 夜雨聆风
夜雨聆风





BVP:为 AI 时代构建生物学原生的数据基础设施
AI时代,生物数据基础设施正在成为真正壁垒
近日,全球知名风险投资机构 Bessemer Venture Partners(BVP) 在其 Atlas 专栏发布文章 《Building Biology-Native Data Infrastructure for the AI Era》。
文章中表述,随着计算成本下降、模型逐渐成熟,想要在全球药物研发竞争中保持优势,就必须在整个数据基础设施上持续创新。
而生物学原生数据、智能体工作流以及实验室自动化,将共同定义下一代领先的生物技术公司。
1
生物学原生数据基础设施
长期以来,药物研发本质上一直是一个通过“试错”来验证生物学假设是否符合临床现实的过程。尽管科学与技术不断进步,从靶点发现到获得临床候选药物,通常仍需要超过五年时间;而进入临床试验的药物中,接近 90% 最终会失败。
随着治疗领域持续演进、药物形式日益复杂,单个获批药物所对应的研发成本仍以约每九年翻一番的速度增长,也就不足为奇了。药物研发真正的限制因素,从来不是缺少假设,而是缺少能够高效、有效评估这些假设的资源。
机器学习在药物设计中的价值,正在于它有可能改变这一“投入产出关系”:通过加速迭代、提高成功概率,重新定义药物研发的效率。2012 年至 2022 年间,约有 200 家利用 AI 进行药物发现的公司累计融资 180 亿美元。如今,我们正在临床阶段看到这些努力的成果。
2025 年 6 月,Insilico Medicine 在《Nature Medicine》上发表了其首创小分子 TNIK 抑制剂 rentosertib 用于治疗特发性肺纤维化的 IIa 期临床阳性结果。该项目也被认为是首个在临床阶段完成概念验证的药物案例,其靶点发现和分子设计均由生成式 AI 完成。
在这一案例中,AI 生成化学平台在分子设计与优化中发挥了关键作用,也展示了 AI 改变药物研发“数学题”的潜力。传统药物发现通常需要筛选数千个分子,而该团队仅筛选了 78 个分子,便成功提名临床前候选药物。整个流程仅耗时 18 个月,研发成本也不到单个获批药物平均研发成本的 10%。
正是由于这种更具吸引力的投入产出结构,包括大型制药公司在内的许多企业,正开始有意识地将 AI 平台纳入自身研发流程,以加速药物发现并提升研发效率。
Insitro 则采用了另一种路径:将大规模人类细胞数据生成与机器学习结合。近期,BMS 又在与 insitro 的合作中提名了两个新的 ALS 靶点,进一步验证了“全栈式方法”的价值,也就是将专有数据生成能力直接嵌入药物开发流程。
Isomorphic Labs 是 Google DeepMind 旗下、AlphaFold 背后的衍生公司,已与礼来、诺华和强生建立深度合作,潜在合作总价值超过 30 亿美元。同时,公司也在推进自有肿瘤管线进入首次人体试验。其最新发布的 IsoDDE 模型在高难度泛化基准测试中,准确率超过 AlphaFold 3 的两倍,使其成为 AI 药物设计领域最受关注的公司之一。
