 夜雨聆风
夜雨聆风





RuyiAI Triton-RISCV开源:在RISC-V上实现Triton原生编译
Triton-RISCV已在中国科学院软件研究所智能软件研究中心推出的RuyiAI系统软件栈中开源,欢迎大家体验和交流。相比现有的Triton项目,它有两个核心特点:
-
原生支持RISC-V向量扩展(RVV)架构:可以在SG2044平台上直接原生构建与运行,无需交叉编译。
-
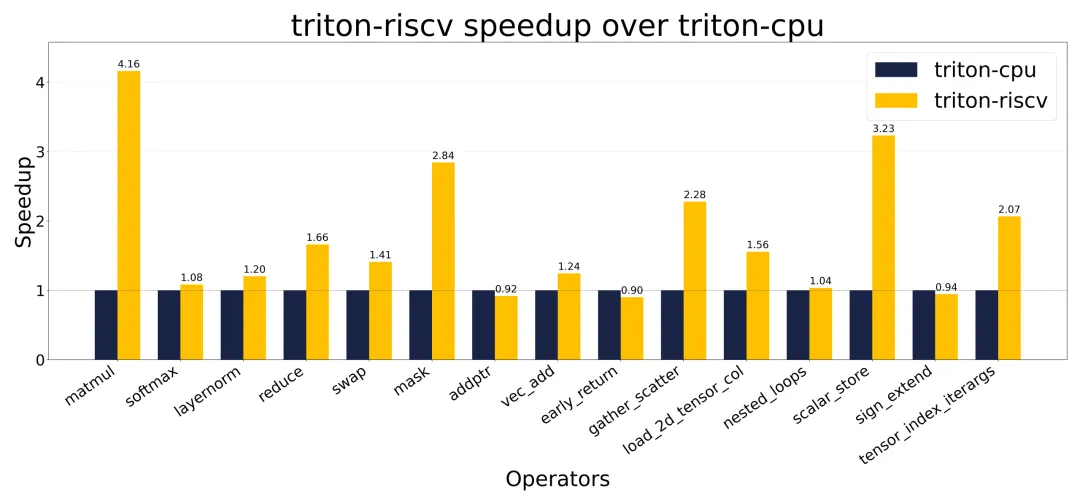
复用buddy-mlir的向量化能力:在采用triton-shared将Triton转换成MLIR的Linalg方言后,buddy-mlir通过自定义的中间表示和下降通路进行优化。在SG2044单线程评测中,相比triton-cpu,最高性能提升达到4.16x,整体平均提升1.57x。
下面介绍我们做Triton-RISCV的动机、技术路线、以及当前的覆盖率和性能结果。
先从Triton本身说起。
在现有的算子编译优化方法中,Triton凭借结构清晰的分块编程模型和友好的Python接口,已经在GPU架构上得到了广泛应用,并且正在被越来越多的后端接入和完善。
对RISC-V平台来说,支持Triton的意义不只是“多支持一种前端语言”,更是打开了一个生态入口:既可以复用Triton的编程模型和使用接口,也能够承接围绕Triton构建的算子库、优化框架等软件生态。
但要把Triton真正落地到RISC-V平台,现有方案仍存在一些不足。
triton-cpu默认会依据向量化维度的输入尺寸,生成相同向量长度的mask load/store。然而在实际场景中,当输入尺寸远超硬件支持的向量寄存器长度时,这种策略会导致严重的寄存器溢出,导致性能不佳。
triton-shared可以将Triton转换为基于Linalg方言,有利于后续的优化和扩展。但当前在下降到RISC-V平台时,主要依赖MLIR官方的convert-linalg-to-affine-loops等标量通路,仍缺少专门的向量化实现来保证可用性能。
此外,这两种方案都不支持在RISC-V平台上的原生编译。
因此,我们实现Triton-RISCV的思路是:前端尽量复用triton-shared的生态,将中间表示落到Linalg层;随后把核心向量化能力交给buddy-mlir,最终生成高效的RVV指令。
Triton-RISCV的整体编译流程如下:
1. 首先将Triton算子转换成Triton官方的TTIR层中间表示;
2. 然后通过triton-shared转换到Linalg层中间表示;
3. 接下来在核心优化阶段接入buddy-mlir,基于自定义的VIR方言完成向量化;
4. 最后逐步下降到LLVM IR,最终完成RVV指令的代码生成。
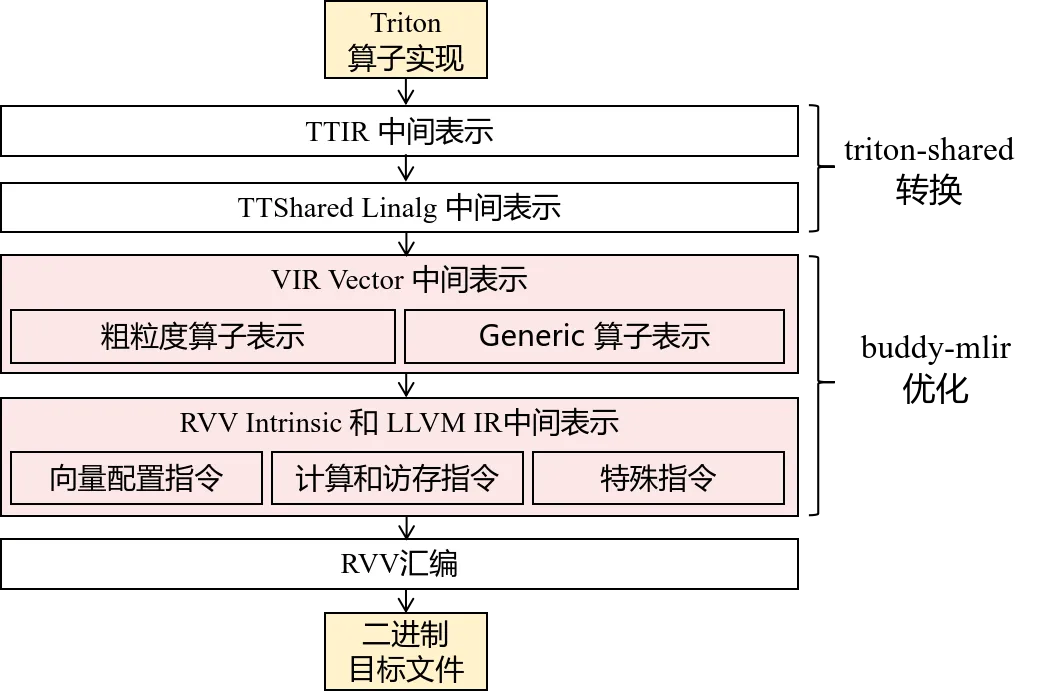
目前主要在两个层级上做了优化。
1.Triton -> Linalg:减少不必要的数据搬运
这一部分基于triton-shared完成,我们重点优化了访存路径,目标是缩短访存链路,减少不必要的数据搬运。
原有实现中,输入和输出路径存在较多临时搬运,例如使用memref.copy、tensor.extract_slice和bufferization.materialize_in_destination。现在改为更直接的向量访存形式:输入拷贝使用显式向量循环,并在尾部使用标量循环处理剩余元素;输出写回采用vector.transfer_read和vector.store,并配合尾部标量处理。在缩短访存链路之后,后续向量化阶段也更容易获得性能收益。
2.Linalg -> VIR -> LLVM IR:提高向量化覆盖率
