 夜雨聆风
夜雨聆风





【AI 进阶篇】:多模态|不止打字聊天!现在的 AI,早就能看、能听、能看懂视频
但不管是打字提问,还是文档读取,本质都还停留在文字交互。可我们真实的生活和工作里,信息从来不止文字这么简单。照片、录音、短视频、监控画面、现场设备实拍……每天接触的,全是图片、声音、影像各类信息。
只会认字的 AI,终究有局限。今天咱们就聊通透:多模态 AI,正在让 AI 跳出文字束缚,真正做到能看、能听、能理解画面。
一、什么是多模态?
先搞懂一个简单概念:模态,就是信息的呈现形式。文字、图片、语音、视频,每一种,都是一种独立模态。
所谓多模态,说白了就是:AI 不再局限于只读文字,可以同时看懂图片、听懂声音、解析视频、生成画面、朗读语音,打通全方位信息。
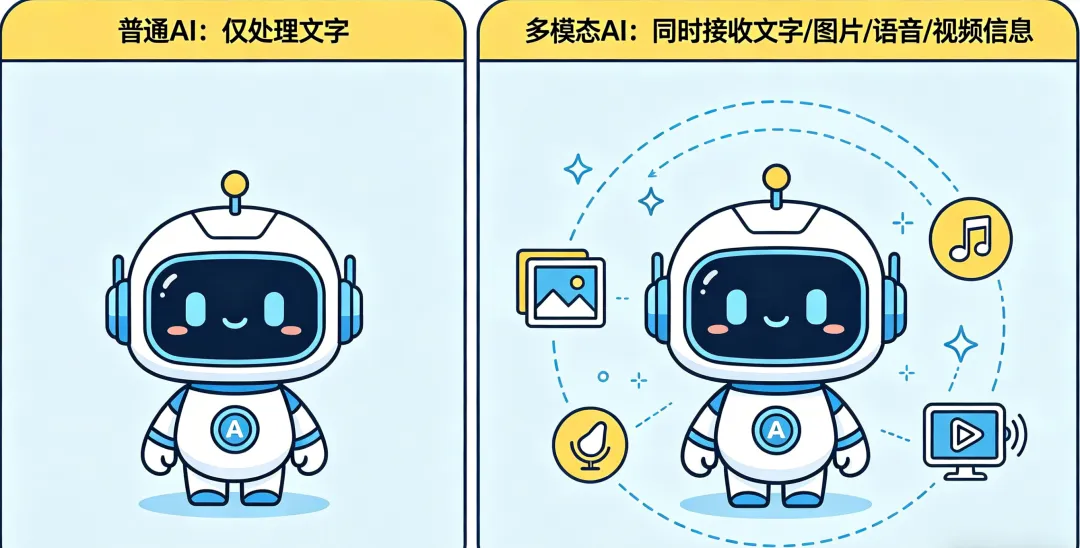
放到日常场景里,很好理解:
看图解读:上传一张设备实拍图,AI 直接告诉你设备状态、有无故障;
语音交互:直接说话下达指令,不用打字,AI 听懂就办事;
视频解析:一段监控录像,AI 自动筛查异常、统计画面内容;
文生图片:一段文字描述,自动生成海报、场景插画;
文字配音:一段文案,一键转换成自然人声朗读。
这不复杂,就是模仿我们人的感知方式。人靠眼睛看、耳朵听、嘴巴说、手写文字;而多模态 AI,正在慢慢补齐这些能力,变得越来越立体、越来越好用。
二、多模态到底能做什么?早就融入日常
其实大家早就悄悄用过多模态功能,只是没有特意留意。分享几个接地气的实用能力,一看就明白。
1. 图片智能识别
工作里经常遇到设备实拍、现场照片、报表截图。放到以前,只能靠自己一点点看、慢慢排查。现在把照片丢给 AI,它可以快速识别:设备型号、指示灯状态、线路连接情况、外观破损问题,一眼排查隐患。很多现场问题,不用工程师亲自到场,拍张照片就能远程判断,省时又省力。
2. 全场景语音交互
打字不方便的时候,语音就是最高效的方式。开车途中、户外巡检、手上忙工作,直接开口下达需求:查询套餐信息、调取业务资料、整理工作纪要、查询故障方案。AI 实时语音识别、快速响应,彻底解放双手,日常办公、一线作业都很适配。
3. 智能视频分析
厂区监控、园区安防、路口画面,过去全靠人工盯着屏幕。长时间值守极易疲劳,遗漏问题是常事。多模态 AI 可以 7×24 小时不间断分析视频画面:自动识别烟火、违规聚集、翻越围栏、异常逗留等风险,一旦发现问题立刻预警,不用人时刻盯屏,安防效率直接拉满。
4. 一键图表与素材生成
做汇报、写材料,最耗时间的就是做图表、做配图。一组枯燥的数据,发给多模态 AI,就能自动生成整洁直观的统计图表;活动宣传、日常科普,输入简单文字描述,就能快速产出配图、短素材,不用依赖设计师,紧急宣传需求也能快速落地。
三、贴合行业:运营商如何用好多模态?
结合运营商一线工作场景,多模态不是抽象概念,落地性极强,四大场景直接能用。
场景 1:一线网络巡检
以前巡检全靠人工现场排查,肉眼观察设备、手工登记台账,工作量大、效率低,还容易因为疏忽漏掉隐患。
引入多模态之后,巡检人员随手拍照、录制短视频,AI 自动识别设备运行状态、线路接线问题、机房环境隐患,自动整理巡检内容,一键生成标准化巡检报告。整体巡检效率提升 3 至 5 倍,漏检、错检问题大幅减少。
场景 2:营业厅智慧服务
线下营业厅经常出现排队拥堵,简单业务占用大量人工精力。借助多模态设备,融合图像识别 + 语音交互:客户出示证件、语音说出办理需求,就能自助办理基础业务。查询、续费、基础业务变更全部自助完成,人工窗口只专注处理复杂业务、特殊诉求,服务体验更好。
场景 3:全域智能安防
机房、园区、办公楼、基站周边,都需要常态化安防管理。依靠多模态视频分析能力,全网监控实时智能研判,全天候自动捕捉异常行为、安全隐患,秒级推送告警信息。不用专人轮班盯监控,安防值守压力大幅降低,安全保障更到位。