制药公司之外,前沿 AI 实验室也开始直接押注药物发现。2026 年 4 月初,Anthropic 以 4 亿美元股票收购了成立仅八个月的 Coefficient Bio。该公司由前 Evozyne、Genentech 和 Prescient Design 的计算生物学家创立,这一交易也显示,AI 巨头正在将药物发现视为重要的落地方向。
虽然计算化学工具早在 20 世纪 80 年代就已出现,但生物技术领域真正进入现代 AI 时代,始于 2010 年代深度学习的兴起。随着神经网络能够从数据中学习分子结构的有效表征,AI 开始真正参与到生物医药研发中。
真正的分水岭,是 DeepMind 的 AlphaFold2 和 Baker Lab 的 RoseTTAFold 解决了基于氨基酸序列预测蛋白质三维结构的难题。
此后,生物 AI 模型数量呈指数级增长。到 2024 年,已有超过 350 个生物 AI 模型发布,包括 AlphaFold3、ESM3、Boltz-1、BindCraft、Evo、scGPT 和 H-Optimus-0。这些模型展示了 AI 在生成式蛋白设计、基因组学与扰动建模、病理图像分析等任务中的应用潜力
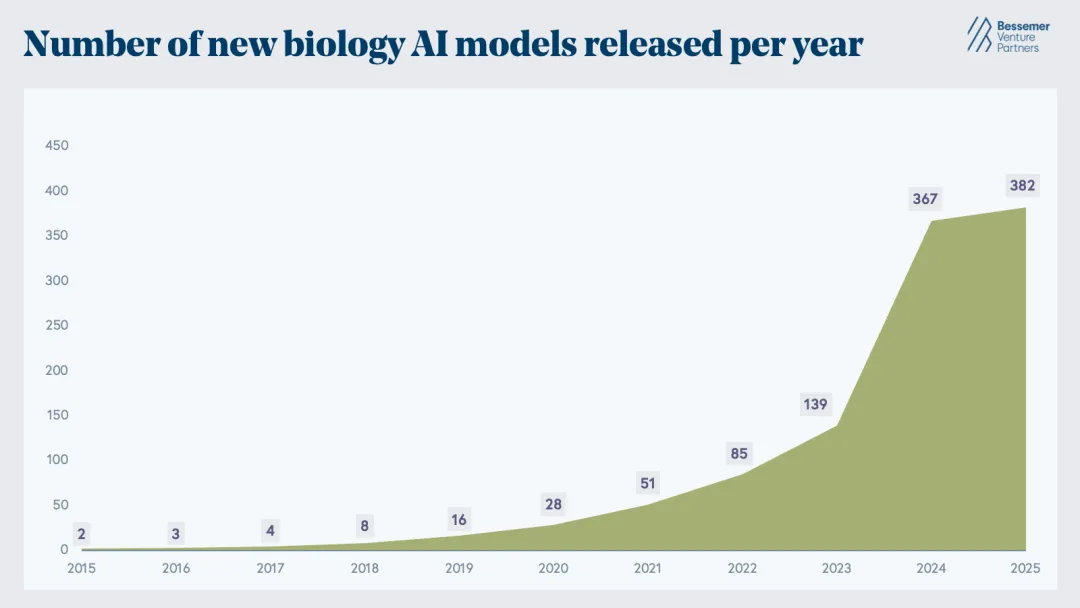
面向生物学的 AI 模型“寒武纪大爆发”已经发生。
2015 年至 2025 年间,每年发布的新生物 AI 模型数量从不到 10 个,指数级增长至 380 个以上,并且仍在持续增加。(需要注意的是,这一统计仅基于 Epoch AI 的数据集,可能并不完整)
最近,JAM-2、BoltzGen、Latent-X2、Chai-2 和 IsoDDE 等新模型持续推动我们接近一个目标:直接通过计算机设计具有药物特性的生物药。在零样本设计任务上,该领域的动能从未如此强劲。随着大量生物 AI 模型不断涌现,药物研发领域已经拥有了一整套工具,覆盖从结构建模、分子设计到药物优化的完整研发链条。
2
生物学原生数据基础设施的三项原则
在一个日益拥挤的市场中,BVP认为,真正能够长期生存并规模化发展的 AI 驱动生物技术公司,将建立在三项核心原则之上。BVP将这些原则统称为“生物学原生数据基础设施”的原则:
-
构建可规模化、多模态的数据集,并且这些数据集要围绕药物作用机制所面临的生物学挑战来设计。
-
将最新的智能体 AI 框架整合到完整的研发工作流中。
-
采用实验室自动化,支持快速、闭环的实验反馈。
能够支持或体现这三个原则的公司,才是真正有可能加速药物设计周期、降低临床试验失败风险,并兑现 AI 在生物学领域承诺的公司。
并且BVP也解释了,为什么这些原则对药物研发行业至关重要,并介绍了正在将这些原则付诸实践的新兴类别和公司。
市场地图

BVP的市场地图展示了正在利用 AI 创建和分析生物数据集的私营生命科学公司。这些数据集旨在解决药物研发链条上的关键挑战,加速端到端研发工作流,并实现湿实验中物理操作的自动化。
3
原则一:大规模生物学原生数据
