夜雨聆风
夜雨聆风





【进化】别用买软件的思维买 AI:高管的认知升级与五维评估(中篇)
前言
2025 年的市场底牌已经掀开:近九成的中国企业已将 AI 落地于实际业务。但若仔细查阅各家的商业账本,会发现一个极其残酷的双面性:对于少数破局者,AI 是拉开代际差距的“生产力飞轮”;而对于大多数跟风者,AI 却成了激化内部矛盾的“生态颠覆者”。
在上集中,我们无情地撕开了企业“伪数字化”的遮羞布:为什么花几十万买了 AI 账号,但效果不佳?因为高管跳过了最致命的一环——业务诊断。
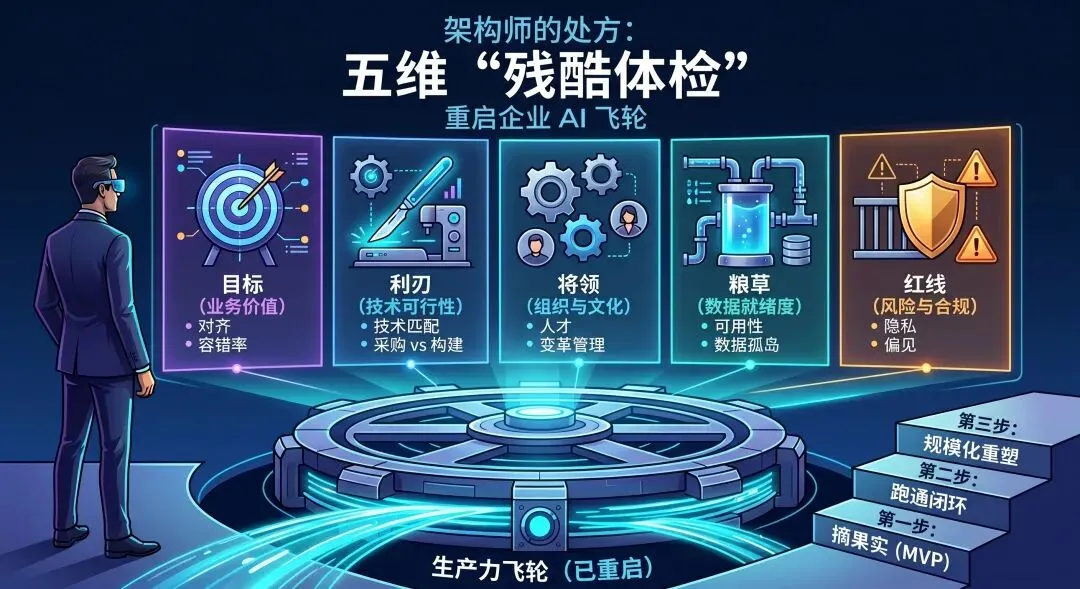
当你准备将 AI 接入核心业务流之前,请立刻停止盲目采购,建议用这套“五维就绪度评估”,对组织进行一次彻底的冷酷体检。
一、业务特点与价值评估(定靶:解决“用在哪”和“值不值”)
AI 必须服务于真实的业务场景,评估的第一步是剖析企业自身的业务形态。
-
业务痛点与战略对齐:明确引入 AI 的核心目的,是为了降本增效(如客服自动化、票据信息抽取)、驱动增长(如千人千面的精准营销),还是业务创新(如 AI 辅助新材料研发、代码生成)?
-
场景的“容错率”(极重要):
-
高容错场景:如营销文案初稿生成、内部头脑风暴、会议纪要提取。即使 AI 出现“幻觉”或小错,人工修正成本极低,适合率先上马大模型应用。
-
低容错场景:如医疗诊断、金融核心交易、工业控制。这些场景对准确率要求极高(99.99%),AI 现阶段只能作为“辅助”,且必须设计严格的“人类审批兜底机制”。
-
流程的标准化与数字化程度:高度标准化、规则清晰、重复频次高的业务最容易被 AI 赋能;而高度非标、强依赖复杂人际博弈的环节(如大客户深度谈判),AI 目前只能做外围信息辅助。
-
ROI(投资回报率)测算:算清“显性成本”(算力购买、API 调用费)与“隐性成本”(前期数据清洗、员工培训、后期模型微调),确保引入 AI 所节省的人力或带来的增量,能够完全覆盖全生命周期的拥有成本。
二、AI 匹配度与技术可行性评估(选刃:解决“能不能”和“怎么建”)
评估当前的 AI 技术能否以合理的成本解决业务问题。
-
技术选型匹配:
-
需要“内容创造、知识问答、信息摘要” → 匹配生成式 AI;
-
需要“销量预测、风险预警、欺诈拦截” → 匹配传统预测性 AI;
-
需要“跨系统的死板自动点击录入” → 匹配传统RPA(机器人流程自动化),成本往往更低。
-
实施路径选择:
-
开箱即用:直接采购成熟的 AI SaaS(如各类 AI 办公助手),成本低、见效快,适合通用办公场景。
-
知识库外挂(RAG 检索增强生成):调用成熟大模型 API + 企业私有知识库。当前性价比最高,既保证了回答的专业性,又避免了数据泄露给公有模型。
-
模型微调:适合拥有独特行业壁垒、对特定垂直领域(如医疗、法律)有深厚数据积累的企业。
-
技术边界认知:客观看待当前 AI 的技术瓶颈(如复杂逻辑多步推理不足、长文本遗忘),不要抱有科幻级的盲目预期。对于绝大部分非科技企业而言,绝不盲目自研大模型底座才是最理智的选择。
三、组织能力与文化评估(点将:解决“谁来用”和“用得好”)
业内铁律:AI 落地的成功,30% 靠技术,70% 靠人与组织。
-
人才结构与“AI 翻译官”:大多数非科技企业不需要养庞大的底层算法科学家团队,但极其需要两类人:
-
复合型产品经理:既懂公司业务痛点,又了解 AI 能力边界,能将业务需求精准“翻译”成技术指令。
-
业务超级个体:在各业务线中能熟练掌握“AI知识”、带头使用 AI 工具的业务骨干。
-
企业文化与变革管理:
-
容错文化:AI 在初期必然会犯错甚至表现“愚蠢”。管理层是否具备战略定力,愿意给予团队试错和迭代的缓冲期?
