 夜雨聆风
夜雨聆风





Meta AI Tuna-2:完全移除视觉编码器,仅靠像素嵌入的统一多模态模型
论文标题: Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation
作者: Zhiheng Liu 等,Meta AI、香港大学、Waterloo 大学
项目主页: tuna-ai.org/tuna-2
问题与动机
统一多模态模型(UMM)的目标是在单一框架内同时支持视觉理解和图像生成。
但当前主流方案在编码视觉输入时普遍依赖两类预训练编码器:VAE 负责压缩图像到潜在空间做生成,CLIP/SigLIP 负责提取语义特征做理解。
问题在于这两类编码器是独立训练的——一个面向重建、一个面向语义对齐——它们输出的视觉表征在理解和生成之间存在本质不匹配。
而且编码器引入了固定分辨率、有限细粒度等归纳偏置,让模型无法端到端地从原始像素直接学习。
Tuna-2 要回答一个核心问题:能不能彻底去掉预训练视觉编码器,构建一个从原始像素直接建模的统一多模态模型?
核心方法
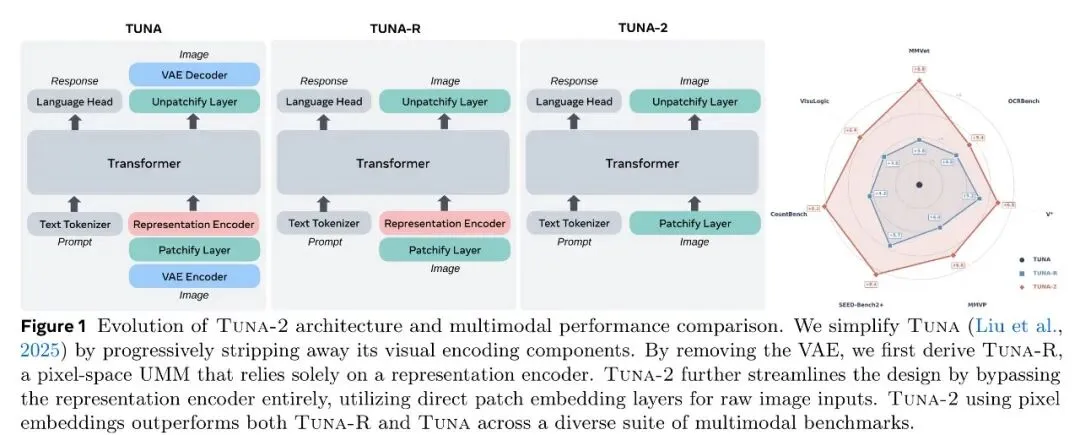
Tuna-2 的最终架构异常简洁:原始图像 → patchify 层(可学习的线性投影)→ 视觉 token + 文本 token → 单一 Transformer decoder。
理解输出走语言模型头做自回归文本,生成输出走 flow matching 头直接在像素空间生成图像。
与现有做法的本质差别在于:Tuna-2 不需要专门的 encoder 来”理解图像”,也不需要用 VAE 压缩到潜在空间再做生成——完整模型就是一个 Transformer,从输入到输出端到端优化。
Tuna-2 是在 Tuna 架构上逐步简化的结果。从最复杂的 Tuna(VAE encoder + LLM decoder + flow matching head)到去掉 VAE 的 Tuna-R(仅保留 SigLIP 2),再到连 representation encoder 也去掉的 Tuna-2——只剩下 patch embedding + Transformer decoder。
关键设计有两个。一是像素空间 Flow Matching,去掉 VAE 后不能走 latent diffusion 路线,改用 JiT 的像素空间 flow matching 方案。给定源图像和高斯噪声,根据 rectified flow 的线性 schedule 构造含噪样本,模型直接预测干净图像,再用 Euler solver 逐步去噪生成。
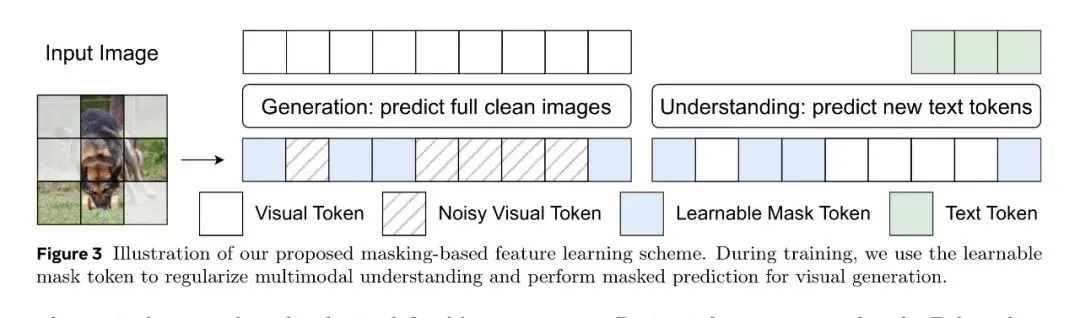
二是 Masking 策略,训练时随机选择部分图像 patch 用 learnable mask token 替换,迫使模型从残缺信息中预测完整图像。生成任务上它创造了更难的去噪问题,理解任务上则作为正则化防止模型走捷径。实验显示 masking 对两个任务都有提升。
训练流程