当前许多 AI 生物模型所依赖的数据,来自过去几十年由公共科研资助持续积累的基础数据库。例如,蛋白质数据库 Protein Data Bank(PDB)收录的 20 多万个蛋白质结构,主要通过 X 射线晶体学、核磁共振波谱等实验技术测定而来。
类似地,人类基因组计划对人类基因和 DNA 序列的绘制,来自全球研究机构的大规模测序工作;ChEMBL 中数百万条小分子生物活性数据,也是在多年时间里从专利和文献中人工整理、提取而成。
这些基础数据库已经对药物研发产生了深远影响。以 PDB 为例,其结构数据参与了 2019 年至 2023 年期间 FDA 批准的所有靶向蛋白小分子抗癌药物的开发。
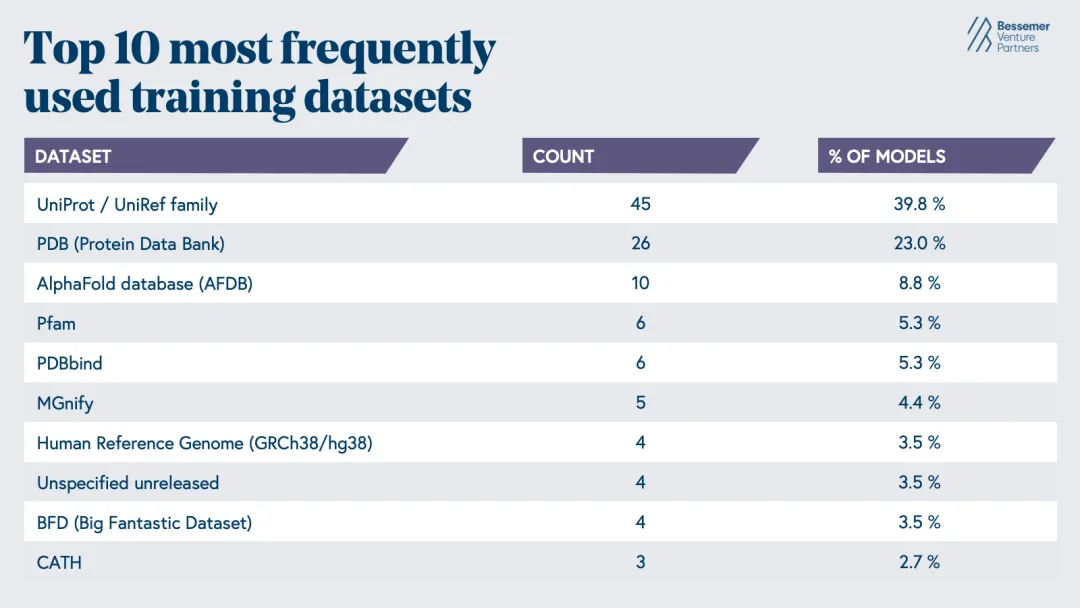
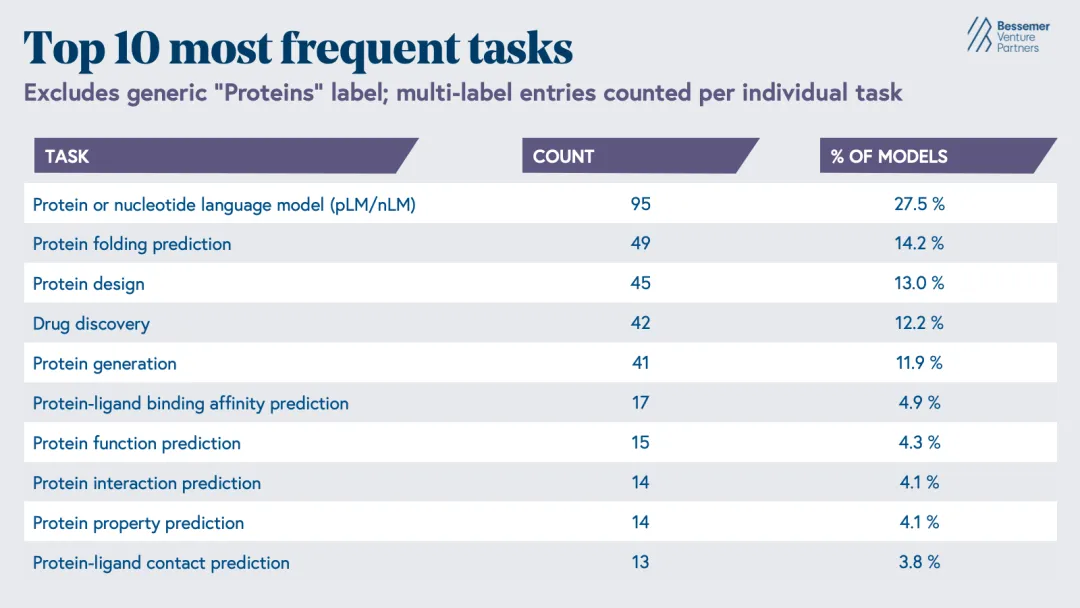
图1:生物技术模型最常使用的训练数据,图2:生物技术模型最常见的 10 类任务(排除了通用的“蛋白质”标签;多标签条目按单个任务分别计数)
过去几十年发展起来的 AI 生物模型,很大程度上反映了现有可用数据的结构。根据 Epoch AI 的数据,近 63% 的模型使用 UniProt 和 PDB 中的蛋白序列与结构数据进行训练。因此,这些模型最常见的任务也集中在蛋白质或核酸序列特征解析、蛋白折叠预测以及蛋白设计等方向。
然而,我们对早期药物发现中生物学机制的理解仍存在明显空白。这些空白既来自生物系统本身的高度复杂性,也来自现有研究工具的局限。
尽管 PDB 规模庞大,但其中的数据高度偏向于稳定、可溶、易于结晶的蛋白。相比之下,膜蛋白、内在无序蛋白以及瞬时蛋白复合物通常更难解析。它们往往是肿瘤学和神经退行性疾病中极具吸引力的药物靶点,却在数据库中代表性不足。
此外,PDB 捕捉到的结构通常只是单一构象状态,相当于把蛋白固定在某一个构象中,而无法呈现其在活细胞内不断变化的动态构象集合。但真正与治疗相关的,往往正是这些替代构象。例如,某些变构结合位点只有在配体结合后才会暴露。
虽然新药研发通常始于蛋白质结构解析与分子设计,但早期药物发现只占整个开发周期和成本的一小部分。超过三分之二的时间和资源,实际投入在后续环节,包括临床前研究中的 ADME 评估,即吸收、分布、代谢和排泄相关的药代动力学特征,以及制剂优化、临床安全性和有效性验证。
要将一个苗头化合物(hit)推进为先导化合物(lead),再进一步成为开发候选药物,仅证明其能够结合靶点远远不够。药物开发还需要系统评估其可开发性、免疫原性、脱靶效应、热稳定性、溶解度和聚集倾向等关键属性。然而,目前这些领域仍缺乏可用于模型监督学习的大规模、高质量公共数据集。
药物发现本质上是在理解生物系统对扰动的响应。但目前并没有类似 PDB 的数据库,能够系统刻画细胞表型如何响应不同扰动;也缺乏一个等价的数据库,用于系统记录不同疾病状态下的蛋白组学特征。
更大的空白在于,细胞层面的数据尚未与临床数据有效连接。与治疗结果和临床试验反应相关的患者级组学数据,往往分散在医院系统和药企数据库中。这使得模型很难在患者入组前,预测其是否会对某种治疗产生应答。
而这些属性,恰恰决定了一个分子最终能否成为获批药物。也就是说,商业价值最高的预测任务,正是当前数据基础设施最薄弱的环节。
