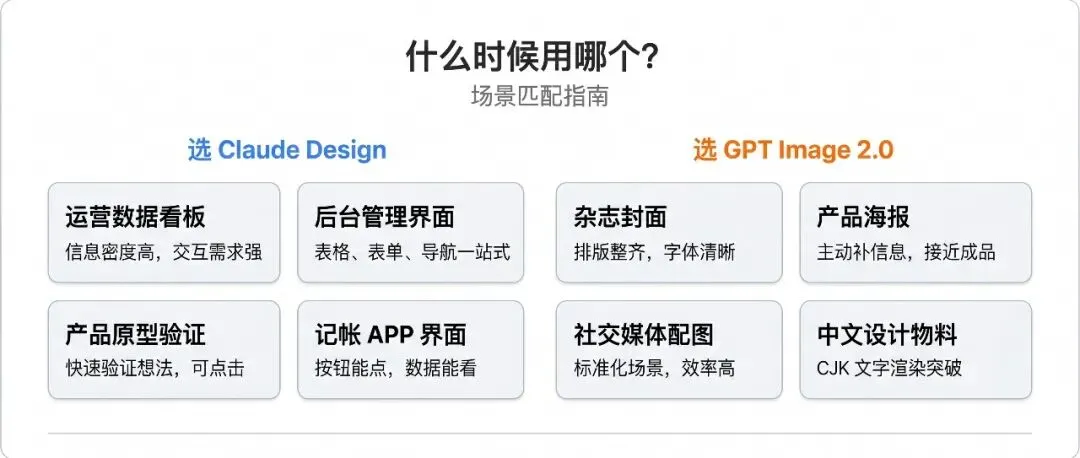
任务一,运营数据看板。
Claude Design 完胜。七个数据表格加四个核心指标展示,排版层次清晰,信息密度高。
GPT Image 2.0 也生成了,但数据呈现偏笼统,缺少关键细节。毕竟它生成的是一张“看起来像仪表盘的图”,而不是一个真正的仪表盘。
任务二,新书上市海报。
这次 GPT Image 2.0 反超了。构图完整,图文排布合理,效果接近可以直接拿来用的成品。它甚至主动加了推荐人模块,还通过联网搜索给了比较精准的推荐人信息。
Claude Design 这边呢,先问了三个问题,最后给了四个方向的概念稿,但用占位图代替了实际封面,视觉焦点模糊,更像是设计探索而非成品。
任务三,记账 APP 界面。
这个我给两个工具都喂了同样的设计草图。
Claude Design 输出了完整的交互界面,按钮可以点,数据可以看,甚至不同页面之间有跳转逻辑。它是在搭建一个真正的产品原型。
GPT Image 2.0 给了一张非常漂亮的 APP 界面截图,视觉效果出色,但你只能看,不能点,不能改。
看出来了吧。
-
信息展示和功能结构 → Claude Design 更合适
-
视觉成品和设计美感 → GPT Image 2.0 更合适
为什么要直接上手捏泥
说到这个,我想聊一个更有意思的事。
HN 上有个哥们写了一篇文章,叫“Thoughts and feelings around Claude Design”,拿到 387 个赞。他提出了一个观点我觉得特别有洞察力。
他说 Figma 当年赢过 Sketch,靠的是让自己的工具成为设计的“真相源”,设计文件就是最终标准。但这个胜利有个隐藏代价,Figma 的格式是封闭的、文档化程度很低的,AI 模型根本学不到 Figma 的操作方式。
LLM 是吃代码长大的,不是吃 Figma 文件长大的。
所以当 AI 开始能写代码、能生成网页的时候,设计的真相源自然就回到了代码。你直接在最终的媒介里做设计,干嘛还要在一个有损的近似物里折腾呢?
“如果我们要做陶器,为什么要在纸上画陶器的水彩画,而不是直接上手捏泥呢?”