-
消除员工防备:基层员工是将 AI 视为“抢饭碗的敌人”,还是“提效的超级助手”?企业需要建立培训体系和激励机制,缓解员工的“被替代焦虑”。
-
组织协同机制:AI 项目需要业务提需求、IT 建底座、法务看合规。企业现有的组织架构是否支持打破“部门墙”?是否有必要成立跨部门的 AI 卓越中心来统筹资源?
四、数据资产就绪度评估(备粮:解决 AI 的“燃料”问题)
没有高质量的数据,再强的 AI 也只会是无源之水。
-
数据可用性与质量:企业的历史数据是否准确、干净?特别是在大模型时代,企业对非结构化数据(如海量的 PDF 操作手册、历史会议录音、产品图纸)是否具备提取、清洗和向量化处理的能力?
-
打破数据孤岛:CRM、ERP、HR等核心系统的数据是否已经打通?如果数据被割裂在各个部门,AI 就无法提供全局视角的智能决策。
-
私有知识壁垒:评估企业是否将独有的“行业 Know-how”沉淀为了数字资产,这是企业不被通用大模型同化、打造专属 AI 护城河的关键所在。
五、风险、安全与合规评估(画线:守住企业的“生死底线”)
特别是引入外部公有云大模型时,风险评估是重中之重。
-
数据隐私与商业机密泄露:员工如果不经规范,将企业的核心源代码、未公开的财务报表或客户的个人敏感信息(PII)输入给公共大模型,将引发严重的泄露灾难。必须评估是否建立网关拦截机制或采用私有化部署。
-
法律合规与版权:AI 生成的代码、营销图片、文案是否存在侵权争议?数据的使用是否符合《网络安全法》、《数据安全法》以及国家对于生成式人工智能服务的监管要求?
-
算法偏见与伦理:AI 在辅助招聘简历筛选、信贷审批中,是否会带有基于历史数据产生的性别、地域偏见?合规评估必须走在业务推进的前面。
💡 架构师的破局药方:告别大跃进,开启 3 步走
完成上述评估后,切忌一开始就全公司、全业务线盲目铺开。建议采用 “大处着眼,小步快跑”的策略:
第一步(MVP试点):利用上述评估矩阵,挑选 1~2 个“高业务价值 + 高容错率 + 数据基础好” 的边缘场景(例如:内部 IT/HR 政策知识库问答、客服助手、营销文案生成)进行 MVP(最小可行性产品)试点。
第二步(跑通局部闭环):在小范围试点中,跑通 “数据处理 → 模型调用 → 业务反馈 → 效果微调”的闭环,让团队尝到甜头,用局部的胜利建立内部信心。
第三步(规模化重塑):沉淀出企业专属的数据飞轮和使用 SOP,逐步将 AI 能力深度集成到核心业务系统(ERP、CRM)中,实现从“辅助工具”到“核心生产力”的跨越。
“道理都懂,但这关键的‘第一步(MVP)’,到底该怎么切入?如果我连代码都不懂,怎么计算 AI 的真实 ROI?”
认知一旦对齐,剩下的就是动手,详见下一集《实操篇》的落地打法。
🔗 欢迎关注与留言👏👏👏
我的朋友们,如果你也脚踏大地、心向大海,欢迎与我一起实践我的 Relink Lab。
Relink Lab·附小诗:《鉴机图》
莫将算力作庸工,
五维明镜破盲从。
铁面海关清旧弊,
飞轮转处定苍龙。