今天可用的许多生物学数据,都是在生物 AI 模型爆发之前生成的,因此往往缺乏对机器学习真正有用的特征。注释信息通常不完整,也缺乏标准化;而关键实验背景信息,例如细胞环境或所使用的实验设备,也很少被捕捉或编码进数据集。
在很多情况下,生物学数据集的规模也不足以让模型得出具有统计显著性的结论,或者做出无偏预测。即使某些数据具备规模,数据也往往按模态被割裂开来,例如基因组、转录组、病理和临床结局数据经常被分别采集,并存放在不同位置。这使得构建一个能够让 AI 从完整的人类生物学图景中进行推理的数据层变得非常困难。
要真正释放 AI 在药物研发中的潜力,我们认为企业应该在两个方向上进行投入。第一,生成新的、多模态的生物学测量数据,以拓宽我们对疾病的理解。第二,构建具备足够规模、一致性和实验背景信息的数据集,使模型能够在不同生物学场景中广泛应用。
Converge Bio 正在生成大规模数据集,用于训练和验证自有模型,并向制药和生物技术客户提供抗体设计和序列优化能力。Seismic 则采用“管线优先”的策略,利用其 IMPACT 平台并行优化新型免疫学生物药的多类药物属性。
药物开发链条下游也在出现新的进展。
例如,NOETIK 正在构建肿瘤学领域最全面的数据集之一,将肿瘤多组学数据与纵向治疗结局相结合。
Prima Mente 则聚焦脑疾病,构建全基因组表观遗传与多组学数据模型。
这些数据丰富的疾病特异性基础模型,旨在支持新靶点和生物标志物发现,构建更精准的虚拟细胞扰动模拟,并优化临床试验设计。
4
原则二:覆盖研发工作流的智能体 AI
尽管将一种药物推向市场的成本不断上升,但自20世纪50年代以来,计算成本呈指数级下降,这与摩尔定律保持一致。在药物研发的整个链条中,那些目前计算开销很大的环节,将在几年内变得极其便宜。那些将其技术架构打造为能够快速适应AI能力持续演进的公司,相比于把AI视为一次性固定投资的公司,将拥有越来越明显的结构性优势。
计算药物发现工作流程的演变,是理解这种“适应性”在实际中如何体现的一个很好的视角。虽然十年前,内部自建专有分子建模和模拟工具可能是一种竞争优势,但如今,各种现成的计算机模拟工具已经非常丰富,这种“可防御性”的逻辑已经改变。
结构预测模型、ADMET模型(即药物的吸收、分布、代谢、排泄和毒性模型)以及分子动力学模拟器都已经非常成熟,并且可以通过闭源架构和开源代码库广泛获取。因此,在时间和资源效率上,策略性地组合使用这些现有工具,通常比从头自建更为划算。
同样的逻辑也适用于未来:随着新的基础模型不断出现、新的训练技术持续演进、以及新硬件带来的计算效率进一步提升。
企业应该从第一天开始就构建这样的基础设施:能够测试、实施并利用最新工具,而不是被固定在某一个技术体系上。今天,这种模块化基础设施可以表现为一个能够自主调用和编排最佳工具的系统,根据不同任务选择合适工具,无论是文献综述,还是运行生物信息学分析流程。
更便宜的计算使长上下文推理在经济上变得可行,让 AI 智能体能够在单次运行中综合分析超过 1000 篇论文和 4 万行代码。再结合提升 AI 准确性和效率的技术,例如思维链推理和多智能体框架,AI 已经越来越有可能显著压缩研发生命周期的成本和时间。