这话说得我直拍大腿。
各自的局限
回到实际使用层面。
我自己用了一周之后的感受是这样的。
Claude Design 适合:
-
快速搭建产品原型
-
做数据看板或后台界面
-
快速验证设计想法
-
对代码不太恐惧的产品经理或运营
GPT Image 2.0 适合:
-
快速出专业海报或封面图
-
给客户展示视觉方案
-
创意性视觉探索
-
设计工具零基础,只想出一张好看的图
坦率的讲,这两个工具目前都还不能替代专业设计师。
Claude Design 虽然能出原型,但细节打磨还得人来。而且它的配额消耗是出了名的快,有用户实测 5 分钟就烧掉了 80% 的周配额。这谁顶得住啊。
GPT Image 2.0 虽然视觉效果出色,但一致性问题还没解决,训练数据截止到 2025 年底,对最新事物的覆盖依赖实时搜索。而且生成的图片终究是图片,你不能像改 PPT 一样改里面的元素。
但它们确实在改变一件事,设计的门槛在急剧降低。
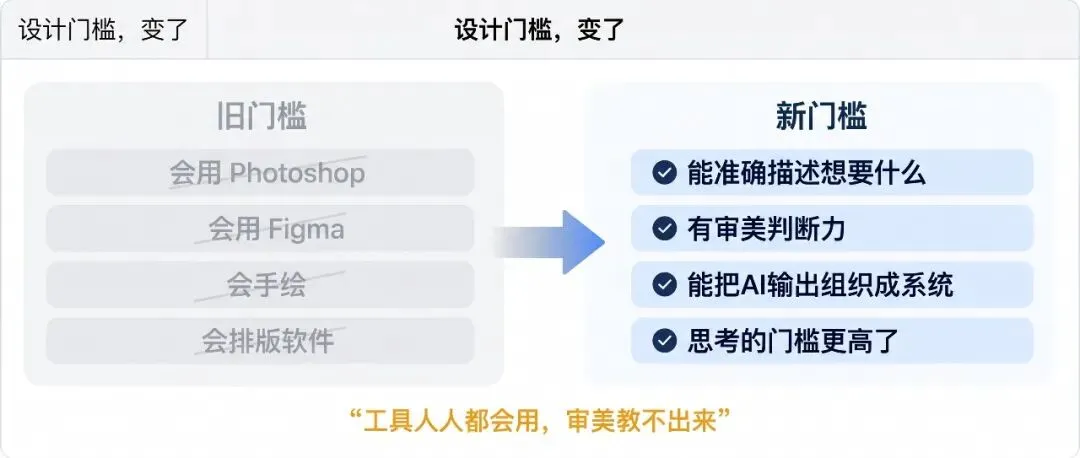
知乎上有个问题叫“GPT-Image-2 发布,设计师和普通人之间的门槛消失了吗”,拿到 133 个赞。最高赞回答的核心观点是,门槛没有消失,但门槛的形状变了。
以前的设计门槛是“你会不会用 Photoshop、Figma 这些工具”。现在这个门槛正在被 AI 工具推平。
但新的门槛正在出现,你能不能准确描述你想要什么,你有没有审美判断力来筛选 AI 给你的选项,你能不能把 AI 的输出组织成一个完整的设计系统。
坦率的讲,工具的操作门槛在降低,但思考的门槛没变甚至更高了。
已经在疯狂干活了
有个事让我觉得特别有意思。
B 站上 code 秘密花园做了个视频,叫“我把 Claude Design 做成了 Skill,人人都能成为顶级网站设计师”,播放量 5.3 万。评论区一堆人说用了 Skill 之后设计效率翻了倍。
小红书上也是,一搜 Claude Design 全是体验帖。“好可怕的 Claude Design”拿了 2029 个赞,“体验完 Claude Design 之后我睡不着了”也有 264 个赞。
用户的反应是最真实的。大家不是在讨论这工具好不好,而是已经在疯狂地用它干活了。
36 氪写了篇文章标题直接是“设计行业的棺材板要被 Claude Design 盖上了”。虽然有点夸张,但也不是完全没道理。Figma 的股价确实受到了冲击,一个叫 Open CoDesign 的开源替代品已经在做“本地优先、开源”的竞品了。国内也有人做了个叫 Huashu Design 的开源平替。
开源社区开始复刻一个工具,这本身就是最好的需求验证。
2026:两条路线
我自己有个不太成熟的看法。
2026 年 AI 设计工具会分叉成两条路线。
视觉生成路线——核心能力是把文字变成图片。GPT Image 2.0、Midjourney、谷歌的 Imagen 都在这条路上。它们解决的问题是“我脑子里有个画面但画不出来”。
结构生成路线——核心能力是把需求变成可交互的产品原型。Claude Design、v0、Open CoDesign 在这条路上。它们解决的问题是“我有个想法但不会做原型”。
两条路线服务的用户不一样,解决的问题不一样,最后大概率不是谁替代谁,而是各自占据不同的生态位。
对普通用户来说,好消息是以前必须花钱请设计师做的事,现在有了 AI 辅助,至少能做到七八十分的水平。剩下那二三十分,就是专业设计师真正创造价值的地方。
说真的,我觉得 AI 对设计行业最真实的影响就是,它在重新定义什么是“设计工作的核心价值”。
以前设计师的核心价值是“我会用工具”。
以后设计师的核心价值可能是“我会判断,我会思考,我知道什么是好的设计”。
工具人人都会用,审美这东西,教不出来。
实用入手指南
最后说点实用的。
如果你想试试这两个工具,我建议这么入手。
Claude Design:
-
直接去
claude.ai/design就能用,免费用户有额度限制 -
刚开始别上来就搞复杂项目,先做个简单的着陆页或者数据卡片试试手感
-
记得给它提供足够的上下文,它问你的问题认真回答,这样出来的东西质量会高很多
GPT Image 2.0:
-
在 ChatGPT 里直接用,Plus 用户优先
-
建议从海报、社交媒体配图这种标准化场景开始试
-
如果你要生成中文内容,记得在提示词里明确说明需要中文文字,它的中文渲染确实比以前好太多了
两个工具都值得花时间玩一玩。
不是为了替代什么人,纯粹就是,这玩意太有意思了。
我自己这一周玩下来,最大的感受不是 AI 有多厉害,而是以前很多因为“不会做”而搁置的想法,现在有了尝试的可能了。
就像一个不会画画的人突然拿到了画笔,画得好不好是一回事,但至少可以开始画了。
这个感觉本身就挺让人兴奋的。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。