这一部分主要复用buddy-mlir的向量化能力。我们针对两类Linalg算子进行了优化:一类是粗粒度算子,如matmul、conv、reduce;另一类是linalg.generic算子,例如常见的arith、cmp/select、min/max、位运算和移位操作。
这些算子会被改写为对应的向量化形式,从而整体提升向量化覆盖率。完成VIR层优化后,Triton-RISCV会继续打通下游代码生成链路,将向量语义逐步下降到LLVM IR,并最终映射到RVV指令,在目标平台上执行。
目前我们从两个方面验证覆盖率。
一个是triton-shared在python/examples中自带的25个Triton测例。涵盖矩阵计算、规约、索引、掩码、访存等场景,目前已全部跑通。
另一个是FlagGems 在 src/flag_gems 中的代表性测例。由于原始测例与FlagGems自身实现的运行时接口强耦合,无法直接执行,因此我们从中挑选并改写了12个测例,涵盖blas、norm、distributed、attention等4个类别。这些测例也已全部跑通,其类型和算子名称汇总如下:
|
类型 |
算子名称 |
|
attention |
attention_flash |
|
attention |
attention_paged_varlen |
|
attention |
attention_sdpa |
|
blas |
addmm |
|
blas |
bmm |
|
blas |
mm |
|
norm |
batch_norm |
|
norm |
group_norm |
|
norm |
layer_norm |
|
distributed |
exponential |
|
distributed |
normal |
|
distributed |
uniform |
实验设置
我们将实验设置统一为以下六个部分。
-
硬件平台
评测平台为SG2044(riscv64),具备RVV原生执行环境。
-
软件版本
-
Python版本:3.11.6
-
Triton-RISCV commit:ce741e2587c9b08c65b4663d1d3ed425170e5810
-
buddy-mlir commit:ceb66d1bef69d9cd7bfe1a0b94748e982902aca3
-
优化对象
评测对象来自triton-shared提供的Triton测例,包括matmul、softmax、layernorm、reduce、mask、gather_scatter、nested_loops等。
-
基线选择
基线为triton-cpu,对应版本是在官方提交基础上加入RISC-V原生编译补丁得到的实现。我们将该实现也放到了RuyiAI-Stack中。
-
性能指标
性能指标定义为执行时间相对triton-cpu的加速比:
Speedup = triton-cpu Wall Avg / Triton-RISCV Wall Avg
当数值大于 1 时,表示Triton-RISCV具有性能优势。
-
评估方法
所有case均在单线程下测量Wall time,每个benchmark使用warmup=5、repeat=20,取Wall Avg作为最终结果。
实验结果
在上述统一设置下,Triton-RISCV在纳入统计的 15 个算子中,平均加速达到 1.57x,峰值达到 4.16x(对应算子为matmul)。
仓库地址:https://github.com/RuyiAI-Stack/triton-riscv
在RVV平台(如SG2044)上,可直接按照README进行原生构建与运行。
Triton-RISCV是RuyiAI-Stack在AI编译栈中的一块关键拼图。它基于triton-shared接入Triton生态,并复用buddy-mlir的向量化能力,将Triton算子真正放到RISC-V/RVV平台上原生执行。欢迎大家试用、复现和反馈!