Agentic AI 科学家可以自动检索并分析预印本服务器、专利申请文件和公共生物数据库,发现非显而易见的关联,生成新的研究假设,开展计算模拟的数据分析,设计湿实验方案,并撰写研究报告。同时,它们还能维护团队级研究背景信息和实验历史记录,帮助科研团队更快、更准确地做出决策。
很快,覆盖药物研发全流程的 AI 操作系统将成为行业标配。这类系统能够利用 AI 长时间记住上下文的能力,把分析过程、实验结果和研究记录整合到同一个研发环境里,而不是让数据和结果散落在一个个互不打通的工具中。
越来越多的公司正在朝这一愿景构建产品。其中既包括专注于生命科学的初创公司,也包括 Anthropic 这样的前沿实验室。
Anthropic 目前已经提供连接器,可以将 Claude 与 Benchling、PubMed、ChEMBL、ClinicalTrials.gov 等平台整合。
K-Dense 和 Edison Scientific 正在开发自主 AI 科学家平台,能够从假设生成到运行计算实验,端到端地规划、执行并迭代复杂、长期的研究工作流。
Phylo 则采用了互补路径,推出 Integrated Biology Environment,这是一个统一工作空间,使科学家能够在自己的数据集和分析流程中与 AI 智能体无缝协作,而无需在碎片化界面之间来回切换。
5
原则三:闭环实验室自动化
即使使用最先进 AI 模型的公司,也会受到实验数据生成能力的限制。虽然蛋白结构预测和分子建模已经取得了很大进展,但很多计算预测结果,例如结合亲和力预测,仍然必须通过湿实验验证,才能支持后续研发决策。
更重要的是,体内药效很难仅靠理论模型准确预测。许多药物在后期失败,往往是因为药代动力学和毒性问题,而这些问题并没有被计算模型提前识别出来。实验结果仍然是最重要的生物学“真实标准”。因此,AI 模型必须持续吸收湿实验反馈,才能不断校准并保持准确性。
但问题在于,从模型给出结果,到完成实验、获得可用于更新模型的数据,往往需要几周甚至几个月。湿实验本身速度慢、失败率高,还依赖经验丰富的实验人员,因此成为缩短药物开发周期的主要瓶颈之一。
在先导化合物优化阶段,典型流程是“设计-合成-测试-分析”的反复迭代,这一过程本身就可能长达三年,并占整个药物开发周期的近四分之一。
此外,很多实验验证还会外包给 CRO。外包虽然常见,但也会带来沟通成本、排队等待和数据质量不一致等问题,使每一轮迭代又额外增加数周甚至数月。因此,越来越多团队需要把实验能力建设到内部。这样不仅可以更好地控制实验背景和数据质量,也能让 AI 模型真正形成“计算预测-实验验证-数据反馈-模型更新”的闭环学习。
虽然 Hamilton 的液体处理机器人和 Chemspeed 的自动化合成平台已经在实验室中使用了几十年,但它们更多是为了完成某些特定步骤的高通量操作,而不是为了实现整个实验流程的自动化和一体化。
目前,大多数实验室自动化仍然需要大量人工介入。例如,实验人员需要在不同仪器之间转移样本和试剂,处理实验故障,并在进入下一步实验前解读结果。因此,这类自动化往往只是加快了单个步骤,并没有真正缩短从实验设计到结果分析的完整周期。