场景 4:营销内容快速创作
运营商日常活动多、宣传节奏快,海报、短视频、科普配图需求量大。传统设计流程慢、排期紧,很难跟上活动节奏。
依托多模态 AI,文字一键生成宣传海报、科普漫画、短视频素材,活动文案、业务介绍,还能自动配音、剪辑,营销素材产出效率翻倍,临时加急宣传也能轻松应对。
四、客观看待:多模态的短板与挑战
多模态体验很强,但也并非完美无缺,客观认清边界,才能合理使用。
第一,识别精度有限。光线昏暗、环境嘈杂、画面模糊时,AI 看图、听音的准确率会明显下降,关键工作、敏感场景,一定要人工二次复核,不能完全依赖 AI。
第二,算力消耗更高。对比纯文字处理,图片、音频、视频的运算负荷更大,需要消耗更高算力资源,对企业平台建设、成本投入有一定要求。
第三,隐私合规风险。视频采集、语音收录、画面抓拍,都会涉及人员隐私与内部场景,尤其是办公区域、机房、营业厅等公开场所,必须严格遵守数据合规要求,做好信息加密与权限管理。

五、主流好用的多模态 AI,日常按需选择
目前国内主流大模型,基本都已全面支持多模态能力,各有优势:
文心一言:图文理解成熟,文生图、日常配图很好用;
通义千问:图文、音频、视频全维度覆盖,综合能力均衡;
讯飞星火:深耕语音技术,语音识别、实时转写、配音体验突出;
Kimi:擅长长文档搭配图片解读,适合材料审核、资料分析;
运营商自研大模型:移动九天、电信星辰等,贴合行业场景,适配内部办公。
不同场景选不同工具,语音需求选讯飞,配图创作选文心,综合办公选通义,贴合内部业务就用运营商自研平台。
六、全文小结
简单总结一下多模态的核心:多模态,就是打破文字局限,让 AI 进化出视觉、听觉、创作能力。图片识别、语音交互、视频分析、素材生成,样样都能落地。
对于运营商从业者来说,不管是网络巡检、一线服务,还是安防管理、宣传营销,多模态都能实实在在简化工作、降低重复劳动、提升效率。
不用把它当成遥远的未来技术,多模态早已全面普及,当下就能上手使用。主动适应、学会巧用,才能让 AI 真正为日常工作赋能。

下期预告AI 安全与伦理!AI 乱用、信息泄露、内容风险、版权问题……普通人职场必懂的 AI 红线,下期一次性讲清楚,避开使用陷阱。
媒体运营编审:锵锵行通信咨询团队
制图:王东 编辑:孙博
审校:黄国栋

END