Stage 1 用 5.5 亿图文对预训练 30 万步,其中 70% captioning、30% text-to-image,外加 20% 纯文本数据。
LLM decoder 用的是 Qwen2.5-7B-Instruct,优化器 AdamW,学习率 1e-4。
Stage 2 用 FineVision 13M 图文对话和 OmniEdit 2M 图像编辑数据微调 5 万步。
因为去掉了编码器,Tuna-2 不需要像 Tuna-R 那样增加额外的 connector alignment stage,这是 encoder-free 设计的附带优势。
实验结果
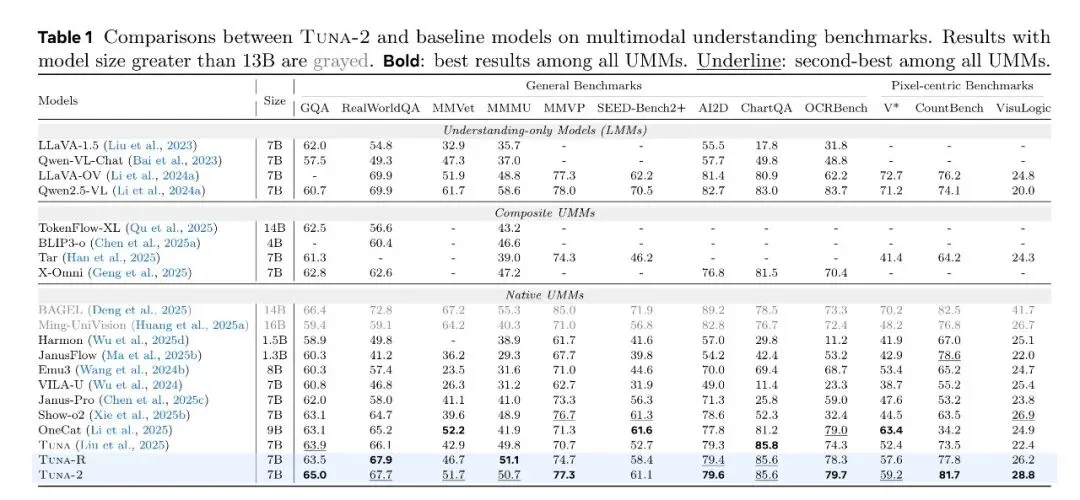
理解能力是这篇论文最有力的部分。在 12 个 benchmark 上,Tuna-2(7B)不仅全面超越带 VAE 的 Tuna(如 MMVP 77.3 vs 70.7、CountBench 81.7 vs 73.5),还超越了带 SigLIP 的 Tuna-R(如 OCRBench 79.7 vs 78.3、V* 59.2 vs 57.6)。
图像生成上小幅落后于带 VAE 的方案(GenEval 0.87 vs 0.90),但 LLM judge 评估中生成多样性大幅领先(48.4% vs Tuna 20.6%、Tuna-R 30.9%)。
图像编辑是短板,但仍优于同期开源方案。
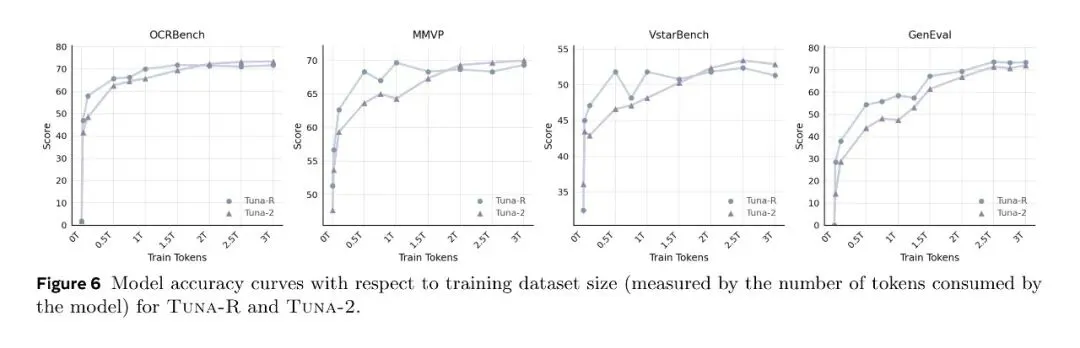
一个关键的训练动力学发现:训练初期 Tuna-R 全面领先(SigLIP 的语义先验提供了热身优势),但 Tuna-2 随着数据量增加逐步追赶并在后期反超。
这表明 encoder-free 的 monolithic 架构在大规模多模态联合预训练下能更充分地受益于数据扩展。
在 pixel-centric benchmark(V*、CountBench、VisuLogic)上,Tuna-2 和 Tuna-R 相对 latent-space 方案有显著优势,说明像素空间表征对细粒度视觉感知的价值。
Attention 可视化也验证了 Tuna-2 的跨模态对齐质量——在对抗性测试场景中能准确聚焦正确目标,而其他模型易被文本先验误导。
局限与展望
生成质量仍有差距,说明 representation encoder 的语义先验对生成仍有裨益。
图像编辑上也落后于带编码器的版本。
此外仅在 7B 模型上验证,训练数据全部为 in-house 数据集不可复现,更大参数规模下的表现需要进一步探索。
未来值得关注的方向包括:通过更强的 masking 目标弥补生成上的语义先验差距、在更大规模(30B+)上验证表现、以及将像素空间 UMM 扩展到视频领域。
#Tuna2 #统一多模态模型 #EncoderFree #像素空间建模 #FlowMatching #MetaAI #多模态大模型 #视觉理解 #图像生成
原文链接:https://arxiv.org/pdf/2604.24763