过去,要让实验室机器人真正自动运行,通常需要专门的自动化工程师来配置仪器,并针对不同实验流程不断编写新的脚本。未来,如果机器人控制可以通过自然语言界面完成,实验自动化能力就有可能被更多科研人员使用。即使科学家没有机器人或软件工程背景,也可以远程、自主地运行、监控和迭代实验。
机器人技术和物理 AI 的进步,也有望进一步自动完成目前仍依赖人工的样本转移和数据流转。例如,现在一些基于视觉识别的系统,已经可以自动读取和分析细胞显微图像,并将结构化数据直接反馈到模型分析流程中,而不再需要科研人员手动提取和录入结果。
自主实验室的发展,将显著提升企业在研发速度和运营成本上的优势。如果一个模型能在竞争对手完成一轮“设计-测试-分析”循环的时间内完成五轮迭代,它对生物学规律的理解就会更快积累。这种积累会直接转化为更好的模型、更优的分子,以及一种很难被依赖传统 CRO 周期的公司追赶的结构性优势。
与此同时,通过实验室自动化提升迭代速度的公司,也将获得更一致、更准确、更大规模的数据。这也进一步呼应了前文的核心判断:AI 药物研发真正需要的是大规模、面向生物学问题设计的数据基础设施。
目前,实验室自动化领域的公司正在从不同方向推进这一趋势。
Medra 正在构建一种不依赖特定仪器品牌的机器人平台,让通用型机器人通过物理操作和软件接口与现有实验室设备互动。
Automata 则采用实验室流程整合的思路,通过 LINQ 平台提供模块化硬件和软件,把分散的仪器连接成协调运行的端到端自动化流程。
Dash Bio 利用机器人技术打造更快速、更自动化的 CRO,希望提供接近内部自动化实验室的速度和一致性。Lila Sciences 则代表了更垂直整合的路径,正在建设一个覆盖药物发现与开发全流程的全自动化实验室。
结语
生命科学将运行在 AI 之上
BVP这篇文章传递了一个清晰信号:
构建大规模生物学原生数据集、以 AI 为核心的开发技术平台,以及能够支持快速闭环实验的实验室自动化平台的公司,将推动并定义下一代生命科学公司。
BVP认为,这一市场可以分为三个相互依赖的层次。
最上层,是那些以 AI 所需的规模、模态和保真度生成数据的公司,它们能够在药物研发链条中产生有意义的发现。
其下,则是物理基础设施层和软件基础设施层,包括工作流自动化和实验室自动化平台,它们能够压缩每一个阶段的研发周期。
三者合在一起,构成了 AI 驱动药物研发中正在形成的大部分价值链。
BVP认为,这也是下一代生命科学公司将会诞生的核心投资领域。
珞米蛋白组方案合集
国际论文背书|2个月神速见刊:Proteonano 把血浆蛋白覆盖提升到 6000+
警惕,你漂亮的蛋白组学数据可能是污染!Mann神再出手,血浆蛋白组学终于迎来新标准?
AI for Science爆发,珞米要做人类蛋白组大数据供应商
哎呦不错,中国公司杀入全球高通量蛋白组第一梯队【珞米高通量蛋白组】

点击“阅读原文”查看原文

产品及服务咨询 请扫码联系或填写您的信息

关于Nanomics珞米科技


分享让更多人看看